《零基础学机器学习》笔记-第1课-MNIST数字识别
机器学习项目的实际过程大致可以分为5个环节,下面以卷积神经网络分析MNIST数据集为例实战一下。
MNIST数据集-卷积神经网络-python源码下载
一、问题定义
MNIST数据集,相当于机器学习领域的Hello World,非常经典,包括60000张训练图像和10000张测试图像,都是28px*28px的手写数字灰度图像。
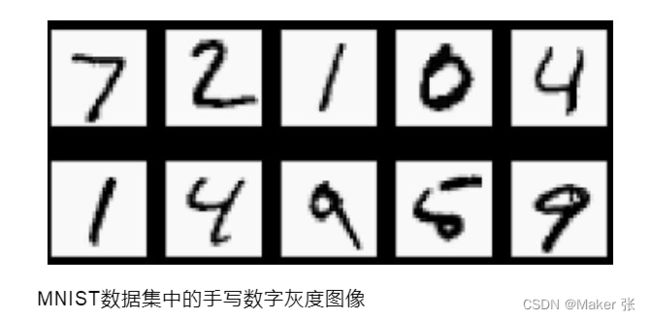
我们要解决的问题是:将手写数字灰度图像分类为0,1,2,3,4,5,6,7,8,9,共10个类别。
二、数据的收集和预处理






4.新建一个Jupyter Notebook,在其中载入Keras自带的MNIST数据集。
import numpy as np # 导入NumPy数学工具箱
import pandas as pd # 导入Pandas数据处理工具箱
from keras.datasets import mnist #从Keras中导入mnist数据集
#读入训练集和测试集
(X_train_image, y_train_lable), (X_test_image, y_test_lable) = mnist.load_data()
数据向量化的工作MNIST数据集已经为我们做好了的,直接显示出来:
print ("特征集张量形状:", X_train_image.shape) #用shape方法显示张量的形状
print ("第一个数据样本:\n", X_train_image[0]) #注意Python的索引是从0开始的



再看一下标签的格式:

上面的数据集再输入机器学习模型之前还要做一些数据格式转换的工作:
from tensorflow.keras.utils import to_categorical # 导入keras.utils工具箱的类别转换工具
X_train = X_train_image.reshape(60000,28,28,1) # 给标签增加一个维度
X_test = X_test_image.reshape(10000,28,28,1) # 给标签增加一个维度
y_train = to_categorical(y_train_lable, 10) # 特征转换为one-hot编码
y_test = to_categorical(y_test_lable, 10) # 特征转换为one-hot编码
print ("数据集张量形状:", X_train.shape) # 特征集张量的形状
print ("第一个数据标签:",y_train[0]) # 显示标签集的第一个数据
![]()

三、选择机器学习模型



from keras import models # 导入Keras模型, 和各种神经网络的层
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
model = models.Sequential() # 用序贯方式建立模型
model.add(Conv2D(32, (3, 3), activation='relu', # 添加Conv2D层
input_shape=(28,28,1))) # 指定输入数据样本张量的类型
model.add(MaxPooling2D(pool_size=(2, 2))) # 添加MaxPooling2D层
model.add(Conv2D(64, (3, 3), activation='relu')) # 添加Conv2D层
model.add(MaxPooling2D(pool_size=(2, 2))) # 添加MaxPooling2D层
model.add(Dropout(0.25)) # 添加Dropout层
model.add(Flatten()) # 展平
model.add(Dense(128, activation='relu')) # 添加全连接层
model.add(Dropout(0.5)) # 添加Dropout层
model.add(Dense(10, activation='softmax')) # Softmax分类激活,输出10维分类码
# 编译模型
model.compile(optimizer='rmsprop', # 指定优化器
loss='categorical_crossentropy', # 指定损失函数
metrics=['accuracy']) # 指定验证过程中的评估指标

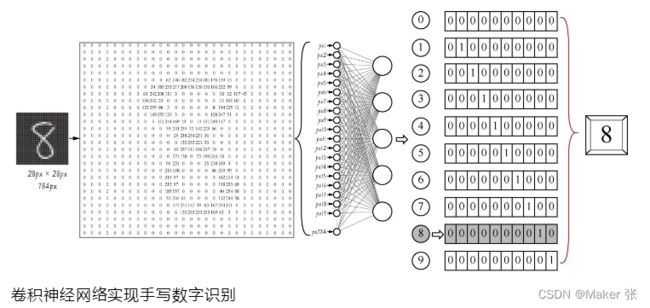
四、训练机器,确定参数

model.fit(X_train, y_train, # 指定训练特征集和训练标签集
validation_split = 0.3, # 部分训练集数据拆分成验证集
epochs=5, # 训练轮次为5轮
batch_size=128) # 以128为批量进行训练

以上五轮训练中,准确率逐步提高。
accuracy:代表训练集上的预测准确率,最后一轮达到了0.9720。
val_accuracy:代表验证集上的预测准确率,最后一轮达到了0.9856。
五、超参数调试和性能优化







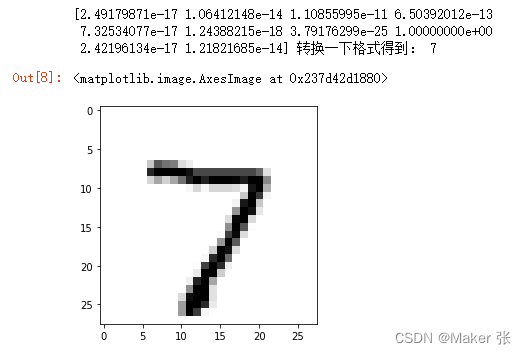
pred = model.predict(X_test[0].reshape(1, 28, 28, 1)) # 预测测试集第一个数据
print(pred[0],"转换一下格式得到:",pred.argmax()) # 把one-hot码转换为数字
import matplotlib.pyplot as plt # 导入绘图工具包
plt.imshow(X_test[0].reshape(28, 28),cmap='Greys') # 输出这个图片