mmdetection训练自己的COCO数据集及常见问题
训练自己的VOC数据集及常见问题见下文:
mmdetection训练自己的VOC数据集及常见问题_不瘦8斤的妥球球饼的博客-CSDN博客_mmdetection训练voc
目录
一、环境安装
二、训练测试步骤
三、常见问题
batch size设置
学习率和epoch的修改
训练过程loss为nan的问题
GPU out of memory
保存最佳权重文件
训练生成的.pth文件占用较大内存
一、环境安装
代码:GitHub - open-mmlab/mmdetection: OpenMMLab Detection Toolbox and Benchmark
官方安装教程:Prerequisites — MMDetection 2.23.0 documentation
或者mmdetection/get_started.md at master · open-mmlab/mmdetection · GitHub
二、训练测试步骤
步骤一:准备数据。首先根据规范的COCO数据集导入到项目目录下,如下所示:
mmdetection
├── mmdet
├── tools
├── configs
├── data
│ ├── coco
│ │ ├── annotations(放json文件train,val,test)
│ │ ├── train2017(放图片)
│ │ ├── val2017(放图片)
│ │ ├── test2017(放图片)推荐以软连接的方式创建:
cd mmdetection
mkdir data
ln -s $COCO2017_ROOT data/coco其中,$COCO2017_ROOT需改为你的coco数据集根目录。
自定义的数据集可借鉴一个大佬的.xml转为coco格式的.json文件代码:把voc格式的标注文件.xml转为coco格式的.json文件_ming.zhang的博客-CSDN博客_pascal voc标注格式
#注意:
- 将图片和.xml文件放在同一文件夹下
- 其中xml_list = glob.glob(xml_dir +"/*.xml")中glob.glob要使用绝对路径。
运行该代码可将数据集按照9:1分成训练集和测试集。
步骤二:修改config.py
在configs文件夹中选择自己要训练的config文件,例如:faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py
选好后,打开可以看到faster_rcnn_r50_fpn_1x_coco.py的基础配置如下:

需要修改前两个文件(如红框所示):
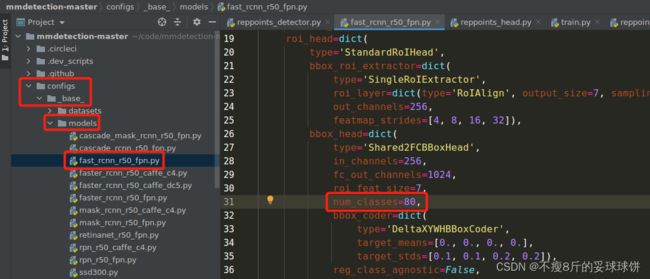
1. 退到上级目录找到_base_,找到faster_rcnn_r50_fpn.py,修改原COCO类的数目:
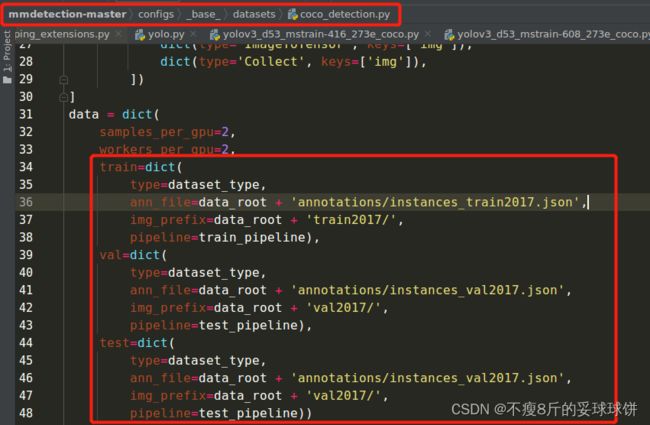
2. 在../_base_/datasets/coco_detection.py修改成你的数据源:
步骤三:修改mmdetection/mmdet/datasets目录下coco.py
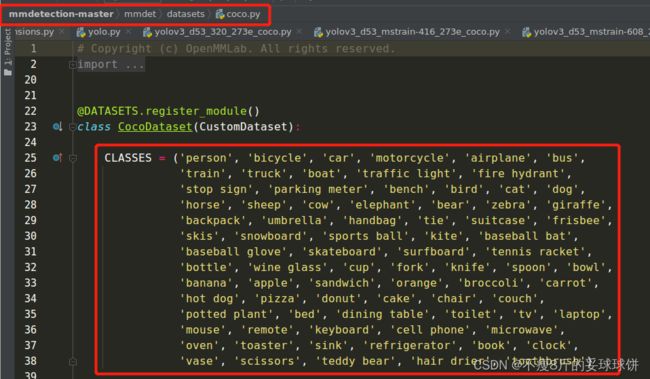
修改CLASSES成自己的类别数,如果是一个类别,需要写成CLASSES = ('person',)【需要加一个逗号】,否则会出现 “AssertionError: CLASSES in RepeatDatasetshould be a tuple of str.Add comma if number of classes is 1 as CLASSES = (person,)” 的错误。
步骤四:修改mmdetection/mmdet/core/evaluation目录下class_names.py

步骤五:运行python setup.py install,重新编译
![]()
步骤六:运行训练代码
1. 使用单个GPU进行训练
python ./tools/train.py ${CONFIG_FILE} [optional arguments]
python ./tools/train.py configs/faster_rcnn/faster_rcnn_r50_fpn.py --work_dir models2.使用多个GPU进行训练
./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
./tools/dist_train.sh configs/faster_rcnn/faster_rcnn_r50_fpn.py[optional arguments] 可选参数
--no-validate : 不建议使用,代码中每隔K(默认为1)执行评估,可以在configs/_base_/datasets/voc0712.py 修改evaluation = dict(interval=1, metric='mAP')
--work-dir ${WORK_DIR} 覆盖配置文件中指定的工作目录
--resume-from ${CHECKPOINT_FILE} 程序中断后继续训练,从先前的检查点文件恢复
--options 'Key=value' : 在使用的配置中覆盖一些设置。
步骤七:测试:
# single-gpu testing
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] [--show]三、常见问题
batch size设置

学习率和epoch的修改

重要:配置文件中的默认学习率(lr=0.02)是8个GPU和samples_per_gpu=2(批大小= 8 * 2 = 16)。根据线性缩放规则,如果您使用不同的GPU或每个GPU的有多少张图像,则需要按批大小设置学习率,例如,对于4GPU* 2 img / gpu=8,lr =8/16 * 0.02 = 0.01 ;对于16GPU* 4 img / gpu=64,lr =64/16 *0.02 = 0.08 。
计算公式:lr = (gpu_num * samples_per_gpu) / 16 * 0.02
![]()
训练过程loss为nan的问题
常见问题解答 — MMDetection 2.23.0 文档
1.检查数据的标注是否正常
长或宽为 0 的框可能会导致回归 loss 变为 nan,一些小尺寸(宽度或高度小于 1)的框在数据增强(例如,instaboost)后也会导致此问题。 因此,可以检查标注并过滤掉那些特别小甚至面积为 0 的框,并关闭一些可能会导致 0 面积框出现数据增强。
2.降低学习率
一般出现loss nan,无非是网络传输的梯度过大导致的,所以首先考虑在模型配置schedule_1x.py里减小模型的学习率。可是学习率调小100倍甚至10000倍,还出现nan的情况,所以考虑其他原因导致。先排除学习率的影响,将学习率设为0,loss依旧nan,然后就可以尝试下一个了。
3.延长 warm up 的时间
一些模型在训练初始时对学习率很敏感,可以在模型配置schedule_1x.py里把 warmup_iters 从 500 更改为 1000 或 2000。
4.梯度裁剪
一些模型需要梯度裁剪来稳定训练过程。 默认的 grad_clip 是 None, 你可以在模型配置schedule_1x.py里设置 optimizer_config=dict(_delete_=True, grad_clip=dict(max_norm=35, norm_type=2)) 如果你的 config 没有继承任何包含 optimizer_config=dict(grad_clip=None), 你可以直接设置optimizer_config=dict(grad_clip=dict(max_norm=35, norm_type=2))。
5.不使用fp16训练
如果用了fp16训练,可尝试将其注释掉。
# fp16 = dict(loss_scale=512.)GPU out of memory
常见问题解答 — MMDetection 2.23.0 文档
-
存在大量 ground truth boxes 或者大量 anchor 的场景,可能在 assigner 会 OOM。 您可以在 assigner 的配置中设置
gpu_assign_thr=N,这样当超过 N 个 GT boxes 时,assigner 会通过 CPU 计算 IOU。 -
在 backbone 中设置
with_cp=True。 这使用 PyTorch 中的sublinear strategy来降低 backbone 占用的 GPU 显存。 -
使用
config/fp16中的示例尝试混合精度训练。loss_scale可能需要针对不同模型进行调整。
保存最佳权重文件
将evaluation = dict(interval=1, metric='bbox')改为
evaluation = dict(interval=1, metric='bbox', save_best='auto')训练生成的.pth文件占用较大内存
可修改configs/base/default_runtime.py文件中:
checkpoint_config = dict(interval=10) # interval=10 表示10个epoch保存一次参考链接:
使用mmdetection中的YOLOv3训练自己的数据集_菜菜2020的博客-CSDN博客_mmdetection yolov3