CVPR 2022 目标跟踪方向 论文推荐~更快、 更强、更通用!
关注公众号,发现CV技术之美
CVPR 2022 论文尚没有完全公布,今日推荐10篇已出目标跟踪方向的论文,既有单目标跟踪也有多目标跟踪,还有无人机视觉中的跟踪问题,基于Transformer 的跟踪,点云目标跟踪,还有多目标跟踪的新范式:具有记忆的模型,和新的可见光-热成像基准数据集等。
✔ 具有记忆的多目标跟踪

(Oral)MeMOT: Multi-Object Tracking with Memory
https://arxiv.org/abs/2203.16761
作者发明了一个通用的检测与关联框架,使多目标跟踪可跟踪到长时间消失的目标,具体做法使用一个大的时空记忆存储目标的身份信息,并可据此自适应参考和聚合有用的信息。

记忆模块这么强,会不会成为后续多目标跟踪算法的标配呢?
✔ 无人机视觉中的目标跟踪

TCTrack: Temporal Contexts for Aerial Tracking
https://arxiv.org/abs/2203.01885
https://github.com/vision4robotics/TCTrack
建模“连续帧之间的时间上下文信息”,精度高、速度快,在真实世界的无人机上测试,其在 NVIDIA Jetson AGX Xavier 上的速度超过 27 FPS。

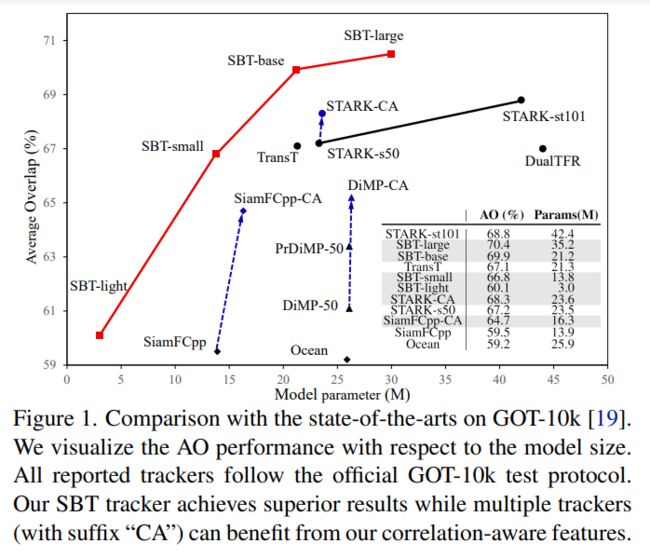
✔ 相关感知的深度跟踪方法

Correlation-Aware Deep Tracking
https://arxiv.org/abs/2203.01666
代码后续开源。
作者提出一种新型目标相关特征网络,用于目标跟踪中的特征提取,可方便应用于现有跟踪算法管道中,提高跟踪性能。
✔ 基于 Transformer 的全局跟踪方法(多目标跟踪)

Global Tracking Transformers
https://arxiv.org/pdf/2203.13250.pdf
https://github.com/xingyizhou/GTR
以往多目标跟踪技术中 tracking-by-detection 的方法,需要对相邻帧的目标进行“成对关联”,作者提出的方法是对多帧图像序列中的目标进行“全局关联”,取得了 MOTA 75.3 mAP 和 HOTA 59.1 mAP 的成绩,在TAO数据集上超出baseline 7.7 mAP。

值得一提的是,该文第一作者同时也是极具影响力的 CenterNet 和 CenterTrack 算法的第一作者。
✔ 将多目标跟踪和单目标跟踪统一建模的基于Transformer 的跟踪方法

Unified Transformer Tracker for Object Tracking
https://arxiv.org/abs/2203.15175
https://github.com/Flowerfan/Trackron
以往多目标跟踪和单目标跟踪是计算机视觉领域中两个相对独立的领域,该文为跟踪问题建立了统一的基于Transformer 的方法 Unified Transformer Tracker (UTT) ,SOT 和 MOT 任务都可以在这个框架内解决。

这种大一统的算法很考验功底!
✔ 基于局部跟踪器集成的全局跟踪(单目标跟踪)

Global Tracking via Ensemble of Local Trackers
https://arxiv.org/abs/2203.16092
该方法的提出为了应对“长期跟踪”中由于突然运动和遮挡造成的目标消失,在多个数据集中均显示出优越的性能。

✔ 无监督学习 + Siamese Tracking (单目标跟踪)

Unsupervised Learning of Accurate Siamese Tracking
https://arxiv.org/abs/2204.01475
https://github.com/FlorinShum/ULAST
该文通过研究向前和向后跟踪视频来获得自监督信息,扩展了Siamese Tracking方法,新方法大大优于之前的无监督方法,甚至在大规模数据集( TrackingNet 和 LaSOT)上的表现与监督方法相当!
跟踪领域,无监督也开始追上有监督了,值得跟进。
✔ 点云3D单目标跟踪

Beyond 3D Siamese Tracking: A Motion-Centric Paradigm for 3D Single Object Tracking in Point Clouds
https://arxiv.org/abs/2203.01730
https://github.com/Ghostish/Open3DSOT
作者认为由于点云数据的textureless and incomplete,基于Siamese 范式的表观匹配方法是不够奏效的,作者转而聚焦于连续帧间的运动信息,发明了一种两阶段的点云目标跟踪方法,首先基于 motion 变换找到后继帧中目标的粗略位置,然后通过运动辅助的形状补全提精定位精度。
实验表明这种方法非常有效,在KITTI、 NuScenes、 与 Waymo Open Dataset 数据集上相对之前的SOTA分别提升了~8%、~17%、 ~22%, 而且速度还很快 ,达到57fps!

换一个赛道做跟踪!速度够快,精度提升很夸张!
✔ min-cost flow + 多目标跟踪

Learning of Global Objective for Network Flow in Multi-Object Tracking
https://arxiv.org/abs/2203.16210
提出了一个通用框架和一种新颖的训练方法,用于学习min-cost flow多目标跟踪问题的成本函数,达到SOTA。

✔ 可见光-热成像 无人机视觉:大规模基准及新基线算法

Visible-Thermal UAV Tracking: A Large-Scale Benchmark and New Baseline
https://arxiv.org/abs/2204.04120
https://zhang-pengyu.github.io/DUT-VTUAV/
500个序列,170万个高分辨(1920x1080)帧对,提供了从粗到细的属性注释,作者提出了新baseline :Hierarchical Multi-modal Fusion Tracker (HMFT)。

追踪更多 CVPR 2022 论文,请关注:
https://github.com/52CV/CVPR-2022-Papers

END
欢迎加入「目标跟踪」交流群备注:OT
