Python分析与处理---利用Python进行学生成绩分析
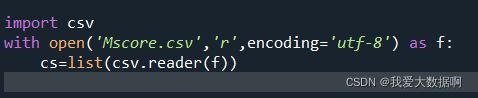
1. 读取Mscore并将其转化为列表,r表示读
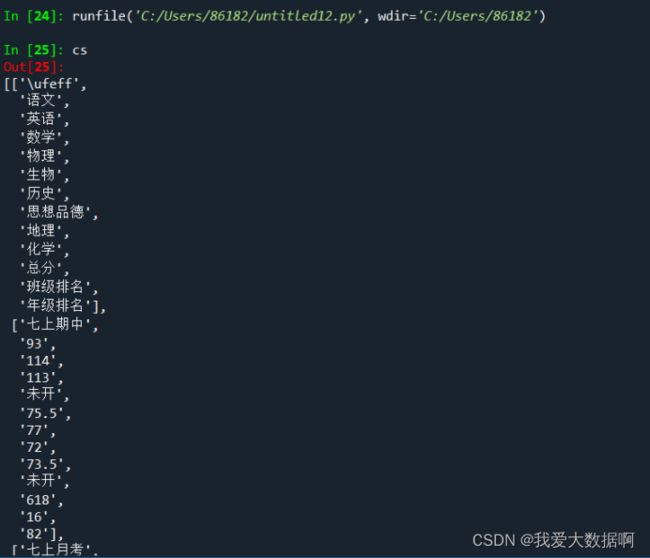

-
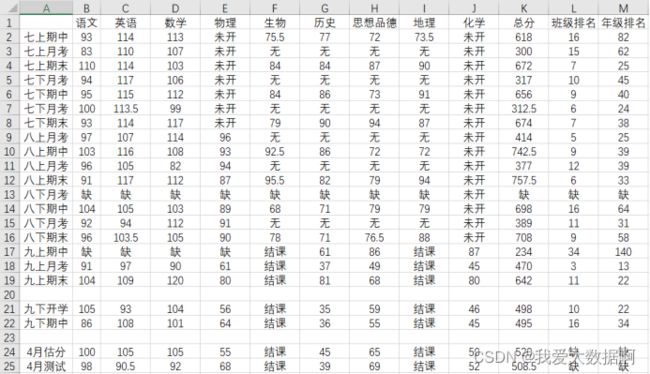
录入数据
生成列表23*13,包含以上数据内容,其中“未开”、“结课”和“无”项用数值-2代替,“缺”用数值-1代替,并将列表信息存储为original_data.txt
import numpy as np
import csv
with open('Mscore.csv','r',encoding='utf-8') as f:
cs=list(csv.reader(f))
original_data=[]
for row in cs:
list_x=[]
for data in row:
if data=='未开':
list_x.append('-2')
elif data=='结课':
list_x.append('-2')
elif data=='无':
list_x.append('-2')
elif data=='缺':
list_x.append('-1')
else:
list_x.append(data)
original_data.append(list_x)
x=np.array(original_data)
x=(np.delete(x,0,axis=0))
original_data=(np.delete(x,0,axis=1))
print(original_data)
np.savetxt('C:/Users/86182/original_data.txt',original_data,fmt='%s',encoding='utf-8')#“未开”、“结课”和“无”项用数值-2代替,“缺”用数值-1代替,并将列表信息存储为original_data.txt
fmt='%s':为指定保存的文件格式,这里为十进制
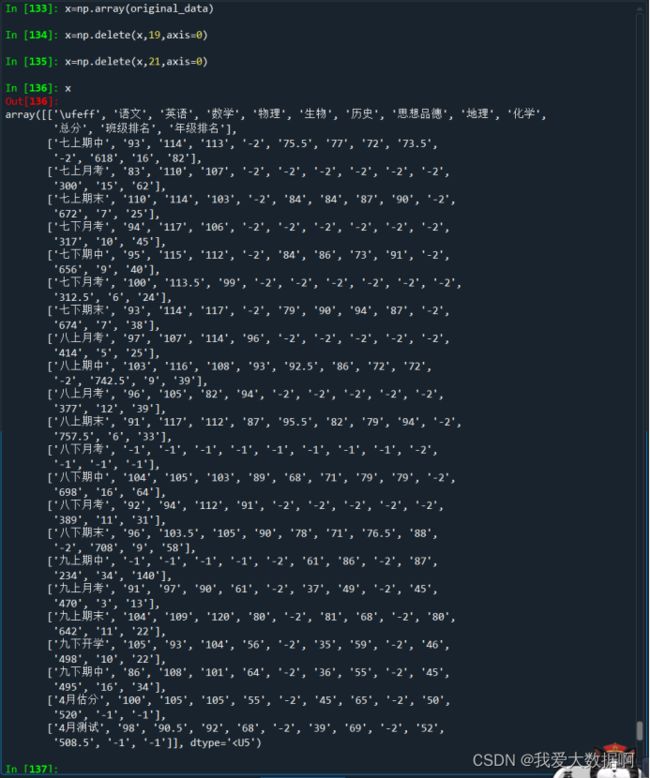
x=np.array(original_data)
x=np.delete(x,19,axis=0)
x=np.delete(x,21,axis=0)
#删除多余的两个空行
x=np.delete(x,0,axis=0)
x=np.delete(x,0,axis=1)#将第一行和第一列删除,只留数值scores 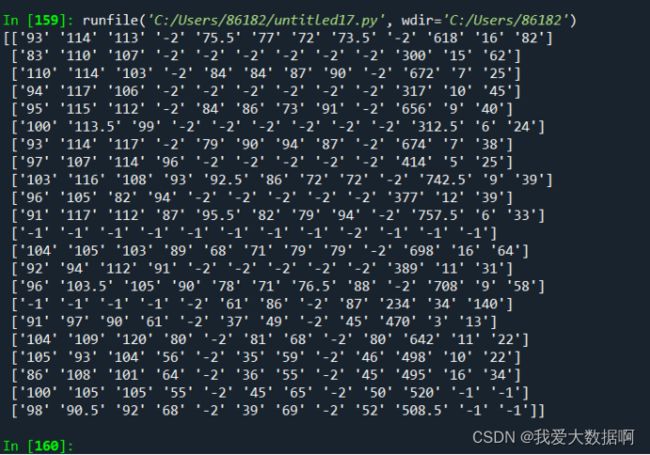
1.生成ndarray数组scores,包含所有分数,效果如下:
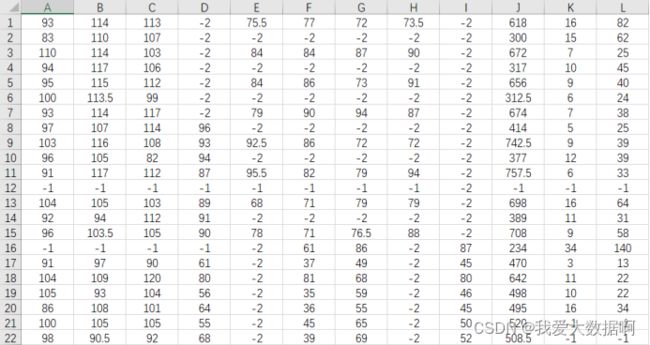 代码如下:
代码如下:
import numpy as np
import csv
with open('Mscore.csv','r',encoding='utf-8') as f:
cs=list(csv.reader(f))
original_data=[]
for row in cs:
list_x=[]
for data in row:
if data=='未开':
list_x.append('-2')
elif data=='结课':
list_x.append('-2')
elif data=='无':
list_x.append('-2')
elif data=='缺':
list_x.append('-1')
else:
list_x.append(data)
original_data.append(list_x)
x=np.array(original_data)
x=(np.delete(x,19,axis=0))
x=(np.delete(x,21,axis=0))
x=(np.delete(x,0,axis=0))
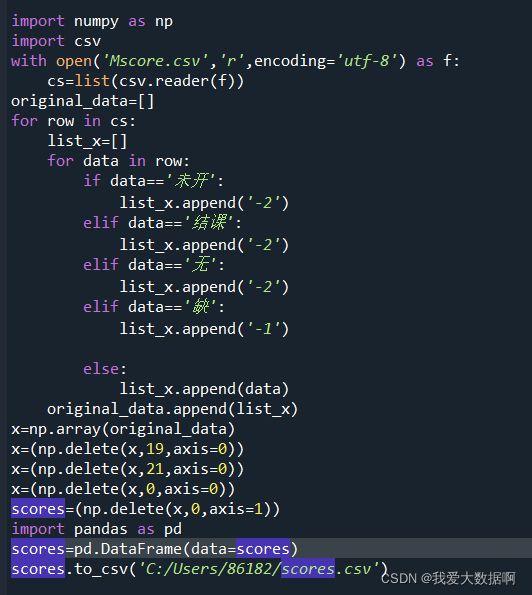
scores=(np.delete(x,0,axis=1))
import pandas as pd
scores=pd.DataFrame(data=scores)
scores.to_csv('C:/Users/86182/scores.csv')#生成ndarray数组scores,包含所有分数效果如图:
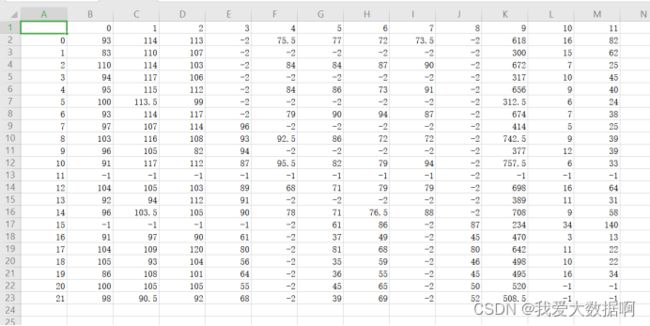
2.生成ndarray数组subjects,包含所有科目名称,效果如下:
![]() 答:
答:
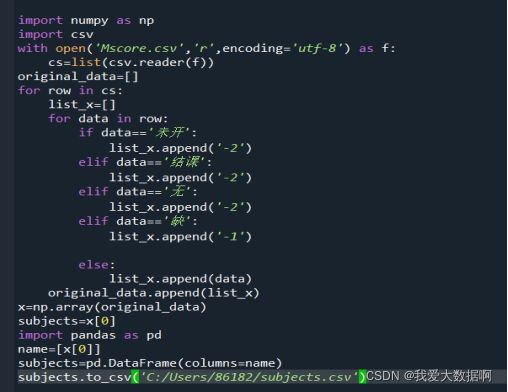
效果如下

3.生成ndarray数组names,包含所有类别,效果如下:
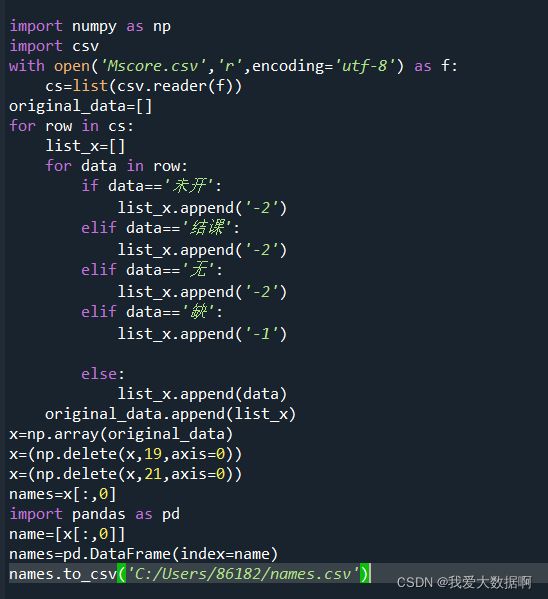
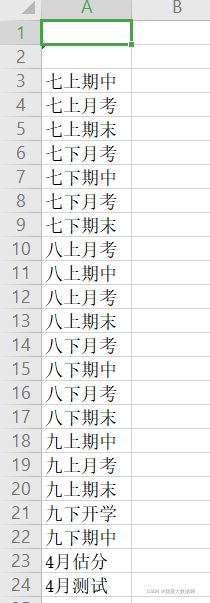
import numpy as np
import csv
with open('Mscore.csv','r',encoding='utf-8') as f:
cs=list(csv.reader(f))
original_data=[]
for row in cs:
list_x=[]
for data in row:
if data=='未开':
list_x.append('-2')
elif data=='结课':
list_x.append('-2')
elif data=='无':
list_x.append('-2')
elif data=='缺':
list_x.append('-1')
else:
list_x.append(data)
original_data.append(list_x)
x=np.array(original_data)
x=(np.delete(x,19,axis=0))
x=(np.delete(x,21,axis=0))
names=x[:,0]
import pandas as pd
name=[x[:,0]]
names=pd.DataFrame(index=name)
names.to_csv('C:/Users/86182/names.csv')#生成ndarray数组names,包含所有类别 
-
数据清洗
4.在numpy中删除“八下月考”,“九上期中”对应分数行
import numpy as np
import csv
with open('Mscore.csv','r',encoding='utf-8') as f:
cs=list(csv.reader(f))
original_data=[]
for row in cs:
list_x=[]
for data in row:
if data=='未开':
list_x.append('-2')
elif data=='结课':
list_x.append('-2')
elif data=='无':
list_x.append('-2')
elif data=='缺':
list_x.append('-1')
else:
list_x.append(data)
original_data.append(list_x)
x=np.array(original_data)
x=(np.delete(x,19,axis=0))
x=(np.delete(x,21,axis=0))
x=(np.delete(x,12,axis=0))
x=(np.delete(x,13,axis=0))
print(np.delete(x,14,axis=0)) 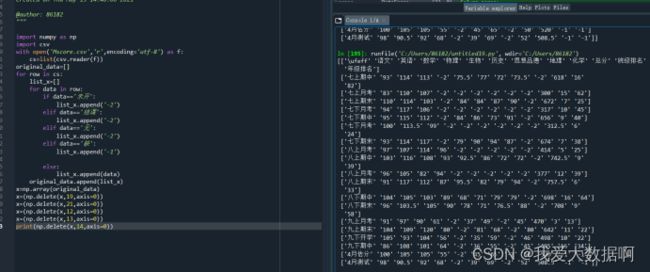
将“八上月考”到“九上期末”的物理成绩转换成80分为满分的数据值(原数据为100分制)
import numpy as np
import csv
with open('Mscore.csv','r',encoding='utf-8') as f:
cs=list(csv.reader(f))
original_data=[]
for row in cs:
list_x=[]
for data in row:
if data=='未开':
list_x.append('-2')
elif data=='结课':
list_x.append('-2')
elif data=='无':
list_x.append('-2')
elif data=='缺':
list_x.append('-1')
else:
list_x.append(data)
original_data.append(list_x)
x=np.array(original_data)
x=(np.delete(x,19,axis=0))
x=(np.delete(x,21,axis=0))
x=(np.delete(x,12,axis=0))
x=(np.delete(x,13,axis=0))
x=(np.delete(x,14,axis=0))
print(x[10:16,4])
x1=x[10:16,4]
for n in x1:
print(float(n)*0.8) 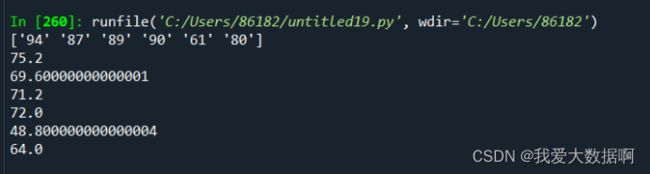
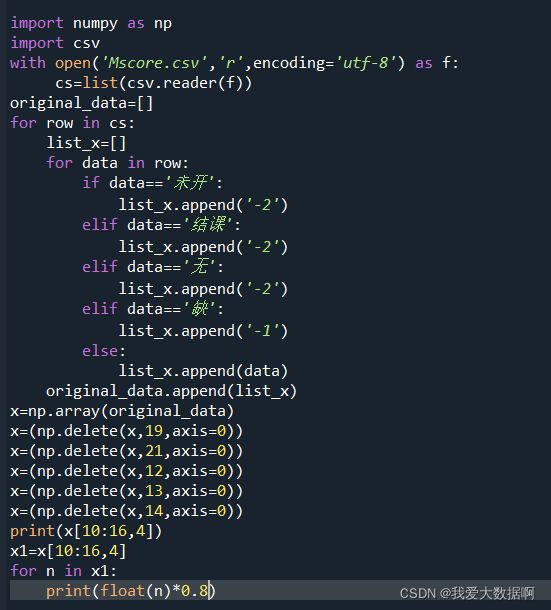
将“九下开学”至“九下期中” 的物理成绩转换成80分为满分的数据值(原数据为70分制)

-
数据选取
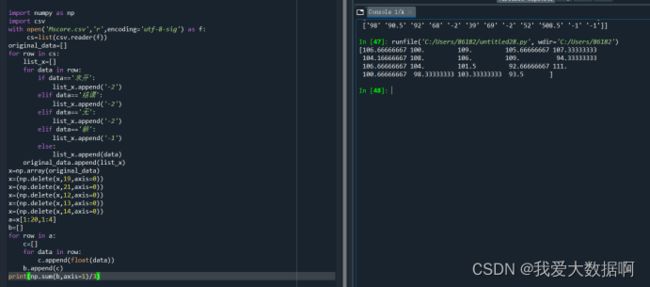
提取所有语、数、英成绩形成新的ndarray数组,并计算各科平均分
用法:mean(matrix,axis=0) 其中 matrix为一个矩阵,axis为参数
以m * n矩阵举例:
axis 不设置值,对 m*n 个数求均值,返回一个实数
axis = 0:压缩行,对各列求均值,返回 1* n 矩阵
axis =1 :压缩列,对各行求均值,返回 m *1 矩阵
#提取所有语、数、英成绩形成新的ndarray数组,并计算平均分
提取“九上月考”到“4月测试”所有科目成绩(不包括地理、生物),生成新的ndarray数组,并保持到txt文件中。
import numpy as np
import csv
with open('Mscore.csv','r',encoding='utf-8') as f:
cs=list(csv.reader(f))
original_data=[]
for row in cs:
list_x=[]
for data in row:
if data=='未开':
list_x.append('-2')
elif data=='结课':
list_x.append('-2')
elif data=='无':
list_x.append('-2')
elif data=='缺':
list_x.append('-1')
else:
list_x.append(data)
original_data.append(list_x)
x=np.array(original_data)
x=(np.delete(x,19,axis=0))
x=(np.delete(x,21,axis=0))
x=(np.delete(x,12,axis=0))
x=(np.delete(x,13,axis=0))
x=(np.delete(x,14,axis=0))
b=x[np.ix_([14,15,16,17,18,19],[1,2,3,4,6,7,9])]
np.savetxt('C:/Users/86182/newarray.txt',b,fmt='%s') 提取“九上月考”到“4月测试”所有科目成绩(不包括地理、生物),生成新的ndarray数组。并保持到txt文件中 