如何利用GPU训练tensorflolw模型
1、tensorflow-gpu+anaconda环境配置
(1)下载anaconda并安装
https://anaconda.en.softonic.com/
选择合适的版本下载
(2)根据当前环境下的cuda和cudnn版本来确定tensorflow-gpu的版本
目前环境下以安装好cuda和cudnn
①查看cuda版本
cat /usr/local/cuda/version.txt
②查看cudnn版本
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
③查看tensorflow、cuda、cudnn之间的版本兼容关系
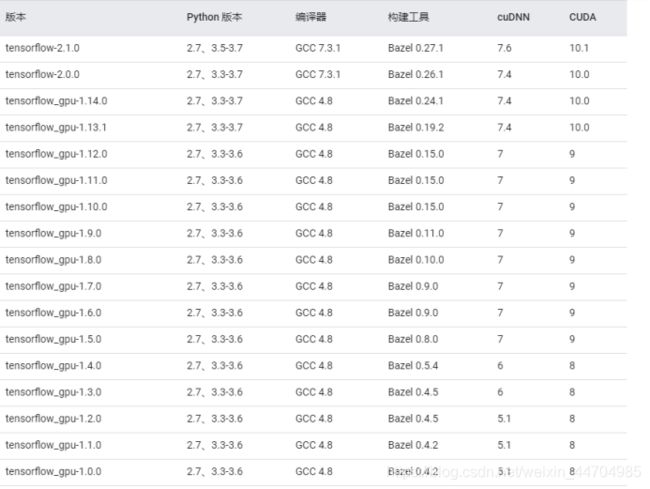
(参考链接:https://tensorflow.google.cn/install/source)
④tensorflow下载链接
tensoflow-gpu
连接地址:http://mirrors.aliyun.com/pypi/simple/tensorflow-gpu
tensorflow-cpu
链接地址:https://pypi.org/project/tensorflow/#files
(3)安装tensorflow-gpu
方式一:在线安装(不推荐,较慢)
pip install tensorflow-gpu==1.14.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
方式二:离线安装(需提前下载好whl包)
pip install tensorflow_gpu-1.14.0-cp36-cp36m-manylinux1_x86_64.whl
添加清华镜像,将有利于提高下载、安装速率
(4)安装相应的cuda和cudnn
conda install cudatoolkit=10.0
conda install cudnn
2、GPU相关信息查询
方式一:
nvidia-smi
方式二:定时更新信息
watch –n 1 nvidia-smi
结果如下所示
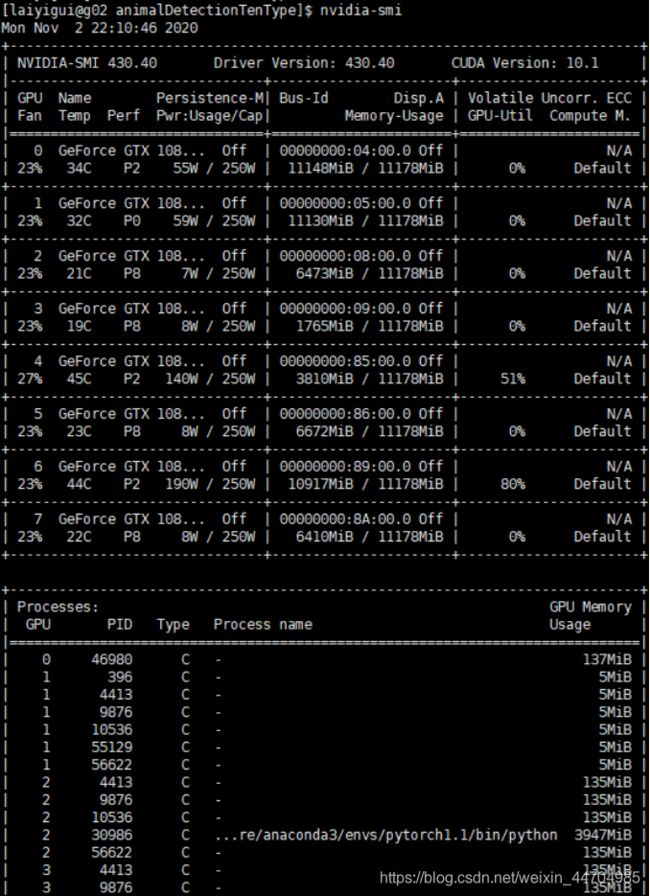
参数介绍
Fan:显示风扇转速,数值在0到100%之间,是计算机的期望转速,如果计算机不是通过风扇冷却或者风扇坏了,显示出来就是N/A;
Temp:显卡内部的温度,单位是摄氏度;
Perf:表征性能状态,从P0到P12,P0表示最大性能,P12表示状态最小性能;
Pwr:能耗表示;
Bus-Id:涉及GPU总线的相关信息;
Disp.A:是Display Active的意思,表示GPU的显示是否初始化;
Memory Usage:显存的使用率;
Volatile GPU-Util:浮动的GPU利用率;
Compute M:计算模式;
下边的Processes显示每块GPU上每个进程所使用的显存情况。
3、tensorflow-gpu的使用
(1)device查看与设置
import tensorflow as tf
a = tf.constant([1.0, 2.0, 3.0], shape=[3], name='a')
b = tf.constant([1.0, 2.0, 3.0], shape=[3], name='b')
c = a + b
# 通过log_device_placement参数来输出运行每一个运算的设备。
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print sess.run(c)
'''
# 在没有GPU的机器上运行以上代码可以得到类似以下的输出。
Device mapping: no known devices.
add: (Add): /job:localhost/replacement/replica:0/task:0/cpu:0
b: (Add): /job:localhost/replacement/replica:0/task:0/cpu:0
a: (Add): /job:localhost/replacement/replica:0/task:0/cpu:0
[2. 4. 6.]
'''
在以上代码中,tensorflow程序会生成会话时加入了参数log_device_placement=True,所以程序会将运行每一个操作的设备输出到屏幕。于是除了可以看到最后的计算结果,还可以看到类似"add: (Add): /job:localhost/replacement/replica:0/task:0/cpu:0
"这样的输出。这些输出显示了执行每一个运算的设备。比如加法操作add是通过CPU来运行的,因为它的设备名称中包含了/cpu:0。
在配置好GPU环境的tensorflow中,如果操作没有明确地指定运行设备,那么tensorflow会优先选择GPU。
Device mapping:
/job:localhost/replica:0/task:0/gpu:0 -> device: 0, name: GRID K520, pci bus
id: 0000:00:03.0
/job:localhost/replica:0/task:0/gpu:0 -> device: 1, name: GRID K520, pci bus
id: 0000:00:04.0
/job:localhost/replica:0/task:0/gpu:0 -> device: 2, name: GRID K520, pci bus
id: 0000:00:05.0
/job:localhost/replica:0/task:0/gpu:0 -> device: 3, name: GRID K520, pci bus
id: 0000:00:06.0
add: (Add): /job:localhost/replace:0/task:0/gpu:0
a: (Const): /job:localhost/replace:0/task:0/gpu:0
b: (Const): /job:localhost/replace:0/task:0/gpu:0
[ 2. 4. 6. ]
从以上输出可以看出在配置好GPU环境的tensorflow中,tensorflow会自动优先将运算放置在GPU上。不过,尽管g2.8xlarge示例中有4个GPU,在默认情况下,tensorflow只会将运算优先放到/gpu:0上。于是可以看见在以上程序中,所有的运算都被放在了/gpu:0上。如果需要将某些运算放到不同的GPU或者CPU上,就需要通过tf.device来手工指定。以下程序给出了一个通过tf.device手工指定运行设备的样例。
import tensorflow as tf
# 通过tf.device将运算指定到特定的设备上。
with tf.device('/cpu:0'):
a = tf.constant([1.0 2.0 3.0], shape=[3], name='a')
b = tf.constant([1.0 2.0 3.0], shape=[3], name='b')
with tf.device('/gpu:1')
c = a + b
sess = tf.Session(config=tf.ConfigProto(log_device_palcement+=True))
print sess.run(c)
'''
在AWS g2.8xlarge实例上的运行上述代码可以得到以下结果:
Device mapping:
/job:localhost/replica:0/task:0/gpu:0 -> device: 0, name: GRID K520, pci bus
id: 0000:00:03.0
/job:localhost/replica:0/task:0/gpu:0 -> device: 1, name: GRID K520, pci bus
id: 0000:00:04.0
/job:localhost/replica:0/task:0/gpu:0 -> device: 2, name: GRID K520, pci bus
id: 0000:00:05.0
/job:localhost/replica:0/task:0/gpu:0 -> device: 3, name: GRID K520, pci bus
id: 0000:00:06.0
add: (Add): /job:localhost/replace:0/task:0/gpu:1
a: (Const): /job:localhost/replace:0/task:0/gpu:0
b: (Const): /job:localhost/replace:0/task:0/gpu:0
[2. 4. 6.]
(2)GPU参数设置
参数一:GPU设备选择
方式一:命令行指定:
# 只使用第二块GPU(GPU编号从0开始)。在demo_code.py中,机器上的第二块GPU的
# 名称变成/gpu:0,不过在运行时所有/gpu:0的运算将被放在第二块GPU上。
CUDA_VISIBLE_DEVICES=1 python demo_code.py
# 只使用第一块和第二块GPU。
CUDA_VISIBLE_DEVICES=0, 1 python demo_code.py
方式二:py代码行指定
import os
# 只使用第三块GPU。
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
参数二:内存占有率
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.9 # 占用GPU90%的显存
config.log_device_placement=True
sess = tf.Session(config=config)
3、问题解决:
(1)内存不足
问题:
failed call to cuDevicePrimaryCtxRetain: CUDA_ERROR_OUT_OF_MEMORY: out of memory; total memory reported: 11721506816
解决方案:
利用nvidia-smi查看GPU内存使用情况,选择内存充足的GPU进行训练,同时需指定利用某个GPU执行程序
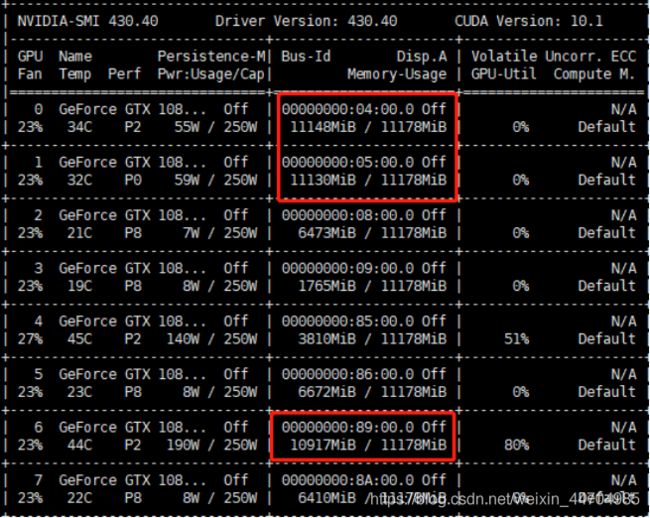
图中的0、1、6号GPU不推荐使用
(2)numpy版本较高
问题:
FutureWarning: Passing (type, 1) or ‘1type’ as a synonym of type is deprecated…:
解决方案:
重新安装numpy-1.16-0
pip install numpy==1.16.0
4、核心原理
能否利用GPU跑代码与代码本身的关系并不大,仍然能使用CPU适用的python代码来利用GPU,关键在于当前的运行环境是否支持GPU,因此能够配置好anaconda的环境对代码能否正常执行起着至关重要的作用