【译】二进制代码相似性综述
原文:https://dl.acm.org/doi/pdf/10.1145/3446371
参考:https://zhuanlan.zhihu.com/p/436870873
目录
- 1. 简介
- 2. 概述
-
- 2.1 编译过程
- 2.2 二进制相似性
- 3. 论文选择范围
- 4. 应用
- 5. 二进制相似性演化
- 6. 方法
-
- 6.1 比较类型
- 6.2 粒度
- 6.3 句法相似性
- 6.4 语义相似性
- 6.5 结构相似性
- 6.6 基于特征的相似性
- 6.7 哈希
- 6.8 支持跨架构
- 6.9 分析类型
- 6.10 规范化
- 7. 实现
- 8. 评估
-
- 8.1 数据集
- 8.2 方法
- 9. 讨论
1. 简介
论文分析了 70 种二进制代码相似性方法,这些方法在四个方面进行了系统化:
1. 它们支持的应用程序
2. 它们的方法特征
3. 这些方法是如何实现的
4. 用于评估的基准和方法
此外,该调查还讨论了该领域的范围和起源、过去二十年的演变以及未来的挑战。
二进制代码相似性方法比较两段或多段二进制代码,例如基本块、函数或整个程序,以识别它们的异同。 在程序源代码不可用的情况下,比较二进制代码是基础,这种情况发生在商业现货 (COTS) 程序、遗留程序和恶意软件中。
二进制代码相似性具有广泛的实际应用程序,例如错误搜索,恶意软件聚类 , 恶意软件检测, 恶意软件谱系, 补丁生成 , 补丁分析, 移植信息跨程序版本和软件盗窃检测。
| Application | Research |
|---|---|
| Bug Search | [1] [2], [3], [4], [5],[6], [7], [8], [9], [10], [11], [12], [13], [14], [15] |
| malware clustering | [16], [17], [18] |
| malware detection | [19], [20], [21] |
| malware lineage | [22], [23], [24] |
| patch generation | [25] |
| patch analysis | [26], [27], [28], [29], [8], [30], [31] |
| porting information across program versions | [32], [26], [27] |
| software theft detection | [33] |
识别二进制代码相似性具有挑战性,因为编译过程会丢失很多程序语义,包括函数名称、变量名称、源注释和数据结构定义。即使程序源代码没有改变,如果重新编译源代码,由于编译过程引入的二次更改,二进制代码也可能发生变化。 例如,当使用不同的编译器、更改编译器优化以及选择不同的目标操作系统和 CPU 架构时,生成的二进制代码可能会发生显著变化。 此外,混淆转换可以应用于源代码和生成的二进制代码,隐藏原始代码。
鉴于其应用和挑战,在过去的 22 年中,已经提出了许多二进制代码相似性方法。然而,据我们所知,尚无对该研究领域的系统调查。以前的调查涉及打包工具中的二进制代码混淆技术 [101]、二进制代码类型推断 [14] 和动态恶意软件分析技术 [37]。这些主题是相关的,因为二进制代码相似性可能需要解决混淆问题,二进制代码类型推断可能会利用相似的二进制分析平台,并且恶意软件通常是二进制代码相似性方法的目标。但是二进制代码相似性与这些主题很好地分开,如先前的调查所示,与本文分析的论文集没有重叠。
其它调查已经探索了对任何二进制数据的相似性检测,不特定于代码,例如用于相似性搜索的散列 [115] 以及数字和二进制特征向量的相似性度量 [16, 107]。相比之下,本调查侧重于比较二进制代码的方法,即反汇编可执行字节流。
2. 概述
2.1 编译过程
二进制代码是指由编译过程产生的机器代码,可以直接由 CPU 运行。 标准编译过程将程序的源代码文件作为输入,它使用选定的编译器和优化级别并针对特定平台(由体系结构、字长和操作系统定义)编译它们,从而生成目标文件。 然后将这些目标文件链接到一个二进制程序,一个独立的可执行文件或一个库。
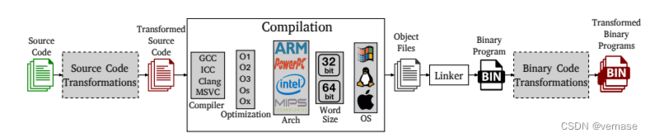
二进制代码相似性方法通常处理扩展编译过程,如图 1 所示,它在标准编译过程中添加了两个可选步骤:源代码和二进制代码转换。 这两种类型的转换通常都是语义保留(即不改变程序功能)并且最常用于混淆(即阻碍分布式二进制程序的逆向工程)。
- 源代码转换发生在编译之前。 因此,它们的输入和输出都是源代码。 无论目标平台如何,它们都可以应用,但可能特定于用于编写程序的编程语言。
- 二进制代码转换发生在编译之后。 因此,它们的输入和输出是二进制代码。 它们独立于所使用的编程语言,但可能特定于目标平台。
混淆是恶意软件的一个基本步骤,但也可以应用于良性程序,例如,保护它们的知识产权。存在使用源代码转换(例如,Tigress [21])和二进制代码转换(例如,打包程序 [112])的现成混淆工具。打包是恶意软件广泛使用的二进制代码转换。一旦恶意软件系列的新版本准备就绪,恶意软件作者就会打包生成可执行文件以隐藏其功能,从而绕过商业恶意软件检测器的检测。打包过程将一个可执行文件作为输入,并生成另一个具有相同功能的可执行文件,但隐藏了原始代码(例如,加密为数据并在运行时解包)。打包过程通常多次应用于相同的输入可执行文件,创建完全相同的源代码的多态变体,这对于恶意软件检测器来说看起来不同。如今,大多数恶意软件都被打包,恶意软件通常使用定制的打包器,而现成的解包器不可用 [112]。
二进制代码相似性的一个主要挑战是编译过程可以为相同的源代码生成不同的二进制代码表示。可以修改图 1 中的任何灰色框,以从相同的源代码生成不同但语义等效的二进制程序,其中一些修改可能是由于标准编译过程。例如,为了提高程序效率,作者可能会改变编译器的优化级别或完全改变编译器。尽管源代码保持不变,但这两项更改都将转换生成的二进制代码。作者还可以更改目标平台以获得适用于不同架构的程序版本。在这种情况下,如果新的目标架构使用不同的指令集,生成的二进制代码可能会完全不同。作者也可能故意应用混淆转换来产生相同源代码的多态变体。生成的变体通常具有由原始源代码定义的相同功能。二进制代码相似性方法的理想目标是它们能够识别对应于经过不同转换的相同源代码的二进制代码的相似性。二进制代码相似性方法的稳健性捕获了它可以处理的编译和混淆转换,即尽管它仍然可以检测到相似性的转换。
2.2 二进制相似性
二进制代码相似性方法比较二进制代码片段。 二进制代码相似性方法的三个主要特征是:
1. 比较的类型(相同、相似、等效)
2. 被比较的二进制代码片段的粒度(指令、基本块、函数)
3. 被比较的输入块的数量(一对一、一对多、多对多)
接下来我们详细介绍这三个特征。 为简单起见,我们描述了两个输入的比较类型和比较粒度,然后推广到多个输入。
1. 比较类型
如果两个(或更多)二进制代码具有相同的语法,即相同的表示,则它们是相同的。
二进制代码可以用不同的方式表示,例如原始字节的十六进制字符串、反汇编指令序列或控制流图。确定几段二进制代码是否相同是一个易于检查的布尔决策(它们是否相同):只需将加密哈希(例如,SHA256)应用于每段的内容。如果散列相同,则片段相同。然而,这种简单的方法在许多情况下都无法检测到相似性。例如,使用不同的编译参数(即编译器、编译器版本、优化级别、目标平台)两次编译相同的程序源代码,会产生功能相似的二进制代码,但具有不同的哈希值。即使所有编译参数都相同,生成的可执行文件也会有不同的文件哈希。发生这种情况是因为可执行文件可能包含在两种编译中不同的元数据,例如编译日期,它会自动计算并包含在生成的可执行文件的标头中。
如果两个二进制代码具有相同的语义,即如果它们提供完全相同的功能,则它们是等效的。等价不关心二进制代码的语法。显然,两段相同的二进制代码将具有相同的语义,但不同的二进制代码段也可能具有相同的语义。例如, mov %eax,$0 和 xor %eax,%eax 在语义上是等效的 x86 指令,因为它们都将寄存器 EAX 的值设置为零。类似地,为两个不同的目标架构编译的相同源代码应该产生等效的可执行文件,如果架构使用不同的指令集,其语法可能完全不同。但是请注意,语义等价超出了从相同源代码编译的二进制代码。例如,同一加密算法的两种不同实现在语义上应该是等价的。证明两个任意程序在功能上是等价的是一个不可判定的问题,它可以简化为解决停止问题[72]。在实践中,确定二进制代码等价是一个非常昂贵的过程,只能对小段二进制代码执行。
如果两段二进制代码的语法、结构或语义相似,则可以认为它们是相似的。
句法相似性比较代码表示。例如,克隆检测方法认为目标二进制代码是一些源二进制代码的克隆,如果它们的语法相似的话。
结构相似性比较二进制代码的图形表示(例如,控制流图、调用图)。它介于句法和语义相似性之间。直觉是二进制代码的控制流在某种程度上捕获了它的语义,例如,对数据做出的决定。此外,图形表示捕获相同功能的多个句法表示。但是,可以在不影响语义的情况下修改图结构,例如,通过内联函数。
语义相似性比较代码功能。语义相似性的一种简单方法是通过操作系统 (OS) API 或系统调用来比较程序与其环境之间的交互。但是具有相似系统或 API 调用的两个程序仍然可以实现显着不同的功能,例如,通过不同地处理系统调用的输出,因此更细粒度的语义相似性方法侧重于代码的语法独立比较。
一般来说,二进制代码相似性方法越稳健,即它可以捕获的转换越多,它的成本就越高。
- 句法相似性方法的计算成本最低,但鲁棒性最低。它们对二进制代码中的简单更改很敏感,例如,寄存器重新分配、指令重新排序、用语义等效的指令替换指令。
- 结构相似性位于中间。它对多种句法转换具有鲁棒性,但对更改代码结构的转换(例如代码内联或删除未使用的函数参数)敏感。
- 尽管代码语法和结构发生了变化,但语义相似性对于保留语义的转换是健壮的,但是对于大量二进制代码来说计算成本非常高。
2. 比较粒度。
二进制代码相似性方法可以应用于不同的粒度。 常见的粒度是指令、基本块、函数和整个程序。 为了在更粗粒度上进行比较,一些方法在更细粒度上使用不同的比较,然后组合更细粒度的结果。例如,为了比较两个程序是否相似,一种方法可以确定两个程序之间相同功能的比例。 因此,我们区分输入粒度,即方法比较的输入二进制代码的粒度,和方法粒度,即方法中不同比较的粒度。
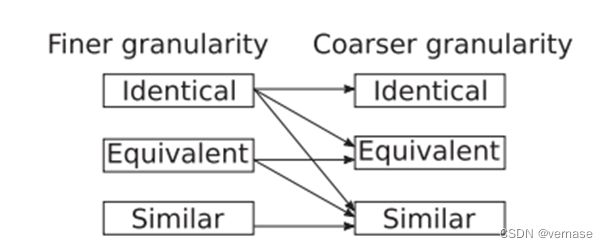
以更细粒度应用特定比较可能会限制可以以更粗粒度执行的比较类型,如图 2 所示。该图显示了在更细粒度(例如,基本块)可用于计算包含它们的较粗粒度片段(例如,它们的功能)是相同的、等效的或相似的。 然而,较细粒度的相似性不能用于推断较粗粒度的代码是等价的或相同的。 例如,在比较两个函数时,仅仅因为它们的基本块都相似,并不能断定它们的函数是相同或等价的。 另一方面,相似性是最普遍的比较类型,任何更细粒度的比较类型都可以用来推断它。
3. 输入数量
二进制代码相似性方法可以比较两段或多段二进制代码。 比较两个以上的部分可以进一步分为将一个部分与其余部分进行比较或将每个部分与所有其他部分进行比较。 因此,我们根据输入的数量以及它们的比较方式确定了三种类型的方法:一对一 (OO)、一对多 (OM) 和多对多 (MM)。 输入片段的来源取决于应用程序。 它们可能来自同一个程序版本(例如,同一个可执行文件的两个函数),来自同一个程序的两个版本,以及来自两个不同的程序。
一对一方法将原始二进制代码(也称为源代码、旧代码、原告代码或参考代码)与目标二进制代码(也称为新代码、补丁代码或升级代码)进行比较。 大多数 OO 方法执行二进制代码差异; 即,它们区分同一程序的两个连续或接近的版本,以识别在目标(修补)版本中添加、删除或修改的内容。二进制代码diffing的粒度通常是一个函数,diffing试图获得原始程序版本中的一个函数和目标程序版本中的另一个函数之间的映射。 添加的函数是不能映射到目标函数的原始函数; 移除的函数是不能映射到原始函数的目标函数; 和修改后的函数是不相同的映射函数。
一对多方法将查询的二进制代码段与许多目标二进制代码段进行比较。 大多数 OM 方法执行二进制代码搜索; 即,他们搜索查询片段是否与任何目标片段相似,并返回前 k 个最相似的目标二进制代码片段。 目标片段可能来自同一程序的多个版本(不同于查询的版本),来自相同架构编译的不同程序,或来自不同架构编译的程序。
与 OO 和 OM 方法相比,多对多方法不区分源片段和目标片段。 所有输入部分都被认为是相等的并相互比较。
这些方法通常执行二进制代码聚类; 即,它们输出称为集群的相似二进制代码组。
3. 论文选择范围
为了使我们对最先进技术的调查保持集中和易于管理,重要的是在范围内定义什么是,什么不是。 总的来说,主要的限制是我们专注于比较二进制代码的工作。 反过来,此限制引入了以下四个约束:
1. 我们排除了需要访问源代码的方法,即源到源(例如,[61])和源到二进制(例如,[131])相似性方法。
2. 我们排除了对字节码进行操作的方法(例如,[18, 23])。
3. 我们排除了通过系统调用或 OS API 调用专门比较程序与其环境交互相似性的行为方法(例如,[6,20,45,68])
4. 我们排除了将二进制代码视为原始字节序列的字节级方法没有诸如文件哈希(例如,[120])、模糊哈希(例如,[69, 89])和基于签名的方法(例如,[74, 86])之类的结构。
需要考虑的是,方法需要将原始字节分解为指令。 虽然我们不包括描述字节级的论文方法,我们确实通过分析的二进制代码相似性方法检查了一些字节级技术(例如模糊散列)的使用。
此外,我们引入了以下约束以保持调查范围的可管理性:
5. 我们将调查限制在同行评审场所发表的论文和学术机构的技术报告中。 因此,我们不分析工具,而是描述他们的方法的研究工作(例如,BinDiff 的 [36, 44])。
6. 我们排除了那些没有提出新的二进制代码相似性方法或技术而只是应用现成的二进制代码相似性工具作为实现其目标的步骤的论文。
论文选择
为了确定候选论文,我们首先系统地检查了过去 22 年在计算机安全和软件工程的 21 个顶级场所发表的所有论文。所选场地对应
- 14个会议(IEEE S&P、ACM CCS、USENIX Security、NDSS、ACSAC、RAID、ESORICS、ASIACCS、DIMVA、ICSE、FSE、ISSTA、ASE、MSR)
- 7个期刊(ACM CSUR、IEEE TIFS、IEEE TDSC、ACM TOPS、爱思唯尔 COSE、IEEE TSE 和爱思唯尔 JSS)
并非所有相关的二进制代码相似性方法都已在这些场所发布,这对于早期方法尤其如此。为了识别其他领域的候选论文,我们使用与二进制代码相似性及其应用相关的术语(例如代码搜索、二进制差异、错误搜索)广泛查询专业搜索引擎,例如 Google Scholar。我们还仔细检查了候选论文的参考文献,以查找我们可能遗漏的任何其他论文。这次探索确定了 100 多篇候选论文。然后,我们阅读每篇候选论文,以确定他们是否提出了满足上述范围限制的二进制代码相似性方法。
最后,我们在表 1 中确定了 70 个二进制代码相似性研究工作,其方法是系统化的。表 1 的前三列包含方法名称、出版年份和作品出版地点。研究工作按出版日期排序,创建了该领域发展的时间表。论文由其系统名称(如果有)标识,否则由每个作者姓氏的首字母和出版年份标识。 70篇论文已在41个地点发表。在 70 篇入选作品中,只有 9 篇发表在期刊上,这 9 篇中的 7 篇(BMAT [119]、BMM2007 [13]、ScalClone [41]、BinGold [3]、libv [95]、CoP2017 [80]、BinGo -E [128])是以前发表的论文的扩展版本。二进制代码相似性是多学科的;虽然大多数论文出现在计算机安全领域(21 个领域的 39 篇论文),但也有软件工程(8 个领域的 15 篇论文)、系统(4 个领域的 6 篇论文)和机器学习(2 个领域的 2 篇论文)的作品。与二进制代码相似度最高的论文是 DIMVA (6)、ASE (4)、CCS (3)、USENIX Security (3)、NDSS (3) 和 PLDI (3)。

4. 应用
本节通过描述二进制代码相似性所支持的应用程序来激发二进制代码相似性的重要性。在分析的 70 篇论文中,有 42 篇展示了一项应用,即对至少一项应用进行定量评估或案例研究。其他 28 篇论文提出了可用于多种应用的通用二进制代码相似性功能,例如二进制差异工具(例如 [7、24、32])、二进制代码搜索平台(例如 [65、71、122])、和二进制相似性检测方法(例如,[33、40、41、55、105])。表 2 总结了确定的八种应用。 42 篇论文中的大多数都展示了单个应用程序,尽管少数(例如 F2004、BinSeqence)展示了多个应用程序。应用程序的一个属性是它是否比较同一程序的不同版本(补丁分析、补丁生成、移植信息、恶意软件谱系)或不同程序(恶意软件集群、恶意软件检测、软件盗窃检测),或者可以应用于这两种情况(错误搜索)。接下来,我们详细介绍这些应用程序。
-
错误搜索——可以说,
二进制代码相似性最流行的应用是在大型目标二进制代码存储库中查找已知错误[17, 25–28, 39, 42, 43, 48, 56, 77, 92 , 93, 109, 125, 128]。 由于代码重用,相同的代码可能会出现在多个程序,甚至是同一程序的多个部分。 因此,当发现错误时,识别可能重复使用错误代码并可能包含相同或相似错误的类似代码非常重要。 错误搜索方法将查询错误的二进制代码片段作为输入,并在存储库中搜索相似的二进制代码片段。 这个问题的一个变种是跨平台错误搜索,其中可以针对不同平台(例如 x86、ARM、MIPS)编译存储库中的目标二进制代码 [17、26、27、39、42、43、 77、92、125、128]。 -
恶意软件检测——
通过将给定的可执行文件与一组先前已知的恶意软件样本进行比较,可以使用二进制代码相似性来检测恶意软件。如果相似度很高,那么输入样本很可能是先前已知的恶意软件家族的变种。 许多恶意软件检测方法是纯粹的行为,比较系统或 API调用行为(例如,[45, 68])。 然而,如第 3 节所述,我们专注于计算二进制代码相似度的方法 [12,15,70]。 -
恶意软件聚类——
恶意软件检测的一个演变是将相似的、已知的恶意可执行文件聚集到家族中。 每个家族集群都应该包含来自同一恶意程序的可执行文件,这些可执行文件可以是恶意程序的不同版本,也可以是一个版本的多态(例如,打包)变体。与恶意软件检测类似,我们专注于比较二进制代码 [52] 并排除基于系统调用和网络流量的纯行为方法(例如 [6,91,96])。 -
恶意软件谱系——
给定一组已知属于同一程序的可执行文件,沿袭方法构建一个图,其中节点是程序版本,边捕获程序跨版本的演变。 沿袭方法对恶意软件最有用,因为版本信息通常不可用 [51、58、75、84]。 由于输入样本应属于同一家族,因此恶意软件谱系通常建立在恶意软件聚类的结果之上。 -
补丁生成和分析——最早的二进制代码相似性应用程序,也是最流行的应用程序之一,
是区分同一程序的两个连续或接近的版本,以识别在较新版本中修补了什么。 这对于供应商不披露补丁细节的专有程序最有用。 差异结果可用于生成小的二进制代码补丁,这些补丁可以有效地运送以更新程序 [5]。 它们还可用于自动识别修复漏洞的安全补丁 [127],分析这些安全补丁 [35、36、44、47、54、56、64],并为旧的易受攻击的版本生成漏洞利用 [11]。 -
移植信息——二进制代码相似性可用于在同一程序的两个相近版本之间移植信息。 由于关闭版本通常共享大量代码,因此为一个版本所做的分析可能在很大程度上可重用于较新版本。 例如,早期的二进制代码相似性方法移植了分析数据 [118, 119] 和在恶意软件逆向工程期间获得的分析结果 [36, 44]。
-
软件盗窃检测——
二进制代码相似性可用于识别未经授权重用来自原厂程序的代码,例如源代码被盗、其二进制代码被重用、专利算法未经许可重新实现或违反许可 (例如,商业应用程序中的 GPL 代码)。 检测此类侵权的早期方法使用软件胎记,即捕获原告程序固有功能的签名 [19, 85]。 然而,如第 3 节所述,我们排除了基于签名的方法,而专注于使用二进制代码相似性的方法 [79, 80]。
5. 二进制相似性演化
本节描述了二进制代码相似性的起源及其在过去 22 年中的演变,重点介绍了一些值得注意的方法。
1. 起源
二进制代码相似性的根源在于生成补丁(或增量)的问题,该补丁(或增量)捕获同一程序的两个连续(或接近)版本之间的差异。文本差异工具自 1970 年代就存在(流行的 UNIX 差异于 1974 年发布)并已集成到早期的源代码版本控制系统中,例如 SCCS [100] (1975) 和 RCS [111] (1985)。低带宽通信网络(例如无线)的日益普及以及某些设备中的资源有限引起了人们对通过传输捕获二进制(即非文本)文件的两个版本之间差异的小补丁来提高效率的技术的兴趣,而不是传输整个文件。 1991 年,Reichenberger 提出了一种差异技术,用于在不了解文件结构的情况下在任意二进制文件之间生成补丁 [99]。该方法在字节级别而不是文本差异的行级别粒度上工作,并有效地识别应该出现在补丁中的字节序列,因为它们只出现在更新版本中,因此在要修补的原始文件中不可用。很快出现了几种用于生成和应用二进制补丁的工具,例如 RTPatch [103]、BDiff95 [22] 和 xDelta [121]。这些工具在字节级别工作,可以区分任何类型的文件。
第一个二进制代码相似性方法是从 1999 年开始的。那一年,Baker 等人提出了一种压缩可执行代码差异的方法,并构建了一个名为 Exediff [5] 的原型差异工具,该工具为 DEC Alpha 可执行文件生成补丁。他们的直觉是,区分同一程序的两个可执行版本时的许多更改代表了由于编译过程造成的二次更改,而不是源代码中的直接更改。他们提到的一个例子是在重新编译时可能会改变的寄存器分配。他们提到的另一个例子是,在较新版本中添加的代码会替换部分旧代码,因此编译过程必须调整替换代码中的指针值以指向正确的地址。他们的想法是在补丁时重建二次更改,这样它们就不需要包含在补丁中,从而减小了补丁大小。 Exediff 是我们发现的最早的方法,它专注于计算二进制代码之间的相似性,通过将原始字节分解为指令来利用代码结构。
同样在 1999 年,Wang 等人。 提出了 BMAT [118],这是一种对齐 Windows DLL 库可执行文件的两个版本的工具,以将配置文件信息从旧(广泛分析)版本传播到新版本,从而减少重新分析的需要。 他们的方法是首先比较函数和基本块(Exediff 比较了两个指令序列),它首先匹配两个可执行文件中的函数,然后匹配每个匹配函数中的相似块。 它使用散列技术来比较块,散列删除了重定位信息以处理指针更改,但对顺序敏感。
2. 第一个十年
在 Exediff 和 BMAT 的初步工作之后,我们在接下来的十年(2000-2009)中只确定了七种二进制代码相似性方法。 然而,其中一些非常有影响力,因为它们将二进制代码的相似性从纯粹的句法扩展到还包括语义; 它们将范围从二进制代码差异 (OO) 扩大到还包括二进制代码聚类 (MM) 和二进制代码搜索 (OM)。他们将二进制代码相似性应用于恶意软件。
2004 年,Thomas Dullien(别名 Halvar Flake)提出了一种基于图的二进制代码差异方法,该方法通过启发式地构建一个调用图同构来关注代码的结构属性,该方法将同一二进制程序的两个版本中的函数对齐[44]。 这是在某些编译器优化引入的函数中处理指令重新排序的第一种方法。 后续工作 [36] 扩展了该方法以匹配函数内的基本块(如在 BMAT 中所做的那样),并引入了小素数乘积(SPP)哈希来识别相似的基本块,尽管指令重新排序。 这两部作品是 Ida 反汇编器 [7] 中流行的 BinDiff 二进制代码差异插件的基础。
2005 年,Kruegel 等人 [70] 提出了一种图形着色技术来检测恶意软件的多态变体。 这是第一种执行语义相似性和MM比较的方法。 他们将具有类似功能的指令分为 14 个语义类。 然后,他们使用这些类为过程间控制流图 (ICFG) 着色,图着色对于诸如垃圾插入、指令重新排序和指令替换等句法混淆具有鲁棒性。 2008 年,高等人。 提出 BinHunt [47] 来识别同一程序的两个版本之间的语义差异。这是第一种检查代码等效性的方法。它使用符号执行和约束求解器来检查两个基本块是否提供相同的功能。
2009 年,胡等人提出了 Smit [52],这是一种给定恶意软件样本的方法,可以在存储库中找到类似的恶意软件。 Smit 是第一个 OM 和二进制代码搜索方法。 它索引数据库中的恶意软件调用图,并使用图编辑距离来查找具有相似调用图的恶意软件。
3. 过去十年
在过去的十年(2010-2019 年),二进制代码相似性的流行度有了巨大的提升,已经确定了 52 种方法。 这十年的重点是二进制代码搜索方法,自 2015 年以来重点关注其跨架构版本(17 种方法),以及近年来的机器学习方法。 2013 年,魏等人提出了 Rendezvous,一个二进制代码搜索引擎,给定查询函数的二进制代码,在存储库中查找具有相似语法和结构属性的其他函数。 将搜索粒度从整个程序 (Smit) 减少到更小的二进制代码片段(例如函数)可以实现一系列应用程序,例如克隆检测和错误搜索。大多数二进制代码搜索方法都针对错误搜索应用程序。
- Jang 等人在 2012 年首次在源代码上解决了这个应用程序。 [57]。 2014 年,David 和 Yahav 提出了 Tracy [28],这是第一个专注于 bug 搜索的二进制代码搜索方法。
- Tracy 使用 tracelets(CFG 中的执行路径)的概念来查找类似于易受攻击函数的函数。
- 2015 年,Pewny 等人。提出了 Multi-MH [92],这是第一个跨架构二进制代码搜索方法。多 MH 索引函数按其输入输出语义。给定为一个 CPU 架构(例如 x86)编译的函数,Multi-MH 可以找到为其他架构(例如 MIPS)编译的类似函数。由于嵌入式设备的普及,这个问题很快引起了人们的关注。
- 2016 年,Lageman 等人 [71] 训练了一个神经网络来决定两个函数是否是从相同的源代码编译的。从那时起,神经网络的使用有所回升,例如 Gemini (2017)、αDiff (2018)、InnerEye (2019)、Asm2Vec (2019) 和 DeepBinDiff (2020)。
6. 方法
6.1 比较类型
本节讨论方法输入之间的比较类型,以及该方法可能使用的更细粒度的比较。
1. 输入比较
分析的所有 70 件作品都会比较它们的输入以识别相似性。 也就是说,没有任何方法可以识别相同的输入(因为哈希就足够了)或输入等价,因为这是一个无法确定的问题 [130],只能有效地解决小段二进制代码。 因此,我们根据输入比较将二进制代码相似性方法分类为一对一(OO,27 种方法)、一对多(OM,32 种方法)和多对多(MM,11 种方法) . OM 方法的主导地位是由于过去十年对二进制代码搜索的高度兴趣。
始终可以从 OO 方法构建 OM 或 MM 方法。 例如,一个OM 方法的简单实现是比较给定的查询段二进制代码n 个目标中的每一个都使用返回两个输入之间相似性的 OO 方法。只需通过降低相似度对 n 个目标进行排名,并返回前 k 个条目或高于相似度阈值的条目。然个进行比较。然而大多数 OM 方法都避免了这种简单的实现,因为它效率低下。提高性能的两个主要解决方案是从每个输入中提取特征向量,并将目标二进制代码片段存储在带有索引的存储库中。为每个输入获取一个特征向量允许每个输入只执行一次特征提取。当特征提取成本很高时,这提供了显着的好处,例如,在 Blex 的情况下,其特征提取需要使用不同的输入多次执行一段二进制代码。一旦提取了特征向量,就使用两个特征向量之间的相似度度量。由于特征向量通常是数字或布尔值,因此该相似性度量通常计算成本较低。一个常见的混淆来源是一些方法提出了相似性指标,而另一些提出了距离指标。重要的是要记住,当指标在 0 和 1 之间归一化时,距离只是 1 减去相似度。 OM 方法使用的另一个解决方案是在特征向量中的特征子集上添加索引。通过仅在输入的二进制代码的特征向量和更可能相似的选定目标的特征向量之间应用相似性度量,索引可用于减少比较次数。
2. 方法比较
大多数方法使用单一类型的比较:相似性(48 种方法)、等价性(5)和相同(2)。 请注意,即使仅使用一种类型的比较在该方法中,它可能与输入比较不同。 例如,Exediff 在区分两个程序的过程中寻找相同的指令。 有 15 种方法以不同的粒度使用多种比较类型。 其中,八个使用更细粒度的相同比较来快速识别相同的二进制代码片段(BMAT、DR2005、SWPQS2006、BinClone、ScalClone)或减少昂贵的比较,例如图同构(Smit,西班牙)。 其他七个使用更细粒度的等价比较来捕获语义相似性。
6.2 粒度
输入粒度: 函数 > 程序 > 基本块
方法粒度: 函数 > 基本块
最常见的输入粒度是函数(30 种方法),然后是整个程序(28)和相关的基本块(4)。 整个程序是 OO 方法 (19/27) 的首选输入粒度,因为大多数二进制代码差异方法都试图在输入程序中的所有函数之间建立一对一的映射,对于 MM (6/11) 方法也是 倾向于聚类输入程序。 另一方面,函数是二进制代码搜索方法 (23/32) 的首选粒度。 另外四种二进制代码搜索方法使用 B* 来识别仅覆盖函数子集或跨越函数边界的代码重用。
最常见的方法粒度是函数(22 种方法),然后是基本块(13)。 大多数方法 (50/70) 使用不同的输入和方法粒度,即使用更精细的方法粒度来比较更粗略的输入粒度。 大多数具有相同输入和方法粒度的方法都执行函数搜索 (10/15)。 执行等价比较的 11 种方法由于效率低而以细粒度进行:6 个具有 B 粒度,5 个具有 I* 和 1 个 F。一些方法以细粒度累积特征,这些特征从未直接比较,因此不会显示在方法粒度列。 例如,Gemini 累积基本块特征以在函数粒度上生成数值向量。 因此,仅比较函数。
6.3 句法相似性
句法方法捕获代码表示的相似性,更具体地说,它们比较指令序列。 最常见的是,序列中的指令在虚拟地址空间中是连续的,属于同一个函数。 序列中的指令可以首先被规范化,例如,只考虑助记符,只考虑操作码,或者将操作数规范化为类。 我们在 6.10 节中详细介绍了指令规范化,并在本小节的其余部分中简单地参考了指令序列。
指令序列可以是固定或可变长度的。固定大小的序列是通过在指令流上滑动窗口来获得的,例如,在函数中的线性排序指令上。这个过程的特点是窗口大小,即序列中的指令数,以及步幅,即滑动窗口起点以产生下一个序列的指令数。当步幅小于窗口大小时,连续序列重叠。当步幅为 1 时,生成的序列称为 n-gram。例如,给定指令助记符序列 {mov,push, add},将提取两个 2-gram:{mov,push} 和 {push, add}。有七种作品使用了 n-gram:Idea、MBC、Rendezvous、MutantX-S、Exposé、iLine 和 Kam1n0。他们使用的n-gram在如何表示指令方面有所不同,例如,使用指令的操作码或其助记符,如第 6.10 节所述,以及 n-gram 的大小。早期作品使用二元组(例如 Idea、MBC),但后来的作品使用三元组(例如 Exposé)或 4 元组(例如 iLine)。一些作品(Rendezvous,MutantX-S)评估多个 n-gram 大小使用 4-gram 实现最佳结果。 SWPQS2006 也使用固定大小的序列,其可配置的步幅大于 1。集合点,除了 n-gram,还使用 n-perms,无序 n-gram,捕获序列中的指令重新排序。一个 n-perm 可以捕获多个 n-gram;例如,2-perm {mov,push} 捕获 2-gram {mov,push} 和 {push,mov}。
比较指令序列的最常用方法是散列、嵌入和对齐。
- 七种方法(BMAT、DR2005、SWPQS2006、Smit、BinClone、Spain、BinXary)使用散列从可变长度指令序列中获取固定长度值。 如果哈希值相同,则序列相似。
- 五种方法从 n-gram 序列生成嵌入(Idea、MBC、MutantX-S、Exposé、Kam1n0)。
- 三种方法(Exediff、Tracy、BinSeqence)对齐两个序列,通过在任一序列中插入间隙来生成它们之间的映射,以解释插入、删除和修改的指令。 这些方法定义了指令对齐时的相似性分数,以及指令与间隙对齐时的间隙分数。
其他不太常见的比较方法是使用布尔特征向量 (iLine) 和编码序列作为索引字符串 (Rendezvous)。
6.4 语义相似性
语义相似性捕获被比较的代码是否具有相似的功能,而不是句法相似性捕获代码表示中的相似性。在极限情况下,如果两个二进制代码提供完全相同的功能,则它们在语义上是等效的。语义等效代码的示例是从完全相同的源代码编译的二进制代码片段,例如,通过改变编译选项或目标平台,假设编译链是语义保留的。但是,从不同源代码编译的代码可能在语义上是等价的,例如,同一加密算法的两种不同实现。具有相同语法的代码在语义上是等价的,但是具有相似但不完全相同的语法的代码可能具有非常不同的语义。例如,一个将两个整数作为输入并返回它们的乘法的函数在语法上与一个将两个整数作为输入并返回它们的除法的函数非常相似,但它们的语义完全不同。我们确定了 27 种计算语义相似度的方法。使用三种方法来捕获语义:将指令或系统/API/库调用语义合并到结构或句法比较、符号公式和输入-输出对中。
-
结合语义。计算语义相似度的一种基本方法是将语义信息(例如指令类型和代码执行的系统/API/库调用)添加到结构或句法相似度方法中。
- 将语义引入二进制代码相似性的第一种方法是 KKMRV2005,它将指令分为 14 类(例如算术、逻辑、数据传输),并使用14位值来捕获基本块中指令的类别。这个语义颜色位向量捕获基本块的效果。这种方法后来被 BMM2006、BMM2007、Beagle、Fossil、Sigma 和 BinGold 采用。此外,BinGo 和 BinGo-E 使用类似的方法,尽管指令类别不同。
- 其他方法包含有关由基本块执行的系统/API调用(Beagle、Sigma、BinGold、BinGo、BinSim、IMF-sim、BinGo-E)和库调用(Blex、BinGo、CACompare、BinGo-E)序列的信息或一个函数。
这种基本的语义相似性方法有助于区分具有相似语法或结构但语义明显不同的代码。但是,它无法确定两段二进制代码是否相等。
-
符号公式。符号公式是一个赋值语句,其中左侧是输出变量,右侧是输入变量和文字的逻辑表达式,用于捕获如何导出输出变量。例如,指令add %eax,%ebx可以用符号公式EBX2 = EAX + EBX1来表示,其中EBX2和EBX1是表示指令执行前后EBX寄存器值的符号。
-
十一种方法使用符号公式:BinHunt、iBinHunt、BinHash、Exposé、Tracy、RMKNHLLP2014、Tedem、CoP、Multi-MH、Esh 和 Xmatch。
其中,八种方法以基本块粒度提取符号公式 Xmatch 和 Exposé 为函数的返回值提取公式 BinSim 从捕获系统调用参数如何派生的执行跟踪中提取符号公式
符号公式的比较使用了三种方法:使用定理证明器检查等价,比较公式的语义哈希以检查等价,以及计算公式的图形表示的相似性。
-
定理证明器——BinHunt 引入了使用STP [46] 或 Z3 [30] 等定理证明器来检查两个符号公式是否等价的想法,即,在两个公式执行后,输出变量是否总是包含相同的值,假设输入变量共享相同的值。每段二进制代码可能有多个输出(内存中的寄存器和变量),每个输出都由其自己的输入变量符号公式表示。这些方法需要计算输出公式的所有成对比较之间的等价性,以确定所有输出公式等价的输入变量之间是否存在双射映射。这种方法的主要限制是计算量很大,因为它需要计算多个成对等价查询,求解时间会随着公式大小而迅速增加,并且对于某些查询,求解器可能无法在分配的时间内返回答案。
-
语义散列——
使用定理证明器的另一种方法是在对公式进行规范化(例如,使用通用寄存器名称)和简化它们(例如,应用常量传播)之后检查两个符号公式是否具有相同的散列。直觉是,如果两个符号公式具有相同的哈希,它们应该是等价的。 三种方法使用语义哈希:BinHash、BinJuice 和 GitZ。 语义哈希比使用求解器更有效,但其局限性在于它们可能会产生误报。 特别是,即使在标准化和简化之后,两个等效公式也可能具有不同的哈希值。 例如,公式之一中符号项的重新排序(例如,由于指令重新排序)会导致不同的散列。 -
图距离——Xmatch 和 Tedem
将基本块的符号公式表示为树,并通过应用图/树编辑距离来计算它们的相似度。计算图/树编辑距离比比较语义散列更昂贵,但图表示比语义散列具有优势,它可以处理术语重新排序。 -
输入输出对。直观地说,
如果给定相同的输入,对于所有可能的输入,两段二进制代码在功能上是等效的。这种等价性独立于代码表示,并在代码执行后比较最终状态,忽略中间程序状态。这种方法是由 Jiang 和 Su 在源代码 [59] 上提出的,后来被许多二进制代码相似性方法使用:BinHash、MXW2015、Blex、Multi-MH、BinGo、BinGo-E、CACompare、Spain、KS2017 和 IMF-sim。它涉及使用相同的输入执行两段二进制代码并比较它们的输出,重复该过程多次。如果任何输入的输出不同,则这两个二进制代码不等价。不幸的是,要确定这两个部分是等价的,该方法需要测试所有可能的输入,这对于任何重要的二进制代码都是不现实的。因此,在实践中,这种方法只能确定两段二进制代码可能等价,置信度与已测试输入的比例成正比,或者它们不等价(确定地)。测试的输入通常是随机选择的,尽管可以使用其他选择规则,例如,从程序数据部分 (CACompare) 中获取值。计算输入-输出对通常是一种动态方法,但一些方法(例如 Multi-MH)在静态提取的符号公式上评估具体输入。
6.5 结构相似性
结构相似性计算二进制代码图形表示的相似性。 它位于句法和语义相似性之间,因为图可以捕获同一代码的多个句法表示,并且可以用语义信息进行注释。
可以在不同的图上计算结构相似性。最常见的三个是过程内控制流图 (CFG)、ICFG 和调用图(CG)。 这三个都是有向图。
- 在 CFG 和 ICFG 中,节点是基本块,边表示控制流转换(例如,分支、跳转)。 CFG中的基本块属于单个功能; 每个函数都有自己的CFG。 ICFG 中的基本块属于任何程序功能;每个程序有一个ICFG。
- 在 CG 中,节点是函数,边捕获调用者-被调用者关系。
结构化方法背后的直觉是 CG、ICFG 和 CFG 是相当稳定的表示,其结构对于相似代码几乎没有变化。 对 CG 或 ICFG 进行操作的方法具有整个程序输入粒度,而对 CFG 进行操作的方法可能具有函数粒度或使用函数相似性作为实现整个程序相似性的一步。 结构相似性方法可以使用标记图。 例如,F2004 和 DR2005 使用 CG 中的节点标签来捕获有关函数 CFG 的结构信息(例如,指令和边的数量)。 其他方法使用特征向量标记 CFG/ICFG 中的基本块,该特征向量捕获基本块的语义(例如,KKMRV2005、BinJuice、eepBinDiff)或其嵌入(Genius、Gemini,参见第 6.6 节)。 边缘标签可用于捕获控制流传输的类型(BMM2006、BMM2007)或聚合源节点和目标节点的语义标签(Fossil)。
结构相似性被 34 种方法使用。 十七种方法仅适用于 CFG; ICFG 上只有六个; CFG 和 CG 上都有 5 个; 还有两个只在CG上。 还有四种使用非标准图的方法:Sigma 提出了一种语义集成图,它结合了来自 CFG、CG 和寄存器流图的信息,而 QSM2015 和 libv 使用执行依赖图 [132]。
本小节的其余部分讨论用于计算图相似度的不同方法。
-
(子)图同构。大多数结构相似性方法检查图同构的变化。两个图 G 和 H 的同构是它们节点集之间的保边双射 f 使得如果任何两个节点 u、v 在 G 中相邻,则 f (u) 和 f (v) 在 H 中也是相邻的。同构要求两个图中的节点集基数相同,这对于二进制代码相似性来说过于严格。因此,方法改为检查子图同构,它确定 G 是否包含与 H 同构的子图。子图同构是一个已知的 NP 完全问题。其他方法检查最大公共子图同构 (MCS),它找到与两个图同构的最大子图,并且也是 NP完全。
鉴于这两个问题的高度复杂性,方法试图减少需要比较的图对的数量,以及比较图的大小。例如,DR2005 避免比较具有相同散列(匹配)的 CFG 和具有非常不同数量的节点和边(不太可能匹配)的 CFG。
iBinHunt通过将污点标签分配给基本块来减少要考虑的节点数量。在子图同构中只考虑具有相同污点标签的节点。对于通过过滤的候选图对,使用可分为贪心和回溯的近似算法。 -
贪婪——这些方法执行邻域探索。 首先识别一组初始匹配节点。 然后,通过仅检查已匹配节点的邻居(即父母或孩子)递归地扩展匹配。 BMAT、F2004、DR2005、LKI2013、Tedem、MultiMH、KLKI2016、Kam1n0、BinSeqence、BinArm 和 BinXary 使用这种方法。 贪心算法的一个限制是早期错误会传播,从而显着降低准确性。
-
回溯 ——回溯算法通过重新访问解决方案来修复错误匹配,如果新匹配没有改善整体匹配,则将其还原(BMM2006、BMM2007、BinHunt、iBinHunt、MXW2015、QSM2015、libv、discovRE)。 回溯可以通过避免局部最优匹配来提高准确性,但成本更高。
-
优化。 四种方法(Smit、BinSlayer、CXZ2014、Genius)使用的替代方法是将图相似性建模为优化问题。 给定两个 CFG 和两个基本块之间的成本函数,他们发现两个 CFG 之间具有最小成本的双射映射。 这种二分匹配忽略了图结构,即不使用边缘信息。 为了解决这个问题,Smit 和 BinSlayer 为连接的基本块分配了较低的成本。 为了执行匹配,Smit、BinSlayer 和 CXZ2014 使用 O(n3) 匈牙利算法,而 Genius 使用遗传算法。
K-子图匹配。 KKMRV2005提出将一个图划分为k-子图,每个子图只包含k个连通节点,然后为每个k-子图生成指纹; 两个图的相似度对应于匹配的最大 k 子图数。 后来有四种其他方法利用了这种方法:Beagle、CXZ2014、Rendezvous 和 Fossil。 -
路径相似度。 有六种方法(CoP、CoP2017、Sigma、BinGold、BinSeqence、BinXary)可以将函数相似度转换为路径相似度比较。 首先,他们从 CFG 中提取一组执行路径,然后定义执行路径之间的路径相似度度量,最后将路径相似度组合成函数相似度。
-
图嵌入。 Genius、VulSeeker 和 Gemini 使用的另一种方法(详见 6.6 节)是从每个图中提取一个实值特征向量,然后计算特征向量的相似度。
6.6 基于特征的相似性
计算相似度的常用方法(30 种方法)是将一段二进制代码表示为一个向量或一组特征,使得相似的二进制代码段具有相似的特征向量或功能集。
特征捕获二进制代码的句法、语义或结构属性。特征可以是布尔值、数字或分类。分类特征具有离散值,例如指令的助记符。特征向量通常具有所有数字或所有布尔特征;后者称为位向量。分类特征通常首先使用 one-hot 编码编码为布尔特征,或使用嵌入编码为实值特征。在 30 种方法中,22 种使用数字特征向量,6 种使用特征集,BinClone 和 ScalClone 使用位向量。一旦特征被提取,特征向量或特征集之间的相似度度量就被用来计算相似度。常见的相似性度量是特征集的 Jaccard 索引、位向量的点积以及数值向量的欧几里德或余弦距离。

图 3 显示了基于特征的相似性的两种替代方法。
top方法包括两个步骤:特征选择和特征编码。
- 特征选择是一个手动过程,分析师使用领域知识来识别代表性特征。 另一种方法是学习从训练数据中自动生成实值特征向量,称为嵌入。 九种最近的方法(Genius、Gemini、αDiff、VulSeeker、RLZ2019、InnerEye、Asm2Vec、SAFE、DeepBinDiff)使用了嵌入。
- 嵌入用于自然语言处理 (NLP) 以使用实数值对分类特征进行编码,与单热编码相比,它通过降低维度和增加特征向量的密度来帮助机器学习算法。 嵌入支持自动特征提取和高效的相似度计算。 但是嵌入中的特征不提供关于所学内容的信息。
二进制代码相似性嵌入可以通过它们捕获的属性及其粒度进行分类。第一个使用嵌入的二进制代码相似性方法是 Genius,后来是 VulSeeker 和 Gemini。所有这三种方法都为函数的 ACFG 构建图嵌入,即一个 CFG其节点使用选定的基本块特征进行注释。 Genius 使用聚类和图形编辑距离来计算嵌入,而 VulSeeker 和 Gemini 通过训练避免昂贵的图形操作的神经网络来提高效率。后来的方法(αDiff、RLZ2019、InnerEye、Asm2Vec、SAFE、DeepBinDiff)通过关注指令或原始字节共现来避免手动选择特征。在 NLP 中,通常会提取一个捕获单词共现的词嵌入(例如 word2vec),然后构建一个基于它的句子嵌入。 RLZ2019 和 InnerEye 使用类似的方法,将指令视为单词,将基本块视为句子。 SAFE 使用类似的方法来创建函数嵌入。同样相关的是 Asm2Vec,它通过组合路径嵌入来获取函数嵌入,该路径嵌入捕获沿函数中不同执行路径同时出现的指令。 αDiff 不使用指令共现,而是使用卷积网络直接从函数原始字节计算函数嵌入。
机器学习。 我们确定了机器学习在二进制代码相似性方法中的三种用途:
- 如上所述生成嵌入
- 使用无监督学习(BinHash,MutantX-S,iLine,RMKNHLLP2014,KLKI2016, Genius)
- 对从相同源代码 (BINDNN, IMF-SIM) 编译的二进制代码片段进行分类。 BINDNN 是神经网络首次用于二进制代码相似性。 而不是生成嵌入,BinDnn 直接使用神经网络分类器来确定两个函数是否是从相同的源代码编译的。 令人惊讶的是,后来的二进制代码相似性方法(包括那些使用神经网络构建嵌入的方法)并未引用 BINDNN 。
6.7 哈希
哈希是将任意大小的数据映射到固定大小值的函数。哈希值存储紧凑、计算效率高、比较效率高,这使得它们非常适合索引。哈希在字节级别上运行。它们不是专门为二进制代码设计的,而是为任意二进制数据设计的。然而,三类散列已用于二进制代码相似性:加密哈希、局部敏感哈希和可执行文件哈希。
加密哈希捕获相同而不是相似的输入。一些二进制代码相似性方法使用它们来快速识别细粒度的重复项(例如,基本块)。局部敏感哈希会为相似的输入生成相似的散列值,而不是加密散列,输入中的微小差异会生成完全不同的散列值。可执行文件哈希将可执行文件作为输入,但哈希计算仅考虑可执行文件的部分内容,例如导入表或可执行文件头的选定字段。他们的目标是为同一恶意软件的多态变体输出相同的哈希值。
局部敏感散列(LSH)。 LSH 为相似的输入生成相似的哈希值,有效地逼近最近邻搜索。 LSH 算法通常对给定的输入应用多个哈希函数,并为相似的输入生成相同的哈希值; 即,它们增加了类似输入的碰撞概率。 LSH 用于二进制代码相似度以提高性能。 例如,OM 方法使用它来索引二进制代码片段,从而实现高效的二进制代码搜索(Kam1n0、Gemini、InnerEye)。 在使用 LSH 的 11 种方法中,7 种使用 MinHash [10](BinHash、Multi-MH、Genius、BinSeqence、BinShape、CACompare、BinSign),2 种没有指定使用的算法(Gemini、InnerEye),SWPQS2006 使用的算法是 Gionis 等人。 [50],Kam1n0 提出了自己的自适应局部敏感哈希(ALSH)。
模糊散列是一种流行的 LSH 类型,用于计算任意文件的相似性。例如,VirusTotal 文件分析服务 [114] 报告提交文件的 ssdeep [69] 哈希值。其他模糊哈希包括 tlsh [89]、sdhash [102] 和 mrsh-v2 [9]。 70 种方法都没有使用它们,但我们简要讨论它们,因为它们通常应用于可执行文件。当应用于可执行文件时,模糊散列可以捕获二进制代码的相似性,但也可以捕获可执行文件中存在的数据的相似性。 Pagani 等人最近研究了这个问题。 [90]。他们的结果表明,当仅应用于 .text 部分的代码时,它们的工作效果比用于整个程序相似性时要差得多。事实上,它们表明正确位置的字节更改、额外的 nop 指令和指令交换会显着降低相似性(在某些情况下会降低到零)。他们观察到,当用不同的优化编译相同的源代码时,可执行文件的数据部分保持不变,这似乎是模糊散列在整个可执行文件上工作得更好的关键原因。
可执行文件哈希。此类哈希是专门为可执行文件设计的。它们旨在为同一恶意软件的多态变体输出相同的哈希值。哈希计算仅考虑在简单地重新打包或重新签名相同的可执行文件时不太可能更改的可执行文件的部分。 70 种方法中的任何一种都没有使用它们,但为了完整起见,我们简要描述了三种流行的哈希。
- peHash [120] 对 PE 可执行文件的选定字段进行哈希处理,这些字段在编译和打包期间不易受更改影响,例如初始堆栈大小、堆大小。
- ImpHash 对可执行文件的导入表进行哈希处理。由于打包变体的功能是相同的,因此它们的导入功能也应该相同。不幸的是,如果加壳器在运行时重建原始导入表,它会给用同一个加壳器打包的不相关的可执行文件带来误报。
- Authentihash 是忽略其 Windows Authenticode 代码签名数据的 PE可执行文件的哈希。它可以识别由不同发布者签名的相同可执行文件。它对整个 PE可执行文件进行哈希处理,除了三部分:Authenticode 数据、指向 Authenticode 数据的指针和文件校验和。
6.8 支持跨架构
跨架构方法可以比较不同 CPU 架构的二进制代码,例如 x86、ARM 和 MIPS。 这与支持不同架构的独立于架构的方法(例如,F2004)不同; 但不能相互比较; 即,它们可以比较两个 x86 输入和两个 MIPS 输入,但不能比较 x86 输入和 MIPS 输入。 有 17 种跨架构方法,都是自 2015 年以来提出的。一个常见的应用程序被赋予一段有缺陷的二进制代码,以搜索为其他架构编译的类似二进制代码,其中也可能包含错误,例如,搜索程序 在已静态编译易受 Heartbleed 攻击的 OpenSSL 版本的固件映像中。
不同架构的代码语法可能会有很大差异,因为它们可能使用具有不同指令助记符、寄存器集和默认调用约定的单独指令集。因此,跨架构方法计算语义相似度,跨架构方法采用两种技术之一。
- 7 种方法将二进制代码提升为与架构无关的中间表示 (IR):Multi-MH、MockingBird、BinGo、BinGo-E、Xmatch、CACompare、GitZ、FirmUp。然后,无论源架构如何,都可以对 IR 执行相同的分析。优点是分析仅依赖于 IR,并且 IR 设计可以外包给单独的组。第 7 节详细介绍了每种方法支持的特定架构以及它们使用的 IR。
- 10 种方法使用的另一种方法是使用基于特征的相似性(在第 6.6 节中讨论)。这些方法对每个架构使用单独的模块来获取捕获二进制代码语义的特征向量(discovRE、BinDnn、Genius、Gemini、αDiff、VulSeeker、RLZ2019、InnerEye、SAFE、DeepBinDiff)。
6.9 分析类型
二进制代码相似性方法可以使用静态分析、动态分析或两者兼有。
静态分析检查反汇编的二进制代码而不执行它。相反,动态分析通过在选定输入上运行代码来检查代码执行。动态分析可以在线执行,因为代码在受控环境中执行,也可以离线执行跟踪。在分析的方法中,66 种仅使用静态分析,4 种仅使用动态分析,6 种将两者结合。
二进制代码相似性的静态分析的主导地位是由于大多数应用程序需要比较所有输入代码。这使用静态分析更容易,因为它提供了完整的代码覆盖率。动态分析一次检查一个执行,并且只能确定在该执行中运行的代码的相似性。为了增加动态分析的覆盖率,三种方法(iBinHunt、Blex、IMF-sim)在覆盖不同执行路径的多个输入上运行代码并组合结果。但是,在涵盖所有可能执行路径的输入上运行任何重要的二进制代码是不可行的。
动态分析的一个优点是简单,因为内存地址、操作数值和控制流目标在运行时是已知的,这回避了内存别名和间接跳转等静态分析挑战。 另一个优点是它可以处理一些混淆并且不需要反汇编代码,这对于混淆代码特别具有挑战性[76]。 第 8 节详细介绍了哪些方法评估了其对混淆代码的鲁棒性。 总体而言,动态分析已用于二进制代码相似性,用于恶意软件解包(Smit、Beagle、MutantX-S、CXZ2014、BinSim)、跟踪粒度操作(BinSim、KS2017)以及收集语义相似性的运行时值(Blex、 BinSim,IMF-sim)。
数据流分析是一种常见的分析类型,它检查值如何通过代码传播。它包括要跟踪的数据源(例如,保存特定变量的寄存器或内存位置)、定义不同指令或 IR 语句如何传播值的传播规则,以及接收器,即检查到达它们的值的程序点。
在使用数据流分析的 24 种方法中,18 种使用符号执行来提取一组符号公式来计算语义相似度(第 6.4 节)。 BMM2006 和 BMM2007 使用数据流来解决函数间接问题。西班牙使用污点分析来总结漏洞模式及其安全补丁。 iBinHunt 同时使用污点分析和符号执行。它首先使用污点分析作为过滤器来查找处理相同用户输入的二进制代码片段,从而将昂贵的子图同构计算限制在具有相同污点标签的那些上。它使用符号公式计算基本块相似度。 IMF-sim 使用反向污染分析从取消引用错误中推断出函数的指针参数。
6.10 规范化
句法相似性方法经常规范化指令,因此规范化为相同形式的两条指令被认为是相似的,尽管存在一些句法差异,例如,使用了不同的寄存器。 总的来说,有 41 种方法使用指令规范化。 他们应用以下三种类型的指令规范化:
- 操作数移除——九种方法使用的规范化是仅通过其助记符或操作码抽象指令,忽略所有操作数。 例如, add %eax, %ebx 和 add [%ecx], %edx 都将由 add 表示并被认为是相似的,尽管它们使用不同的操作数。
- 操作数规范化——38 种方法使用的规范化是将指令操作数替换为捕获操作数类型的符号,例如 REG 表示寄存器,MEM 表示内存,IMM 表示立即值。 例如,add %eax, %ebx 和 add %ecx, %edx 都将表示为 add REG, REG,尽管编译器使用了不同的寄存器分配,但与指令匹配。 操作数规范化比操作数删除抽象少。 例如,add [%ecx], %edx 将表示为 add MEM, REG,因此被认为与上述不同。 一些方法还对通用寄存器和段寄存器以及不同大小的操作数使用不同的符号(例如 BinClone 中的 RegGen8 和 RegGen32)。
- 助记符规范化——三种方法(BMAT、BMAT2000 和 iLine)使用的规范化是用相同的符号表示多个助记符。 例如,这三种方法用相同的符号表示所有条件跳转(例如 je、jne),以说明编译器修改跳转条件。
另一种规范化是忽略不应影响语义的代码。 例如,一些指令集包含不改变进程状态的无操作指令。 并且编译器通常使用无操作等效指令进行填充,例如将寄存器移动到自身的指令,例如 mov %eax, %eax。 无操作等效指令对于语义相似性和结构相似性方法无关紧要,但由于它们改变了语法,它们可能会影响句法相似性方法。
- 三种方法删除无操作指令(iLine、MXW2015、QSM2015)。
- 一些方法还删除了可能由混淆引入的无法访问的死代码(BMM2006、BMM2007、FirmUp); 函数尾声和序言指令(Exposé),这可能会使小的无关函数看起来相似; 以及编译器添加的用于加载程序的函数,这些函数不存在于源代码中(BinGo、BinGo-E、Sigma、BinGold)。
7. 实现
本节将 70 种方法的实施系统化。 对于每种方法,表 3 显示了它构建的静态和动态平台、用于实现该方法的编程语言、该实现是否支持分布式分析、支持的目标程序架构和操作系统,以及该方法是如何发布的。 破折号 (-) 表示我们找不到信息(即未知),而叉号 (✗) 表示不支持/未使用。
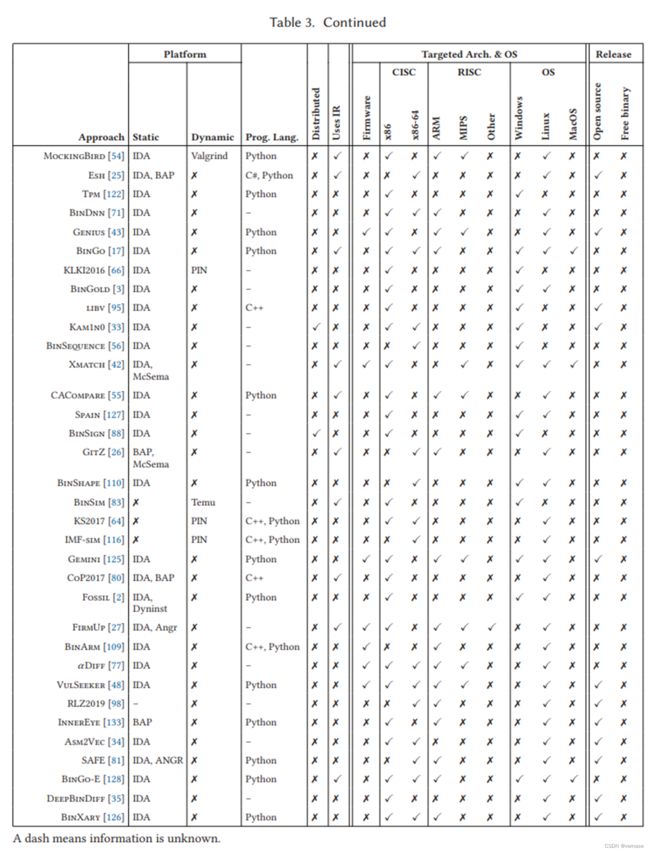
从头开始构建二进制代码相似性方法需要付出巨大的努力。因此,所有方法都建立在以前可用的二进制分析平台或工具之上,这些平台或工具提供了诸如用于静态分析的反汇编和控制流图或用于动态分析的指令级监控等功能。但是,一种方法的实现可能只使用底层平台提供的功能的子集。最受欢迎的静态平台是 Ida(49 种方法),其次是 BAP(5)、DynInst(3)和 McSema(2)。 Ida 的主要功能是反汇编和构建控制流图。它的流行来自于对大量架构的支持。一些二进制分析平台已经支持使用 Ida 作为其反汇编程序,因此将 Ida 与另一个平台结合使用(六种方法)并不罕见。在动态方法中,PIN 是最受欢迎的五种方法,其次是 Temu 的三种方法。以前的工作已经分析了二进制代码类型推断方法使用的二进制分析平台 [14]。由于大多数平台重叠,我们建议读者阅读该作品以了解平台详细信息。
一些方法建立在以前的二进制代码相似性方法之上。 一种情况是两种方法都有重叠的作者。 例如,RMKNHLLP2014 基于 BinJuice,MXW2015 扩展了已经与 BinHunt 共享组件的 iBinHunt。 另一种情况是使用以前发布的方法。 例如,BinSlayer 和西班牙使用 BinDiff 作为第一阶段过滤器来查找匹配的函数。
最流行的编程语言是 Python(22 种方法),其次是 C++(16 种)。 原因之一是大多数方法都使用 Ida 进行反汇编,而 Ida 支持这两种方法C++ 和 Python 插件。 此外,两种方法(Kam1n0、BinSign)使用分布式平台(例如 Hadoop)来分发他们的分析。
二进制代码分析可以直接对特定指令集(例如 x86、ARM)进行操作,也可以将指令集转换为中间表示(IR)。使用 IR 有两个主要优点。首先,更容易重用建立在 IR 之上的分析。比如支持一个新的架构,只需要增加一个新的前端来翻译成IR,但是分析代码是可以复用的。其次,复杂的指令集(例如,x86/x86-64)可以转换为更小的 IR 语句和表达式集,这可以显式显示任何副作用,例如隐式操作数或条件标志。
使用 IR 的方法有 17 种,大多数使用底层平台提供的 IR。在 17 种方法中,5 种使用 BitBlaze 提供的 VINE(BinHunt、iBinHunt、CoP、MXW2015、BinSim),另外 5 种使用 Valgrind 提供的 VEX(Multi-MH、MockingBird、CACompare、GitZ、FirmUp),2 种使用 LLVM-IR (Esh,Xmatch)。其余四种方法使用 SAGE III (SWPQS2006)、METASM (Tedem) 和 REIL (BinGo, BinGo-E)。令人惊讶的是,17 种跨架构方法中只有 6 种使用 IR(Multi-MH、Xmatch、MockingBird、CACompare、GitZ、FirmUp)。其余方法为每个架构提供单独的分析模块,这些模块通常输出具有通用格式的特征向量。
要分析的目标程序最受支持的架构是 x86/x86-64(68 种方法),其次是 ARM(18)和 MIPS(10)。唯一不支持 x86/x86-64 的两种方法是针对 Digital Alpha 的 Exediff 和针对 ARM 的 BinArm。有 17 种跨架构方法和 9 种支持固件的方法。第一个跨架构方法是 Multi-MH,它在 2015 年增加了对 ARM 的支持。从那时起,由于移动和物联网设备的普及,ARM 支持变得非常普遍。值得注意的是,即使有 49 种方法使用 Ida,它支持 60 多个处理器系列,但大多数基于 Ida 构建的方法仅分析 x86/x86-64 程序。最受支持的操作系统是 Linux(47 种方法),其次是 Windows(42 种)。只有五种方法支持 MacOS。专注于 x86/x86-64 的早期方法通常使用 Ida 来获得对 PE/Windows 和 ELF/Linux 可执行文件的支持。最近,所有利用 ARM 的方法都支持 Linux,Android 和许多 IoT 设备都使用 Linux。
在 70 种方法中,只有 16 种是开源的(BinSlayer、Tracy、QSM2015、Esh、Genius、libv、Kam1n0、Gemini、Asm2Vec、VulSeeker、RLZ2019、InnerEye、SAFE、DeepBinDiff、BinXary)。 DR2005 是在 BinDiff 商业工具中实现的,该工具现在作为免费的二进制文件提供。 其余方法尚未以任何形式发布,尽管它们构建的平台可能是开源的。 此外,16 种开源方法中有 4 种(Esh、Genius、RLZ2019、InnerEye)已经部分发布了它们的源代码和机器学习模型。
8. 评估
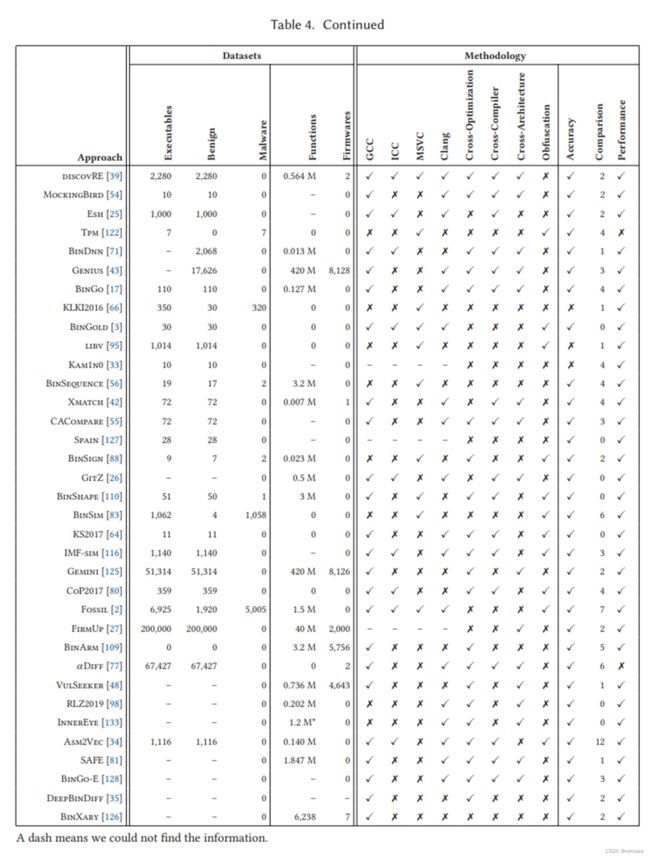
本节系统化了 70 种二进制代码相似性方法的评估。 对于每种方法,表 4 总结了使用的数据集(第 8.1 节)和评估方法(第 8.2 节)。

8.1 数据集
表 4 的左侧描述了每种方法使用的数据集。 它首先显示了评估中使用的可执行文件的总数,并将它们分为良性和恶意可执行文件。 可执行文件可能来自不同的程序或对应于同一程序的多个版本,例如,具有不同的编译器和编译选项。 然后,对于具有函数粒度的方法,它会捕获评估的函数总数,对于分析固件的方法,它会捕获从中获取可执行文件的图像数量。 列中的破折号表示我们在论文中找不到数字。 例如,SWPQS2006 对 Windows XP 中的系统库文件进行评估,但未指明可执行文件的总数。
大多数方法使用自定义数据集; 一个流行的基准是 Coreutils,被 18 种方法使用。 此外,评估固件的方法使用两个公开可用的固件(ReadyNAS [97] 和 DD-WRT [29])。 超过一半的方法评估少于 100 个可执行文件,12 个评估小于 1K,10 个评估小于 10K,只有 7 个评估超过 10K。 在 70 种方法中,43 种仅评估了良性程序,8 种仅评估了恶意软件,16 种评估了两者。 这表明二进制代码相似性在恶意软件分析中也很流行。 然而,在对恶意软件进行评估的 26 种方法中,只有 5 种使用打包的恶意软件样本(Smit、Beagle、MutantX-S、CXZ2014、BinSim)。 这些方法首先使用自定义解包器 (Smit) 或通用(写入并执行)解包器(Beagle、MutantX-S、CXZ2014、BinSim)解包恶意软件,然后计算二进制代码相似度。 其余的可以访问恶意软件的源代码或解压样本。
对于使用函数粒度的二进制代码搜索方法,存储库中的函数数量可以更好地捕捉数据集的大小。 最大的数据集来自 Genius,它评估了从 8,126 个固件中提取的 420M 函数。 先前的方法最多评估了 0.5M 个函数,这证明了其嵌入方法的可扩展性增益。 其他五种方法已经评估了超过 100 万个函数:Fossil (1.5M)、BinSeqence (3.2M)、BinArm(3.2M)、FirmUp (40M) 和 Gemini (420M),它们使用与 Genius 相同的数据集。 此外,InnerEye 还评估了 120 万个基本块的存储库。
8.2 方法
表 4 的右侧描述了每种方法使用的评估方法的四个方面:稳健性、准确性、性能以及与先前方法的比较。
1. 稳健性
表 4 右侧的前八列记录了作者如何评估他们的方法的稳健性,即,尽管对输入程序进行了转换,但他们捕捉相似性的能力。 首先,它显示了它们是否使用我们观察到的四种编译器中的每一种来编译数据集中的程序:GCC、ICC、Visual Studio (MSVS) 和 Clang。 然后,它捕获作者是否评估使用不同编译选项编译的程序之间(交叉优化)、使用不同编译器编译的程序之间(交叉编译器)以及为不同架构编译的程序之间(跨架构)的相似性。 最后,它捕获了当混淆转换应用于输入程序时作者是否评估相似性。
有 40 种方法可以评估稳健性(在最后四个稳健性列中至少有一种),而 30 种没有。许多早期作品没有评估稳健性。随着方法的成熟,这种评估变得越来越流行。最流行的稳健性评估是交叉优化(26 种方法),其次是交叉编译器(21)、跨架构(17)和混淆(17)。 有 10 种方法评估了交叉优化、交叉编译器和跨架构。 评估交叉编译器的方法通常也评估交叉优化,因为它是一个更简单的情况。 类似地,评估跨架构的方法通常也评估交叉编译器,因为可以使用不同的编译器生成跨架构程序。 请注意,可以使用多个编译器编译程序但不执行交叉编译器评估的方法,即不比较使用不同编译器编译的程序之间的相似性。有 17 种方法对混淆程序进行了评估。 其中,Asm2Vec 仅使用源代码转换,三个仅使用二进制代码转换(KKMRV2005、Tpm、BinShape),五个使用打包恶意软件(Smit、Beagle、MutantX-S、CXZ2014、BinSim),四个评估源代码和二进制 代码转换(CoP、BinSim、IMF-sim、Fossil)。
2. 精度评估和比较
有 57 种方法使用一些基本事实 (✔) 对其准确性进行定量评估,而通过案例研究 (✗) 进行定性准确性评估的方法有 13 种。 定量评估最常使用标准准确度指标,例如真阳性、假阳性、精度和召回率。 然而,有两种方法提出了新颖的特定于应用程序的准确度指标(iLine,KS2017)。
与以前的方法相比,有 40 种方法。所有这些都比较准确性,六个还比较运行时间。比较的首要目标是 BinDiff(13 种方法与之比较),其次是 Tracy(5)、discovRE(4)和 Multi-MH(4)。由于多种原因,比较二进制代码相似性方法的准确性具有挑战性。首先,只有一小部分提议的方法公开了他们的代码(第 7 节)。由于大多数方法不是公开可用的,因此通常通过重新实施以前的方法来进行比较,这可能需要付出很大的努力。重新实现的一个优点是可以在新数据集上比较方法。重新实施的替代方法是在先前方法使用的相同数据集上评估新方法,并与报告的结果进行比较。此方法仅被六种方法(Genius、BinGo、Xmatch、CACompare、Gemini 和 BinArm)使用,可能是因为大多数数据集是自定义的且不公开可用。幸运的是,我们观察到公共代码发布在最近的方法中变得更加普遍。其次,输入比较和输入粒度可能因方法而异,因此几乎不可能进行公平比较。例如,很难以公平的方式比较使用调用图(例如 Smit)识别程序相似性的方法与比较基本块的方法(例如 InnerEye)。第三,即使输入比较和输入粒度相同,评估指标和方法也可能不同,从而显着影响测量的准确性。
后一个挑战在以函数粒度运行的二进制代码搜索方法上得到了最好的说明。 这些方法在存储库中找到与给定函数最相似的函数。 它们返回多个按相似度降序排列的条目,如果前 k 个最相似的条目之一是真正的匹配,则将其计数为真阳性。 不幸的是,k 的值因方法而异,并显着影响准确性。 例如,前 10 名的 98% 精度明显低于前 3 名的 98% 精度。因此,很难比较使用不同 k 值获得的精度数,并且很容易将 k 提高到足够高的精度数 已完成。 此外,许多方法没有描述用于确定存储库中不存在类似条目的相似性阈值。 因此,他们总能找到一些相似的存储库中的条目,即使相似度可能非常低。
3. 表现
衡量一种方法的运行时性能是很常见的 (58/70)。 运行时间通常是端到端测量的,但一些方法会为每个方法组件(例如 BinSim)报告它。 五种方法报告了它们的渐近复杂度(BMM2006、BMM2007、SWPQS2006、iLine、MockingBird)
9. 讨论
本节讨论开放的挑战和未来可能的研究方向。
1. 一小段二进制代码
许多二进制代码相似性方法会忽略小块二进制代码,对要考虑的最小指令或基本块数设置阈值。通常,只有少量指令的二进制代码会被忽略,例如指令少于 5 条的函数,但有些方法使用大阈值,例如 Tracy 中的 100 个基本块。小段二进制代码具有挑战性,因为它们很常见,可能由一个阻止结构分析的基本块组成,并且尽管语义不同,但可能具有相同的语法。例如,更新对象中字段值的 setter 函数具有几乎相同的语法和结构,只需使用参数值设置内存变量。但它们可能具有非常不同的语义,例如,设置安全级别或更新性能计数器。此外,指令分类、符号公式和输入输出对等语义相似性技术可能无法捕捉它们的差异,例如,如果它们不区分不同的内存变量。小段二进制代码的相似性仍然是一个开放的挑战。一种潜在的途径是进一步结合上下文。一些结构方法已经考虑调用图来匹配函数(例如,F2004),但这并不总是足够的。我们相信有可能进一步结合其他上下文,例如局部性(例如,二进制代码在程序结构中的接近程度)和数据引用(例如,它们是否使用等效变量)[63]。
2. 源到二进制的相似性
像抄袭检测这样的一些应用程序可能需要将源代码与二进制代码进行比较。 早期的源代码与二进制文件相似性方法使用软件胎记来捕获源代码的固有功能 [19, 85]。 最近,源到二进制相似性已被用于搜索开源代码中的已知错误是否存在于某些目标二进制代码中[131]。 源代码的可用性提供了更多的语义(例如,变量和函数名称、类型、注释),与简单地编译源代码和执行二进制代码相似性相比,可能会提高准确性。 我们相信其他应用程序仍然需要确定目标二进制代码是否已从某些给定源代码编译或演变。 例如,可能有些程序的源代码仅适用于旧版本,因此需要了解较新的二进制版本是如何从原始源代码演变而来的。
数据相似性。 这项调查主要关注二进制代码的相似性,但程序由代码和数据组成。 在某些情况下,代码使用的数据与代码一样重要,例如,程序版本之间的唯一变化是使用的数据,例如更改机器学习分类器的参数。 此外,数据可以存储在可能是功能关键的复杂数据结构中。 二进制代码的类型推断技术历史悠久[14],我们认为可以将其与二进制代码相似性相结合,以比较不同二进制代码使用的数据结构,或者两段二进制代码如何使用相同的数据 结构体。
3. 语义关系
语义相似性的另一个方面是识别具有相关功能的二进制代码,例如加密或网络功能。 这是具有挑战性的,因为与其功能相关的代码可能没有相同的语义。 例如,一个解密函数显然与其加密函数相关,但执行的是逆运算。 到目前为止,大多数工作都集中在特定领域的技术上,例如用于识别密码功能的技术(例如,[117, 124])。 但是最近一些方法已经开始探索与领域无关的技术[63]。 我们认为需要进一步的工作来更好地定义这种语义关系及其识别。
可扩展性。 迄今为止,最大的二进制代码相似性评估是 Genius 和 Gemini 对 8,126 个固件映像的 420M 函数(每个映像 500K 函数)进行的评估。 虽然这是与先前方法相比的重要一步,但如果我们考虑 100K 唯一固件,这是一个保守的数字,因为预计到 2020 年将有 200 亿个物联网设备连接到互联网 [49],我们需要二进制代码相似性方法 可以处理 500 亿个函数。 因此,实现二进制代码搜索引擎的愿景需要进一步提高可扩展性。
3. 混淆
混淆代码上的二进制代码相似性仍然存在许多挑战。 例如,最近的一项研究表明,最先进的解包技术可能会遗漏 20%–60% 的原始代码,例如,由于不完整的功能检测 [51]。 并且目前没有二进制代码相似性方法集成了先前提出的对基于虚拟化的打包器进行去混淆的方法(例如,[108, 123])。 此外,混淆最好用语义相似性来解决,这对不尊重代码原始语义但仍执行其主要目标的混淆转换具有挑战。
4. 方法比较
用于评估这些方法的数据集和方法的多样性(例如,OM 方法的 top k 评估),加上其中许多缺乏源代码,使得很难进行公平的比较以了解它们的优点和局限性。 我们相信该领域将极大地受益于在相同实验条件下进行基准测试和独立验证的开放数据集。 此外,除了更改编译器和编译器选项之外,还需要改进处理混淆的方法的比较。 考虑到可能的混淆转换的巨大空间,并且每种方法都支持不同的子集,构建一个涵盖真实世界混淆的数据集至关重要。
5. 将最新进展应用于神经网络
在过去 3 年中,多种二进制代码相似性方法利用了神经网络(例如 Gemini、αDiff、InnerEye、Asm2Vec、DeepBinDiff)。 由于神经网络的研究正在迅速发展,我们预计新的二进制代码相似性方法将很快利用最近的进展,例如与注意力模型 [4, 31]、神经架构 [113] 和图形自动编码器 [67] 相关的进展。我们预计神经网络模型(例如,[129])的可解释性将成为恶意软件谱系和恶意软件归因等应用程序的一个重要问题,在这些应用程序中,人类可能需要了解模型捕获的相似性。 类似地,对抗性学习技术 [78] 对于具有活跃对手(例如涉及恶意软件的那些)的二进制代码相似性应用程序可能变得很重要。
在过去的 20 年中,研究人员提出了许多执行二进制代码相似性的方法,并将它们应用于解决重要问题,例如补丁分析、错误搜索、恶意软件检测和恶意软件分析。 该领域已经从二进制代码差异发展到二进制代码搜索,从句法相似性发展到结合结构和语义相似性,以涵盖多个代码粒度,以加强比较的鲁棒性(即交叉优化、交叉编译器、跨操作系统、 跨架构、混淆),以扩展比较输入的数量(例如,通过散列、嵌入、索引),并自动学习相似性特征。
尽管它很受欢迎,但该领域尚未得到系统分析。 本文介绍了对二进制代码相似性的第一次调查。 文章的核心从四个维度系统化了 70 种二进制代码相似性方法:它们支持的应用程序、它们的方法特征、这些方法的实现方式以及用于评估它们的基准和评估方法。 它讨论了不同方法的优点和局限性、它们的实施和评估。 它将结果汇总到易于访问的表格中,对初学者和专家都很有用。 此外,它还讨论了该领域的演变并概述了仍然存在的挑战,表明该领域拥有光明的未来。