第42讲:MySQL数据库索引的基本使用规则以及在正确使用索引的方式
文章目录
-
- 1.索引规则之最左前缀法则
-
- 1.1.最左前缀法则的概念
- 1.2.最左前缀法则的验证案例
- 2.索引规则之范围查询
- 3.使用索引时会导致索引失效的几种情况
-
- 3.1.索引列使用运算导致索引失效
- 3.2.索引列的值不加引号导致索引失效
- 3.3.索引列模糊查询可能会导致索引失效
- 3.4.OR连接条件使用不规范可能会导致索引失效
- 3.5.数据分布影响可能会导致索引失效
- 4.索引规则之SQL提示
-
- 4.1.SQL提示的概念
- 4.2.SQL提示的基本使用
- 5.索引规则之覆盖索引提升查询效率
-
- 5.1.覆盖索引的概念
- 5.2.图解覆盖索引的概念以及什么情况下需要回表查询
- 5.3.覆盖索引的结论
- 5.4.演示索引覆盖查询与不覆盖查询的区别
1.索引规则之最左前缀法则
1.1.最左前缀法则的概念
在讲解索引规则的使用时,首先来说一下索引的最左前缀法则。
最左前缀法则主要是针对联合索引的一项指标,可以根据这个规则然后合理的使用联合索引。
如果表中多列形成了联合索引,那么一定要遵守最左前缀的法则去使用这个联合索引,否则在查询表时,这个索引就可能起不到任何作用。
最左前缀法则的概念:
一个联合索引中一定会包含多个字段,最左前缀指的是索引字段列表中最左边的字段。
在使用联合索引时,要从索引的最左边的字段开始使用,并且查询条件中一定要包含索引中最左侧的字段,否则这个联合索引将没有任何作用,还是会从全表范围进行查询。
想要发挥联合索引的作用,那么就在SQL的查询条件里全部指定上联合索引中所有的字段,此时查询效率是最高的。
在最左前缀法则中,在查询条件里指定所有的联合索引字段,效率最高,只指定最左边的索引字段,索引有效,跳过其中一个字段,跳过的字段以及该字段往右的所有字段索引无效,不指定最左边的索引字段,该索引无效。
在使用联合索引时可能会出现以下几种情况,某些情况中索引是无效的。
- 只查询最左侧的索引字段,只有最左侧的索引字段产生索引的作用,即使表中返回的数据也包含了联合索引中的其他字段,但是我们在查询条件里没有指定,那么也是没有作用的。
- 查询联合索引中的全部索引字段,此时联合索引的效率最高。
- 查询最左侧字段和联合索引中其他的一个索引字段,例如联合索引中有三个字段,分别是name、age、xb,我们在查询条件里只查询name和xb字段,跳过中间的age字段,那么此时只有最左侧的name字段的索引有效,跳过了某一个索引字段,该索引字段往右的其他索引字段将无效。
- 查询左侧字段以及挨着左侧字段,即连续的几个索引字段时,只对指定的几个索引有效。
- 查询条件里不包含最左侧的索引字段,那么此联合索引不会起到任何作用。
结论:使用联合索引时,必须要遵循最左前缀查询法则,并且在查询条件上指定所有的索引字段,此时查询效率最优。
在最左前缀法则中,只要在查询时包含最左侧的索引列,不管顺序是怎么样的,索引都生效。
1.2.最左前缀法则的验证案例
tb_user表中已经在前面创建好了一个联合索引,下面我们通过该联合索引,验证最左前缀法则。
在这个联合索引中,索引字段的顺序是zy、nl、zt,其中最左前缀索引字段是zy,最右侧索引字段是zt。

1)查询联合索引中的全部字段,观察执行计划。
mysql> explain select * from tb_user where zy = '网络工程' and nl = '31' and zt = '1';
+----+-------------+---------+------------+------+-------------------+-------------------+---------+-------------------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+-------------------+-------------------+---------+-------------------+------+----------+-----------------------+
| 1 | SIMPLE | tb_user | NULL | ref | idx_user_zy_nl_zt | idx_user_zy_nl_zt | 54 | const,const,const | 1 | 100.00 | Using index condition |
+----+-------------+---------+------------+------+-------------------+-------------------+---------+-------------------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
注意观察这三个字段,可能使用的索引是idx_user_zy_nl_zt,实际使用的索引也是idx_user_zy_nl_zt,索引的长度为54,说明三个索引的累计的长度是54,当我们不知道联合索引中有几个索引生效时,可以观察ref这个字段,里面有几个值,就表示有几个字段生效了,当前也不是那么精准。

2)只查询最左侧的索引字段,观察执行计划。
本次不全部查询联合索引中的全部字段,只查询一个最左侧的索引字段。
mysql> explain select * from tb_user where zy = '网络工程';
观察输出的执行计划,根据ref字段得知本次只有一个索引起到了作用,也就验证了一句话“只查询最左侧的索引字段,只有最左侧的索引字段产生索引的作用”,即使我们查询的是表中所有的字段,联合索引也有其他字段的索引,但是不会生效哦。
根据索引长度我们得知最左侧的索引字段占用的长度是47。

3)只查询最左侧索引字段和挨着最左侧索引字段的一个字段,观察执行计划。
只查询最左侧的字段和挨着左侧字段的第二个字段,验证“指定最左侧的索引字段,并且还使用了挨着最左侧索引字段的连续的索引字段,此时指定了哪些索引字段,哪些索引字段就有效”。
mysql> explain select * from tb_user where zy = '网络工程' and nl = '31';
观察输出的执行计划,根据ref字段我们得知本次有两个索引字段起到了作用,我们查询的索引字段是最左侧的索引和第二个索引字段,第一个索引字段的长度从2中得知是47,根据下图中显示的索引长度,我们可以得知第二个字段的索引长度为2,那么第三个字段的索引长度就是5。
在优化索引时,要牢记每个索引字段的长度,可以分析对应长度的索引字段是否生效起到了作用。

4)查询最左侧的索引字段和第三个索引字段,观察执行计划。
只查询最左侧的索引字段和第三个索引字段,验证“查询条件包含最左侧索引字段,但是中间跳过了索引列表中的一些字段,此时只有最左侧的索引字段有效。”
mysql> explain select * from tb_user where zy = '网络工程' and zt = '1';
观察输出的执行计划,可以看到只有一个索引生效了,索引的长度是47,那么生效的索引字段就是最左侧的索引字段,其余的索引字段没有生效,也验证了“查询条件包含最左侧索引字段,但是中间跳过了索引列表中的一些字段,此时只有最左侧的索引字段有效。”这句话。

5)查询条件中不指定最左侧的索引字段。
查询条件中不指定最左侧的索引字段,验证“查询条件里不包含最左侧的索引字段,那么此联合索引不会起到任何作用。”这句话。
mysql> explain select * from tb_user where nl = '31' and zt = '1';
观察执行计划的输出结果,可以看到没有使用任何索引。

2.索引规则之范围查询
范围查询也是针对联合索引的一种使用规则,在联合索引中,可能会出现范围查询的操作,例如年龄大于20,小于30等等,如果在使用联合索引时,某个索引字段使用了范围查询,那么该字段往右的索引字段将会失效。
避免范围查询影响右侧索引字段失效的方法就是在业务逻辑允许的情况下,尽可能去使用大于等于或者小于等于。
如下面这个SQL,nl字段也是联合索引中的一个字段,对该字段我们使用了范围查询。
mysql> explain select * from tb_user where zy = '网络工程' and nl > '30' and zt = '1';
观察执行计划的输出,可以看到索引的长度是49,从前面的案例中我们得知最左侧的索引字段长度是47,第二个索引字段的长度是2,那么我们就可以得知在这条SQL中,只有最左侧索引和第二个索引生效了,第三个字段的索引没生效,此时也就验证了“某个索引字段使用了范围查询,那么该字段往右的索引字段将会失效。”这句话。

如果业务逻辑允许的情况下,我们将第二个索引字段的范围查询条件改成大于等于,就可以避免右侧索引无效的情况。
mysql> explain select * from tb_user where zy = '网络工程' and nl >= '30' and zt = '1';
观察执行计划的输出,可以看到索引的长度为54,那么就表示三个索引字段全部都起到作用了。

小细节:当我们不知道有几个索引字段生效时,可以一次查询一个索引,记录他的索引长度,和总的索引长度去比较,就可以得知联合索引中有几个索引起到作用了。
3.使用索引时会导致索引失效的几种情况
3.1.索引列使用运算导致索引失效
在使用索引时,一定不要在索引的列上进行运算操作,否则会导致索引失效。
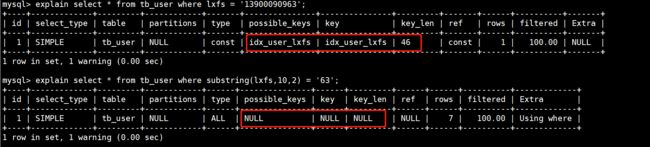
在tb_user表中有一个id_user_lxfs的索引,这个索引是针对lxfs这个字段的,我们针对这个索引去做一组运算,观察索引是否还有效。

mysql> explain select * from tb_user where lxfs = '13900090963';
mysql> explain select * from tb_user where substring(lxfs,10,2) = '63';
从下面的执行计划中可以看出,在使用运算后,索引就没有任何作用了。
3.2.索引列的值不加引号导致索引失效
如果索引列的字段类型是字符串类型,那么在查询时,值不使用引号引起来,那么就会导致该列的索引失效。
常规类型的索引列不使用引号引起来,就会导致索引失效,联合索引也是同样的,只要是索引的字段值没有添加引号,就会导致索引失效。
此时会有人有疑问:在MySQL数据库中,字符串类型的字段内容一般都是文字、字母类型的,肯定会带着引号,那么也有情况字符串中全部都是数字,如果写SQL的人不规范,就看影响索引的效率。
索引字段值加引号和不加引号的对比。
mysql> explain select * from tb_user where lxfs = 13900090963;
观察执行计划,索引字段在查询时不加引号,可以看到在possible_keys列中虽然显示了可能会用到的索引,但是在key列中则显示了NULL,表示没有使用任何索引,此时索引就无效了。

3.3.索引列模糊查询可能会导致索引失效
如果查询条件中,索引列的字段值是用的模糊匹配,如果仅仅是尾部进行模糊匹配,这种条件下索引是有效的,如果是头部模糊匹配,则索引无效。
无论是中间内容匹配,还是头部内容匹配,都会导致索引无效。
首先我们在查询条件中指定索引列,并且使用尾部模糊匹配,观察索引是否有效。
mysql> explain select * from tb_user where lxfs like "139%";
通过执行计划的输出,我们可以看到即使使用了尾部的模糊匹配,索引依旧生效。

下面我们再索引列的字段中使用头部模糊匹配,观察索引是否还有效。
mysql> explain select * from tb_user where lxfs like "%139";
通过执行计划的输出,我们可以看到当索引字段在查询时使用了头部模糊匹配,索引就失效了。

经过上面的案例,我们可以得出结论,在索引列使用模糊查询时,关键字前面加%,索引就会失效,关键字后面加%,索引正常使用。
3.4.OR连接条件使用不规范可能会导致索引失效
在查询条件很多情况下都会包含OR连接条件,但是在使用索引列作为条件查询时,如果OR条件前面的字段有索引,OR条件后面的字段没有索引,此时即使有索引的字段也会失去索引的作用。
OR连接条件前后的字段必须全都有索引,此时索引才不会失效。

tb_user表中的lxfs和xm字段都是有索引的,我们编写一条SQL,使用or连接查询,观察索引是否有效。
mysql> explain select * from tb_user where xm = "江睿基" or lxfs = "15101030779";
从SQL的执行计划中来看,OR连接条件前后的字段的索引全部起到了作用。

tb_user表中nl字段的索引是联合索引,nl字段在联合索引中也不是最左侧的索引,我们直接使用这个字段查询时,这个字段相当于没有索引,我们可以通过这个案例,观察索引是否会失效。
mysql> explain select * from tb_user where xm = "江睿基" or nl = "31";
从SQL的执行计划中,我们可以看到当我们使用了OR连接条件,即使连接条件左侧字段有索引,但是右侧字段没有索引,此时所有的索引都会失效。

3.5.数据分布影响可能会导致索引失效
MySQL有数据分布的特性,根据数据分布的影响,会去评估查询语句是使用全表扫描的效率高还是使用索引的效率高,如果MySQL觉得查询的条件适合全表扫描时,索引可能就会失效了。
”数据分布影响“是针对查询条件查询出来的数据量进行评估的,如果我们查询的字段有索引,但是查询出来的数据条数可能是全表数据的一半以上时,此时MySQL就会觉得查询全表的效率会更好,如果查询的数据只包含全表的几分之一,很少的量,那么MySQL就会觉得使用索引的效率会更高。
例如我们要查询tb_user表中lxfs这个字段内容为空的数据条目,如果该字段的数据全部都是空的,或者表中总数据为20条,有10条以上的数据都为空,那么此时MySQL就会认为使用全表扫描的效率更高,就不会使用索引去查询了,如果数据为空的只有一两条,那么就会使用索引查询。
1)查询tb_user表中lxfs为13401004368的数据,观察是否走索引查询。
mysql> explain select * from tb_user where lxfs = '13401004368';
此时表中lxfs是13401004368的数据只有一条,因此MySQL认为走索引查询效率更高。

2)查询tb_user表中lxfs为空的数据,观察是否走索引查询。
将lxfs字段的值全部设为NULL,然后在观察执行计划。
mysql> update tb_user set lxfs = NULL ;
mysql> explain select * from tb_user where lxfs is null ;
当表中满足条件的数据量大时,并且超过了表中全部数据的一半以上,此时MySQL就认为全表查询的效率要比索引高,因此就会导致索引失效,字段type为ALL时表示全表扫描。

4.索引规则之SQL提示
4.1.SQL提示的概念
SQL提示只是一个术语,是用于某个字段有多个索引,我们提示MySQL使用哪个索引的一种场景。
我们在查询条件中指定了某个字段,该字段有多个索引,既有常规索引也有联合索引的情况下,MySQL会自动帮我们选择它认为效率最高的索引去使用。
如果我们不想让MySQL自动选择评估使用哪个索引,我们就可以通过SQL提示的功能,建议MySQL使用我们指定的索引、让MySQL忽略不使用指定的索引、强制让MySQL使用指定的索引。
简单来说SQL提示是数据库优化过程中的一个重要手段,可以在SQL语句中增加一些人为的提示来到达优化的目的。
SQL提示三种方法的语法格式:
- use index:建议MySQL使用指定的索引。
explain select * from 表名 use index(索引名) where 条件
- ignore index:让MySQL忽略不使用指定的索引。
explain select * from 表名 ignore index(索引名) where 条件
- force index:强制MySQL使用指定的索引。
explain select * from 表名 force index(索引名) where 条件
4.2.SQL提示的基本使用
首先给tb_user表的zy字段添加一个常规索引,该字段目前已经拥有一个联合索引了,我们可以通过SQL提示让MySQL使用特定的索引。
mysql> create index idx_user_zy on tb_user (zy);

1)当zy字段有多个索引时,观察MySQL会使用哪个索引。
mysql> explain select * from tb_user where zy = '网络工程';
根据执行计划的输出,我们可以看到在查询zy字段时,可能会用到的索引既有联合索引又有常规索引,但是最后选择的是联合索引。

2)建议MySQL查询zy字段时,使用zy字段的常规索引。
mysql> explain select * from tb_user use index(idx_user_zy) where zy = '网络工程';
根据执行计划的输出,我们可以看到MySQL使用了我们建议的索引去查询,但是不是每次建议都会生效,MySQL还是会评估该索引和它默认选择的索引哪个执行效率高,就会使用哪个索引

3)让MySQL忽略zy字段的常规索引,不使用指定的索引去查询。
mysql> explain select * from tb_user ignore index(idx_user_zy) where zy = '网络工程';
根据执行计划的输出,我们可以看到MySQL忽略了我们指定的常规索引,而是使用联合索引去查询。

3)强制让MySQL使用zy字段的联合索引去查询数据。
mysql> explain select * from tb_user force index(idx_user_zy_nl_zt) where zy = '网络工程';
根据执行计划的输出,我们可以看到MySQL已经强制使用了我们指定的联合索引,此时MySQL不管效率如何,都会去使用我们指定的联合索引。

5.索引规则之覆盖索引提升查询效率
5.1.覆盖索引的概念
覆盖索引也是索引的一种术语。
覆盖索引并不是说覆盖掉索引,简单来说含义就是要通过select返回的字段列,这些列在索引中全部都包含了,在一个索引中能够全部找到。
我们在查询数据时,尽量避免select *的操作,尽可能的只返回我们需要的字段列,然后将需要返回的多个字段列设置成联合索引,此时要查询的字段都会位于一个二级索引时,这时的查询效率是最高的,因为不需要再进行回表查询去聚集索引中拿到完整的一行数据。
如果我们查询时返回的字段都是索引中包含的字段,那么在SQL的执行计划中Extra更多详情这一列看到这样的返回内容:
- Using where; Using Index:当我们在更多一列看到这样的内容时,就表示我们使用索引列查询数据时,要返回的字段都在索引中包含,不需要回表查询数据,此时的效率最高。
如果我们查询时返回的字段并没有在索引中包含,那么在SQL的执行计划中的Extra这一列就会看到这样的返回内容:
- Using index condition:当我们在更多一列看到这样的内容时,就表示虽然我们使用索引列查询数据了,但是返回的字段并没有在索引列中,此时需要回表查询数据,效率不如直接从索引中获取的高。
回表与不回表操作对于查询的效率是有影响的,我们在优化SQL时,尽量避免回表操作,尽可能的将返回的字段都添加到联合索引中,如果查询的字段都在联合索引中,那么只需要在二级索引一层中就能拿到需要的数据,如果返回的字段没有在二级索引中,此时就会通过回表的方式,向聚集索引中获取数据。
5.2.图解覆盖索引的概念以及什么情况下需要回表查询
通过下面这张图详细说明到底什么是覆盖索引,以及什么情况下会进行回表操作。
1)到底什么是覆盖索引
如下图左侧的这张人员信息表,其中id字段是一个主键索引,user_name字段是一个常规索引,此时我们要查询user_name是asd的人员信息,返回的字段是id、user_name和xb这三个字段。
我们是以user_name字段去查询的,该字段是一个常规索引,也就是二级索引,asd比kli小因此会走左侧节点,然后找到hug,asd比hug小,接着走左侧节点然后找到了asd。asd元素中会包含关联数据的主键,id字段正好就是表中的主键字段,我们这条查询语句要返回的字段有id、user_name和xb三个字段,此时在二级索引中只拿到了两个字段,xb字段并没有在该索引中找到。
到目前为止,我们就得知要返回的三个字段并没有都在一个索引中包含,还需要进行回表查询才能拿到完整的数据。
如果返回的所有字段都能在一个索引中找到,就表示这些字段都覆盖在了这个索引中,这就是覆盖索引的概念。换句话来说,索引覆盖指的是索引中的字段覆盖了查询时返回的字段。
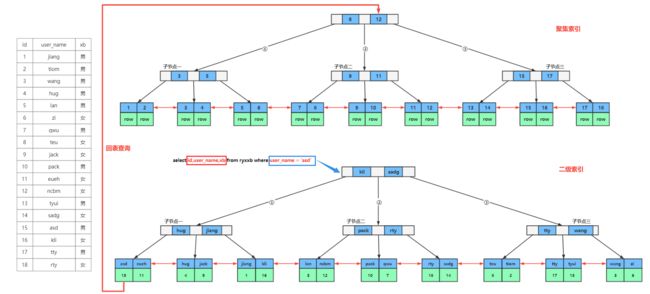
2)什么情况下才会进行回表查询以及如何避免
在上面我们已经得知,在二级索引中没有xb字段,但是我们却要返回xb字段的数据,此时就需要回表查询,去聚集索引中拿到完整的一行数据,然后才能返回xb字段的数据。
在这种情况下,我们还需要回表查询,找到聚集索引,多找一次,才能拿到完整的数据,效率相对来说是很低下的。
那么应该如何避免回表查询呢?回表查询会影响查询的效率,其实也很简单,将user_name字段的常规索引删除,然后创建一个联合索引,在联合索引中将需要返回的user_name和xb两个字段都加进去,此时一层二级索引检索就能拿到完整的数据,也就不需要回表查询了,大大提高查询的效率。
5.3.覆盖索引的结论
在实际的生产环境中,最好的查询效率就是将要返回的字段都包含在一个索引中,也就是做成联合索引,此时只需要检索一层二级索引就可以返回数据,效率很高。
5.4.演示索引覆盖查询与不覆盖查询的区别
在tb_user表中yx字段没有任何索引,zy、nl、zt字段属于同一个联合索引,我们可以通过以下两种方式即可观察到覆盖索引前后的对比。
- 查询时返回的字段有yx、zy、nl等(不覆盖索引)。
- 查询时返回的字段有zy、nl、zt等(覆盖索引)

1)当查询时要返回的字段不覆盖索引时,观察执行计划的效果。
查询时返回的字段有yx、zy、nl,其中yx字段不在idx_user_zy_nl_zt这个联合索引内,相当于不覆盖索引。
mysql> explain select yx,zy,nl from tb_user where zy = '网络工程' and nl= '31' and zt = "1";
分析SQL的执行计划,我们看到在可能使用的索引中一共有两个,最终使用的索引是联合索引,但是我们返回的yx字段并没有在这个联合索引中,没有覆盖联合索引,此时就会返回Using index condition,说明要进行回表查询了。

提一点:在可能用到的索引中出现了两个,我们可以通过SQL提示,建议或者强制MySQL使用特定的索引,但是这个索引最好能覆盖返回的字段。
1)当查询时要返回的字段覆盖索引时,观察执行计划的效果。
查询时返回的字段有zy、nl、zt,这三个字段都在联合索引内,相当于已经覆盖索引了,换句话来说,索引里的字段覆盖了查询时返回的字段。
mysql> explain select zy,nl,zt from tb_user where zy = '网络工程' and nl= '31' and zt = "1";
分析SQL的执行计划,我们看到在可能使用的索引中一共有两个,最终使用的索引是联合索引,我们要返回的字段也全都在联合查询的索引中,因此就会返回Using where; Using index ,说明此时不会回表查询,查询效率最高 。
