pandas行列转换的4大技巧
公众号:尤而小屋
作者:Peter
编辑:Peter
大家好,我是Peter~
本文介绍的是Pandas中4个行列转换的方法,包含:
- melt
- 转置T或者transpose
- wide_to_long
- explode(爆炸函数)
最后回答一个读者朋友问到的数据处理问题。

Pandas行列转换
pandas中有多种方法能够实现行列转换:
导入库
import pandas as pd
import numpy as np
函数melt
melt的主要参数:
pandas.melt(frame,
id_vars=None,
value_vars=None,
var_name=None,
value_name='value',
ignore_index=True,
col_level=None)
下面解释参数的含义:
-
frame:要处理的数据框DataFrame。
-
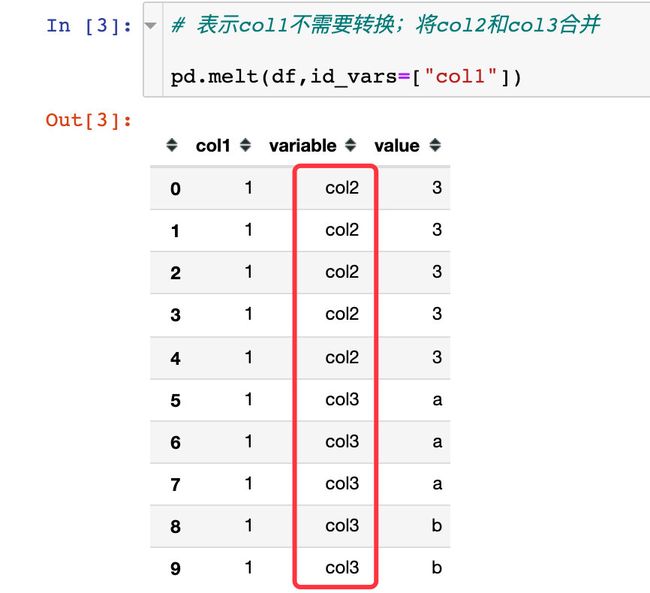
id_vars:表示不需要被转换的列名
-
value_vars:表示需要转换的列名,如果剩下的列全部都需要进行转换,则不必写
-
var_name和value_name:自定义设置对应的列名,相当于是取新的列名
-
igonore_index:是否忽略原列名,默认是True,就是忽略了原索引名,重新生成0,1,2,3,4…的自然索引
-
col_level:如果列是多层索引列MultiIndex,则使用此参数;这个参数少用
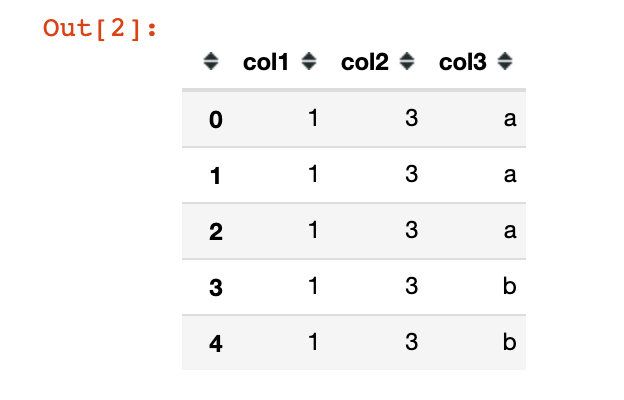
模拟数据
# 待转换的数据:frame
df = pd.DataFrame({"col1":[1,1,1,1,1],
"col2":[3,3,3,3,3],
"col3":["a","a","a","b","b"]
})
df
id_vars
value_vars

上面两个参数的同时使用:
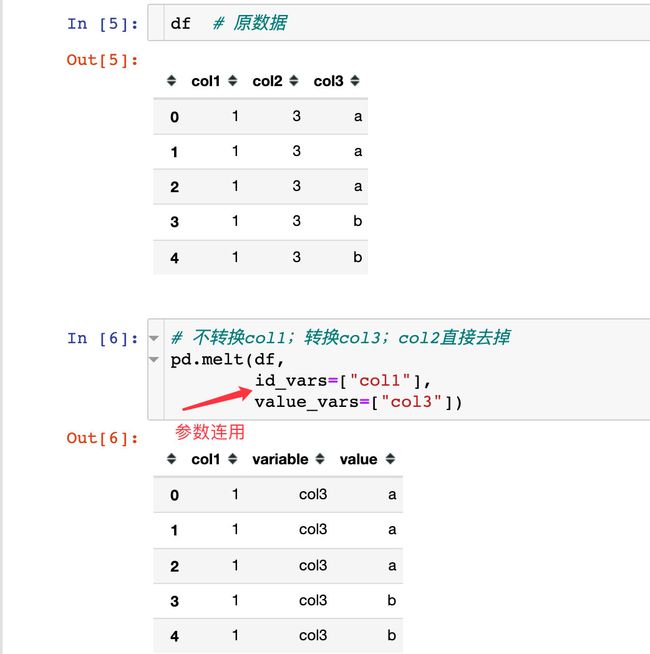
同时转换多个列属性:

var_name和value_name
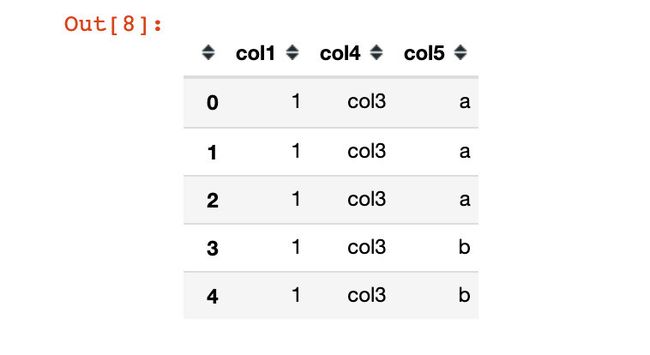
pd.melt(
df,
id_vars=["col1"], # 不变
value_vars=["col3"], # 转变
var_name="col4", # 新的列名
value_name="col5" # 对应值的新列名
)
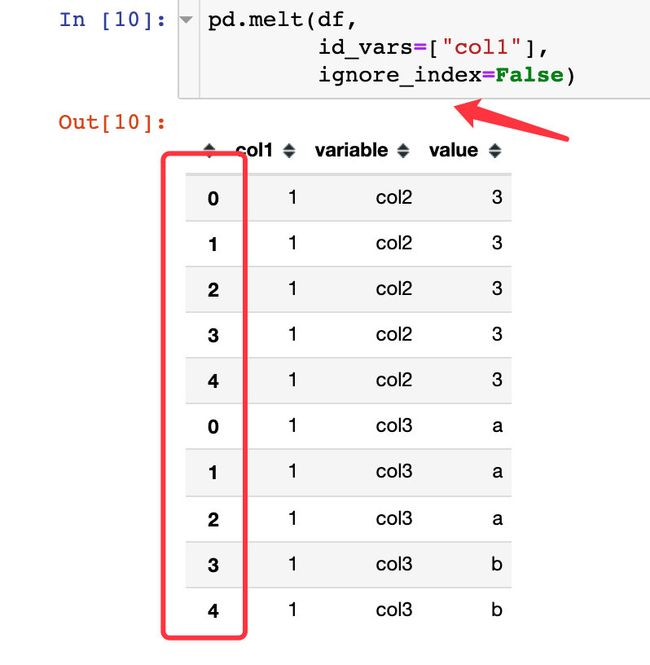
ignore_index
默认情况下是生成自然索引:

可以改成False,使用原来的索引:
转置函数
pandas中的T属性或者transpose函数就是实现行转列的功能,准确地说就是转置
简单转置
模拟了一份数据,查看转置的结果:

使用transpose函数进行转置:

还有另一个方法:先对值values进行转置,再把索引和列名进行交换:

最后看一个简单的案例:

wide_to_long函数
字面意思就是:将数据集从宽格式转换为长格式
wide_to_long(
df,
stubnames,
i,
j,
sep: str = "",
suffix: str = "\\d+"
参数的具体解释:
- df:待转换的数据框
- stubnames:宽表中列名相同的存部分
- i:要用作 id 变量的列
- j:给长格式的“后缀”列设置 columns
- sep:设置要删除的分隔符。例如 columns 为 A-2020,则指定 sep=’-’ 来删除分隔符。默认为空。
- suffix:通过设置正则表达式取得“后缀”。默认’\d+‘表示取得数字后缀。没有数字的“后缀”可以用’\D+'来取得
模拟数据
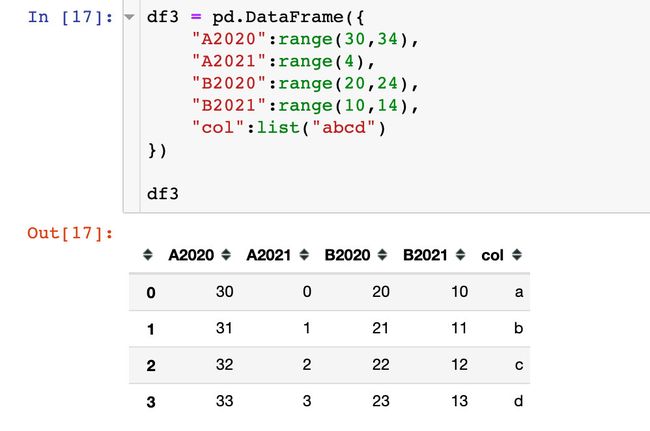
转换过程
使用函数实施转换:

设置多层索引
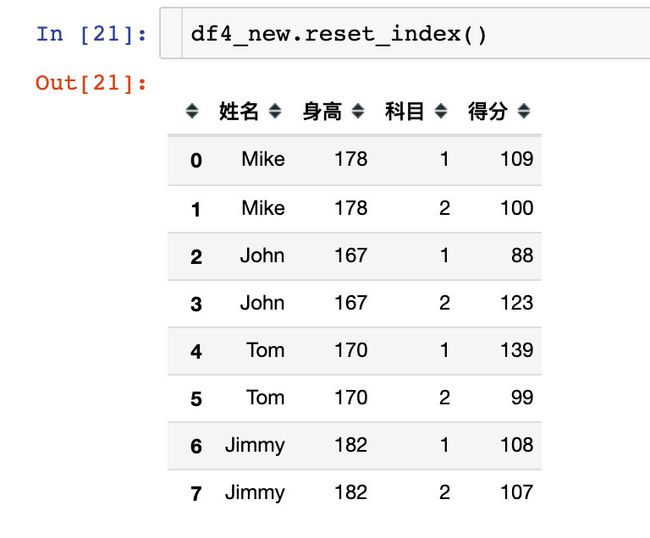
先模拟一份数据:


如果不习惯多层索引,可以转成下面的格式:
sep和suffix
df5 = pd.DataFrame({
'a': [1, 1, 2, 2, 3, 3, 3],
'b': [1, 2, 2, 3, 1, 2, 3],
'stu_one': [2.8, 2.9, 1.8, 1.9, 2.2, 2.3, 2.1],
'stu_two': [3.4, 3.8, 2.8, 2.4, 3.3, 3.4, 2.9]
})
df5

pd.wide_to_long(
df5,
stubnames='stu',
i=['a', 'b'],
j='number',
sep='_', # 列名中存在连接符时使用;默认为空
suffix=r'\w+') # 基于正则表达式的后缀;默认是数字\d+;这里改成\w+,表示字母

爆炸函数-explode
explode(column, ignore_index=False)
这个函数的参数就只有两个:
- column:待爆炸的元素
- ignore_index:是否忽略索引;默认是False,保持原来的索引
模拟数据
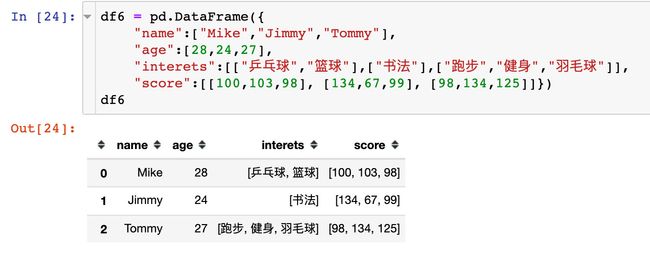
单个字段爆炸
对单个字段实施爆炸过程,将宽表转成长表:

参数ignore_index

多个字段爆炸
连续对多个字段实施爆炸的过程:

读者解疑
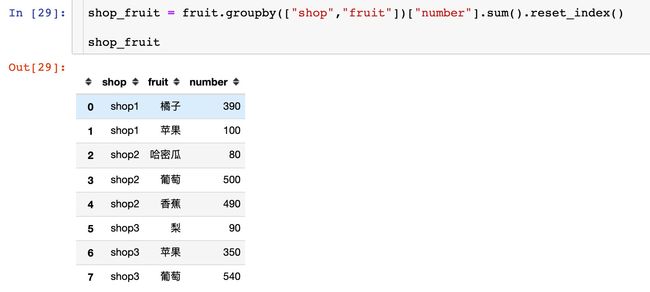
在这里回答一个读者的问题,数据采用模拟的形式。有下面的这样一份数据,需求:
每个shop下每个fruit在各自shop的占比
fruit = pd.DataFrame({
"shop":["shop1","shop3","shop2","shop3",
"shop2","shop1","shop3","shop2",
"shop3","shop2","shop3","shop2","shop1"],
"fruit":["苹果","葡萄","香蕉","苹果",
"葡萄","橘子","梨","哈密瓜",
"葡萄","香蕉","苹果","葡萄","橘子"],
"number":[100,200,340,150,
200,300,90,80,340,
150,200,300,90]})
fruit

首先我们是需要统计每个shop每个fruit的销量
方法1:多步骤
方法1采用的是多步骤解决:
1、每个shop的总销量

2、增加总和shop_sum列
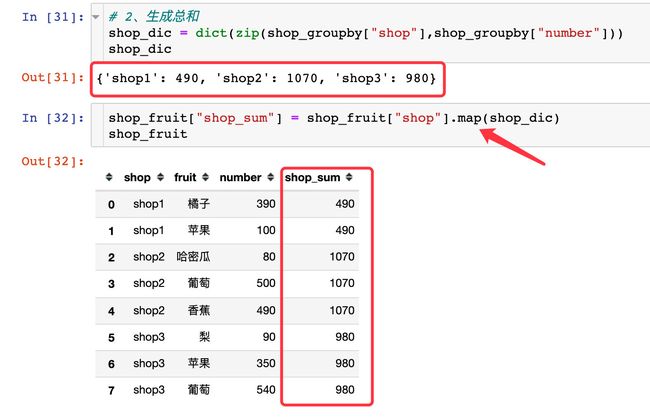
3、生成占比

方法2:使用transform函数
