[PaddleDetection保姆级教程]使用自定义数据集实现跌倒识别预测
PaddleDetection介绍
PaddleDetection是基于PaddlePaddle的端到端对象检测开发工具包,旨在帮助开发人员在训练模型的整个开发,优化性能和推理速度以及部署模型方面提供帮助。PaddleDetection在模块化设计中提供了各种对象检测体系结构,并提供了丰富的数据增强方法,网络组件,丢失功能等。PaddleDetection支持实际项目,例如工业质量检查,遥感图像对象检测以及具有模型等实际功能的自动检查。压缩和多平台部署。
手把手教你在AIStudio平台上使用PaddleDetection API训练自己的数据集
教程目的: 通过PaddleDetection API熟悉经典的目标检测框架,为下一步自己手写实现目标检测网络打基础
教程内容: 以PaddleDetection API中的特色模型为例,介绍网络结构,以及如何使用此框架训练自己的数据集
数据准备: 本教程程基于pp_fall数据集,为方便读者体验,已经上传至 data/data94809/pp_fall.zip。
PaddelDetection: 为方便读者体验,存放在PaddleDetection。
其他说明: 本教程所有命令均在Notebook中执行。
运行代码请点击:https://aistudio.baidu.com/aistudio/projectdetail/2071768,点击fork,运行一下即可。
本次项目实验步骤以及实验结果
本次实验通过使用PaddleDetection2.0中的YOLOv3(主干网络为mobilenetv3的轻量化模型),通过几行代码就能实现跌倒的目标检测,后期可部署用于监控医院、疗养院甚至家里等,mAP值达到80.28%
![[PaddleDetection保姆级教程]使用自定义数据集实现跌倒识别预测_第1张图片](http://img.e-com-net.com/image/info8/a84c7677205041669e8842f270edb3a7.jpg)
按以下几个步骤来介绍项目实现流程。
-
解压自定义的数据集;
-
下载安装PaddleDetection包;
-
自定义数据集划分;
-
选择模型(本次选择YOLO-v3)进行训练:训练的配置文件说明;
5.效果可视化:使用训练好的模型进行预测,同时对结果进行可视化;
6.模型评估和预测:评估模型效果;
7.预测结果
检测效果如下图所示:
![[PaddleDetection保姆级教程]使用自定义数据集实现跌倒识别预测_第2张图片](http://img.e-com-net.com/image/info8/87342962c9164a028eb45c8fb1c36c18.jpg)
![[PaddleDetection保姆级教程]使用自定义数据集实现跌倒识别预测_第3张图片](http://img.e-com-net.com/image/info8/0aefc2da98744a4eaf91d96e6ec6b350.jpg)
1数据解压
将把完成好标注的吸烟图片(VOC数据集)进行解压。
建议把上传压缩包
文件格式:
pp_fall:
–Annotations:
1.xml
2.xml
.......
–images:
1.jpg
2.jpg
.......
!unzip -oq data/data94809/pp_fall.zip -d work/
2准备环境
目前代码的版本是release/2.0,需要使用PaddlePaddle2.0.2版本。
! git clone https://gitee.com/paddlepaddle/PaddleDetection.git
3自定义数据集的划分
将数据集按照9:1的比例进行划分,并生成train.txt和val.txt进行训练
import random
import os
#生成train.txt和val.txt
random.seed(2020)
xml_dir = '/home/aistudio/work/Annotations'#标签文件地址
img_dir = '/home/aistudio/work/images'#图像文件地址
path_list = list()
for img in os.listdir(img_dir):
img_path = os.path.join(img_dir,img)
xml_path = os.path.join(xml_dir,img.replace('jpg', 'xml'))
path_list.append((img_path, xml_path))
random.shuffle(path_list)
ratio = 0.9
train_f = open('/home/aistudio/work/train.txt','w') #生成训练文件
val_f = open('/home/aistudio/work/val.txt' ,'w')#生成验证文件
for i ,content in enumerate(path_list):
img, xml = content
text = img + ' ' + xml + '\n'
if i < len(path_list) * ratio:
train_f.write(text)
else:
val_f.write(text)
train_f.close()
val_f.close()
#生成标签文档
label = ['fall']#设置你想检测的类别
with open('/home/aistudio/work/label_list.txt', 'w') as f:
for text in label:
f.write(text+'\n')
注意:
这个数据集是我自己制作的,所以有些图片的标签信息PD识别shape会有错误,所以在执行train.py文件后会报大概有10张图片有问题,只需要把这些照片和对应的标注信息删除掉再重新执行上面的程序生成train.txt,val.txt,再执行train.py就可以了。
%cd ~
/home/aistudio
file_name = "work/images/fall_981.jpg"#work/images/fall_981.jpg work/Annotations/fall_981.xml
if os.path.exists(file_name):
os.remove(file_name)
print('成功删除文件:', file_name)
else:
print('成功删除文件:', file_name)
else:
print('未找到此文件:', file_name)
成功删除文件: work/images/fall_981.jpg
%cd PaddleDetection
/home/aistudio/PaddleDetection
4 模型训练
用户在选择好模型后,只需要改动对应的配置文件后,只需要运行train.py文件,即可实现训练。
本项目中,使用YOLOv3模型里的yolov3_mobilenet_v3_large_ssld_270e_voc.yml进行训练
4.1配置文件示例
我们使用configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml配置进行训练。
在PaddleDetection2.0中,模块化做的更好,可以可自由修改覆盖各模块配置,进行自由组合。
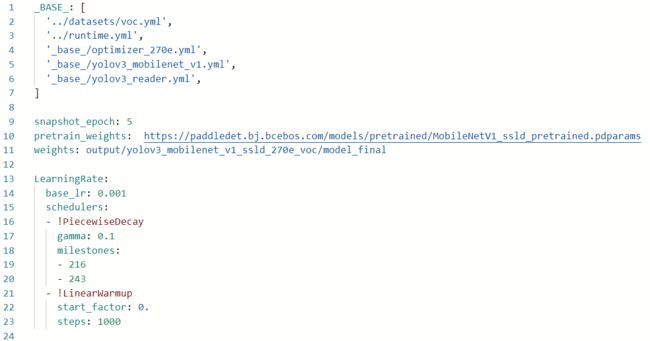
4.2配置文件详细说明
从上图看到yolov3_mobilenet_v3_large_ssld_270e_voc.yml配置需要依赖其他的配置文件。在该例子中需要依赖:
![[PaddleDetection保姆级教程]使用自定义数据集实现跌倒识别预测_第4张图片](http://img.e-com-net.com/image/info8/04ca16bdba934fc39a8c7a4f5f4b5abc.png)
在修改文件之前,先给大家解释一下各依赖文件的作用:
'_base_/optimizer_270e.yml',主要说明了学习率和优化器的配置,以及设置epochs。在其他的训练的配置中,学习率和优化器是放在了一个新的配置文件中。
'../datasets/voc.yml'主要说明了训练数据和验证数据的路径,包括数据格式(coco、voc等)
'_base_/yolov3_reader.yml', 主要说明了读取后的预处理操作,比如resize、数据增强等等
'_base_/yolov3_mobilenet_v3_large.yml',主要说明模型、和主干网络的情况说明。
'../runtime.yml',主要说明了公共的运行状态,比如说是否使用GPU、迭代轮数等等
介绍一下需要修改的几个地方(画红线的地方):
…/datasets/voc.yml

base/optimizer_270e.yml

4.3执行训练
执行下面命令开始进行训练
!python tools/train.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml --eval --use_vdl=True --vdl_log_dir="./output"
![[PaddleDetection保姆级教程]使用自定义数据集实现跌倒识别预测_第5张图片](http://img.e-com-net.com/image/info8/b696c6b8eb4b4e46bf7d59fd85bf5da7.jpg)
5.效果可视化
当打开use_vdl开关后,PaddleDetection会将训练过程中的数据写入VisualDL文件,可实时查看训练过程中的日志。记录的数据包括:
- loss变化趋势
- mAP变化趋势
使用如下命令启动VisualDL查看日志
# 下述命令会在127.0.0.1上启动一个服务,支持通过前端web页面查看,可以通过--host这个参数指定实际ip地址
visualdl --logdir output/
在浏览器输入提示的网址,效果如下:
visualdl --logdir output/
File "", line 1
visualdl --logdir output/
^
SyntaxError: invalid syntax
如果上面代码执行不成功,可以通过左端界面控制进行查看

具体操作可以去查看这个网站:https://my.oschina.net/u/4067628/blog/4839747(第三步骤)
![[PaddleDetection保姆级教程]使用自定义数据集实现跌倒识别预测_第6张图片](http://img.e-com-net.com/image/info8/31bd662c8c4f450e95ad77dc9fa1caca.jpg)
![[PaddleDetection保姆级教程]使用自定义数据集实现跌倒识别预测_第7张图片](http://img.e-com-net.com/image/info8/e3661e098aff4432bfeabdc7b6d606a4.jpg)
6.模型评估
python -u tools/eval.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml \
-o weights=output/yolov3_mobilenet_v3_large_ssld_270e_voc/best_model.pdparams
!python -u tools/eval.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml -o weights=output/yolov3_mobilenet_v3_large_ssld_270e_voc/best_model.pdparams
![[PaddleDetection保姆级教程]使用自定义数据集实现跌倒识别预测_第8张图片](http://img.e-com-net.com/image/info8/8c449f9ff1fd4ba1ae77804e52cab775.jpg)
7. 模型预测
在执行tools/infer.py后,在output文件夹下会生成对应的预测结果
python tools/infer.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml \
-o weights=output/yolov3_mobilenet_v3_large_ssld_270e_voc/best_model.pdparams \
--infer_img=/home/aistudio/work/fall4.jpg(需要检测的图片)
!python tools/infer.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml -o weights=output/yolov3_mobilenet_v3_large_ssld_270e_voc/best_model.pdparams --infer_img=/home/aistudio/work/fall4.jpg
- 结果展示
原图
![[PaddleDetection保姆级教程]使用自定义数据集实现跌倒识别预测_第9张图片](http://img.e-com-net.com/image/info8/b8f534c136fb4f05b8b84cd1f4810d7f.jpg)
![[PaddleDetection保姆级教程]使用自定义数据集实现跌倒识别预测_第10张图片](http://img.e-com-net.com/image/info8/917e18d0da984b8dab55008bcb3786d1.jpg)
预测图
![[PaddleDetection保姆级教程]使用自定义数据集实现跌倒识别预测_第11张图片](http://img.e-com-net.com/image/info8/e313bd68485f4307818d1c9004d49ec3.jpg)
![[PaddleDetection保姆级教程]使用自定义数据集实现跌倒识别预测_第12张图片](http://img.e-com-net.com/image/info8/dc4a10753607458aab94094586ba48bb.jpg)
总结
由上图我们可以看到,使用PaddleDetection完成了跌倒的目标识别检测,并且mAP已经达到了80.28%。
优化方案
可以通过增加数据集、选择更优化模型,增加训练的次数。
后期应用
后期可以部署到医院、疗养院等公共场合,甚至家里的监控中实现跌倒目标检测,可以及时救援,以免造成更大的损失。
关于更多关于PaddleDetection的信息请参考下面的链接地址。
PaddleDetection教程文档地址:https://github.com/PaddlePaddle/PaddleDetection
PaddleDetection Github地址:https://github.com/PaddlePaddle/PaddleDetection
关于作者
感兴趣的方向为:目标检测等
AIstudio主页: 我在AI Studio上获得白银等级,点亮3个徽章,来互关呀~ https://aistudio.baidu.com/aistudio/personalcenter/thirdview/474269
Github主页: https://github.com/Niki173
欢迎大家有问题留言交流学习,共同进步成长。