论文笔记:Meshed-Memory Transformer for Image Captioning
前言
在看这篇论文之前首先要了解transformer,如果还没了解的需要先去看transformer。本小白是在学习了transformer之后,开始阅读使用transformer来做image caption的文章。这篇论文是CVPR2020的一篇论文,作者在摘要中提到虽然基于Transformer的体系结构代表了序列建模任务(如机器翻译和语言理解)的最新水平。然而,它们对图像描述等多模态上下文的适用性仍然有待探索,所以作者为了fill the gap ,提出了M^2(Meshed Transformer with Memory)
论文创新点
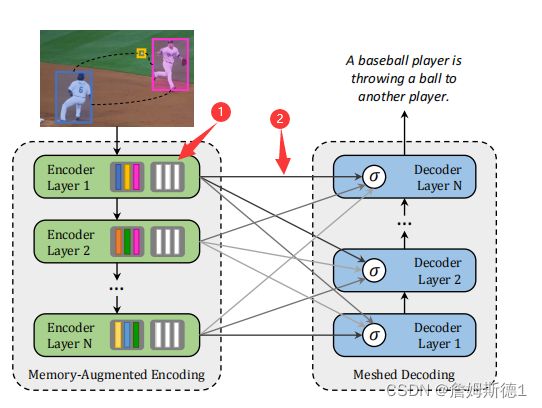
上图来自于原文,从上图可以大致看出encoder和decoder 框架上基本是没什么改动,创新点就在于图中标记的两处。
创新1.将图像区域和其关系编码为一个多层次结构,其中考虑了低层次和高层次关系。通过memory vector实现。这个memory vector就是图中白色的那部分,主要是用来编码先验知识。
创新2:句子的生成采用多层次结构,利用低层次和高层次的视觉关系。这是通过一个学习过的门控机制来实现的,该机制在每个阶段加权多层次的贡献。图中也可以看出编码器和解码器层之间创建了一个网格连接模式。
个人理解就是其中两个创新点都在于融合,无论是视觉特征的融合还是语义特征的融合,以及融合多模态,这样做显然比单模态,单层特征会更好
Meshed-Memory Transformer
首先就是整体描述了一下,说整个模型分为编码器和解码器模块,编码器负责处理输入图像的区域并设计它们之间的关系,解码器从每个编码层的输出中逐字读取并输出描述。文字和图像级特征之间的模态内和跨模态的交互都是通过缩放点积注意力来建模的,而不使用递归。然后给了一个Attention的公式,这个公式看过transformer的盆友应该很熟悉了

注意力操作基于三个向量:Q,K,V。根据Q和K向量之间的相似度分布,计算V向量的加权和
Memory-Augmented Encoder
然后论文给出了第二个公式

其中![]() ,
,![]() ,
,![]() 是可学习权重矩阵,输出的是一组新的元素S(X),与X有相同的基数,也就是说原始的从输入图像中提取的一组图像区域X,X中的每个元素都替换为值的加权和。因为自注意力机制是看自己和其他是否有比较紧密的关系,S(·)可以自然地对理解输入图像所需要的区域之间的成对关系进行编码,然后再进行描述。
是可学习权重矩阵,输出的是一组新的元素S(X),与X有相同的基数,也就是说原始的从输入图像中提取的一组图像区域X,X中的每个元素都替换为值的加权和。因为自注意力机制是看自己和其他是否有比较紧密的关系,S(·)可以自然地对理解输入图像所需要的区域之间的成对关系进行编码,然后再进行描述。
按照原文的表述,然而,self-attention有一个重大的局限性,self-attention不能对图像区域之间的关系建立先验知识模型,也就是S仅能代表两者之间有关系,但具体是什么关系就没办法表达了。原文也给了一个例子,给定一个编码人和一个编码篮球的区域,在没有任何先验知识的情况下,很难推断出球员或打球的概念。同样,给定编码鸡蛋和烤面包的区域,可以很容易地利用关系的先验知识推断出图片描述的是早餐。所以这个先验知识对图片描述的准确性还是有影响的。
Memory-Augmented Attention(记忆增强注意力层)
既然没有K向量和V向量没有地方放先验知识,那加个位置放不就好了。所以为了克服self-attention的局限性,作者提出了一个记忆增强注意力,将K和V的集合扩展一个“槽”来编码先验信息。先验不依赖于输入X,是一个普通的向量。并且这个 和
和![]() 可以直接通过SGD更新,于是也就有了下面这个公式
可以直接通过SGD更新,于是也就有了下面这个公式

其中和![]() 是可学习的矩阵,且[,]表示concat连接,也就是现在的K矩阵不只有本身,还带有编码了先验信息。直观地说,通过增加可学习的K和V,通过注意力机制将有可能检索到尚未嵌入X中的学习知识。 接下来最让我这个小白不理解的地方来了,因为transformer源码中,Q,K,V矩阵都是通过nn.Linear()转化来的,那和
是可学习的矩阵,且[,]表示concat连接,也就是现在的K矩阵不只有本身,还带有编码了先验信息。直观地说,通过增加可学习的K和V,通过注意力机制将有可能检索到尚未嵌入X中的学习知识。 接下来最让我这个小白不理解的地方来了,因为transformer源码中,Q,K,V矩阵都是通过nn.Linear()转化来的,那和![]() 既然可以直接通过SGD更新,它是如何训练的呢?
既然可以直接通过SGD更新,它是如何训练的呢?
然后我就从原文给的github中找寻了一下源码

前面还是熟悉的Q,K,V和 nn.Linear(),我发现和![]() 是使用nn.Parameter(),小白没见过这东西,于是搜寻了一下资料。
是使用nn.Parameter(),小白没见过这东西,于是搜寻了一下资料。

看到这应该就明白和![]() 是如何训练的了。
是如何训练的了。
Encoding layer
作者将记忆增强嵌入到一个类似transformer的层中,这句话很重要,说明encoder和transformer近似。然后给了我们几个几个公式。
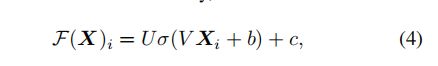

公式4中,其中![]() 表示输入集的第i个向量,F(
表示输入集的第i个向量,F(![]() )表示输出集的第i个向量,
)表示输出集的第i个向量,![]() 是Relu激活函数,V和U是可学习的权重矩阵,b和c是偏置项。AddNorm表示残差连接和layer norm层。
是Relu激活函数,V和U是可学习的权重矩阵,b和c是偏置项。AddNorm表示残差连接和layer norm层。

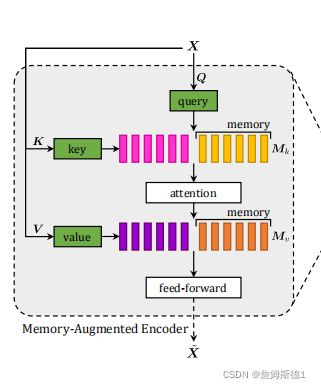
根据左边的transformer的流程图,因为作者将记忆增强嵌入到一个transformer的层中,所以经过公式3出来的![]() (X)就类比于transformer中Multi-Head的输出,然后经过AddNorm得到公式5中的Z,然后经过Fc层,只不过这个全连接层改了一下,最后再进行一个AddNorm得到
(X)就类比于transformer中Multi-Head的输出,然后经过AddNorm得到公式5中的Z,然后经过Fc层,只不过这个全连接层改了一下,最后再进行一个AddNorm得到![]()
Meshed Decoder
解码器以前面生成的单词和区域编码为条件,并负责生成输出描述的下一个token。作者设计了一个网格注意力操作,不同于Transformer,它可以利用句子生成过程中的所有编码层,利用上述输入图像的多层表示,构建多层结构。也就是最开始我们第一张图的第二部分。
那应该怎么融合多层表示呢?当然是加权求和。如下图所示,原来的transformer是用最后一层的encoder的输出当做K和V(图中蓝色箭头标出),现在作者既然要用到encoder中的每一层,自然需要对每一个输出![]() …
…![]() (图中红色框出部分)都做同样的操作。所以就有了下面的公式。
(图中红色框出部分)都做同样的操作。所以就有了下面的公式。

其中其中,C(,)代表编码器-解码器的Cross Attention,计算如下:

其实这还是Attention的计算,换汤不换药,只不过K和V变成了每一层encoder层的输出。
αi是一个权重矩阵,αi的权值调节各编码层的单一贡献,以及不同编码层之间的相对重要性。通过测量每个编码层的交叉注意结果与输入查询之间的相关性来计算这些数据,如下所示:

其中[,]表示concat连接,![]() 是sigmoid激活函数,Wi是权重矩阵,bi是偏置向量。
是sigmoid激活函数,Wi是权重矩阵,bi是偏置向量。
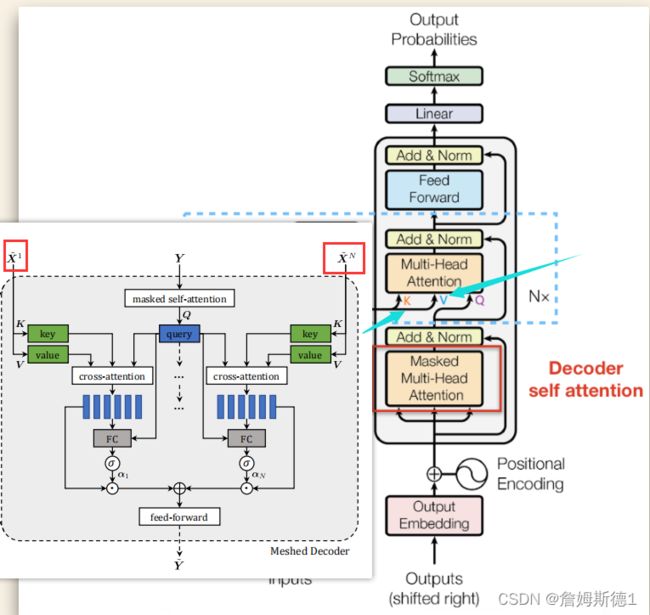
最终,解码的体系结构表达如下:

其实这跟上图右边的transformer结构也是类似的,先经过一个Mask attention得到上式中的![]() ,然后进入AddNorm,然后进行Q,K,V的attention计算,然后再经过一个AddNorm,最后经过跟encoder一样的Fc层,以及最后的AddNorm得到最终的Y,可以看到流程是跟transformer一样的。
,然后进入AddNorm,然后进行Q,K,V的attention计算,然后再经过一个AddNorm,最后经过跟encoder一样的Fc层,以及最后的AddNorm得到最终的Y,可以看到流程是跟transformer一样的。
总结
实验部分作者也花了比较大的心思,做了好几组消融实验,也和很多算法进行了对比,由于精力有限,暂且就不在这贴出来了,有兴趣的可以自己去阅读原文。
用一句话总结,作者提出了对self-attention中的K和V增加记忆槽以引入高层信息和先验知识的特征向量结构,和使用多重cross-attention作加权,利用低层次和高层次的视觉关系的encoder和decoder全连接结构。