ICCV2021- 牛津大学新的预训练视频文本数据集WebVid-2M,设计用于端到端检索的联合视频和图像编码器!代码已开源!...
关注公众号,发现CV技术之美
▊ 写在前面
视频文本检索的挑战包括视觉网络结构的设计 和训练数据的性质 ,因为可用的大规模视频文本训练数据集 (例如HowTo100M) 是noisy的,因此只能通过大量的计算才能达到竞争力的性能。
作者在本文中解决了这两个挑战,并提出了一种端到端可训练模型,该模型旨在利用大规模图像和视频字幕数据集。本文的模型是对最近的ViT和Timesformer结构的修改和扩展,并且包括在空间和时间上的注意力。
该模型是灵活的,可以独立或结合在图像和视频文本数据集上进行训练。模型将图像视为视频的frozen snapshots开始,然后在接受视频数据集训练时逐渐学会attend到时间上下文。
此外,作者还提供了一个新的视频文本预训练数据集WebVid-2M ,包括200万多个视频,这些视频带有从互联网上抓取的弱字幕。尽管对数据集的训练要小一个数量级,但实验表明,这种方法在标准的下游视频检索基准 (包括msr-vtt,MSVD,DiDeMo和LSMDC) 上产生了SOTA的结果。
▊ 1. 论文和代码地址

Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval
论文:https://arxiv.org/abs/2104.00650
代码:https://github.com/m-bain/frozen-in-time
▊ 2. Motivation
视觉语言任务的快速发展主要归功于三个方面的改进:新的神经网络结构 (例如,用于文本和视觉输入的Transformer);新的大规模数据集 ;能够处理标签噪声的新损失函数 。但是,它们的发展主要在两个独立的赛道上进行: 一个用于图像,一个用于视频。
两者之间唯一的共同联系是,视频网络通常是通过在图像数据集上预训练图像网络来初始化的。考虑到图像和视频在多个任务上传达的信息重叠,这种工作分离是次优的。例如,尽管对某些人类动作进行分类需要对视频帧进行时间排序,但许多动作可以从它们在帧上的分布甚至单个帧中进行分类。
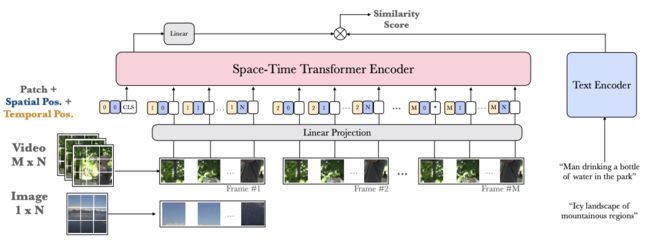
在本文中,作者尝试统一这两个赛道,提出了一种双编码器结构,该结构利用Transformer视觉编码器的灵活性来从带有字幕的图像、或带有字幕的视频片段或两者进行训练 (如上图所示)。作者通过将图像视为 “时间冻结(frozen in time)” 的视频特例来做到这一点。
使用基于Tranformer的结构使模型能够训练可变长度序列,只需将图像视为单个帧视频。此外,与许多最近的视频文本双编码方法不同,作者不使用在外部图像数据集上预先训练,然后固定的一组 “专家网络”,而是端到端训练模型。
作者通过爬取web以获取超过200万个视频-文本对的大规模视频文本字幕数据集WebVid-2M来促进这种端到端训练,此外,还利用大规模图像字幕数据集,如Conceptual Captions。
▊ 3. 方法
3.1. Model Architecture
Input
视觉编码器将图像或视频片段作为输入,该图像或视频片段由分辨率为的个帧组成,其中图像的M = 1。文本编码器将标记化的单词序列作为输入。
Spatio-temporal patches
遵循VIT和Timesformer中的设置,将输入视频片段划分为大小为P×P的M×N个不重叠的时空块,其中。
Transformer input
Patch通过2D卷积层处理,并且输出flatten,形成用于输入到Transformer的嵌入序列,其中D取决于卷积层中卷积核的数量。
学习到的时间和空间位置嵌入,被添加到每个输入token:
帧m内的所有patch都被赋予相同的时间位置,不同时间的相同位置的patch被赋予了相同的空间位置。从而使模型能够感知patch的时间和空间位置。
此外,将学习的 [CLS] token 连接到序列的开头,该序列用于产生Transformer的最终的视觉输出嵌入。
Space-time self-attention blocks
视频序列被送到一堆时空Transformer块中。作者对 Divided Space-Time Attention做了一个小修改,将块输入和时间注意力输出之间的残差连接替换为块输入和空间注意力输出之间的残差连接。
每个块在先前块的输出上依次执行时间自注意,然后执行空间自注意。视频片段嵌入是从最终块的 [CLS] token获得的。
Text encoding
文本编码器架构是一种多层双向Transformer编码器,在自然语言处理任务中显示出巨大的成功。对于最终文本编码,作者使用最终层的 [CLS] token输出。
Projection to common text-video space
文本和视频编码都通过单个线性层投影到一个公共维度。作者通过在两个投影嵌入之间执行点积来计算文本和视频之间的相似度。
Efficiency
本文的模型具有独立的双编码器路径 ,仅需要视频和文本嵌入之间的点积。这确保了检索推理的成本较低,因为它是可索引的,即它允许使用快速近似最近邻搜索,并且在推理时可扩展到非常大规模的检索。
给定目标图库中的t个文本查询和v个视频,模型的检索复杂度为。相比之下,将文本和视频作为输入到单编码器的ClipBERT的检索复杂度为,因为必须将每个文本-视频组合之后输入到模型中。
3.2. Training Strategy
Loss
在检索中,batch中匹配的文本-视频对被视为正样本对,批次中的所有其他成对组合被视为负样本对。在训练过程中,需要最小化两个损失函数,即视频到文本和文本到视频:
其中,和分别是第i个视频和第j个文本在大小为B的batch中的归一化嵌入,σ 是温度参数。
Joint image-video training
在这项工作中,作者在图像-文本对和视频-文本对上进行联合训练,利用两者进行更大规模的预训练。本文的联合训练策略包括在图像和视频数据集之间的batch交替进行。由于注意力机制与输入帧的平方成比例,因此图像数据的batch相比于视频数据可以设置的更大。
Weight initialisation and pretraining
作者使用在ImageNet-21k上训练的ViT权重初始化时空Transformer模型中的空间注意权重,并将时间注意权重初始化为零。残差连接的意义在于,在这样的初始化设置下,模型开始相当于每个输入帧上的ViT,从而允许模型随着训练的进行逐渐学习关注时间。
由于transformer架构在大规模预训练中取得了很大的成功,作者使用了两个大规模文本图像/视频数据集,并采用了联合训练策略,从而大大提高了性能。
Temporal curriculum learning
时空Transformer结构允许可变长度的输入序列,因此可以处理可变数量的输入视频帧。但是,如果模型仅在长度为m的视频上进行了训练,则仅在中学习时间位置嵌入。因此,将模型应用于长度为M的序列的输入视频需要添加。
作者研究了两种时间扩展方法: 插值(interpolation)和零填充(zero-padding)。零填充为将0填充到,允许模型在训练时从头开始学习额外的时间位置。另外,可以使用插值来对时间维度中的时间嵌入进行上采样,即。作者研究了两种插值方法: 最近邻法和双线性法。
Frame sampling
给定包含L个帧的视频,作者将其细分为M个相等的片段,其中M是视频编码器的所需帧数。在训练过程中,作者从每个片段中统一采样一个帧。在测试时,作者对每个片段中的第i帧进行采样,以获得视频嵌入。使用步幅S 确定i的值,从而产生视频嵌入数组。这些视频嵌入的平均值用作视频的最终嵌入。
▊ 4.实验
4.1. Pretraining Datasets

在本文中,作者提出了一个新的视频-文本预训练数据集WebVid2M,上图给出了一些样本示例。
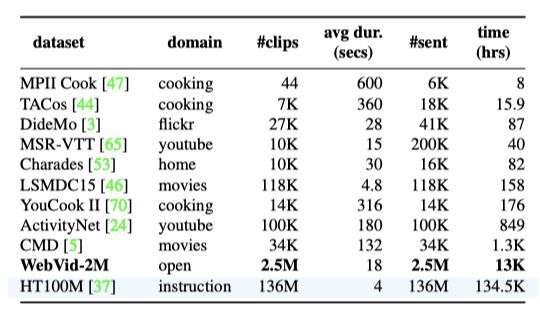
上表为不同视频-文本的预训练数据集的统计结果。
4.2. Ablation Study

上表展示了本文模型在不同预训练数据集下的实验结果,可以看出CC3M + WebVid2M数据集上的预训练结果是最好的。
4.3. Curriculum strategy
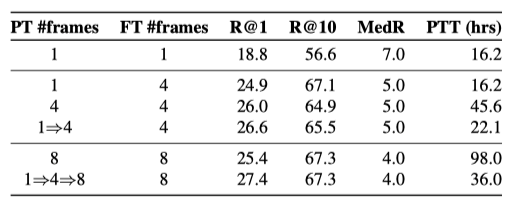
上表展示了不同帧数的实验结果。

上图显示了msr-vtt测试集上各种模型的zero-shot性能,以及相应的总训练时间。
4.4. Comparison to the State of the Art
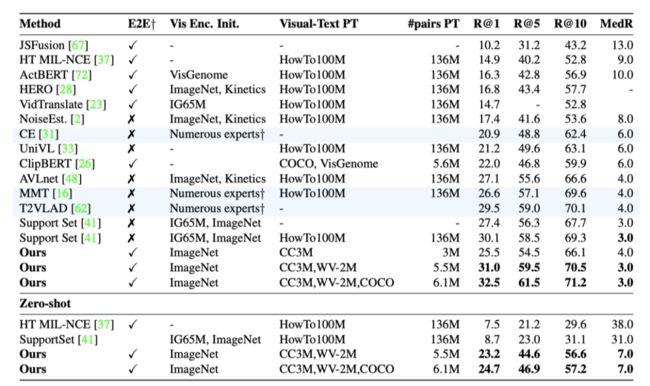
上表展示了MSR-VTT数据集上本文方法的fine-tuning和zero-shot的text-to-video实验结果。
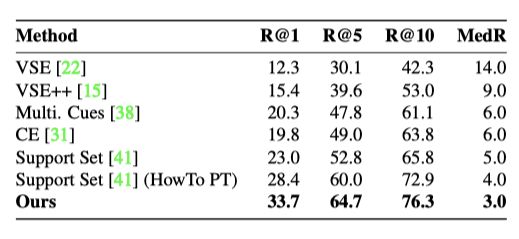
上表展示了MSVD数据集上本文方法的text-to-video实验结果。

上表展示了DiDeMo数据集上本文方法的text-to-video实验结果。
▊ 5. 总结
在本文中,作者提出了一种用于文本视频检索的端到端训练的双编码器模型,该模型旨在利用大规模图像和视频字幕数据集。
本文的模型在许多下游基准上实现了SOTA的性能,但是作者注意到本文的模型的性能尚未达到饱和,通过加入更多预训练的数据集(如HowTo100M,Google3BN),可以进一步发掘本文模型的性能潜力。
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
欢迎加入「视频检索」交流群备注:检索
