论文笔记:图像分割——FCN
Fully Convolutional Networks for Semantic Segmentation
语义分割中的全卷积网络
文章目录
- Fully Convolutional Networks for Semantic Segmentation
- 语义分割中的全卷积网络
-
- 论文结构
- 一、摘要核心
- 二、Introduction和Related Work
-
- 语义分割存在的问题:全局信息与局部信息内部相矛盾
- 三、Fully convolutional networks
-
- (1)先验知识
- (2) 3.1 Adapting classifiers for dense prediction
- (3)3.2 Shift-and-stitch is filter rarefaction
- (4)3.3 上采样 Upsampling is backwards strided convolution
- 四、Segmentation Architecture
-
- 算法架构 4.2
- 关键点:
- 其他的优化方式:减少步长
- 五、训练技巧&实验结果分析
-
- ① 训练技巧
- ② 实验结果及分析
- 六、论文总结
-
- ① 关键点&创新点
- ② 改进点
论文结构
摘要: 介绍论文的背景、核心观点、方法途径、最终成果
1. Introduction: 语义分割研究现状、本质贡献、文章整体结构
2. Related Work: 文章思想来源、先前方法的特点、本文的不同之处
3. Prior knowledge: 卷积网络基本定义、与分类网络间的联系和区别、Shift-and-stitch、Deconvolution、Patchwise training
4. Details of learning: 算法结构、创新点、设计细节
5. Results: 指标定义、多种数据集中的实验分析
6. Conclusion: 实验结论
7. References: 参考文献
一、摘要核心
- 主要成就:端到端、像素到像素训练方式下的卷积神经网络超过了现有语义分割方向最先进的技术
- 核心思想:搭建了一个全卷积网络,输入任意尺寸的图像,经过有效推理和学习得到相同尺寸的输出
- 主要方法:将当前分类网络改编成全卷积网络(AlexNet、VGGNet和GoogLeNet),并进行微调设计了跳跃连接将全局信息和局部信息连接起来,相互补偿
- 实验结果:在PASCAL VOC、NYUDv2和SIFT Flow数据集上得到了state-of-the-art的结果
二、Introduction和Related Work
语义分割存在的问题:全局信息与局部信息内部相矛盾
(1)局部信息
提取位置:浅层网络中提取局部信息
特点:物体的几何信息比较丰富,对应的感受野较小
目的:有助于分割尺寸较小的目标,有利于提高分割的精确程度
(2)全局信息
提取位置:深层网络中提取全局信息
特点:物体的空间信息比较丰富,对应的感受野较大
目的:有助于分割尺寸较大的目标,有利于提高分 割的精确程度
(3)矛盾:
随着下载量,网络结构的加深,局部信息几乎都被处理成为了全局信息。
解决方式:跳跃连接保留局部信息,再在后面和全局信息一起融合
**(4)**在以往的分割方法中,主要有两大类缺点:
- 基于图像块的分割虽然常见,但是效率低,且往往需要前期或者后期处理(例如超像素、检测框、局部预分类等)
- 语义分割面临着语义和位置信息不可兼得的问题。全局信息解决的“是什么“,而局部信息解决的是”在哪里“
(5) 为了解决这三个问题,本文有三个创新点:
- 将分类网络改编为全卷积神经网络,具体包括全连接层转化为卷积层,以及通过反卷积进行上采样
- 使用迁移学习的方法进行微调
- 使用跳跃结构使得语义信息可以和表征信息相结合,产生准确而精细的分割
三、Fully convolutional networks
(1)先验知识
**① 感受野
** 定义:在卷积神经网络中,决定某一层输出结果中一个元素所对应的输入层的区域大小
大感受野的效果比小感受野的效果更好,
步长越大,感受野越大,
但是过大的步长会使feature map保留的信息变少。
因此,在减小步长的情况下,如何增大感受野或保持不变,成为了分割中的一大问题。
** ② 平移普遍性 Translation invariance**
宏观结果:图像中的目标无论被移到图片中的哪个位置,分类结果都应该是相同的
具体过程:卷积≈平移不变图像中的目标有移动时,得到的特征图也会产生移动
虽然是神经网络的基础,基本的满足,
但是
在CNN中没有遵循这个原理,忽略了采样定律(下采样、二次采样),步长变化了,大尺度跨越,破坏了原始的空间坐标,导致结果输出有问题
③ FCN、损失函数、梯度下降的介绍
FCN:
一个普通的深度网络去计算一个普通的非线性函数,这样的网络叫做deep filter 或者 FCN。
FCN是密集的像素级预测任务,任务量更重,对网络的性能要求更强
(2) 3.1 Adapting classifiers for dense prediction
① 全连接层的缺点:
- 全连接层需要固定维数
- 会丢掉空间坐标
- 会引入很多参数
② FCN优点:
如果把全连接层替换为全卷积层,可以接收任意尺寸的图像,还能输出预测的分类图
虽然任务量加大了,但是效率没有受到影响
能很有效的减少网络参数
会在最后会把特征图的信息融合起来
③ 经典算法VS本文算法:
FCN网络中,将CNN网络的后三层全部转化为1×1的卷积核所对应等同向量长度的多通道卷积层。整个网络模型全部都由卷积层组成,没有全连接层产生向量。CNN是图像级的识别,也就是从图像到结果。而FCN是像素级的识别,标注出输入图像上的每一个像素最可能属于哪一类别。
(3)3.2 Shift-and-stitch is filter rarefaction
Shift-and-stitch : 在FCN之前的一个用于密集预测任务的一种方式,效率不高
步骤:
补零+平移原始图片得到四种版本的输入图片;
最大池化得到对应的四张输出特征图;
将四张输出图拼接成密集预测图
(4)3.3 上采样 Upsampling is backwards strided convolution
反卷积进行上采样:在端到端中参数可以进行学习
本文没有沿用以往的插值上采样interpolation,而是提出了新的上采样,即反卷积。
可以理解为卷积操作的逆运算,反卷积并不能复原因卷积操作造成的值的损失,它仅仅是卷积过程中的步骤反向变换一次,因此它还可以称为转置卷积、
卷积与反卷积公式


四、Segmentation Architecture
算法架构 4.2
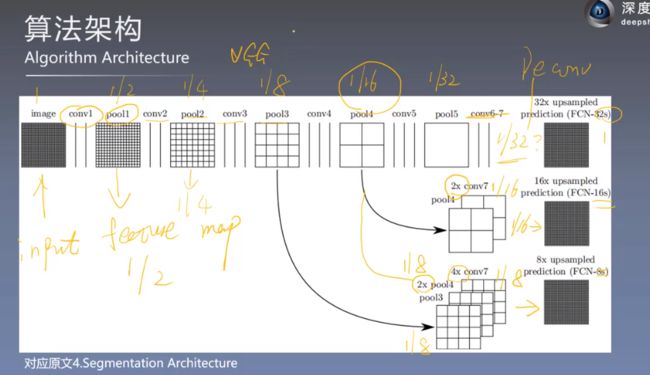
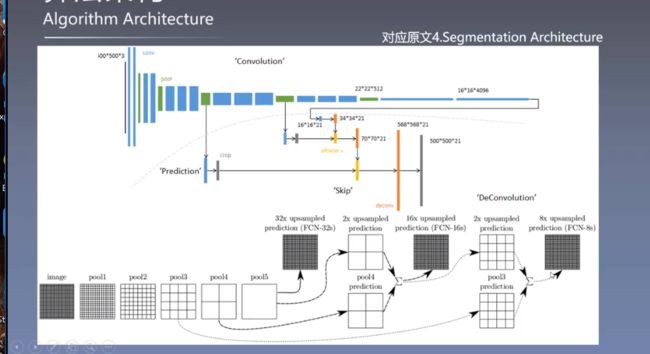
FCN-32s对结果输出的结果是有限制的
把一个线性的拓扑结构转换为DAG有向无环图形式
如果网络太深,只能获取比较少的像素点,信息丢失严重,一些精细的预测需要更少的层的网络去做,因为信息保留比较多,但是浅层网络信息提取不够到位,效果没有深层网络好,但是提取的太多,损失的也多,所以使用跳跃连接的方式,把浅层的信息加到最后的融合输出来,起到一个提升的效果
FCN-16s
把第七全连接层变成卷积层,把特征图用反卷积的方式进行2倍的上采样,和pool4进行融合。(图三)
采用线性插值的方式进行初始化上采样反卷积的卷积核,
最后通过16倍的还原进行预测输出
细节补充:在pool4后面加的1×1卷积的卷积核是用0来初始化卷积核,现在不常用了
FCN-8s
把pool3的特征图和2倍的pool4、4倍的第七层卷积特征图,进行融合操作
关键点:
再结合pool2和pool1得到了负反馈和负优化的结果,并没有对结果造成很大的提升,还多余的增加了很多参数
其他的优化方式:减少步长
- 步长越长,感受野越大
- 步长越长,对特征图的损失越大
但是不可取,减小步长,感受域变小了,对语义分割不利,只能扩大卷积核从3×3变到14×14,才能保证感受野不变,但是计算量变大了。
五、训练技巧&实验结果分析
① 训练技巧
- 加载与训练模型
- 初始化反卷积参数,使用线性插值的方式,把反卷积的卷积核进行初始化,为了更快的收敛
- 至少175个epoch后算法才有不错的表现
- 学习率在100次后进行调整,越到后面调的越小
- pool3之前的特征图不需要融合
② 实验结果及分析
六、论文总结
① 关键点&创新点
- 对经典网络vgg、Alexnet、Googlenet的改编——卷积替换全连接
- 对前后特征图做补偿——跳跃连接,将全局信息和局部信息做一个相互弥补,得到一个更准确的结果
- 对特征图尺寸的恢复——反卷积,扩大图片尺寸。不主张大跨度形式,可以逐步的2倍2倍去做
② 改进点
尺寸恢复
类别平衡
数据预处理(随机镜像和jittering )
资源利用,多个GPU跑一个模型,越快越好,越快实验的次数就越多