图像分割UNet (2) : 使用Pytorch搭建UNet网络
本文介绍如何使用pytorch搭建UNet网络结构进行医学视网膜血管影像分割,源码下载
其中UNet网络结构相关介绍可参博文:图像分割UNet (1):网络结构讲解

项目代码使用
参考开源仓库
- https://github.com/milesial/Pytorch-UNet
- https://github.com/pytorch/vision
环境配置:
- Python3.6/3.7/3.8
- Pytorch1.10
- Ubuntu或Centos(Windows暂不支持多GPU训练)
- 最好使用GPU训练
- 详细环境配置见
requirements.txt
文件结构:
├── src: 搭建U-Net模型代码
├── train_utils: 训练、验证以及多GPU训练相关模块
├── my_dataset.py: 自定义dataset用于读取DRIVE数据集(视网膜血管分割)
├── train.py: 以单GPU为例进行训练
├── train_multi_GPU.py: 针对使用多GPU的用户使用
├── predict.py: 简易的预测脚本,使用训练好的权重进行预测测试
└── compute_mean_std.py: 统计数据集各通道的均值和标准差
DRIVE数据集下载地址:
- 官网地址: https://drive.grand-challenge.org/,官网需要注册才可下载
- 百度云链接: https://pan.baidu.com/s/1Tjkrx2B9FgoJk0KviA-rDw 密码: 8no8
数据集目录
── training: 训练数据集
├──1st_manual 血管分割图
├──images 原始图片
├──mask 感兴趣区域
── test: 测试数据集
├──1st_manual 血管分割图
├──2st_manual 血管分割图
├──images 原始图片
├──mask 感兴趣区域
训练方法
- 确保提前准备好数据集
- 若要使用单GPU或者CPU训练,直接使用train.py训练脚本
- 若要使用多GPU训练,使用
torchrun --nproc_per_node=8 train_multi_GPU.py指令,nproc_per_node参数为使用GPU数量 - 如果想指定使用哪些GPU设备可在指令前加上
CUDA_VISIBLE_DEVICES=0,3(例如我只要使用设备中的第1块和第4块GPU设备) CUDA_VISIBLE_DEVICES=0,3 torchrun --nproc_per_node=2 train_multi_GPU.py
注意事项
- 在使用训练脚本时,注意要将
--data-path设置为自己存放DRIVE文件夹所在的根目录 - 在使用预测脚本时,要将
weights_path设置为你自己生成的权重路径。 - 使用validation文件时,注意确保你的验证集或者测试集中必须包含每个类别的目标,并且使用时只需要修改
--num-classes、--data-path和--weights即可,其他代码尽量不要改动
使用U-Net在DRIVE数据集上训练得到的权重(仅供测试使用)
模型是在DRIVE数据集上迭代了200个EPOCH,得到的训练权重。
- 链接: https://pan.baidu.com/s/1BOqkEpgt1XRqziyc941Hcw 密码: p50a
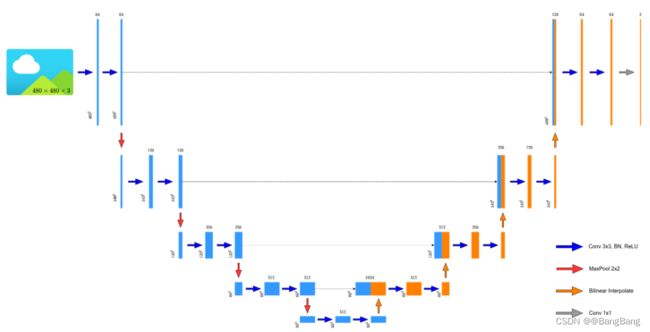
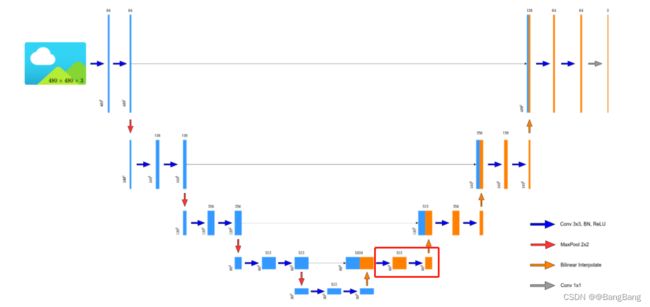
本项目U-Net默认使用双线性插值做为上采样,结构图如下
下图是重绘的UNet网络结构,在原论文实现的UNet它的每个卷积层都会改变卷积层的高和宽,参考:图像分割UNet (1):网络结构讲解。但现在主流方式是不会通过卷积层改变特征层的高和宽的,并且现在很多人都喜欢将转置卷积替换成简单的双线性差值上采样, 因此网络也是以双线性差值上采样进行绘制的。
项目的结构如下,我这边是将数据集DRIVE放在当前项目unet的目录下的,因此在训练脚本中,将读取数据集的路径data-path,默认是设置为与训练脚本同级目录:
parser.add_argument("--data-path", default="./", help="DRIVE root")
如果数据集改为其他地方,记得修改默认的data-path路径。
pytorch UNet 网络搭建
在unet 网络代码在 src -> unet.py文件中
定义DoubleConv模块
在网络结构中,卷积基本上都是成对使用的,所以就定义了一个DoubleConv类

DoubleConv 模块代码实现
class DoubleConv(nn.Sequential):
def __init__(self,in_channels,out_channels,mid_channels=None):
if mid_channels is None:
mid_channels=out_channels
super(DoubleConv,self).__init__(
nn.Conv2d(in_channels,mid_channels,kernel_size=3,padding=1,bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels,out_channels,kernel_size=3,padding=1,bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace = True)
)
in_channels: 指的是输入特征层的channelsout_channels: 指的是经过DoubleConv层后输出特征层的channelsmid_channels: 指第一个卷积层输出的channels- 通过父类的构造函数搭建
DoubleConv,其中Conv2d的Kernel=3,padding=1,设置padding=1经过卷积后不会改变特征层的大小,这也是现在主流的实现方式 - 由于我们会使用到
BN,因此将bias设置为Flase
定义Down 模块
Down模块包括下采样(MaxPool) + 2个Conv2d,因为在网络左侧encoder部分基本上都是通过下采样(MaxPool) + 2个Conv2d搭建的。

Down 模块代码实现:
class Down(nn.Sequential):
def __init__(self,in_channels,out_channels):
super(Down,self).__init__(
nn.MaxPool2d(2,stride=2),
DoubleConv(in_channels,out_channels)
)
定义UP 模块
UP模块包含:上采样(w,h翻倍)+concat拼接+2个Conv2d, 在UNet网络的右半部分decoder也就是解码器部分,基本上都是有各个上采样+concat拼接+2个Conv2d模块组成,因此这里定义了一个UP模块。
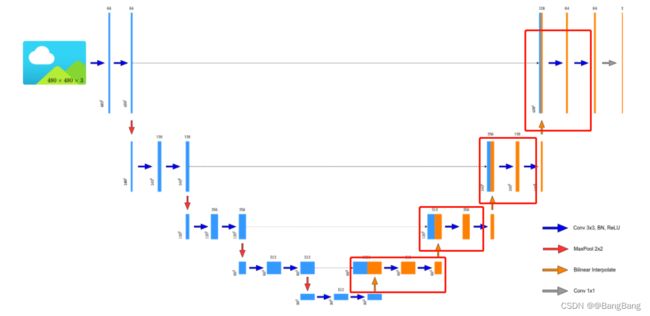
UP 模块代码实现:
class Up(nn.Module):
def __init__(self,in_channels,out_channels,bilinear=True):
super(Up,self).__init__()
if bilinear:
self.up=nn.Upsample(scale_factor=2,mode='bilinear',align_corners=True)
self.conv=DoubleConv(in_channels,out_channels,in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels,in_channels //2,kernel_size=2,stride=2)
self.conv=DoubleConv(in_channels,out_channels)
def forward(self,x1,x2):
x1=self.up(x1)
#[N,C,H,W]
diff_y=x2.size()[2] - x1.size()[2]
diff_x=x2.size()[3] - x1.size()[3]
# padding_left,padding_right,padding_top,padding_bottom
x1=F.pad(x1,[diff_x //2,diff_x - diff_x //2,
diff_y //2,diff_y - diff_y//2])
x=torch.cat([x2,x1],dim=1)
x=self.conv(x)
return x
- 输入参数
bilinear=True,表示默认情况下是会使用双线性差值 in_channels:指的是concat拼接后的channels,或者是up这个模块第一个卷积输入的channels- 如果
bilinear=False, 则使用论文中提到的转置卷积进行上采样,长宽翻倍,channels会减半,此时DoubleConv(in_channels,out_channels)中mid_channels和out_channels是一样的。因为在原论文中这两个卷积的channels是一样的。参考:图像分割UNet (1):网络结构讲解

- 如果采用双线性插值进行上采样的话(经过双线性插值自身不会改变channels),上采样后面跟着的两个卷积的channels是不一样的,比如通过第一个卷积后channels会减半,通过第二个卷积后,channels又会减半。这样做的目的是为了经过双线性插值后得到的channels和我们要concat拼接的特征层的channels保持一致。
- forward正向传播过程,x1指的是需要上采样的特征层,x2指的是要concat拼接的特征层。
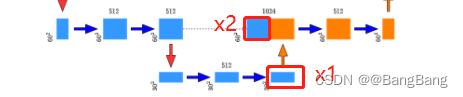
流程是:首先我们需要对x1进行上采样x1=self.up(x1)得到采样之后的特征层,按理说可以直接通过concat拼接,将两个特征层在我们的channels维度进行拼接就可以了。然后再通过两个卷积层得到我们的特征输出。
def forward(self,x1,x2):
x1=self.up(x1)
#[N,C,H,W]
diff_y=x2.size()[2] - x1.size()[2] # H
diff_x=x2.size()[3] - x1.size()[3] # W
# padding_left,padding_right,padding_top,padding_bottom
x1=F.pad(x1,[diff_x //2,diff_x - diff_x //2,
diff_y //2,diff_y - diff_y//2])
x=torch.cat([x2,x1],dim=1)
x=self.conv(x)
return x
但是这里作者有多做了一步,对我们上采样之后的x1进行了padding,目的是为了防止我们输入的图片如果不是16的整数倍的话,通过下采样得到的x1与我们要拼接的x2的高度和宽度是不一致的。
在我们unet的搭建过程下采样了4次也就是16倍,如果高和宽不是16的整数倍,那么在下采样的过程中,可能面临着向下取整的情况。比如在某个位置特征层大小是7x7的,经过下采样它的高和宽就变为3x3了,在通过上采样是6x6,很明显与7x7的特征层就无法拼接了。为了防止出现该问题,对x1进行了padding,padding之后就能保住x1和x2的高和宽是一致的了,这样就可以进行concat拼接了。
定义OutConv 模块
OutConv对应的是最后一个1x1的卷积层,通过这个1x1的卷积层之后就得到我们最终的输出了。这个1x1的卷积它是没有BN和ReLU激活函数的。
class OutConv(nn.Sequential):
def __init__(self,in_channels,num_classes):
super(OutConv,self).__init__(
nn.Conv2d(in_channels,num_classes,kernel_size=1)
)
UNet 网络整体搭建过程
class UNet(nn.Module):
def __init__(self,
in_channels: int = 1,
num_classes: int = 2,
bilinear: bool = True,
base_c: int = 64):
super(UNet, self).__init__()
self.in_channels = in_channels
self.num_classes = num_classes
self.bilinear = bilinear
self.in_conv = DoubleConv(in_channels, base_c)
self.down1 = Down(base_c, base_c * 2)
self.down2 = Down(base_c * 2, base_c * 4)
self.down3 = Down(base_c * 4, base_c * 8)
factor = 2 if bilinear else 1
self.down4 = Down(base_c * 8, base_c * 16 // factor)
self.up1 = Up(base_c * 16, base_c * 8 // factor, bilinear)
self.up2 = Up(base_c * 8, base_c * 4 // factor, bilinear)
self.up3 = Up(base_c * 4, base_c * 2 // factor, bilinear)
self.up4 = Up(base_c * 2, base_c, bilinear)
self.out_conv = OutConv(base_c, num_classes)
def forward(self, x: torch.Tensor) -> Dict[str, torch.Tensor]:
x1 = self.in_conv(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.out_conv(x)
return {"out": logits}
in_channels,输入的图片如果是彩色的,in_channels=3,如果使用的是黑白的`in_channels=1- bilinear 默认是True,根据测试无论采用双线性插值还是采用转置卷积计算,他们的结果其实是差不多的。那么你采用双线性差值其实会更高效点。
base_c就是网络中第一个卷积层输出的channels,在unet网络中各层的channels都是翻倍的,比如64,128,256,512,所以就定义了一个base channel,默认为64,也可以根据自己的想法去调整channels的大小。我这边训练的时候将base_c设置为32,发现得到的结果也没啥区别,但设置为32网络的参数会降低、训练速度会得到提升。- 然后经过down1,down2,dow3,down4,4个下采样过程,注意到down1~down3通过两层卷积后channels都翻倍了,但down4经过两层卷积后channels没有翻倍。因为我们要保证经过双线性差值上采样得到的channels要与拼接的特征的channels保持一致,所以这里就没有进行翻倍。因此对输出的channels除了一个factor,如果采用双线性差值factor=2,如果采用转置卷积的话(本身会对w,h翻倍,channels减半,而双线性插值不会影响channels),因此factor=1。
factor = 2 if bilinear else 1
self.down4 = Down(base_c * 8, base_c * 16 // factor)
完整的UNet搭建代码:
from typing import Dict
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Sequential):
def __init__(self, in_channels, out_channels, mid_channels=None):
if mid_channels is None:
mid_channels = out_channels
super(DoubleConv, self).__init__(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
class Down(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(Down, self).__init__(
nn.MaxPool2d(2, stride=2),
DoubleConv(in_channels, out_channels)
)
class Up(nn.Module):
def __init__(self, in_channels, out_channels, bilinear=True):
super(Up, self).__init__()
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor:
x1 = self.up(x1)
# [N, C, H, W]
diff_y = x2.size()[2] - x1.size()[2]
diff_x = x2.size()[3] - x1.size()[3]
# padding_left, padding_right, padding_top, padding_bottom
x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2,
diff_y // 2, diff_y - diff_y // 2])
x = torch.cat([x2, x1], dim=1)
x = self.conv(x)
return x
class OutConv(nn.Sequential):
def __init__(self, in_channels, num_classes):
super(OutConv, self).__init__(
nn.Conv2d(in_channels, num_classes, kernel_size=1)
)
class UNet(nn.Module):
def __init__(self,
in_channels: int = 1,
num_classes: int = 2,
bilinear: bool = True,
base_c: int = 64):
super(UNet, self).__init__()
self.in_channels = in_channels
self.num_classes = num_classes
self.bilinear = bilinear
self.in_conv = DoubleConv(in_channels, base_c)
self.down1 = Down(base_c, base_c * 2)
self.down2 = Down(base_c * 2, base_c * 4)
self.down3 = Down(base_c * 4, base_c * 8)
factor = 2 if bilinear else 1
self.down4 = Down(base_c * 8, base_c * 16 // factor)
self.up1 = Up(base_c * 16, base_c * 8 // factor, bilinear)
self.up2 = Up(base_c * 8, base_c * 4 // factor, bilinear)
self.up3 = Up(base_c * 4, base_c * 2 // factor, bilinear)
self.up4 = Up(base_c * 2, base_c, bilinear)
self.out_conv = OutConv(base_c, num_classes)
def forward(self, x: torch.Tensor) -> Dict[str, torch.Tensor]:
x1 = self.in_conv(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.out_conv(x)
return {"out": logits}