Redis总结
一 简介
Redis 是一个开源(BSD 许可)的内存数据结构存储,用作数据库、缓存和消息代理。 Redis 提供数据结构,例如字符串、散列、列表、集合、具有范围查询的排序集合、位图、超日志、地理空间索引和流。 Redis 具有内置复制、Lua 脚本、LRU 驱逐、事务和不同级别的磁盘持久性,并通过 Redis Sentinel 和 Redis Cluster 自动分区提供高可用性。
换句话说,可用以下几点概括:
1:Redis是一个基于内存存储的非关系型数据库
2:Redis提供了丰富的数据类型,比如String、hash、list、set、zset,来满足不同业务场景
3:Redis可以通过哨兵模式和分布式集群解决Redis在生产中的高可用问题
4:Redis的应用场景,可以将Redis作为mysql的一个补充,也可以将redis作为缓存服务。
二 Redis特性
速度快
基于键值对的数据结构服务器
丰富的功能,丰富的数据结构
简单稳定
客户端语言多
持久化
主从复制
高可用&分布式
三 Redis合适的应用场景
缓存
排行榜
计数器
分布式会话
分布式锁
社交网络
最新列表
消息系统
四 Redis高级功能有哪些?
消息队列
自动过期删除
事务,数据持久化
分布式锁
慢查询分析
Sentinel和集群等多项功能
五 如何安装Redis
下载安装包->解压->进入解压之后的目录进行编译->安装->运行
运行分为前台运行和后台运行(守护进程) 前台运行直接启动redis-server
但是命令端口不能进行其它操作.后台运行修改reids-conf中的daemonize no变为yes
六 Redis有哪几种数据类型
基础的有:字符串(String),哈希(Hash),列表(List),集合(Set),有序集合(Zset)
还有流,地理坐标等
String 操作语法
set pro 华为
key :pro
value:华为
expire pro 10 设置过期时间
ttl pro 查看剩余时间
setex pro 10 华为 设置pro 华为 同时设置过期时间为10秒
List 有序,可重复
k: String v:List
lpush(rpush) num 1 2 3 4
往左(右)存元素进去
lrange num 0 -1 查所有元素
lpop(rpop) num 1 往左(右)弹出一个元素并删除list中的数据
先进先出:lpush rpop
Set
无序不可重复
k:String V:Set
sadd 存
smembers 查看k中元素
srem 删除k中某一个元素
scard 获取k中的长度
Hash
key不能重复,重复则覆盖
K:String
V:Hash
存
hset person name 'jack'
hset person age 40
取
hget person name
hget person age
存多个
hmset person name 'rose' age 12
大小
hlen person
判断k是否存在
hexists person age
Zset
k:String
v:Zset
特点:有序,不可重复,通过score排序,且必须是数字
通过score进行排序
zadd hot 300 '华为met10' 10 '苹果10' 19 '小米'
zrange hot 0 -1
zrevrange hot 0 -1
#分数范围过滤
zrangebyscore hot 11 100
zrangebyscore hot 10 100 limit 0 1
#删除
zrem hot '小米'
zcard hot #查看集合的元素个数
七 Redis在idea中的使用
导入依赖
org.springframework.data
spring-data-redis
2.4.10
注入redis模板,调用其它api方法
八 Redis持久化
Redis持久化方案2种
RDB(Redis Databases):内存中的数据集快照写入磁盘,也就是 Snapshot 快照,恢复时是将快照文件直接读到内存里。
AOF(Append Of File):以日志的形式记录每个写操作(命令),当redis重启时,加载aof文件,将修改命令执行一遍。
rdb持久化如何触发
手动触发:
-
.正常关闭redis-server(shutdown手动)
-
2.save该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。显然该命令对于内存比较大的实例会造成长时间阻塞,这是致命的缺陷。
-
3.bgsave执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。具体操作是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
自动触发:
flushall:7变化,就会触发
主从同步触发
save xsecends n:表示在x秒内,有n个键发生变化,就会触发rdb持久化
aof持久化
aof持久化默认不开启,要开启需修改配置appendonly yes
aof有几种策略:一般开启appendfsync always

查询aof是否开启:config get appendonly
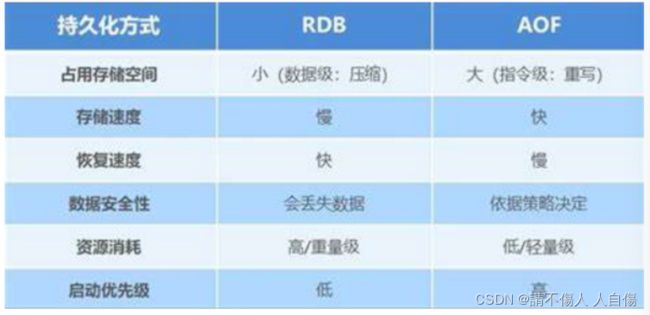
rdb对比aof
九 Redis集群配置
一主两从三哨兵
哨兵模式
哨兵职责:
监控(Monitoring):Sentinel 会不断地定期检查你的主服务器和从服务器是否运作正常。
提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
自动故障迁移(Automaticfailover): 当主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作,选举新主
哨兵:是整个集群的入口
分布式集群(java客户端连接)
导入依赖
redis.clients
jedis
2.9.0
org.springframework.data
spring-data-redis
2.0.12.RELEASE
面试题:Redis的Java客户端官方推荐?实际选择?
官方推荐的有3种: Jedis、 Redisson和lettuce 。
- -般来说用的比较多的有:Jedis I Redisson。
Jedis:更轻量、简介、不支持读写分离需要我们来实现,文档比较少。API提供了比较全面的Redis命令的支持
Redisson:基于Netty实现,性能高,支持异步请求。提供了很多分布式相关操作服务。高级功能能比较多,文档也比较丰富,但实用上复杂度也相对高。和Jedis相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等Redis特性。
十 Redis缓存的六类问题
缓存击穿
某一个热点key,在失效的一瞬间,持续的高并发访问击破缓存直接访问数据库,导致数据库造的访问压力
缓存击穿解决办法:
不设置过期时间(不推荐)
加锁(分布式锁),两次判断
缓存穿透
非法参数访问、数据库并不存在,缓存也无法命中,请求都会到数据库,从而可能压垮数据源
数据库中没有,同时Redis中也没有
方案一:缓存空值
缺点:存在大量垃圾数据
方案2:使用Redis set集群进行非法参数校验
弊端:集合判断元素是否存在 时间复杂度 O(n) 效率低
方案3:布隆过滤
初始化bloomfilter
最终版代码如下:
package com.qf.service.impl;
import cn.hutool.json.JSONUtil;
import com.qf.bloom.RedissonConfig;
import com.qf.entity.CmsContent;
import com.qf.mapper.CmsContentDao;
import com.qf.service.CmsContentService;
import org.redisson.api.RBloomFilter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.BoundValueOperations;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;
import org.springframework.util.StringUtils;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* @author: 玉米
* @description
* @date: 2022/3/25 16:16
*/
@Service
public class CmsContentServiceImpl implements CmsContentService {
@Autowired
private CmsContentDao cmsContentDao;
@Autowired
private StringRedisTemplate redisTemplate;
@Override
public List findCmsContentById(String cid) {
/* BoundListOperations boundListOperations = redisTemplate.boundListOps("menhu:index:cms:" + cid);
List range = boundListOperations.range(0, -1);
if(range==null||range.size()<=0){
//read from db
System.out.println("read from db");
List cmsContents = cmsContentDao.queryByCid(cid);
//缓存到redis
cmsContents.forEach(item->{
String toJsonStr = JSONUtil.toJsonStr(item);
boundListOperations.leftPush(toJsonStr);
});
//设置过期时间
redisTemplate.expire("menhu:index:cms:" + cid,30, TimeUnit.SECONDS);
return cmsContents;
}
//read from cache
System.out.println("read from cache");
List collect = range.stream().map(item -> {
CmsContent cmsContent = JSONUtil.toBean(item, CmsContent.class);
return cmsContent;
}).collect(Collectors.toList());
return collect;
}*/
RedissonConfig redissonConfig = new RedissonConfig();
RBloomFilter bloomFilter = redissonConfig.initRedissonClient();
//使用布隆过滤器进行非法参数校验
boolean contains = bloomFilter.contains(cid);
if(!contains){
return new ArrayList<>();
}
BoundValueOperations operations = redisTemplate.boundValueOps("portal:index:cat");
String JsonStr = operations.get();
if (StringUtils.isEmpty(JsonStr)) {
//没有命中
List cmsContents = new ArrayList<>();
synchronized (this) {
//从redis取数据
String JsonStr2 = operations.get();
if (StringUtils.isEmpty(JsonStr2)) {//redis没有命中
System.out.println("from db");
cmsContents = cmsContentDao.queryByCid(cid);
System.out.println("cache redis");
operations.set(JSONUtil.toJsonStr(cmsContents));
redisTemplate.expire("portal:index:cat",10, TimeUnit.MINUTES);
} else {//命中
System.out.println("from redis2");
cmsContents = JSONUtil.toList(JsonStr2, CmsContent.class);
}
}
return cmsContents;
} else {
System.out.println("from redis");
List cmsContents = JSONUtil.toList(JsonStr, CmsContent.class);
return cmsContents;
}
}}
什么是布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。
它实际上是一个很长的二进制数组和一系列随机映射(hash)函数。
布隆过滤器可以用于检索一个元素是否在一个集合中。
set ismember 时间复杂度O(n) 空间复杂度O(n)
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set(O(n))、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
布隆过滤器优缺点
优点:
-
由于存储的是二进制数据,所以占用的空间很小
-
它的插入和查询速度是非常快的,时间复杂度是O(K),可以联想一下HashMap的过程
-
保密性很好,因为本身不存储任何原始数据,只有二进制数据
缺点:
存在误判,但是可以通过加到二进制数组的长度以及增加hash的次数来降低误判率
缓存雪崩
缓存雪崩是缓存击穿的"大面积"版,缓存击穿是数据库缓存到Redis内的热点数据失效导致大量并发查询穿过redis直接击打到底层数据库,而缓存雪崩是指Redis中大量的key几乎同时过期,然后大量并发查询穿过redis击打到底层数据库上,此时数据库层的负载压力会骤增,我们称这种现象为"缓存雪崩"。事实上缓存雪崩相比于缓存击穿更容易发生,对于大多数公司来讲,同时超大并发量访问同一个过时key的场景的确太少见了,而大量key同时过期,大量用户访问这些key的几率相比缓存击穿来说明显更大。
解决方案
在可接受的时间范围内随机设置key的过期时间,分散key的过期时间,以防止大量的key在同一时刻过期;
延长热点key的过期时间或者设置永不过期,这一点和缓存击穿中的方案一样;
缓存预热
缓存预热如字面意思,当系统上线时,缓存内还没有数据,如果直接提供给用户使用,每个请求都会穿过缓存去访问底层数据库,如果并发大的话,很有可能在上线当天就会宕机,因此我们需要在上线前先将数据库内的热点数据缓存至Redis内再提供出去使用,这种操作就成为"缓存预热"。
解决方案:
缓存预热的实现方式有很多,比较通用的方式是写个批任务,在启动项目时或定时去触发将底层数据库内的热点数据加载到缓存内。
缓存降级
Redis服务不可用,或者网络抖动,导致服务不稳定
解决方案:
使用Sentinel熔断降级策略进行服务熔断降级
面试题
Redis内存满了怎么办?
设置Redis内存大小
1、通过配置文件配置
通过在Redis安装目录下面的redis.conf配置文件中添加以下配置设置内存大小
//设置Redis最大占用内存大小为100M maxmemory 100mb
2、通过命令修改
Redis支持运行时通过命令动态修改内存大小
//设置Redis最大占用内存大小为100M 127.0.0.1:6379> config set maxmemory 100mb //获取设置的Redis能使用的最大内存大小 127.0.0.1:6379> config get maxmemory
如果不设置最大内存大小或者设置最大内存大小为0,在64位操作系统下不限制内存大小,在32位操作系统下最多使用3GB内存
Redis的内存淘汰
既然可以设置Redis最大占用内存大小,那么配置的内存就有用完的时候。那在内存用完的时候,还继续往Redis里面添加数据不就没内存可用了吗?
实际上Redis定义了几种策略用来处理这种情况:
-
noeviction(默认策略):对于写请求不再提供服务,直接返回错误(DEL请求和部分特殊请求除外)
-
allkeys-lru:从所有key中使用LRU算法进行淘汰,LRU(Least Recently Used)
-
volatile-lru:从设置了过期时间的key中使用LRU算法进行淘汰,LRU(Least Recently Used)
-
allkeys-random:从所有key中随机淘汰数据
-
volatile-random:从设置了过期时间的key中随机淘汰
-
volatile-ttl:在设置了过期时间的key中,根据key的过期时间进行淘汰,越早过期的越优先被淘汰
当使用volatile-lru、volatile-random、volatile-ttl这三种策略时,如果没有key可以被淘汰,则和noeviction一样返回错误
查询当前内存淘汰策略:
127.0.0.1:6379> config get maxmemory-policy
通过配置文件设置淘汰策略(修改redis.conf文件):
maxmemory-policy allkeys-lru
通过命令修改淘汰策略:
127.0.0.1:6379> config set maxmemory-policy allkeys-lru
Redis6的新特性
多线程
Redis多线程主要解决网络IO瓶颈,并不是解决CPU瓶颈
Redis6.0的多线程默认是禁用的,只使用主线程。如需开启需要修改redis.conf配置文件:
io-threads-do-reads yes
开启多线程后,还需要设置线程数,否则是不生效的。同样修改redis.conf配置文件
acl
Redis6之前Redis就只有一个用户(default)权限最高,通过配置文件的requirepass配置
Redis6版本推出了ACL(Access Control List)访问控制权限的功能,基于此功能,我们可以设置多个用户,为了保证向下兼容,Redis6保留了default用户和使用requirepass的方式给default用户设置密码,默认情况下default用户拥有Redis最大权限,我们使用redis-cli连接时如果没有指定用户名,用户也是默认default