【动手学深度学习PyTorch版】11 使用GPU
上一篇移步【动手学深度学习PyTorch版】10 PyTorch 神经网络基础_水w的博客-CSDN博客
目录
一、使用GPU
1.1 确认GPU
1.2 硬件
◼ 计算设备
◼ 允许我们在请求的GPU不存在的情况下运行代码的两个函数
◼ 查询张量所在设备
1.3 神经网络与GPU
一、使用GPU
1.1 确认GPU
如果你发现你的 NVIDIA GPU 无法运行 GPU 代码,nvidia-smi 可以看到有没有GPU,会很方便查看GPU使用情况,可以查看显卡的显存利用率。
!nvidia-smi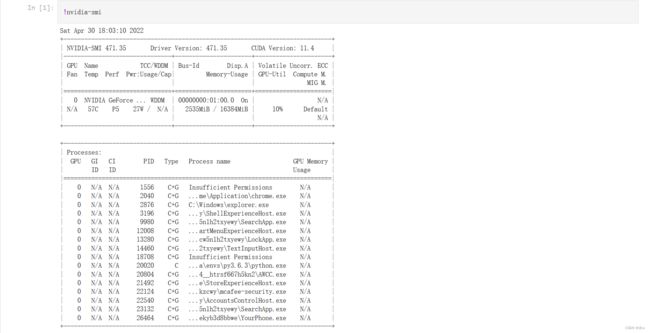 图中可以看到,一共有4块GPU,以及各自的内存情况。另外也可以看到cuda的版本是10.1,我们之后会根据cuda的版本来装对应的版本框架。
图中可以看到,一共有4块GPU,以及各自的内存情况。另外也可以看到cuda的版本是10.1,我们之后会根据cuda的版本来装对应的版本框架。
图的最下面,可以看到是谁在用GPU。
1.2 硬件
◼ 计算设备
(1)一般默认是使用cpu来训练模型,
import torch
from torch import nn
torch.device('cpu')(2)通过torch.cuda.device('cuda')来指定GPU,即使没有显式指定a使用gpu 0,但是pytorch默认还是将tensor分配在gpu 0上。
torch.cuda.device('cuda')(3)torch.device('cuda') 与 torch.device('cuda:0')在进行计算时,对于单卡计算机而言,没有任何区别,都是唯一的那一张GPU。
对于多卡GPU,如果想要访问第一个GPU的话,需要torch.cuda.device('cuda:1')。
torch.cuda.device('cuda:1')(4)查看是否有可用GPU:,
torch.cuda.is_available()查询可用的GPU数量,
print(torch.cuda.device_count())
查看当前使用的GPU序号
torch.cuda.current_device()◼ 允许我们在请求的GPU不存在的情况下运行代码的两个函数
def try_gpu(i=0):
"""如果存在,则返回gpu(i),否则返回gpu"""
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
def try_all_gpus():
"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]。"""
devices = [torch.device(f'cuda:{i}') for i in range(torch.cuda.device_count())]
return devices if devices else [torch.device('cpu')]
print(try_gpu()) # 返回第一个GPU
print(try_gpu(10)) # 没有10个GPU,所以返回的是cpu
print(try_all_gpus()) # 返回所有可用的GPU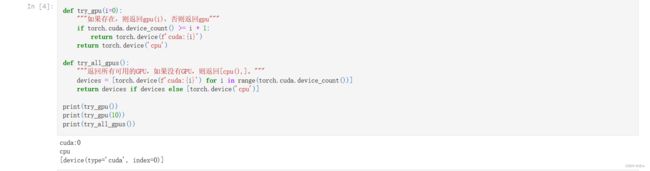
◼ 查询张量所在设备
(1)在GPU上默认创建tensor,然后我们查询一下张量所在设备,通过.device查询, 默认在CPU内存上。
# 查询张量所在设备
X = torch.tensor([1,2,3])
print(X.device) # 默认在CPU内存上
(2)在创建tensor的时候,告诉张量所在设备为cpu,
# 存储在GPU上
X = torch.ones(2,3,device=try_gpu())
X 
可以看到结果中,“device=cuda:0”表示在GPU0上创建了一个随机张量。
(3)同理,在创建tensor的时候,在第二个GPU,即GPU1上,创建了一个随机张量。
# 在第二个GPU上创建一个随即张量
Y = torch.rand(2,3,device=try_gpu(1))
print(Y.device) # 没有1号GPU,则放到CPU上
Y
(4)做计算X+Y,我们需要决定在哪里执行这个操作?
计算X+Y会发生在X和Y对应的device上面,所以X+Y必须X和Y都在同一个GPU上。
另外就是如果“Z = X.cuda(0)”,Z已经在GPU0上的话,那么就不会任何操作,“Z.cuda(0) is Z”就会返回True,不会自己所在的gpu把Z的值又复制到本身自己所在的gpu。
# 要计算X+Y,我们需要决定在哪里执行这个操作
Z = X.cuda(0) # 创建z,把x的值复制到GPU0上的z,因为X+Y必须X和Y都在同一个GPU上
print(X)
print(Z)
这样之后,现在数据Y和Z都在同一个GPU上,我们可以将它们相加,Y和Z的加法就会在这个GPU上完成。
Y = torch.rand(2,3,device=try_gpu(0))
Y + Z
Z.cuda(0) is Z # 如果变量在0号GPU时,就返回True
可以看到,结果也会也在这个GPU上。
在GPU直接挪数据,特别是GPU到CPU挪数据是很慢的。
比如,如果我的一个网络,基本上所有的层都已经在cpu创建好了,一不小心把某一层的网络创建在了gpu上,那么就需要来来回回挪东西,很麻烦, 而且也很容易造成性能问题。并且很难debug。
1.3 神经网络与GPU
(1)通常在cpu上创建神经网络时已经把权重初始化好了,然后可以调用“to()”把所有权重参数在0号GPU上拷贝一份,
# 神经网络与GPU
net = nn.Sequential(nn.Linear(3,1)) # 创建神经网络时已经把权重初始化好了
net = net.to(device=try_gpu()) # 把所有参数在0号GPU上拷贝一份
X = torch.ones(2,3,device=try_gpu()) # X 在0号GPU上
net(X) # 所以前项运算所有元素都在0号GPU上运行
(2)确认模型参数存储在同一个GPU上,
# 确认模型参数存储在同一个GPU上
net[0].weight.data.device
通常来说,一般在cpu上创建神经网络时已经把权重初始化好了,然后把所有权重参数和输入在GPU上拷贝一份,训练模型的时候,当然forward函数也会在这个GPU上运行。