Pytorch学习笔记(四)
目录
模型训练
model_pretrained.py
model_save.py
model_load.py
model.py
train_cpu.py
train_gpu1.py
train_gpu2.py
test.py
模型训练
本笔记包含对现有网络模型的使用和修改、保存与读取、完整的模型训练套路、利用GPU训练的两种方法以及完整的模型验证套路。
model_pretrained.py:现有网络模型的使用和修改,以pytorch官网中用于分类的vgg16模型为例,其是在ImageNet数据集(1000个class)上进行预训练。但实操中由于ImageNet数据集过大,有100G,故而未下载到本地。只是利用加载模型参数的不同在debug中观察vgg16在数据集上训练前后参数的不同。同时以将vgg16模型应用到CIFAR-10数据集(10个class)上为例实现模型修改。
model_save.py model_load.py:包含两种模型保存方法以及两种相应的模型加载方法。模型保存包括保存模型结构和模型训练数据及参数。model.py:为了规范化网络训练步骤,将搭建模型部分单独存放在文件中,在训练模型时将其引入即可。train_cpu.py:在cpu上实现完整的模型训练
train_gpu1.py:利用.cuda()方法在gpu上实现完整的模型训练train_gpu2.py:利用.to(device)在gpu上实现完整的模型训练
test.py:在文件中load已训练且保存好的模型,在imgs中随意添加CIFAR-10数据集中所包含的图像类别相关图片,进行测试验证。如:dog.pn/airplane.png
实验证明利用model_0.pth(即训练一轮保存的模型)会将图片分类错误,使用model_10.pth(即训练十轮保存的模型)会将图片正确分类。
CIFAR-10 数字对应类别
#‘airplane’=0 'automobile'=1 'bird'=2 'cat'=3 'deer'=4
# 'dog'=5 'frog'=6 'horse'=7 'ship'=8 'truck'=9 _len_=10
model_pretrained.py
import torchvision
from torch import nn
# train_data=torchvision.datasets.ImageNet("../dataset",split='train',download=True,
# transform=torchvision.transforms.ToTensor())
# #RuntimeError: The archive ILSVRC2012_devkit_t12.tar.gz is not present in the root directory or is corrupted.
# # You need to download it externally and place it in ../dataset. 只能手动下载 但文件但大了100G
#由于数据集太大 接下来只能debug观察一下模型pretrained=false和true时的区别
#false时 是初始的weight true时,是在ImageNet数据集上训练好的参数
vgg16_false=torchvision.models.vgg16(pretrained=False)#flase时只是加载网络模型,不需要下载
vgg16_true=torchvision.models.vgg16(pretrained=True)#true时需要下载网络模型
# print("ok") #打断点 debug
print(vgg16_true) #输出网络模型 可以知道vgg16可以识别1000个类别(ImageNet数据集含1000个class)
#之前用的CIFAR10数据集包含10个class
train_data=torchvision.datasets.CIFAR10("../dataset",train=True,download=True,
transform=torchvision.transforms.ToTensor())
# 如何在CIFAR10上应用这样一个输出类别为1000个的模型呢?
# 方式①将最后一层线性层中的out_feature的1000 改为10
# 方式②在分类器中再加一层线性层 in_features=1000,out_features=10
#在vgg16_true模型结构中添加层
vgg16_true.classifier.add_module('add_linear',nn.Linear(1000,10))
print(vgg16_true)
print(vgg16_false)
#修改vgg16_false模型结构
vgg16_false.classifier[6]=nn.Linear(4096,10)
print(vgg16_false)vgg16model 结构:(未截图完整)

原vgg16model中的classifier:(最后一个线性层可以看出class为1000个)

add_module后的classifier:

修改最后classifier中最后一个线性层后:

model_save.py
#模型的保存
import torch
import torchvision
from torch import nn
vgg16=torchvision.models.vgg16(pretrained=False)#false时参数是初始参数,即为训练过的参数
#保存方式1
torch.save(vgg16,"vgg16_method1.pth") #会产生.pth文件 不仅保存了模型结构 还保存了模型参数
#保存方式2(官方推荐) 占用空间小
torch.save(vgg16.state_dict(),"vgg16_method2.pth") # 把vgg16中网络模型参数保存为python中的字典形式 只保存参数 不保存结构
#陷阱
class myModel(nn.Module):
def __init__(self):
super(myModel, self).__init__()
self.conv1=nn.Conv2d(3,64,kernel_size=3)
def forward(self,x):
x=self.conv1(x)
return x
model=myModel()
torch.save(model,"model_method1.pth")
model_load.py
#加载模型
import torch
import torchvision
from torch import nn
#方式1-对应model_save.py 中的保存方式1
model = torch.load("vgg16_method1.pth")
# print(model)#debug可以看到保存的该模型参数 输出的是模型的结构
#方式2 加载模型
vgg16 = torchvision.models.vgg16(pretrained=False)#加载模型结构
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))#加载模型参数
# model = torch.load("vgg16_method2.pth")#字典形式存储的模型参数
# print(model)
# print(vgg16)
# 陷阱1 使用方式1保存模型
# 如果是自己定义的模型 加载已经保存的可能它会不认识这个模型
# 需要将原模型class导入 或者 将文件import
model=torch.load('model_method1.pth')
print(model)#AttributeError: Can't get attribute 'myModel' 使用方法1陷阱(未加载保存的自定义model class或者引入其所在文件)

model.py
#为了规范,一般会把该部分单独放在一个文件中,然后引入
import torch
from torch import nn
#搭建神经网络
class myModel(nn.Module):
def __init__(self):
super(myModel, self).__init__()
self.model=nn.Sequential(
nn.Conv2d(3,32,5,1,2),#in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
#测试网络模型
if __name__ == '__main__': #main
model=myModel()
input=torch.ones((64,3,32,32))
output=model(input)
print(output.shape)train_cpu.py
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
from model import * #从model.py文件引入搭建的神经网络
#准备数据集
train_data=torchvision.datasets.CIFAR10(root="../dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data=torchvision.datasets.CIFAR10(root="../dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#length 数据集长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# print(f"训练数据集的长度为:{train_data_size}")
#利用DataLoader加载数据集
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)
# # 搭建神经网络
# # 为了规范,一般会把该部分单独放在一个文件中,然后引入 (from model import *)
# class myModel(nn.module):
# def __init__(self):
# super(myModel, self).__init__()
# self.model=nn.Sequential(
# nn.Conv2d(3,32,5,1,2),#in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2
# nn.MaxPool2d(2),
# nn.Conv2d(32,32,5,1,2),
# nn.MaxPool2d(2),
# nn.Conv2d(32, 64, 5, 1, 2),
# nn.MaxPool2d(2),
# nn.Flatten(),
# nn.Linear(64*4*4,64),
# nn.Linear(64,10)
# )
#
# def forward(self,x):
# x=self.model(x)
# return x
#创建网络模型
model = myModel()
#创建损失函数
loss_fn = nn.CrossEntropyLoss()
#优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(),learning_rate)
#设置训练网络的一些参数
total_train_step = 0 #记录训练的次数
total_test_step = 0 #记录测试的次数
epoch = 10 #训练的轮数
#添加tensorboard可视化
writer=SummaryWriter("../logs")
start_time=time.time()
for i in range(epoch):
print("--------第{}轮训练开始--------".format(i+1))#i=0,1,...9
#训练步骤开始
model.train()#只对一部分网络层有作用 eg, Dropout,BatchNorm,etc.
for data in train_dataloader:
imgs,targets=data
outputs=model(imgs)
loss=loss_fn(outputs,targets)
#优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step+=1
if total_train_step%100 == 0:
end_time=time.time()
print(end_time-start_time)
print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
#loss和loss.item()输出看起来没什么区别,但是item()会把tensor数据类型转化为数字 可以为后续loss可视化做铺垫
#测试步骤开始
model.eval()#只对一部分网络层有作用 eg, Dropout,BatchNorm,etc.
total_test_loss=0
total_accuracy=0
with torch.no_grad():#不需要梯度调优 用已训练的模型进行测试
for data in test_dataloader:
imgs,targets=data
outputs=model(imgs)
loss=loss_fn(outputs,targets)#loss是一部分数据的测试误差
total_test_loss+=loss.item()#整个测试数据集上的测试误差
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy += accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step += 1
#保存每一轮训练的模型
torch.save(model,"model_{}.pth".format(i))
# torch.save(model.state_dict(),"model_{}.pth".format(i))
print("模型已保存")
writer.close()train_gpu1.py
#使用GPU 方法1
#找到网络模型、数据(输入、标注)损失函数三种变量
#调用.cuda
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
# from model import * #从model.py文件引入搭建的神经网络
#准备数据集
train_data=torchvision.datasets.CIFAR10(root="../dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data=torchvision.datasets.CIFAR10(root="../dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#length 数据集长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# print(f"训练数据集的长度为:{train_data_size}")
#利用DataLoader加载数据集
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)
# # 搭建神经网络
# # 为了规范,一般会把该部分单独放在一个文件中,然后引入 (from model import *)
class myModel(nn.Module):
def __init__(self):
super(myModel, self).__init__()
self.model=nn.Sequential(
nn.Conv2d(3,32,5,1,2),#in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
#创建网络模型
model = myModel()
if torch.cuda.is_available():
model=model.cuda()
#创建损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn=loss_fn.cuda()
#优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(),learning_rate)
#设置训练网络的一些参数
total_train_step = 0 #记录训练的次数
total_test_step = 0 #记录测试的次数
epoch = 10 #训练的轮数
#添加tensorboard可视化
writer=SummaryWriter("../logs")
start_time=time.time()
for i in range(epoch):
print("--------第{}轮训练开始--------".format(i+1))#i=0,1,...9
#训练步骤开始
model.train()#只对一部分网络层有作用 eg, Dropout,BatchNorm,etc.
for data in train_dataloader:
imgs,targets=data
if torch.cuda.is_available():
imgs=imgs.cuda()
targets=targets.cuda()
outputs=model(imgs)
loss=loss_fn(outputs,targets)
#优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step+=1
if total_train_step%100 == 0:
end_time = time.time()
print(end_time-start_time)
print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
#loss和loss.item()输出看起来没什么区别,但是item()会把tensor数据类型转化为数字 可以为后续loss可视化做铺垫
#测试步骤开始
model.eval()#只对一部分网络层有作用 eg, Dropout,BatchNorm,etc.
total_test_loss=0
total_accuracy=0
with torch.no_grad():#不需要梯度调优 用已训练的模型进行测试
for data in test_dataloader:
imgs,targets=data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs=model(imgs)
loss=loss_fn(outputs,targets)#loss是一部分数据的测试误差
total_test_loss+=loss.item()#整个测试数据集上的测试误差
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy += accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step += 1
#保存每一轮训练的模型
torch.save(model,"model_{}.pth".format(i))
# torch.save(model.state_dict(),"model_{}.pth".format(i))
print("模型已保存")
writer.close()train_gpu2.py
#使用GPU 方法2 更长远
#device=torch.device("cpu")
#.to(device)
#torch.device("cuda")
#torch.device("cuda:0") 第一张显卡
#torch.device("cuda:1") 第二张显卡
#torch.device("cuda" if torch.cuda.is_available() else "cpu")
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
#定义训练使用的设备
# device=torch.device("cpu")
device=torch.device("cuda")
# from model import * #从model.py文件引入搭建的神经网络
#准备数据集
train_data=torchvision.datasets.CIFAR10(root="../dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data=torchvision.datasets.CIFAR10(root="../dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#length 数据集长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# print(f"训练数据集的长度为:{train_data_size}")
#利用DataLoader加载数据集
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)
# # 搭建神经网络
# # 为了规范,一般会把该部分单独放在一个文件中,然后引入 (from model import *)
class myModel(nn.Module):
def __init__(self):
super(myModel, self).__init__()
self.model=nn.Sequential(
nn.Conv2d(3,32,5,1,2),#in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
#创建网络模型
model = myModel()
model=model.to(device)
#创建损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn=loss_fn.to(device)
#优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(),learning_rate)
#设置训练网络的一些参数
total_train_step = 0 #记录训练的次数
total_test_step = 0 #记录测试的次数
epoch = 20 #训练的轮数
#添加tensorboard可视化
writer=SummaryWriter("../logs")
# start_time = time.time()
for i in range(epoch):
print("--------第{}轮训练开始--------".format(i+1))#i=0,1,...9
#训练步骤开始
model.train()#只对一部分网络层有作用 eg, Dropout,BatchNorm,etc.
for data in train_dataloader:
start_time = time.time()
imgs,targets=data
imgs=imgs.to(device)
targets=targets.to(device)
outputs=model(imgs)
loss=loss_fn(outputs,targets)
#优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step+=1
if total_train_step%100 == 0:
end_time = time.time()
print(end_time-start_time)
print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
#loss和loss.item()输出看起来没什么区别,但是item()会把tensor数据类型转化为数字 可以为后续loss可视化做铺垫
#测试步骤开始
model.eval()#只对一部分网络层有作用 eg, Dropout,BatchNorm,etc.
total_test_loss=0
total_accuracy=0
with torch.no_grad():#不需要梯度调优 用已训练的模型进行测试
for data in test_dataloader:
imgs,targets=data
imgs = imgs.to(device)
targets = targets.to(device)
outputs=model(imgs)
loss=loss_fn(outputs,targets)#loss是一部分数据的测试误差
total_test_loss+=loss.item()#整个测试数据集上的测试误差
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy += accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step += 1
#保存每一轮训练的模型
torch.save(model,"model_{}.pth".format(i))
# torch.save(model.state_dict(),"model_{}.pth".format(i))
print("模型已保存")
writer.close()


test.py
import torch
import torchvision
from PIL import Image
from model import *#方式1加载保存好的模型需要copy model class或者导入model文件
#image_path="../imgs/dog.png"
image_path="../imgs/airplane.png"
image = Image.open(image_path)
print(image)#
image = image.convert('RGB')#png格式有四个通道:RGB+Alph透明通道 调用convert保留其RGB通道
#model要求输入只能是32*32
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)#torch.Size([3, 32, 32])
#载入train好的模型(数据、参数及模型结构)
#model=torch.load('model_0.pth')#方式1导入
model=torch.load('model_9.pth')#方式1导入
print(model)
image=torch.reshape(image,(1,3,32,32))#模型输入需要是四维数据
image=image.cuda()#若保存的模型是用gpu训练的,则需要将输入数据同样写为在gpu训练形式
model.eval()#进入测试状态
with torch.no_grad():
output=model(image)
print(output)
print(output.argmax(1))
#CIFAR-10 数字对应类别
# ‘airplane’=0 'automobile'=1 'bird'=2 'cat'=3 'deer'=4
# 'dog'=5 'frog'=6 'horse'=7 'ship'=8 'truck'=9 _len_=10 测试输入数据:

airplane.png

dog.png

使用model_0.pth测试 airplane.png(预测正确√)

使用model_0.pth测试 dog.png(预测错误×)

使用model_9.pth测试dog.png(预测正确√)
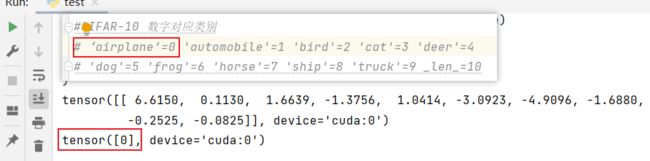
使用model_9.pth测试airplane.png(预测正确√)