利用GPU训练模型
利用.cuda()函数
网络模型中,有三种变量可以调用.cuda(),分别是网路模型、数据(输入、标注)、损失函数,调用完需要返回。
以之前的一个网络为例:
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10),
)
def forward(self, x):
x = self.model(x)
return x
loss = nn.CrossEntropyLoss()
model = Model()
optim = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(20):
sum = 0
for data in dataloader:
imgs, targets = data
outputs = model(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad()
result_loss.backward()
optim.step()
sum = sum+result_loss
print(sum)
分别调用.cuda():
loss = nn.CrossEntropyLoss().cuda()#将损失函数转移到cuda上
model = Model().cuda()#将网络模型转移到cuda上
...
for data in dataloader:
imgs, targets = data
imgs = imgs.cuda()#数据输入转移到cuda上
targets = targets.cuda()#数据标注转移到cuda上
...然后就可以利用gpu进行训练,输出结果:
tensor(18662.0469, device='cuda:0', grad_fn=
)
tensor(16061.3145, device='cuda:0', grad_fn=)
tensor(15350.5762, device='cuda:0', grad_fn=) ...
如果电脑没有gpu或者gpu没有配置成功则会报错,可以加一个条件语句:
loss = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss = loss.cuda()如果可以利用gpu时,在将其转移到cuda上,否则就在CPU训练。
我们使用time查看CPU和GPU训练时间差别:
import time
for epoch in range(20):
start_time = time.time()
sum = 0
for data in dataloader:
imgs, targets = data
imgs = imgs.cuda()#数据输入转移到cuda上
targets = targets.cuda()#数据标注转移到cuda上
outputs = model(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad()
result_loss.backward()
optim.step()
sum = sum+result_loss
print(sum)
end_time = time.time()
print(end_time - start_time)使用GPU训练:
tensor(18699.9785, device='cuda:0', grad_fn=
)
17.295462369918823
tensor(16166.4746, device='cuda:0', grad_fn=)
14.85786747932434...使用CPU训练:
tensor(18777.4297, grad_fn=
)
21.17310380935669
tensor(16230.0479, grad_fn=)
19.265528202056885...
在terminal输入nvidia-smi可以查看GPU的一些信息
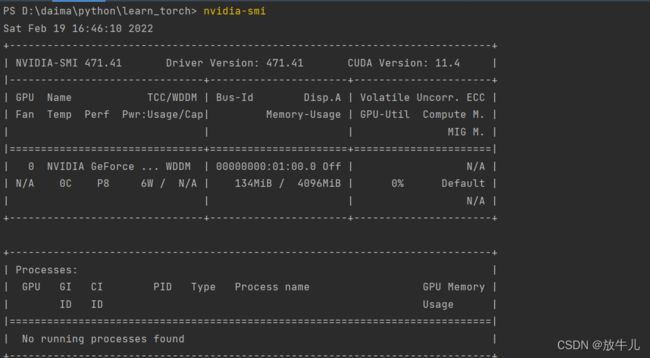
使用Google colab
谷歌搜索Google colab,使用谷歌提供的一个免费的GPU:
创建一个笔记本,导入torch:
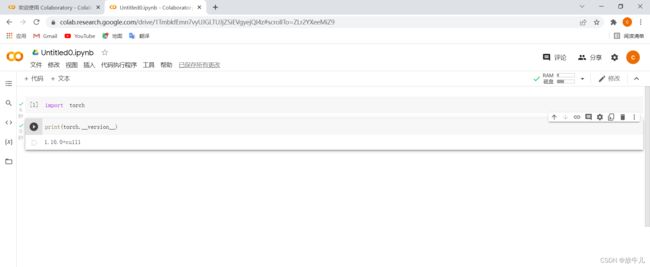
导入成功,因为其中自带pytorch,并且是GPU的版本。如果想使用GPU则在左上角修改,笔记本设置中,选择GPU加速:
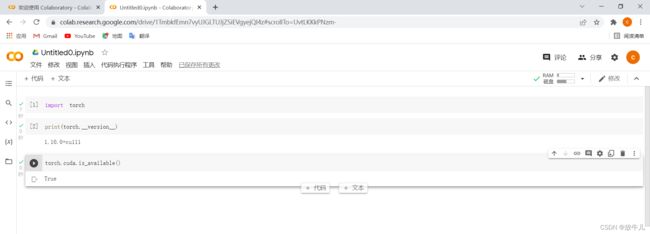
将我们原来的代码直接复制过去即可运行,也可以使用!nvidia-smi查看提供的显卡信息。
利用.to()函数
定义训练的设备:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#cuda和cuda:0没有区别.to()改变定义的设备则所有的变量都跟着改变,不像.cuda()需要一个一个修改。
loss = nn.CrossEntropyLoss().to(device)
model = Model().to(device)
...
for data in dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
...