NNDL 实验五 前馈神经网络(1)二分类任务
pytorch实现
4.1 神经元
4.1.1 净活性值
使用pytorch计算一组输入的净活性值z
净活性值z经过一个非线性函数f(·)后,得到神经元的活性值a

使用pytorch计算一组输入的净活性值,代码参考paddle例题:
import paddle
# 2个特征数为5的样本
X = paddle.rand(shape=[2, 5])
# 含有5个参数的权重向量
w = paddle.rand(shape=[5, 1])
# 偏置项
b = paddle.rand(shape=[1, 1])
# 使用'paddle.matmul'实现矩阵相乘
z = paddle.matmul(X, w) + b
print("input X:", X)
print("weight w:", w, "\nbias b:", b)
print("output z:", z)在飞桨中,可以使用nn.Linear完成输入张量的上述变换。
在pytorch中学习相应函数torch.nn.Linear(features_in, features_out, bias=False)。
实现上面的例子,完成代码,进一步深入研究torch.nn.Linear()的使用。
import torch
# 2个特征数为5的样本
X = torch.rand(size=[2, 5])
# 含有5个参数的权重向量
w = torch.rand(size=[5, 1])
# 偏置项
b = torch.rand(size=[1, 1])
# 使用'torch.matmul'实现矩阵相乘
z = torch.matmul(X, w) + b
print("input X:", X)
print("weight w:", w, "\nbias b:", b)
print("output z:", z)运行结果:
input X: tensor([[0.0598, 0.2653, 0.2298, 0.0296, 0.2904],
[0.9668, 0.9356, 0.7022, 0.9960, 0.3819]])
weight w: tensor([[0.9602],
[0.2978],
[0.2794],
[0.7497],
[0.7112]])
bias b: tensor([[0.2056]])
output z: tensor([[0.6349],
[2.6271]])【思考题】加权相加与仿射变换之间有什么区别和联系?
仿射变换:仿射变换主要包括平移变换、旋转变换、尺度变换、倾斜变换(也叫错切变换、剪切变换、偏移变换)、翻转变换,一共有六个自由度(平移包括x方向平移和y方向平移,算两个自由度)。仿射变换保持二维图形的平直性和平行性,但是角度会改变
加权相加:
4.1.2 激活函数
激活函数通常为非线性函数,可以增强神经网络的表示能力和学习能力。
常用的激活函数有S型函数和ReLU函数。
4.1.2.1 Sigmoid 型函数
Sigmoid 型函数是指一类S型曲线函数,为两端饱和函数。常用的 Sigmoid 型函数有 Logistic 函数和 Tanh 函数,其数学表达式为
Logistic 函数(4.4)
Tanh 函数(4.5)
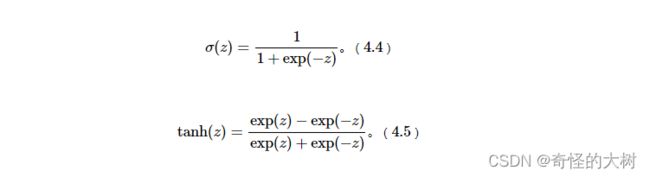
Logistic函数和Tanh函数的代码实现和可视化如下:
import torch
import matplotlib.pyplot as plt
# Logistic函数
def logistic(z):
return 1.0 / (1.0 + torch.exp(-z))
# Tanh函数
def tanh(z):
return (torch.exp(z) - torch.exp(-z)) / (torch.exp(z) + torch.exp(-z))
# 在[-10,10]的范围内生成10000个输入值,用于绘制函数曲线
z = torch.linspace(-10, 10, 10000)
plt.figure()
plt.plot(z.tolist(), logistic(z).tolist(), color='#e4007f', label="Logistic Function")
plt.plot(z.tolist(), tanh(z).tolist(), color='#f19ec2', linestyle ='--', label="Tanh Function")
ax = plt.gca() # 获取轴,默认有4个
# 隐藏两个轴,通过把颜色设置成none
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
# 调整坐标轴位置
ax.spines['left'].set_position(('data',0))
ax.spines['bottom'].set_position(('data',0))
plt.legend(loc='lower right', fontsize='large')
plt.savefig('fw-logistic-tanh.pdf')
plt.show() 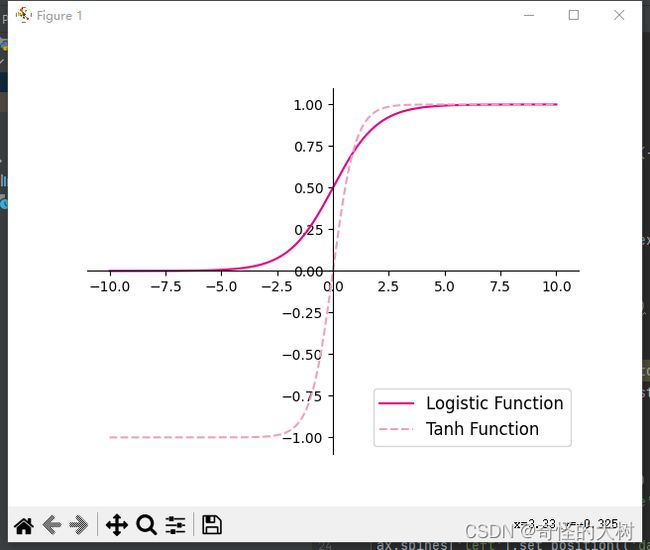
4.1.2.2 ReLU型函数
常见的ReLU函数有ReLU和带泄露的ReLU(Leaky ReLU)
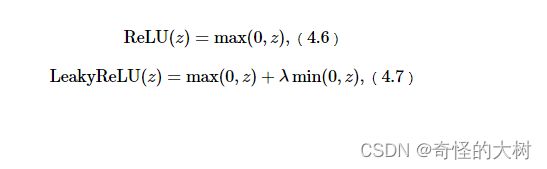
其中λ为超参数。
可视化ReLU和带泄露的ReLU的函数的代码实现和可视化如下:
# ReLU
def relu(z):
return torch.maximum(z, torch.tensor(0.))
# 带泄露的ReLU
def leaky_relu(z, negative_slope=0.1):
# 当前版本torch暂不支持直接将bool类型转成int类型,因此调用了torch的cast函数来进行显式转换
a1 = (torch.tensor((z > 0)) * z)
a1 = a1.to(torch.float32)
a2 = (torch.tensor((z <= 0)) * (negative_slope * z))
a2 = a2.to(torch.float32)
return a1 + a2
# 在[-10,10]的范围内生成一系列的输入值,用于绘制relu、leaky_relu的函数曲线
z = torch.linspace(-10, 10, 10000)
plt.figure()
plt.plot(z.tolist(), relu(z).tolist(), color="#e4007f", label="ReLU Function")
plt.plot(z.tolist(), leaky_relu(z).tolist(), color="#f19ec2", linestyle="--", label="LeakyReLU Function")
ax = plt.gca()
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
ax.spines['left'].set_position(('data',0))
ax.spines['bottom'].set_position(('data',0))
plt.legend(loc='upper left', fontsize='large')
plt.savefig('fw-relu-leakyrelu.pdf')
plt.show()
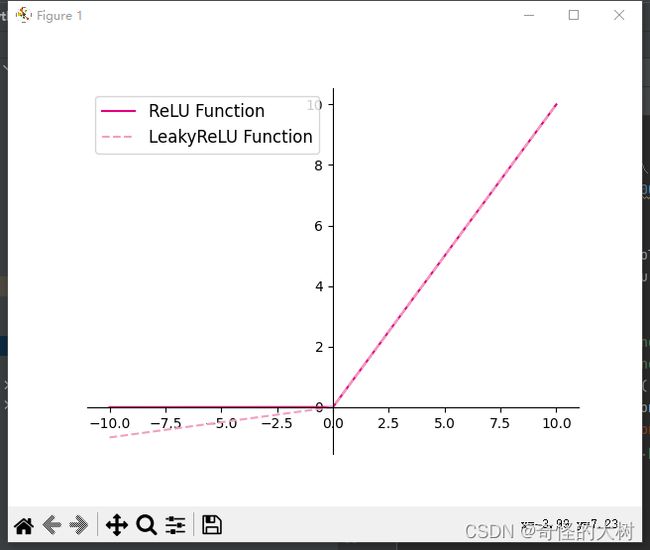
- 在飞桨中,可以通过调用paddle.nn.functional.relu和paddle.nn.functional.leaky_relu完成ReLU与带泄露的ReLU的计算。在pytorch中找到相应函数并测试。
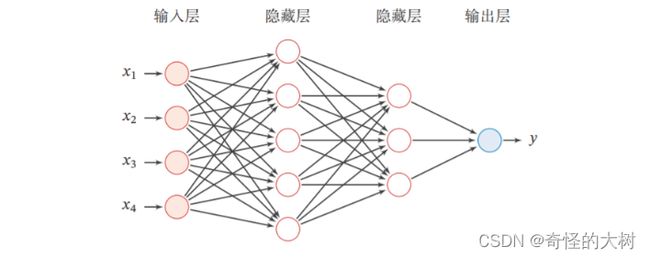
4.2 基于前馈神经网络的二分类任务
前馈神经网络的网络结构如下图所示。每一层获取前一层神经元的活性值,并重复上述计算得到该层的活性值,传入到下一层。整个网络中无反馈,信号从输入层向输出层逐层的单向传播,得到网络最后的输出 a(L)a(L)。
4.2.1 数据集构建
使用第3.1.1节中构建的二分类数据集:Moon1000数据集,其中训练集640条、验证集160条、测试集200条。该数据集的数据是从两个带噪音的弯月形状数据分布中采样得到,每个样本包含2个特征。
#nndl make mons
import torch
import math
import numpy as np
# 新增make_moons函数
def make_moons(n_samples=1000, shuffle=True, noise=None):
n_samples_out = n_samples // 2
n_samples_in = n_samples - n_samples_out
outer_circ_x = torch.cos(torch.linspace(0, math.pi, n_samples_out))
outer_circ_y = torch.sin(torch.linspace(0, math.pi, n_samples_out))
inner_circ_x = 1 - torch.cos(torch.linspace(0, math.pi, n_samples_in))
inner_circ_y = 0.5 - torch.sin(torch.linspace(0, math.pi, n_samples_in))
print('outer_circ_x.shape:', outer_circ_x.shape, 'outer_circ_y.shape:', outer_circ_y.shape)
print('inner_circ_x.shape:', inner_circ_x.shape, 'inner_circ_y.shape:', inner_circ_y.shape)
X = torch.stack(
[torch.cat([outer_circ_x, inner_circ_x]),
torch.cat([outer_circ_y, inner_circ_y])],
axis=1
)
print('after concat shape:', torch.cat([outer_circ_x, inner_circ_x]).shape)
print('X shape:', X.shape)
# 使用'torch. zeros'将第一类数据的标签全部设置为0
# 使用'torch. ones'将第一类数据的标签全部设置为1
y = torch.cat(
[torch.zeros([n_samples_out]), torch.ones([n_samples_in])]
)
print('y shape:', y.shape)
# 如果shuffle为True,将所有数据打乱
if shuffle:
# 使用'torch.randperm'生成一个数值在0到X.shape[0],随机排列的一维Tensor做索引值,用于打乱数据
idx = torch.randperm(X.shape[0])
X = X[idx]
y = y[idx]
# 如果noise不为None,则给特征值加入噪声
if noise is not None:
X += np.random.normal(0.0, noise, X.shape)
return X, y
# 采样1000个样本
n_samples = 1000
X, y = make_moons(n_samples=n_samples, shuffle=True, noise=0.5)
num_train = 640
num_dev = 160
num_test = 200
X_train, y_train = X[:num_train], y[:num_train]
X_dev, y_dev = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
X_test, y_test = X[num_train + num_dev:], y[num_train + num_dev:]
y_train = y_train.reshape([-1,1])
y_dev = y_dev.reshape([-1,1])
y_test = y_test.reshape([-1,1])注意此代码里需用到的函数make_mons代码已经和主带码放在一起。
C:\Users\320\PycharmProjects\pythonProject\venv\Scripts\python.exe C:/Users/320/PycharmProjects/pythonProject/main.py
outer_circ_x.shape: torch.Size([500]) outer_circ_y.shape: torch.Size([500])
inner_circ_x.shape: torch.Size([500]) inner_circ_y.shape: torch.Size([500])
after concat shape: torch.Size([1000])
X shape: torch.Size([1000, 2])
y shape: torch.Size([1000])
Process finished with exit code -1073741749 (0xC000004B)4.2.2 模型构建
为了更高效的构建前馈神经网络,我们先定义每一层的算子,然后再通过算子组合构建整个前馈神经网络。
4.2.2.1 线性层算子
# 实现线性层算子
class Op(object):
def __init__(self):
pass
def __call__(self, inputs):
return self.forward(inputs)
def forward(self, inputs):
raise NotImplementedError
def backward(self, inputs):
raise NotImplementedError
class Linear(Op):
def __init__(self, input_size, output_size, name, weight_init=np.random.standard_normal, bias_init=torch.zeros):
self.params = {}
# 初始化权重
self.params['W'] = weight_init([input_size, output_size])
self.params['W'] = torch.as_tensor(self.params['W'],dtype=torch.float32)
# 初始化偏置
self.params['b'] = bias_init([1, output_size])
self.inputs = None
self.name = name
def forward(self, inputs):
self.inputs = inputs
outputs = torch.matmul(self.inputs, self.params['W']) + self.params['b']
return outputs4.2.2.2 Logistic算子(激活函数)
class Logistic(Op):
def __init__(self):
self.inputs = None
self.outputs = None
def forward(self, inputs):
outputs = 1.0 / (1.0 + torch.exp(-inputs))
self.outputs = outputs
return outputs
4.2.2.3 层的串行组合
实现一个两层的用于二分类任务的前馈神经网络,选用Logistic作为激活函数,可以利用上面实现的线性层和激活函数算子来组装
# 实现一个两层前馈神经网络 class Model_MLP_L2(Op): def __init__(self, input_size, hidden_size, output_size): self.fc1 = Linear(input_size, hidden_size, name="fc1") self.act_fn1 = Logistic() self.fc2 = Linear(hidden_size, output_size, name="fc2") self.act_fn2 = Logistic() def __call__(self, X): return self.forward(X) def forward(self, X): z1 = self.fc1(X) a1 = self.act_fn1(z1) z2 = self.fc2(a1) a2 = self.act_fn2(z2) return a2
实例化一个两层的前馈网络,令其输入层维度为5,隐藏层维度为10,输出层维度为1。
并随机生成一条长度为5的数据输入两层神经网络,观察输出结果。
# 实例化模型
model = Model_MLP_L2(input_size=5, hidden_size=10, output_size=1)
# 随机生成1条长度为5的数据
X = torch.rand([1, 5])
result = model(X)
print ("result: ", result)
result: tensor([[0.3707]])4.2.3 损失函数
二分类交叉熵损失函数见第三章
# 实现交叉熵损失函数
class BinaryCrossEntropyLoss(op.Op):
def __init__(self):
self.predicts = None
self.labels = None
self.num = None
def __call__(self, predicts, labels):
return self.forward(predicts, labels)
def forward(self, predicts, labels):
self.predicts = predicts
self.labels = labels
self.num = self.predicts.shape[0]
loss = -1. / self.num * (torch.matmul(self.labels.t(), torch.log(self.predicts)) + torch.matmul((1-self.labels.t()), torch.log(1-self.predicts)))
loss = torch.squeeze(loss, axis=1)
return loss
4.2.4 模型优化
神经网络的层数通常比较深,其梯度计算和上一章中的线性分类模型的不同的点在于:
线性模型通常比较简单可以直接计算梯度,而神经网络相当于一个复合函数,需要利用链式法则进行反向传播来计算梯度。
4.2.4.1 反向传播算法
第1步是前向计算,可以利用算子的forward()方法来实现;
第2步是反向计算梯度,可以利用算子的backward()方法来实现;
第3步中的计算参数梯度也放到backward()中实现,更新参数放到另外的优化器中专门进行。
4.2.4.2 损失函数
二分类交叉熵损失函数
实现损失函数的backward()
# 实现交叉熵损失函数
class BinaryCrossEntropyLoss(Op):
def __init__(self, model):
self.predicts = None
self.labels = None
self.num = None
self.model = model
def __call__(self, predicts, labels):
return self.forward(predicts, labels)
def forward(self, predicts, labels):
self.predicts = predicts
self.labels = labels
self.num = self.predicts.shape[0]
loss = -1. / self.num * (torch.matmul(self.labels.t(), torch.log(self.predicts))
+ torch.matmul((1 - self.labels.t()), torch.log(1 - self.predicts)))
loss = torch.squeeze(loss, axis=1)
return loss
def backward(self):
# 计算损失函数对模型预测的导数
loss_grad_predicts = -1.0 * (self.labels / self.predicts -
(1 - self.labels) / (1 - self.predicts)) / self.num
# 梯度反向传播
self.model.backward(loss_grad_predicts)
4.2.4.3 Logistic算子
为Logistic算子增加反向函数
class Logistic(Op):
def __init__(self):
self.inputs = None
self.outputs = None
self.params = None
def forward(self, inputs):
outputs = 1.0 / (1.0 + torch.exp(-inputs))
self.outputs = outputs
return outputs
def backward(self, grads):
# 计算Logistic激活函数对输入的导数
outputs_grad_inputs = torch.multiply(self.outputs, (1.0 - self.outputs))
return torch.multiply(grads,outputs_grad_inputs)
4.2.4.4 线性层
线性层输入的梯度
计算线性层参数的梯度

图片来源:NNDL 实验4(上) - HBU_DAVID - 博客园 (cnblogs.com)
class Linear(Op):
def __init__(self, input_size, output_size, name, weight_init=np.random.standard_normal, bias_init=torch.zeros):
self.params = {}
self.params['W'] = weight_init([input_size, output_size])
self.params['W'] = torch.as_tensor(self.params['W'],dtype=torch.float32)
self.params['b'] = bias_init([1, output_size])
self.inputs = None
self.grads = {}
self.name = name
def forward(self, inputs):
self.inputs = inputs
outputs = torch.matmul(self.inputs, self.params['W']) + self.params['b']
return outputs
def backward(self, grads):
self.grads['W'] = torch.matmul(self.inputs.T, grads)
self.grads['b'] = torch.sum(grads, dim=0)
# 线性层输入的梯度
return torch.matmul(grads, self.params['W'].T)
4.2.4.5 整个网络
实现完整的两层神经网络的前向和反向计算,代码实现如下。
class Model_MLP_L2(Op):
def __init__(self, input_size, hidden_size, output_size):
# 线性层
self.fc1 = Linear(input_size, hidden_size, name="fc1")
# Logistic激活函数层
self.act_fn1 = Logistic()
self.fc2 = Linear(hidden_size, output_size, name="fc2")
self.act_fn2 = Logistic()
self.layers = [self.fc1, self.act_fn1, self.fc2, self.act_fn2]
def __call__(self, X):
return self.forward(X)
# 前向计算
def forward(self, X):
z1 = self.fc1(X)
a1 = self.act_fn1(z1)
z2 = self.fc2(a1)
a2 = self.act_fn2(z2)
return a2
# 反向计算
def backward(self, loss_grad_a2):
loss_grad_z2 = self.act_fn2.backward(loss_grad_a2)
loss_grad_a1 = self.fc2.backward(loss_grad_z2)
loss_grad_z1 = self.act_fn1.backward(loss_grad_a1)
loss_grad_inputs = self.fc1.backward(loss_grad_z1)
4.2.4.6 优化器
在计算好神经网络参数的梯度之后,我们将梯度下降法中参数的更新过程实现在优化器中。
与第3章中实现的梯度下降优化器SimpleBatchGD不同的是,此处的优化器需要遍历每层,对每层的参数分别做更新。
from nndl.opitimizer import Optimizer
class BatchGD(Optimizer):
def __init__(self, init_lr, model):
super(BatchGD, self).__init__(init_lr=init_lr, model=model)
def step(self):
# 参数更新
for layer in self.model.layers: # 遍历所有层
if isinstance(layer.params, dict):
for key in layer.params.keys():
layer.params[key] = layer.params[key] - self.init_lr * layer.grads[key]
from abc import abstractmethod
#新增优化器基类
class Optimizer(object):
def __init__(self, init_lr, model):
#初始化学习率,用于参数更新的计算
self.init_lr = init_lr
#指定优化器需要优化的模型
self.model = model
@abstractmethod
def step(self):
pass
4.2.5 完善Runner类:RunnerV2_1
支持自定义算子的梯度计算,在训练过程中调用self.loss_fn.backward()从损失函数开始反向计算梯度;
每层的模型保存和加载,将每一层的参数分别进行保存和加载。
class RunnerV2_1(object):
def __init__(self, model, optimizer, metric, loss_fn, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric
# 记录训练过程中的评估指标变化情况
self.train_scores = []
self.dev_scores = []
# 记录训练过程中的评价指标变化情况
self.train_loss = []
self.dev_loss = []
def train(self, train_set, dev_set, **kwargs):
# 传入训练轮数,如果没有传入值则默认为0
num_epochs = kwargs.get("num_epochs", 0)
# 传入log打印频率,如果没有传入值则默认为100
log_epochs = kwargs.get("log_epochs", 100)
# 传入模型保存路径
save_dir = kwargs.get("save_dir", None)
# 记录全局最优指标
best_score = 0
# 进行num_epochs轮训练
for epoch in range(num_epochs):
X, y = train_set
# 获取模型预测
logits = self.model(X)
# 计算交叉熵损失
trn_loss = self.loss_fn(logits, y) # return a tensor
self.train_loss.append(trn_loss.item())
# 计算评估指标
trn_score = self.metric(logits, y).item()
self.train_scores.append(trn_score)
self.loss_fn.backward()
# 参数更新
self.optimizer.step()
dev_score, dev_loss = self.evaluate(dev_set)
# 如果当前指标为最优指标,保存该模型
if dev_score > best_score:
print(f"[Evaluate] best accuracy performence has been updated: {best_score:.5f} --> {dev_score:.5f}")
best_score = dev_score
if save_dir:
self.save_model(save_dir)
if log_epochs and epoch % log_epochs == 0:
print(f"[Train] epoch: {epoch}/{num_epochs}, loss: {trn_loss.item()}")
def evaluate(self, data_set):
X, y = data_set
# 计算模型输出
logits = self.model(X)
# 计算损失函数
loss = self.loss_fn(logits, y).item()
self.dev_loss.append(loss)
# 计算评估指标
score = self.metric(logits, y).item()
self.dev_scores.append(score)
return score, loss
def predict(self, X):
return self.model(X)
def save_model(self, save_dir):
# 对模型每层参数分别进行保存,保存文件名称与该层名称相同
for layer in self.model.layers: # 遍历所有层
if isinstance(layer.params, dict):
torch.save(layer.params, os.path.join(save_dir, layer.name+".pdparams"))
def load_model(self, model_dir):
# 获取所有层参数名称和保存路径之间的对应关系
model_file_names = os.listdir(model_dir)
name_file_dict = {}
for file_name in model_file_names:
name = file_name.replace(".pdparams", "")
name_file_dict[name] = os.path.join(model_dir, file_name)
# 加载每层参数
for layer in self.model.layers: # 遍历所有层
if isinstance(layer.params, dict):
name = layer.name
file_path = name_file_dict[name]
layer.params = torch.load(file_path)
4.2.6 模型训练
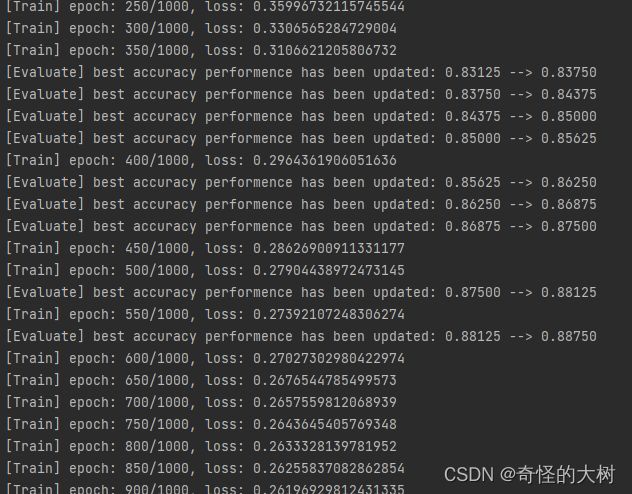
使用训练集和验证集进行模型训练,共训练2000个epoch。评价指标为accuracy。
#模型训练
from nndl.metric import accuracy
torch.random.manual_seed(123)
epoch_num = 1000
model_saved_dir = "model"
# 输入层维度为2
input_size = 2
# 隐藏层维度为5
hidden_size = 5
# 输出层维度为1
output_size = 1
# 定义网络
model = Model_MLP_L2(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# 损失函数
loss_fn = BinaryCrossEntropyLoss(model)
# 优化器
learning_rate = 0.2
optimizer = BatchGD(learning_rate, model)
# 评价方法
metric = accuracy
# 实例化RunnerV2_1类,并传入训练配置
runner = RunnerV2_1(model, optimizer, metric, loss_fn)
runner.train([X_train, y_train], [X_dev, y_dev], num_epochs=epoch_num, log_epochs=50, save_dir=model_saved_dir)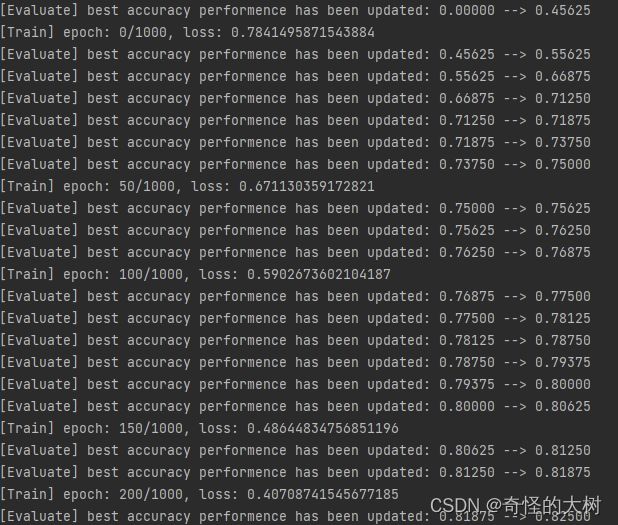
可视化目标
#可视化观察训练集与验证集的损失函数变化情况
# 打印训练集和验证集的损失
import matplotlib.pyplot as plt
plt.figure()
plt.plot(range(epoch_num), runner.train_loss, color="#e4007f", label="Train loss")
plt.plot(range(epoch_num), runner.dev_loss, color="#f19ec2", linestyle='--', label="Dev loss")
plt.xlabel("epoch", fontsize='large')
plt.ylabel("loss", fontsize='large')
plt.legend(fontsize='x-large')
plt.savefig('fw-loss2.pdf')
plt.show()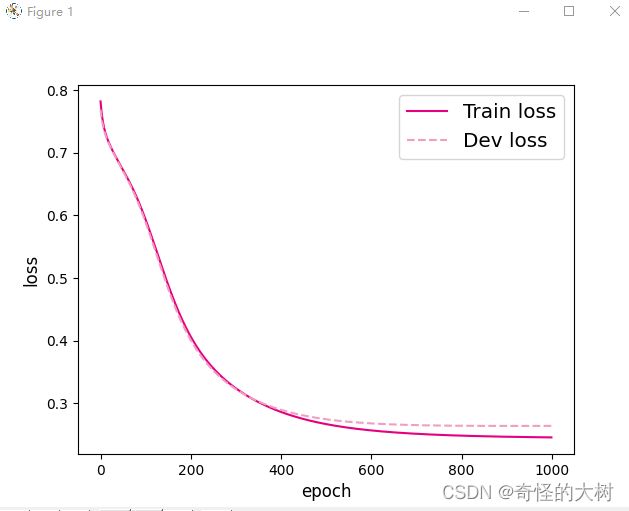
4.2.7 性能评价
使用测试集对训练中的最优模型进行评价,观察模型的评价指标。
#性能评价
# 加载训练好的模型
runner.load_model(model_saved_dir)
# 在测试集上对模型进行评价
score, loss = runner.evaluate([X_test, y_test])
print("[Test] score/loss: {:.4f}/{:.4f}".format(score, loss))可视化目标
import math
# 均匀生成40000个数据点
x1, x2 = torch.meshgrid(torch.linspace(-math.pi, math.pi, 200), torch.linspace(-math.pi, math.pi, 200))
x = torch.stack([torch.flatten(x1), torch.flatten(x2)], axis=1)
# 预测对应类别
y = runner.predict(x)
y = torch.squeeze((y>=0.5).to(dtype=torch.float32),axis=-1)
# 绘制类别区域
plt.ylabel('x2')
plt.xlabel('x1')
plt.scatter(x[:,0].tolist(), x[:,1].tolist(), c=y.tolist(), cmap=plt.cm.Spectral)
plt.scatter(X_train[:, 0].tolist(), X_train[:, 1].tolist(), marker='*', c=torch.squeeze(y_train,axis=-1).tolist())
plt.scatter(X_dev[:, 0].tolist(), X_dev[:, 1].tolist(), marker='*', c=torch.squeeze(y_dev,axis=-1).tolist())
plt.scatter(X_test[:, 0].tolist(), X_test[:, 1].tolist(), marker='*', c=torch.squeeze(y_test,axis=-1).tolist())
plt.show()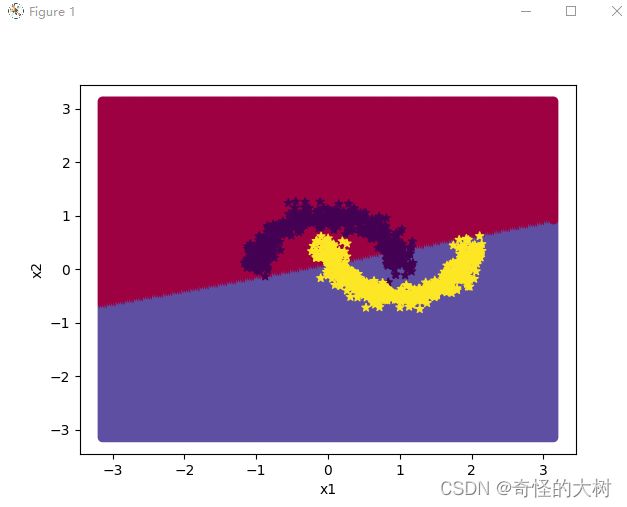
【思考题】
3.1 基于Logistic回归的二分类任务 4.2 基于前馈神经网络的二分类任务
谈谈自己的看法
Logistic回归的二分类任务比较简单,并且它属于是线性的,对于一些普通简单的数据集可能有很好的分类效果但是对于一些类似于弯月数据集复杂的数据集可能就不太适用了。
前馈神经网络二分类任务相较于前者,它是属于非线性的,因为神经网络含有激活函数,激活函数可以将线性的转化为非线性,对于像弯月型复杂的数据集有很好的分类效果
总结:通过实验,我对torch的理解更深了,了解了不同模组之间的关系。通过亲手建立神经网络,对常见的分类问题的印象进一步加深了,同时对数据处理部分也有了更深的理解。掌握了更多torch中常用的函数,对torch中常用的函数的输入与输出进行了测试,运用更加灵活
参考资料
(6条消息) NNDL 实验五 前馈神经网络(1)二分类任务_HBU_David的博客-CSDN博客