(学习笔记01)MNIST手写数字的识别(tensorflow + CPU)
MNIST手写数字的识别
本节将学习机器学习的分类开发应用,即MNIST手写数字的识别。对此,我们通过建立一个两层神经网络的模型来用于识别图片里面的数字。
MNIST数据集介绍
MNIST是一个非常有名的手写体数字识别数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张28像素 × 28像素的灰度图像(1通道),各个像素的取值在0到255之间。每个图像数据都相应地标有“1”“2”“3”等标签,如下图所示。

更多MNIST数据集的详细介绍可参考:MNIST数据集介绍
- 下载数据集:
MNIST数据集下载网址:MNIST数据集下载
下载到本地后该数据集共有四个压缩文件,如下图所示,可根据需要移动到指定路径。
当然,也可以通过 tensorflow 来自动下载和安装这个数据集。
下载以后的数据集包括:
- Training set images[训练图集]: train-images-idx3-ubyte.gz (包含 60000 个样本)
- Training set labels[训练标签集]: train-labels-idx1-ubyte.gz (包含 60000 个标签)
- Test set images[测试图集]: t10k-images-idx3-ubyte.gz (包含 10000 个样本)
- Test set labels[测试标签集]: t10k-labels-idx1-ubyte.gz (包含 10000 个标签)
至此,数据的准备工作已完成。
环境搭建
-
-
环境说明
- 电脑系统:win10
- CPU: i5
-
显卡:

-
-
本文采用
- python 3.5.2 / anaconda 4.2.0
- tensorflow 1.2.1(CPU版本)
我们将在anaconda中集合的 jupyter notebook 中进行模型的训练。
模型训练
1.数据读取
tensorflow 提供了数据集读取的方法:
import tensorflow as tf
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist = input_data.read_data_sets("xxx", one_hot = True)
其中 “xxx” 是你存放数据集的路径,可通过数据集属性进行查看。
[tips]: 这个路径要自己手动输入才可以,不要忘了将路径中的’ \ ‘更换为’ / '。
在 jupyter 中运行之后结果为:

input_data.read_data_sets() 函数里面有两个参数:第一个为数据集所放的路径;第二个参数是one_hot (独热编码),设置为True,当然也可以把它设置为False,这两种情况下读进来的标签的数据格式是不一样的。当one_hot设置为True时,则对应的位置的值为1,其余都是0。

如果这个数字为3,就让下标为3的地方值为1,其他都为0。如果是8,就让下标为8的地方值为1,其他都为0。
[tips]: 如果是第一次读取MNIST数据集,在指定目录下不存在这个文件,那么它会自动去网上下载对应的文件,不过需要一定的等待时间;如果数据集已经存在了,那么它就会直接读取数据,速度会比较快。
2.模型构建
-
定义全连接层函数
不管有多少层,对于每一层的定义都可以通过这个函数来解决。
def fcn_layer(inputs,
input_dim,
output_dim,
activation=None):
W = tf.Variable(tf.truncated_normal([input_dim, output_dim], stddev=0.1))
b = tf.Variable(tf.zeros([output_dim]))
XWb = tf.matmul(inputs,W) + b
if activation is None:
outputs = XWb
else:
outputs = activation(XWb)
return outputs
定义了一个函数 fcn_layer(),它有四个参数:
| 参数 | 解释 |
|---|---|
| inputs | 这一层网络的输入数据 |
| input_dim | 输入神经元的数量 |
| output_dim | 输出神经元的数量 |
| activation | 激活函数(缺省值为None) |
-
权重与偏置项定义:
-
- 权值W:它是TensorFlow的一个变量(tf.Variable),它的形状为输入的神经元数量以及输出的神经元数量,以截断的正态分布随机数来初始化,它的标准差为0.1。
-
- 偏置项b:以0来初始化偏置项b,它的形状为输出的神经元数量。
- 定义待输入数据的占位符
x = tf.placeholder(tf.float32, [None, 784],name = 'X' )
y = tf.placeholder(tf.float32, [None, 10],name = 'Y' )
x是输入图像数据的占位符。每张图片是28×28大小的灰度图,有784列,相当于把它每⼀行像素点都拉平,形成⼀个⼀维数组。因为需要批量进行训练,每次代入的样本是⼀个批量,所以对于行先设为None。
y是标签数据的占位符,因为这个标签是转换成one_hot形式的,是⼀个十分类的标签,所以列数为10列,行跟刚才的特征值⼀样,用None保留,允许后面产生多行。
- 定义隐藏层神经元数量
H1_NN = 256 # 第1隐藏层神经元为256个
H2_NN = 64 # 第2隐藏层神经元为64个
- 构建网络
直接调用上面所定义的 fcn_layer 函数。
# 构建隐藏层1
h1 = fcn_layer(inputs=x,
input_dim=784,
output_dim=H1_NN,
activation=tf.nn.relu)
# 构建隐藏层2
h2 = fcn_layer(inputs=h1,
input_dim=H1_NN,
output_dim=H2_NN,
activation=tf.nn.relu)
# 构建输出层
forward = fcn_layer(inputs=h2,
input_dim=H2_NN,
output_dim=10,
activation=None)
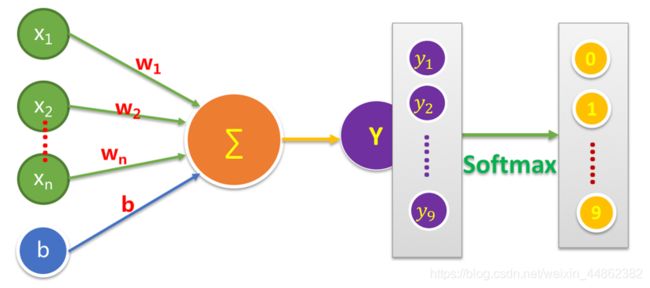
pred = tf.nn.softmax(forward)
这里可以直接调用tensorflow中提供的 softmax函数 来实现分类,即把计算出来的y值通过softmax函数转换成为它属于这十个类别中哪⼀类的概率值,转换后的y是一个有十个元素的向量,其中的每个分量表示属于对应类别的概率值。
- 定义损失函数
loss_function = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = forward, labels = y))
tf.nn.softmax_cross_entropy_with_logits() 函数是tensorflow中常用的求交叉熵的函数。第一个参数 logits:就是神经网络最后一层的输出,如果有batch的话,它的大小就是[batchsize,y],单样本的话,大小就是y。
- 设置训练参数
train_epochs = 40
batch_size = 50
total_batch = int(mnist.train.num_examples/batch_size)
display_step = 1
learning_rate = 0.01
-
这一部分是对一些超参数的设定。
-
- train_epochs = 40 设定训练轮数为50轮
-
- batch_size = 50 小批量输入样本数量设置为50,训练集中图片数量是55000,除以50,即一个 epoch训练需要1100次。.
-
- display_steps = 1 用来显示粒度,表示后面显示当前的损失及精确率的控制粒度。
-
- learning_rate = 0.01 学习率初始化为0.01。
所谓的训练模型就是根据训练的结果去调整这些超参数。
- 选择适合的优化器
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(loss_function)
tensorflow中常见的优化器有:GradientDescentOptimizer、AdagradOptimizer、AdagradDAOptimizer、MomentumOptimizer、AdamOptimizer、RMSPropOptimize.
AdamOptimizer 是梯度下降算法的一种变形,但是每次迭代参数的学习率都有一定的范围,不会因为梯度很大而导致学习率(步长)也变得很大,参数的值相对比较稳定。
3.训练模型
from time import time
startTime=time()
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
for epoch in range(train_epochs):
for batch in range(total_batch):
xs,ys = mnist.train.next_batch(batch_size)
sess.run(optimizer, feed_dict={x:xs, y:ys})
loss,acc = sess.run([loss_function,accuracy],
feed_dict = {x:mnist.validation.images, y:mnist.validation.labels})
if(epoch+1) %display_step == 0:
print("Train Epoch:",'%02d' %(epoch+1),"Loss=","{:.9f}".format(loss),"Accuracy=","{:.4f}".format(acc))
duration = time() - startTime
print("Train Finished takes:","{:.2f}".format(duration))
-
代码解析:
-
- 第一部分记录了训练开始的时间,在结束时记录了整个训练运行的时间花费,并打印在最后。
-
- 第二部分启动会话,并进行变量初始化。
-
- 第三部分for循环开始进行训练,每次通过 tensorflow 中封装好函数读取下一批数据,而且在读取之前,已经做了shuffle。然后把得到的样本值作为输入,送入优化器进行训练。
-
- 第四部分优化器每训练完一轮,即经过一次完整的for循环,可通过验证的数据集去验证数据的损失和准确率并显示出来。
训练后的结果如下图所示。
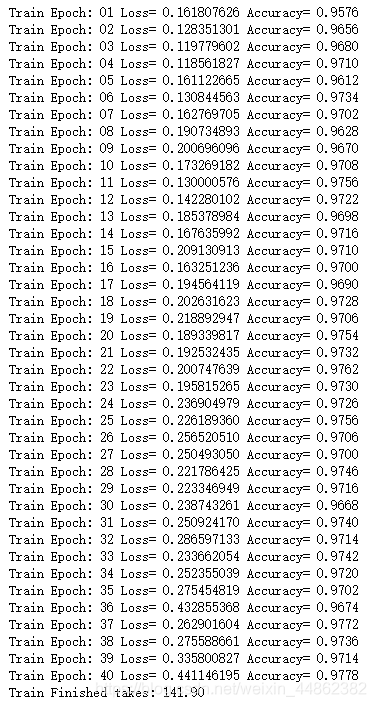
准确率可达到 97.78%。
模型评估
用测试集对训练好的模型进行评估,最后的结果为 97.58%。
accu_test = sess.run(accuracy,feed_dict={x:mnist.test.images, y:mnist.test.labels})
print("Test Accuracy:", accu_test)

到此已完成了模型的建立与训练,最后附上完整代码:
import tensorflow as tf
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist = input_data.read_data_sets("xxx", one_hot = True)
# 定义全连接层函数
def fcn_layer(inputs, # 输入数据
input_dim, # 输入神经元数量
output_dim, # 输出神经元数量
activation=None): # 激活函数
W = tf.Variable(tf.truncated_normal([input_dim, output_dim], stddev=0.1))
b = tf.Variable(tf.zeros([output_dim]))
XWb = tf.matmul(inputs,W) + b
if activation is None: # 默认不使用激活函数
outputs = XWb
else: # 若传入激活函数,则用其对输出结果进行变换
outputs = activation(XWb)
return outputs
# 定义标签数据占位符
x = tf.placeholder(tf.float32, [None, 784],name = 'X' )
# 隐藏层神经元数量
H1_NN = 256 # 第1隐藏层神经元为256个
H2_NN = 64 # 第2隐藏层神经元为64个
# 构建隐藏层1
h1 = fcn_layer(inputs=x,
input_dim=784,
output_dim=H1_NN,
activation=tf.nn.relu)
# 构建隐藏层2
h2 = fcn_layer(inputs=h1,
input_dim=H1_NN,
output_dim=H2_NN,
activation=tf.nn.relu)
# 构建输出层
forward = fcn_layer(inputs=h2,
input_dim=H2_NN,
output_dim=10,
activation=None)
pred = tf.nn.softmax(forward)
y = tf.placeholder(tf.float32, [None, 10],name = 'Y' )
loss_function = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = forward, labels = y))
# 设置训练参数
train_epochs = 40 #训练轮数
batch_size = 50 # 单次训练样本数(批次大小)
total_batch = int(mnist.train.num_examples/batch_size) # 一轮训练有多少批次
display_step = 1 # 显示粒度
learning_rate = 0.01 # 学习率
# 梯度下降优化器
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(loss_function)
# 定义准确率
# 检查预测类别tf.argmax(pred,1)与实际类别tf.argmax(y,1)的匹配情况
correct_prediction = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
# 准确率,将布尔值转化为浮点数,并计算平均值
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 记录训练开始时间
from time import time
startTime=time()
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
for epoch in range(train_epochs):
for batch in range(total_batch):
xs,ys = mnist.train.next_batch(batch_size) # 读取批次数据
sess.run(optimizer, feed_dict={x:xs, y:ys})
# total_batch个批次训练完成后,使用验证数据计算误差与准确率;验证集没有分批
loss,acc = sess.run([loss_function,accuracy],
feed_dict = {x:mnist.validation.images, y:mnist.validation.labels})
# 打印训练过程中的详细信息
if(epoch+1) %display_step == 0:
print("Train Epoch:",'%02d' %(epoch+1),"Loss=","{:.9f}".format(loss),"Accuracy=","{:.4f}".format(acc))
# 显示运行总时间
duration = time() - startTime
print("Train Finished takes:","{:.2f}".format(duration))
accu_test = sess.run(accuracy,feed_dict={x:mnist.test.images, y:mnist.test.labels})
print("Test Accuracy:", accu_test)