ShuffleNetV2Plus-基于MindStudio的MindX SDK应用开发
目录
一、任务介绍
二、环境搭建与配置
1. Windows安装MindStudio
2. Windows安装MindX SDK
三、推理开发运行流程
四、ShuffleNetV2Plus模型推理介绍
五、Python应用开发(可参考代码)
1. 创建MindX SDK应用工程
2. 模型转换
3. pipeline流程文件编排
4. Python脚本编写
5. Python脚本应用运行
六、C++应用开发(可参考代码)
1. 创建MindX SDK应用工程
2. 图片处理脚本preprocess.py
3. 头文件Shufflenetv2plusClassify.h
4. 源文件Shufflenetv2plusClassify.cpp
5. 主函数源文件main.cpp
6. C++应用编译
7. C++可执行文件应用运行
七、FAQ
八、从昇腾社区获得更多帮助
一、任务介绍
MindX SDK应用开发旨在使用华为提供的SDK和应用案例快速开发并部署人工智能应用,是基于现有模型、使用pyACL提供的Python语言API库开发深度神经网络应用,用于实现目标识别、图像分类等功能。
通过MindStudio实现SDK应用开发分为基础开发与深入开发,通常情况下用户关注基础开发即可,基础开发主要包含如何通过现有的插件构建业务流并实现业务数据对接,采用模块化的设计理念,将业务流程中的各个功能单元封装成独立的插件,通过插件的串接快速构建推理业务。
根据MindStudio昇腾论坛上的教程“MindX SDK应用开发全流程”,本图文案例的输出,是基于整体过程在Windows操作系统上开展的,针对ShuffleNetV2Plus图片分类模型的,基于MindStudio的MindX SDK应用开发。
二、环境搭建与配置
1. Windows安装MindStudio
MindStudio提供了AI开发所需的一站式开发环境,提供图形化开发界面,支持模型开发、算子开发以及应用开发三个主流程中的开发任务。同时还支持网络移植、优化和分析等功能。依靠模型可视化、算力测试、IDE本地仿真调试等功能,MindStudio能够帮助用户在一个工具上就能高效便捷地完成AI应用开发。同时,MindStudio采用了插件化扩展机制,开发者可以通过开发插件来扩展已有功能。
MindStudio可以单独安装在Windows上,用户可在MindStudio下载页面下载软件。安装MindStudio前还需要安装Python3.7.5、MinGW、CMake等本地依赖,具体安装流程可以参考Windows安装MindStudio。
在安装MindStudio前需要在Linux服务器上安装部署好Ascend-cann-toolkit开发套件包,之后在Windows上安装MindStudio,安装完成后通过配置远程连接的方式建立MindStudio所在的Windows服务器与Ascend-cann-toolkit开发套件包所在的Linux服务器的连接,实现全流程开发功能。开发运行场景如图1所示。

图1 开发运行场景(共部署形态)
2. Windows安装MindX SDK
- 步骤1-远端环境MindX SDK开发套件安装
Windows场景下基于MindStuido的SDK应用开发,请先确保远端环境上MindX SDK软件包已安装完成,安装方式请参见《mxManufacture 用户指南》和《mxVision 用户指南》的“使用命令行方式开发”>“安装MindX SDK开发套件”章节。
- 步骤2-本地CANN安装
在Windows本地打开MindStudio,点击Customize > All settings…,如图2所示。
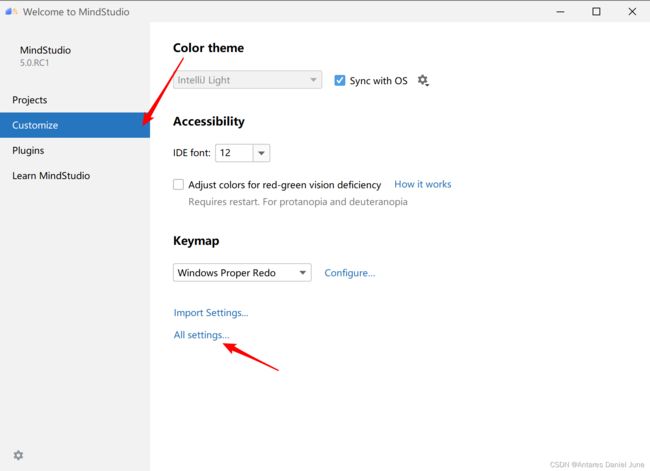
图2 All Settings
进入设置页面,点击Appearance & Behavior > System Settings > CANN进入CANN管理界面。界面中的Remote Connection为远程连接的用户及IP,Remote CANN Location为远端环境上CANN开发套件包的路径。单击“Change CANN”进入Remote CANN Setting界面,如图3。
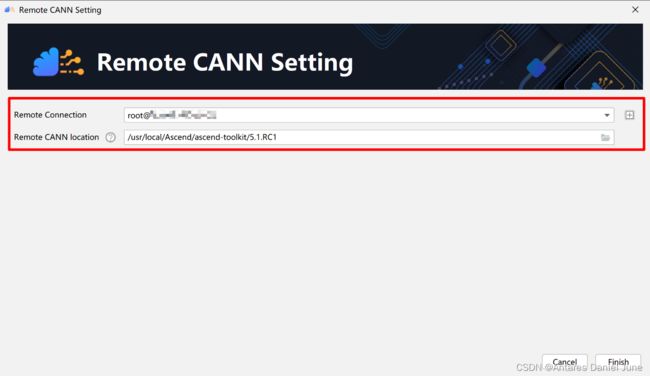
图3 Remote CANN Setting
首先配置远程连接,点击右侧“+”,出现如图4的界面,表1是一些参数说明。
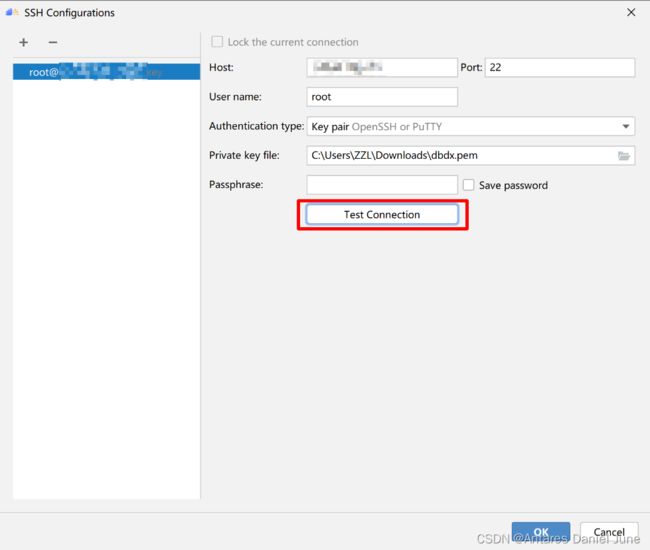
图4 SSH Configurations
| 参数 |
说明 |
| Host |
远程服务器IP地址 |
| Port |
远程服务器端口号 |
| Username |
用户名 |
| Authentication type |
验证类型 |
| Password |
密码 |
表1 SSH Configurations参数说明
填写完毕后,点击“Test Connection”测试连接是否正常,若显示图5弹窗,则表示远程连接可用。即可一路点击“OK”按钮完成远程连接的配置。
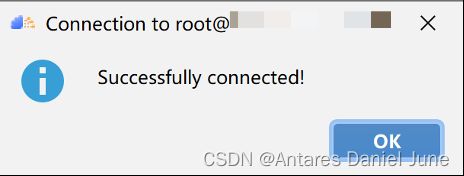
图5 远程连接测试成功
然后配置远端环境上CANN开发套件包的路径,我们这里填写“/usr/local/Ascend/ascend-toolkit/5.1.RC1”。随后点击“Finish”按钮,等待同步完成即可,CANN安装成功后的CANN管理页面如图6所示。
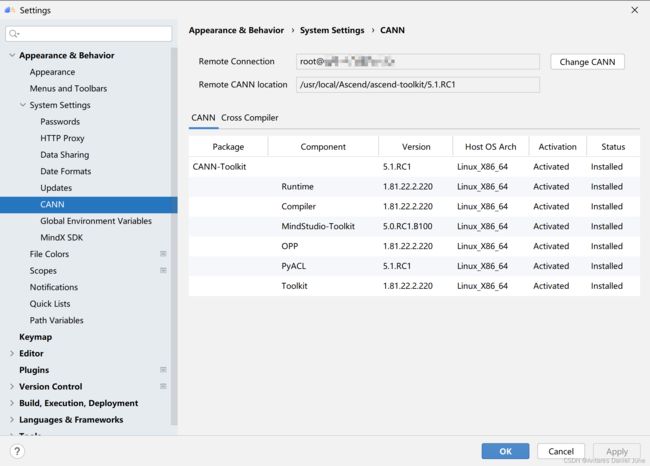
图6 CANN安装成功后的CANN管理页面
- 步骤3-本地MindX SDK安装
与步骤2开始一致,进入设置页面,点击Appearance & Behavior > System Settings > MindX SDK进入MindX SDK管理界面。界面中MindX SDK Location为软件包的默认安装路径,默认安装路径为“C:\Users\用户名\Ascend\mindx_sdk”。单击Install SDK进入Installation settings界面,如图7,表2为一些参数说明。
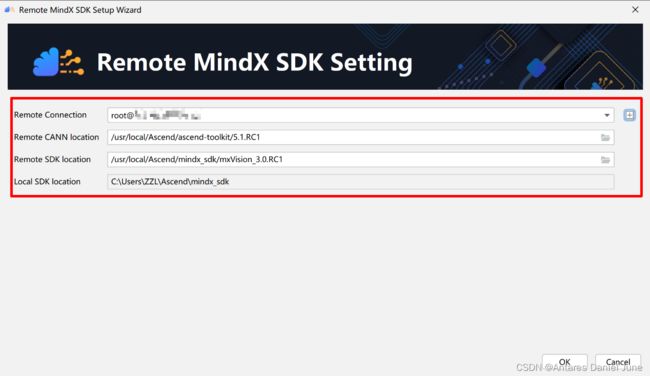
图7 Remote MindX SDK Setup Wizard
| 参数 |
说明 |
| Remote Connection |
远程连接的用户及IP |
| Remote CANN Location |
远端环境上CANN开发套件包的路径,请配置到版本号一级 |
| Remote SDK Location |
远端环境上SDK的路径,请配置到版本号一级。IDE将同步该层级下的include、opensource、python、samples文件夹到本地Windows环境 |
| Local SDK Location |
同步远端环境上SDK文件夹到本地的路径。默认安装路径为“C:\Users\用户名\Ascend\mindx_sdk” |
表2 Remote MindX SDK Setup Wizard参数说明
填写完毕后,点击“OK”按钮,等待MindSrudio将远端服务器上的MindX SDK套件安装到本地电脑中。MindX SDK套件安装成功后的MindX SDK管理页面如图8所示。
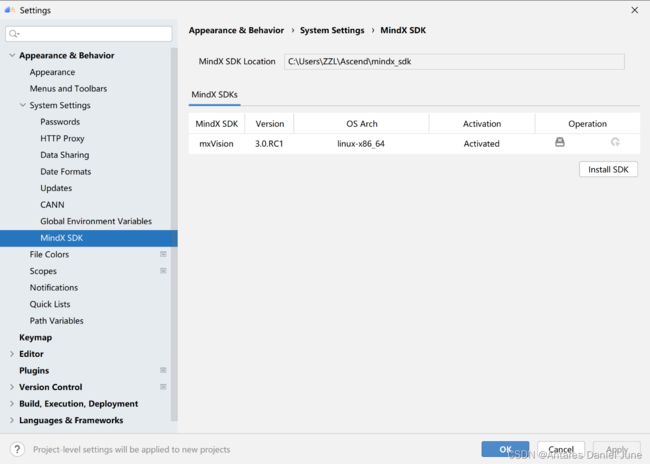
图8 MindX SDK套件安装成功后的MindX SDK管理页面
最后点击“OK”按钮,结束MindX SDK在本地Windows上的全部配置流程。
三、推理开发运行流程
使用MindStudio开发和运行推理业务步骤如下:
- 确定业务流程:根据业务功能如目标检测、图像分类、属性识别等,将业务流程进行模块化。
- 寻找合适插件:根据已有SDK插件的功能描述和规格限制来匹配业务功能,当SDK提供的插件无法满足功能需求时,用户可以开发自定义插件。
- 准备推理模型文件与数据:准备输入图片和下载模型,使用Model Convertor模型转换工具将模型转换为om格式。
- 流程编排:以可视化的方式,开发数据流图,生成pipeline文件供应用框架使用,配置文件以json格式编写,必须指定业务流名称、元件名称和插件名称,并根据需要,补充元件属性和下游元件名称信息。
- 业务集成:编写C++程序或Python程序,调用业务流管理的API(MxStreamManager),先进行初始化,再加载业务流配置文件(*.pipeline),然后根据stream配置文件中的StreamName往指定Stream获取输出数据,最后销毁Stream。
- 编译与运行应用:若新建的工程为Python版本的应用工程,不需要执行编译应用工程,配置Python环境后,即可在远端服务器运行;若新建工程为C++版本的应用工程,则需要进行远端编译,远端编译时,会对工程文件夹进行目录拷贝到远端连接的环境,编译成功后即可运行。
四、ShuffleNetV2Plus模型推理介绍
ShuffleNetV2Plus是一个轻量化的图片分类网络,我们下载其可参考源代码进行深入学习,该源码使用Pytorch框架实现,推理采用ImageNet数据集验证集。
在使用MindStudio进行MindX SDK应用开发前,我们已经完成了MindX SDK和MxBase的推理开发,且推理精度已达标。在进行推理开发的过程中,除了按需求编排流程外,最重要的就是图片的处理方式。根据源代码,我们发现在ShuffleNetV2Plus模型的验证部分中,图片的处理是基于PIL库的,为使推理精度达标,必须同样使用PIL库执行图片处理操作,而非opencv。
因此,针对MindX SDK,图像的解码、缩放、裁剪等操作需要在pipeline流程编排之外进行,即送入Stream的数据是已经处理好且解码完成的;针对MxBase,送入可执行程序的数据应该是处理后图像的bin类型文件。这一操作准则也同样适用于使用MindStudio的MindX SDK应用开发。
五、Python应用开发(可参考代码)
1. 创建MindX SDK应用工程
首先进入工程创建页面,若首次登录MindStudio,单击New Project;若非首次登录MindStudio,在顶部菜单栏中选择File > New > Project...。在New Project窗口中,选择Ascend App工程进行创建,创建工程配置如图9所示,一些参数说明如表3所示。
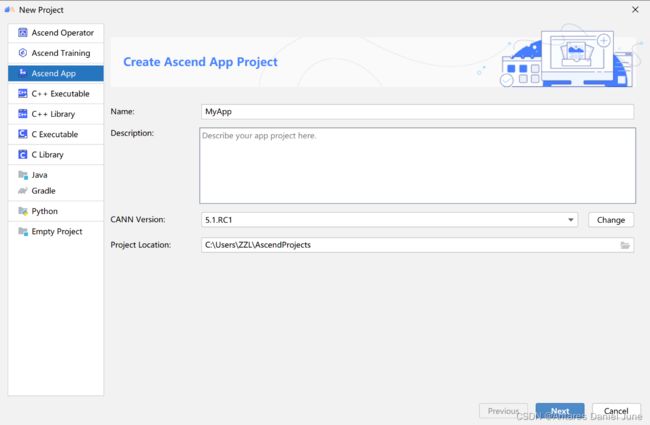
图9 创建工程配置
| 参数 |
说明 |
| Name |
工程名称必须以字母开头,以字母或数字结尾 |
| Description |
工程信息描述,自行配置 |
| CANN Version |
当前CANN版本,单击“Change”可重新配置CANN包的路径(详见“环境搭建与配置”中的“本地CANN安装”部分) |
| Project Location |
工程存储路径,可自定义 |
表3 Ascend App工程创建参数说明
信息填写完毕后,单击“Next”后进入工程模板类型选择页面,选择“MindX SDK Project (Python)”,如图10所示。随后点击“Finish”即可完成工程创建。
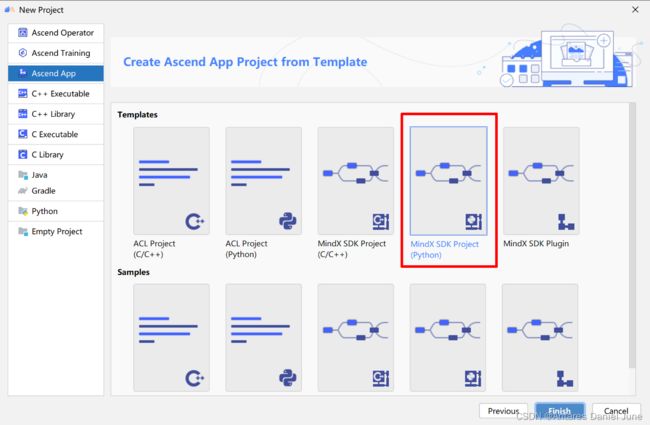
图10 Python工程模板类型选择
我们基于创建好的不含逻辑代码的空白工程进行Python应用开发,工程目录如图11所示。

图11 Python应用工程目录
如图11所示,除开发Python脚本和pipeline流程编排文件外,我们还需下载推理数据,即若干张ImageNet数据验证集图片,测试时可命名为“test.JPEG”,ImageNet标签文件也需要添加在“model”文件夹下。我们还需要准备ShuffleNetV2Plus模型的om文件,om模型文件由pth>onnx>om转换而来,pth模型文件可在ModelZoo网站上下载,并使用脚本转换为onnx格式,onnx>om转换流程在“模型转换”部分介绍。
2. 模型转换
- 步骤1
在菜单栏选择“Ascend > Model Converter”,打开模型转换页面,在“Model Information”页签中上传模型文件,加载成功后,会自动填充下列参数信息,如图12,一些参数介绍如表4所示。
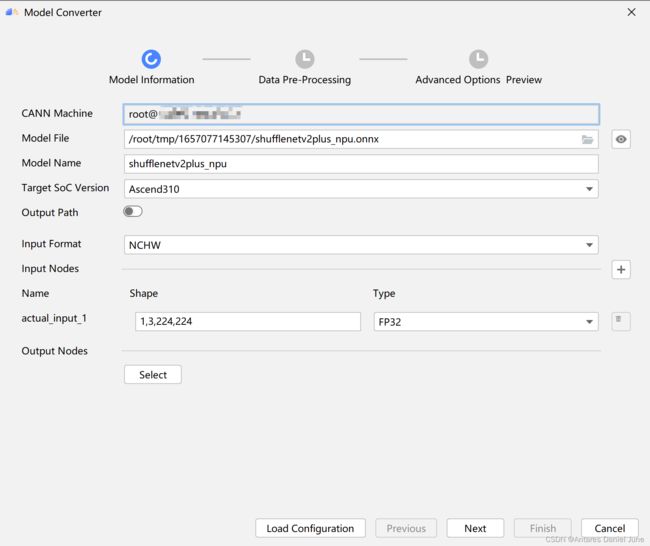
图12 Model Information页
| 参数 |
说明 |
| Model File |
onnx模型文件地址,建议上传到CANN包所在的远端环境 |
| Model Name |
模型名称 |
| Target SoC Version |
模型转换时指定芯片版本,使用310芯片 |
| Input Format |
输入数据格式,使用默认NCHW |
| actual_input_1 |
转换ShuffleNetV2Plus模型时,输入Shape请使用1,3,224,224,输入Type请使用FP32 |
| Output Nodes |
指定输出节点信息,这里无需配置 |
表4 Model Information页签参数介绍
- 步骤2
单击“Next”,进入“Data Pre-Processiong”页面,无需操作,如图13。
图13 Data Pre-Processiong页
- 步骤3
单击“Next”,进入“Advanced Options Preview”页面,由于此模型在后期编写脚本时进行标准化处理,故不在此处的“Additional Arguments”参数中增加aipp文件命令,检查Command Preview有无错误即可,如图14。

图14 Advanced Options Preview页
- 步骤4
单击“Finish”开始模型转换,在MindStudio界面下方,“Output”窗口会显示模型转换过程中的日志信息,如果提示**Model converted successfully**,则表示模型转换成功。“Output“窗口会显示模型转换所用的命令、所设置的环境变量、模型转换的结果、模型输出路径以及模型转换日志路径等信息,如图15。
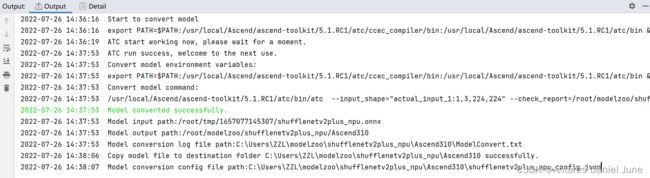
图15 模型转换输出信息
- 步骤5
转换完成的模型om文件生成在“$HOME/modelzoo”下,将其移动放置于“工程文件根目录/model”下。
3. pipeline流程文件编排
图片分类是推理应用开发中常见的功能,用户通过调用API,向推理业务发送图像,等待推理服务返回目标的坐标(目标检测插件输出)和图像分类结果。
由于ShuffleNetV2Plus模型的推理图片处理需要PIL库而非opencv,故不在pipeline中执行图片解码、缩放、裁剪等操作,因此编排的业务流程可简化为五个步骤:初始化>图片数据获取>图片分类>序列化>结果发送。如图16所示。

图16 pipeline可视化
各个元件的属性配置参数及插件的使用详见pipeline文件的代码,如图17所示。

图17 pipeline文件代码
4. Python脚本编写
Python脚本的编写是开发应用的重中之重,下面对main.py文件的代码详解。
1) 引入相关库(图18)
引入PIL库用于处理图片,引入StreamManagerApi包的相关方法,用于操作stream,引入MxpiDataType包,用于封装解码后的图片数据,便于送入pipeline。
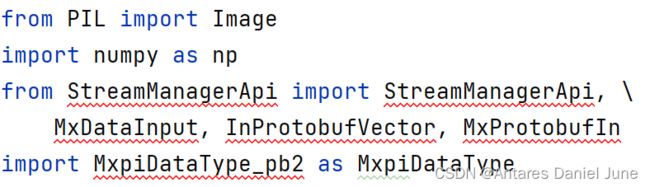
图18 引入相关库
2) 初始化stream(图19)

图19 初始化stream
3) 根据pipeline文件创建stream(图20)

图20 根据pipeline文件创建stream
4) 构建stream输入数据
首先使用PIL库的Image.open方法读取测试图片,并使用resize方法将图片等比例缩放,保持最短边为256,如图21。

图21 图片缩放
其次对图片执行中心裁剪操作,裁剪大小为224×224,如图22。

图22 图片裁剪
然后将图片数据归一化、标准化,并使用transpose方法调整图片的shape,将“高度、宽度、通道数”的shape转换为“通道数、高度、宽度”,与模型输入维度保持一致,如图23。

图23 图片归一化与标准化
接着,我们使用mxVision套件提供的MxpiDataType.MxpiVisionList()方法和InProtobufVector()方法构建向量protobuf_vec作为stream的输入数据,该向量包括了图片的尺寸(224×224)和图片的二进制数据的属性,如图24。这个向量时无需其他处理,可以直接送进stream走pipeline流程的。

图24 构建向量protobuf_vec
5) 根据stream名称和已经获得的图片数据向量,使用SendProtobuf()方法,将数据输入进特定的stream,即执行pipeline流程(图25)

图25 根据stream名称将数据输入进特定的stream
6) 通过stream名称和SendProtobuf()方法的返回值uniqueId获取图片推理结果,并输出到控制台(图26)
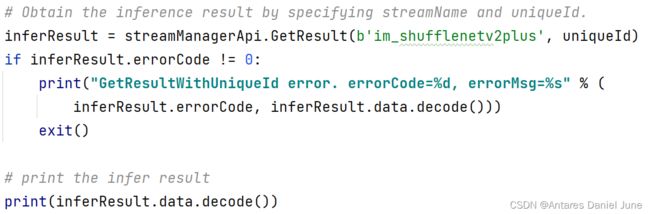
图26 通过stream名称和SendProtobuf()方法返回值uniqueId获取图片推理结果
7) 销毁stream,推理结束(图26)

图27 销毁stream
5. Python脚本应用运行
1) 配置Python解释器
在顶部菜单栏中选择File > Project Structure,在Project Structure窗口中,点击Platform Settings > SDKs,点击上方的“+”添加Python SDK,从本地环境中导入Python3.9,如图28。
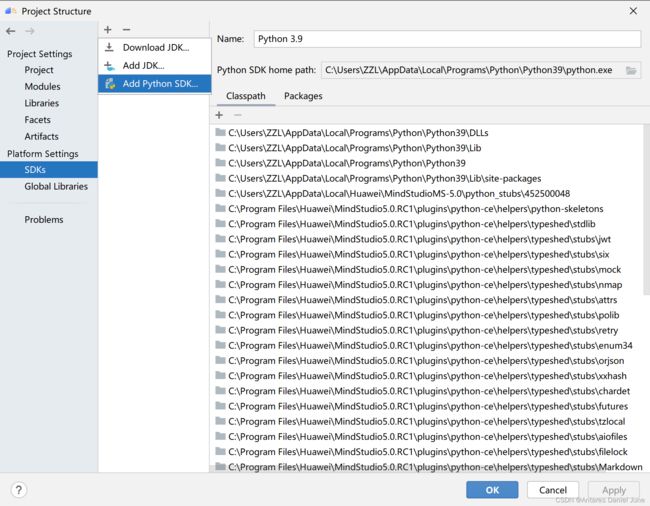
图28 添加Python SDK
然后,点击Project Settings > Project,选择上一步添加的Python SDK,如图29。
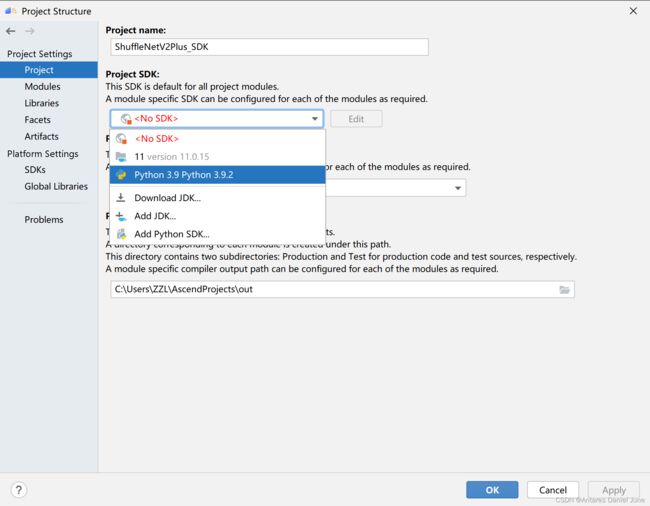
图29 添加Project SDK
接着,点击Project Settings > Modules,选中此项目,点击“+”后选择Python,为Python Interpreter选择上述添加的Python SDK,如图30。
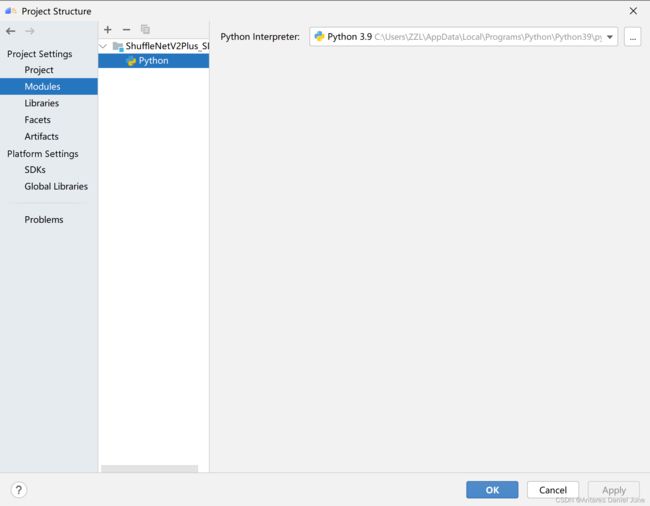 图30 添加Module SDK
图30 添加Module SDK
点击OK完成应用工程Python SDK配置。
2) 配置运行参数
在MindStudio工程界面,依次选择“Run > Edit Configurations...”,进入运行配置页面。选择“Ascend App > 工程名”配置应用工程运行参数,图31为配置示例。配置完成后,单击“Apply”保存运行配置,单击“OK”,关闭运行配置窗口。
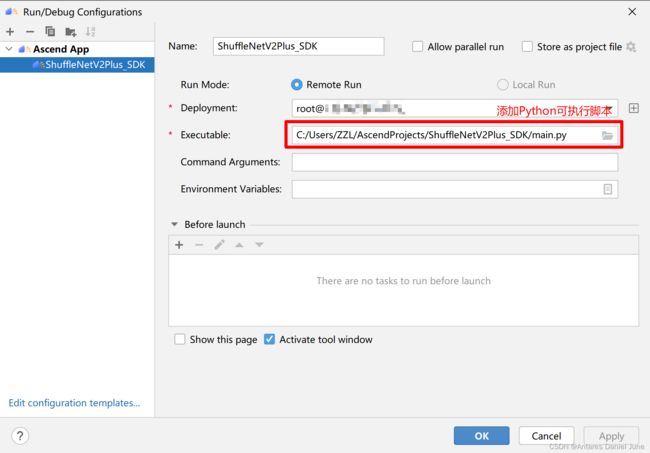
图31 运行参数配置
3) 运行应用

图32 测试图片输入
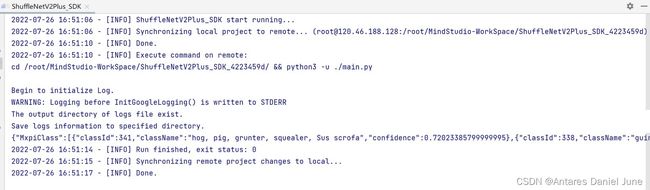
图33 分类结果输出(图片推理为猪)
根据运行成功日志可见,图片分类结果与事实相符,应用输出结果正确。
六、C++应用开发(可参考代码)
1. 创建MindX SDK应用工程
C++应用开发的创建工程步骤与Python应用基本一致,这里不再过多赘述。需要说明的是,在选择工程模板时,选择C++应用即可,如图34。
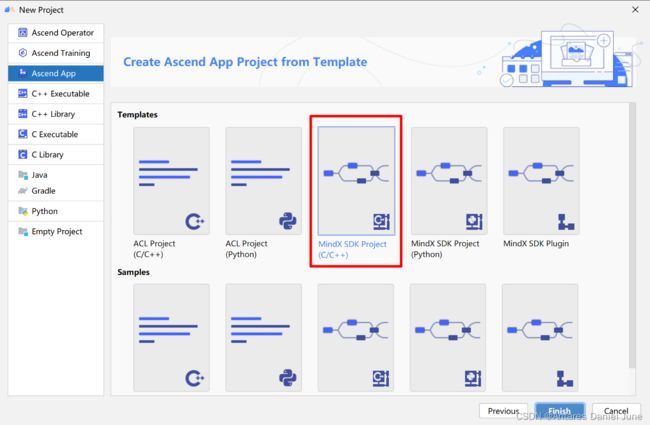
图34 C++工程模板类型选择
我们基于创建好的不含逻辑代码的空白工程进行C++应用开发,工程目录如图35所示。
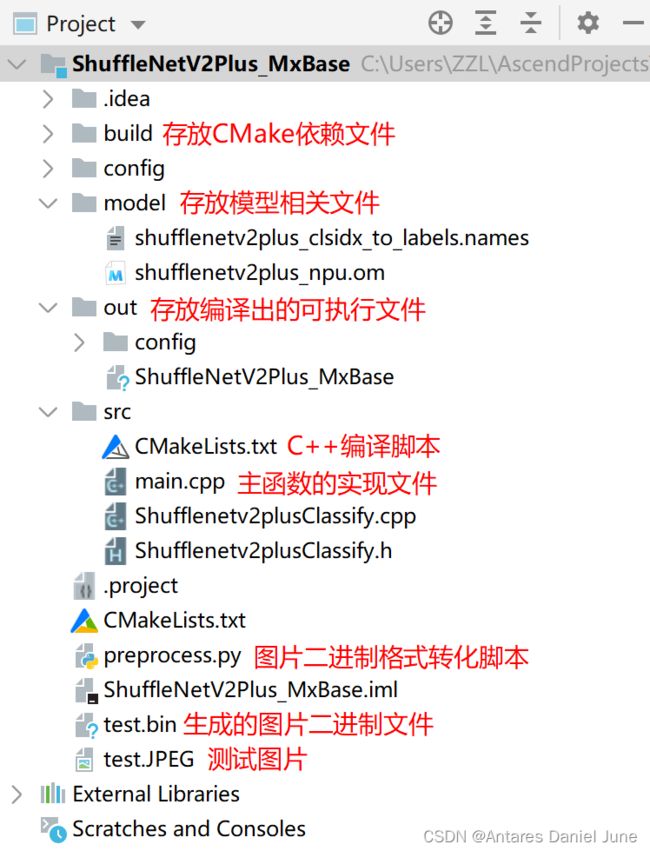
图35 C++应用工程目录
如图35所示,在“src”文件夹下,我们不只开发了main.cpp主函数源文件,我们编写头文件Shufflenetv2plusClassify.h用于声明类和函数原型,编写源文件Shufflenetv2plusClassify.cpp实现头文件中已经声明的那些函数的具体代码,并在main.cpp主函数源文件中调用源文件Shufflenetv2plusClassify.cpp中的相关函数,从而实现模型的推理。
除开发图片处理脚本以及“src”文件夹中的C++编译脚本、主函数实现文件和其他函数类文件外,我们还需下载推理数据,即若干张ImageNet数据验证集图片,测试时可命名为“test.JP EG”,ImageNet标签文件也需要添加在“model”文件夹下。我们还需要准备ShuffleNetV2Plus模型的om文件,在上面的“Python应用开发”部分,om模型文件的转换已经做了详细阐述,这里不做赘述,直接将已经生成好的om’模型文件拷贝到“model”文件夹下即可。
2. 图片处理脚本preprocess.py
由于ShuffleNetV2Plus模型的推理图片处理需要PIL库,且只有在Python脚本中才能调用此库,因此我们编写了一个Python脚本,作用是在运行可执行C++文件前对图片进行预处理,执行缩放、裁剪、解码等操作,并输出bin文件,供C++可执行文件读取。
图片处理脚本preprocess.py主要分为以下几个步骤:
- 步骤1:导入依赖库
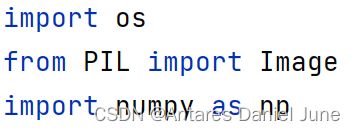
图36 导入依赖库
- 步骤2:图片读取与缩放

图37 图片读取与缩放
- 步骤3:图片裁剪

图38 图片裁剪
- 步骤4:图片归一化、标准化与维度转换

图39 图片归一化、标准化与维度转换
- 步骤5:bin文件输出

图40 bin文件输出
上述preprocess.py脚本的图片处理步骤,与Python应用开发中main,py脚本中的图片处理部分基本一致,这里不做赘述。
3. 头文件Shufflenetv2plusClassify.h
Shufflenetv2plusClassify.h头文件包含了类的声明(包括类里面的成员和方法的声明)、函数原型、#define常数等。其中,#include类及#define常数如图41所示;定义的初始化参数结构体InitParam如图42所示;类里面的成员和方法的声明如图43所示。

图41 #include类及#define常数

图42 初始化参数结构体InitParam
 图43 类里面的成员和方法的声明
图43 类里面的成员和方法的声明
4. 源文件Shufflenetv2plusClassify.cpp
Shufflenetv2plusClassify.cpp源文件的开头#include了要实现的头文件,以及其他要用到的头文件,如图44。

图44 #include头文件
Shufflenetv2plusClassify.cpp源文件的主体部分主要实现了头文件中已经声明的那些函数的具体代码,下面对这些函数的实现进行详解。
1) Init初始化
Init函数以在头文件中声明结构的InitParam为参数,初始化DeviceManager、ModelInferenceProcessor、Resnet50PostProcess等服务,为模型推理做准备,如图45、46。
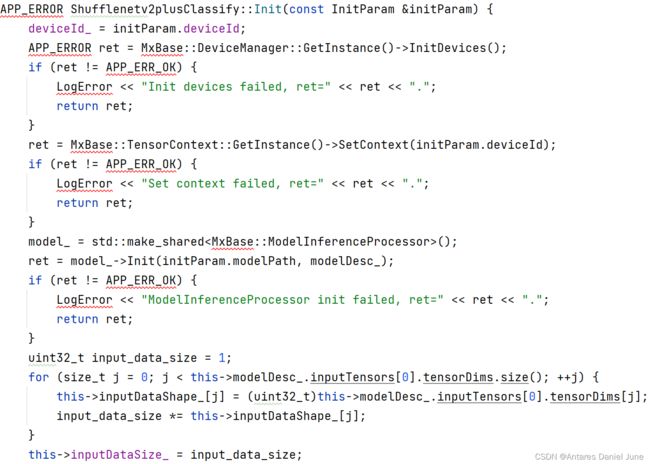
图45 Init(1)

图46 Init(2)
2) ReadTensorFromFile从bin文件读取数据(如图47)
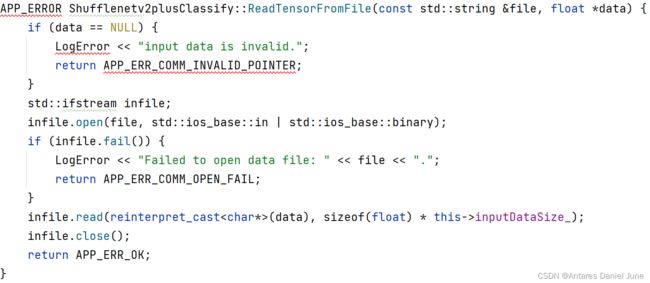
图47 ReadTensorFromFile
3) ReadInputTensor生成输入张量
调用ReadTensorFromFile函数,从图片的bin格式文件读取数据,根据输入数据的大小,在内存中分配合适的空间,并使用TensorBase方法生成输入张量inputs,如图48。
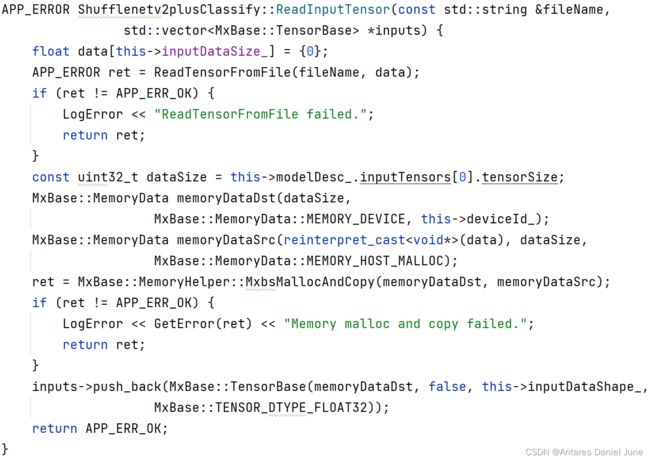
图48 ReadInputTensor
4) Inference推理
声明输出outputs,将inputs作为参数,调用ModelInference方法执行推理过程,如图49。
 图49 Inference
图49 Inference
5) PostProcess后处理
由于mxVision套件已经提供了Resnet50PostProcess后处理类,且Resnet50与本模型相近皆为图像分类模型,因此后处理过程调用Resnet50PostProcess后处理类中的方法即可,如图50。
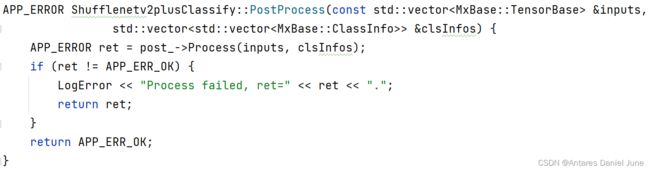
图50 PostProcess
6) ShowResult结果展示(如图51)
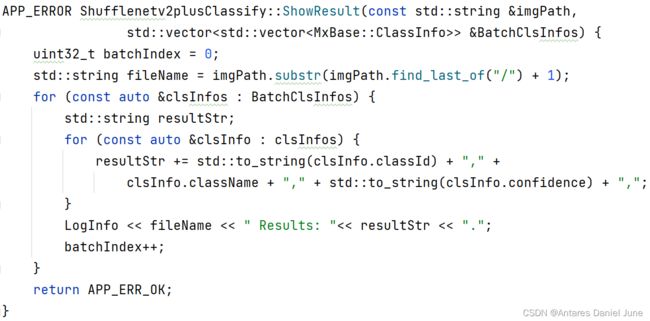
图51 ShowResult
7) Process流程编排
根据以上实现的源文件函数,按照“读取图片并生成输入张量>模型推理>后处理>输出结果”的流程编排编写Process函数,如图52。
 图52 Process
图52 Process
8) DeInit终止
模型推理结束后,终止DeviceManager、ModelInferenceProcessor、Resnet50PostProcess等服务,如图53。
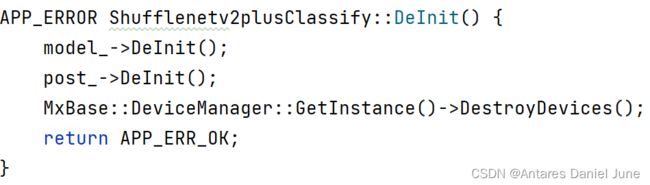
图53 DeInit
5. 主函数源文件main.cpp
完成Shufflenetv2plusClassify的头文件和源文件编码后,即可根据应用的整体推理流程编写main.cpp源文件。
首先,#include头文件Shufflenetv2plusClassify.h和其他需要头文件,如图54。
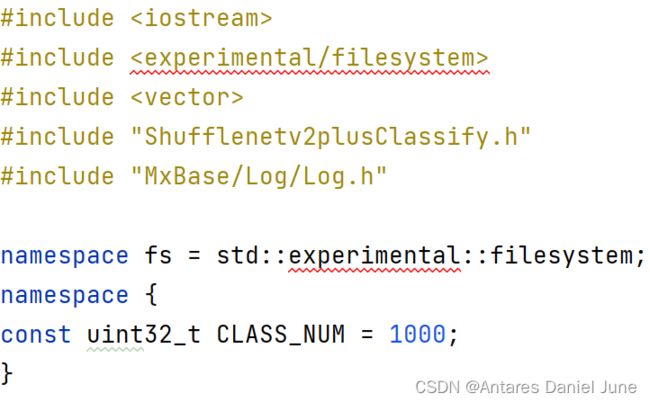
图54 #include头文件Shufflenetv2plusClassify.h和其他需要头文件
其次,开始编写main函数,声明并赋值initParam变量,配置模型路径和图像标签路径等重要参数,如图55。
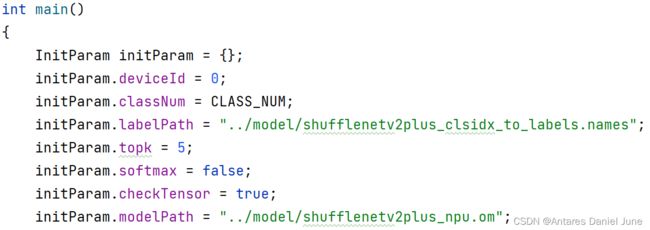
图55 声明并赋值initParam变量
接着,继续完善main函数,使用make_shared构造Shufflenetv2plusClassify数据对象,以此调用Init(以InitParam为参数)、Process(以图像bin文件路径为参数)、DeInit三个函数,执行模型推理操作,如图56。 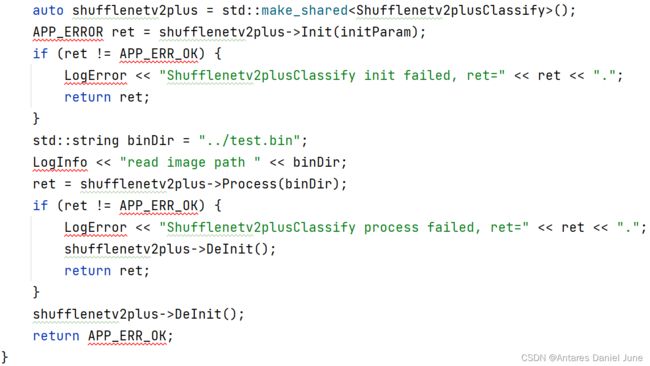
图56 执行模型推理操作
至此,main.cpp主函数实现文件编写完成,下面即可展开编译和运行操作。
6. C++应用编译
1) 编写编译脚本
在编译前,我们需要在“src”文件夹下编写CMakeLists.txt编译脚本。在编译脚本中,需要指定CMake最低版本要求、项目信息、编译选项等参数,并且需要指定特定头文件和特定库文件的搜索路径。除此之外,要说明根据main.cpp和Shufflenetv2plusClassify.cpp两个源文件生成ShuffleNetV2Plus_MxBase可执行文件,同时需要指定可执行文件的安装位置,即“out”文件夹下。
2) 配置编译环境
在MindStudio工程界面,依次选择“Build > Edit Build Configuration”,进入编译配置页面,如图57,配置完成后单击“OK”保存编译配置。
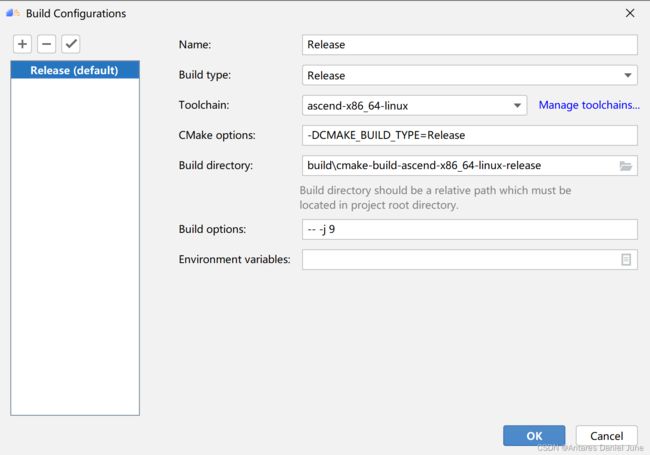
图57 编译配置页面
3) 执行编译
单击“Build”编译工程。如果在编译过程中无错误提示,且编译进度到“100%”,则表示编译成功,如图58。
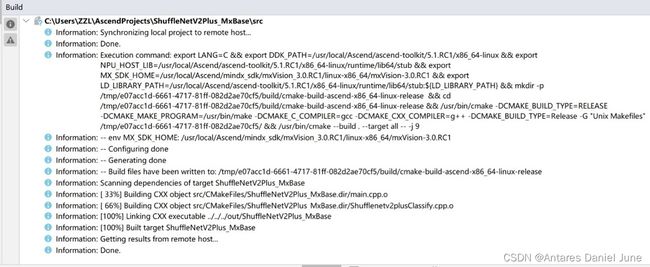
图58 编译成功
此时,编译成的可执行文件已经拷贝到了“out”文件夹下,用于应用运行。
7. C++可执行文件应用运行
1) 图像预处理脚本运行配置
首先将测试图片拷贝到工程目录下,命名为“test.JPEG”,如图59。

图59 test.JPEG
其次,在MindStudio工程界面,依次选择“Run > Edit Configurations...”,进入运行配置页面。选择“Ascend App > preprocess”配置图像预处理Python脚本运行参数,图60为配置示例。配置完成后,单击“Apply”保存运行配置,单击“OK”,关闭运行配置窗口。
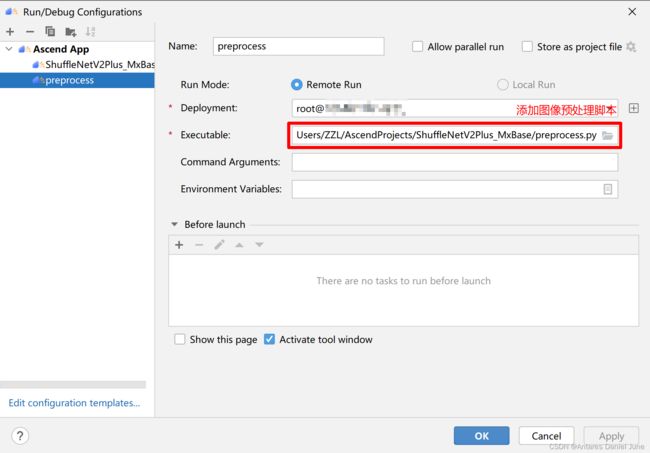
图60 图像预处理脚本运行参数配置
2) C++可执行文件运行配置
首先,在MindStudio工程界面,依次选择“Run > Edit Configurations...”,进入运行配置页面。选择“Ascend App > 工程名”配置应用工程运行参数,图61为配置示例。需要注意的是,除添加C++可执行文件外,还需在下方的“Before Launch”界面,选择“+ > Run Another Configuration > preprocess”,即设置运行C++可执行文件前先运行preprocess图像预处理脚本。配置完成后,单击“Apply”保存运行配置,单击“OK”,关闭运行配置窗口。

图61 C++运行参数配置
3) 应用运行
在MindStudio工程界面,依次选择“Run > Run...”,然后,在弹出框中选择已创建好的运行配置信息,运行应用。图62为图像预处理脚本输出结果,图63为C++应用运行的输出结果。
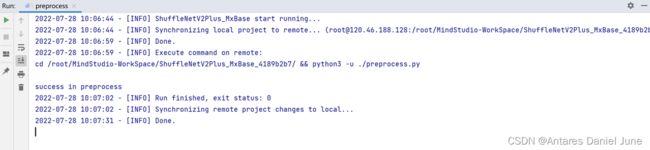
图62 图像预处理结果输出
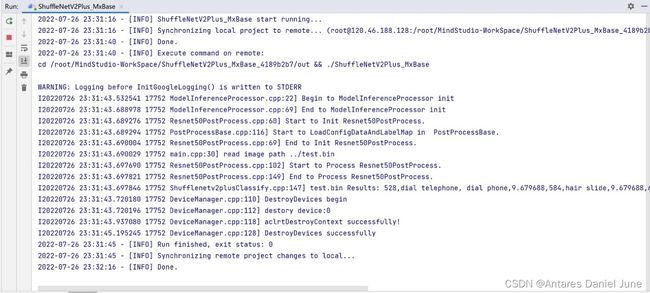
图63 分类结果输出(图片推理为电话)
根据运行成功日志可见,图片分类结果与事实相符,应用输出结果正确。
七、FAQ
1. MindStudio导入应用工程后,提示“No Python interpreter configured for the module”
解决方案:在顶部菜单栏中选择“File > Project Structure”,点击“Project Settings > Modules”,在“Dependencies”配置中配置“Module SDK”,选择一个Python 3.9的本地环境,如图64。
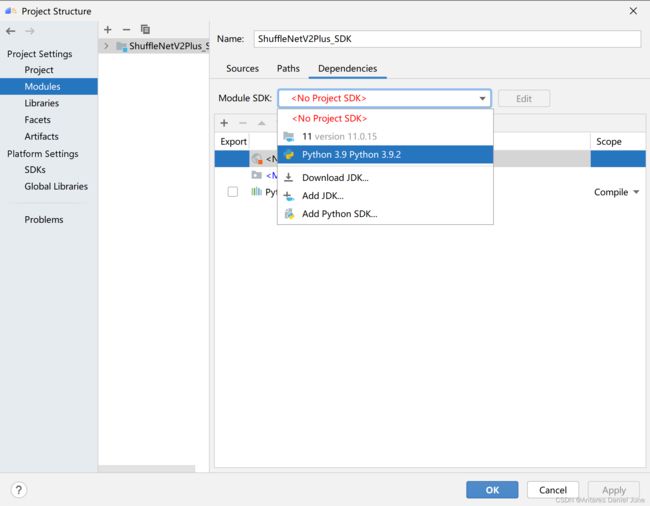
图64 FAQ-1
2. SDK版本获取失败
解决方案:SDK远端地址为“usr/local/Ascend/mindx_sdk/mxVision_3.0.RC1/linux-x86_64/mxVision-3.0.RC1”,若选择同名父路径,则会报错“Get mindx sdk version failed!”,如图65。
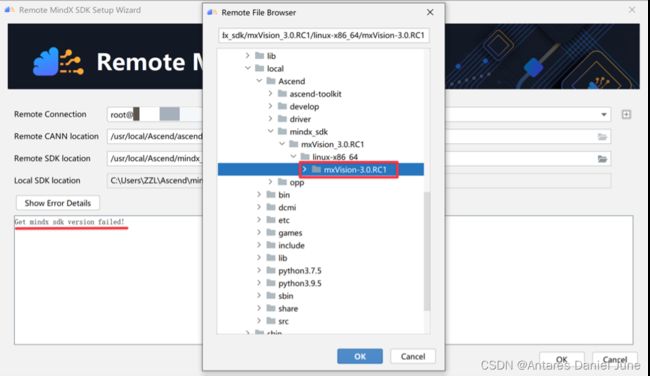
图65 FAQ-2
3. om模型文件运行报错
解决方案:在模型转换的时,模型的输入Type默认值为FP16,我们需要将其修改为FP32,如图66。
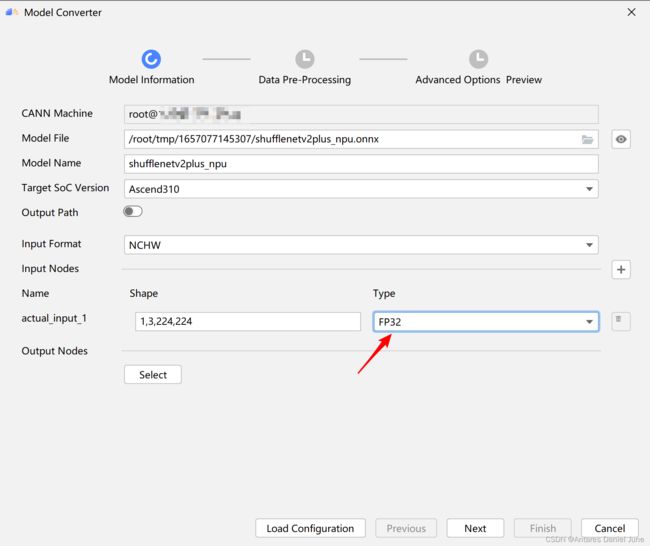
图66 FAQ-3
4. 相对路径非法,找不到相关文件
解决方案:针对Python应用,在pipeline流程编排中,相对路径需要使用相对main.py脚本文件位置的相对路径,而不是相对于pipeline文件的相对路径;针对C++应用,相对路径需要使用相对可执行文件生成位置的相对路径,修改cpp文件或h文件后,需要重新编译成可执行文件,修改才能生效。
八、从昇腾社区获得更多帮助
开发者在使用MindStudio进行应用开发过程中遇到任何问题,可以登录MindStudio昇腾论坛获得更多的帮助。