目标检测之one-stage模型发展总结
由于广泛的应用和技术上的突破,目标检测(object detection)在近些年吸引了越来越多的注意力,以飞快的速度发展着。在导致目标检测领域飞速发展的众多因素中,深度卷积神经网络和GPU算力无疑占据着重要的地位。大多数顶尖的目标检测网络都充分利用了深度学习网络作为骨干网络用来提取图像特征进行分类和定位。如今,目标检测越来越多的应用在了多分类检测(multi-categories)、边缘检测(edge detection)、显著性目标检测(salient object detection)、姿态检测(pose detection)、场景文本检测(scene text detection)、人脸检测(face detection)和行人检测(pedestrian detection)等领域。
检测器通常能够被分为两类,一类是two-stage检测器,最具代表的为faster R-CNN;另一类是one-stage检测器,包括YOLO,SSD等。一般来说,two-stage检测器具有高定位和识别准确性,而one-stage则有速度上的优势。其在结构上的区别就是two-stage检测器有一个生成region proposal的步骤,然后对其进行预测和分类;而one-stage则是直接对预测框进行回归和分类预测,示意图如下:
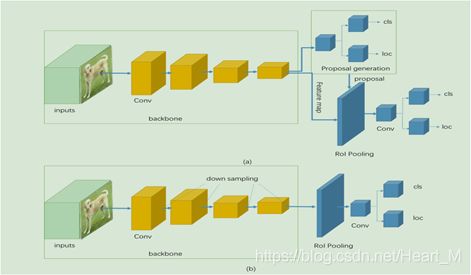
这次我们回顾总结的是one-stage目标检测器的发展历程,由于其先天结构的问题,其准确率一直逊色于two-stage检测器,但是随着不断的发展和研究人员的努力,目前的one-stage检测器在保证速度的同时,其准确率也可以媲美于two-stage检测器,下面我们就来回顾总结one-stage检测器发展历程中的具有代表意义的网络模型。
YOLO(you only look once) 2015
YOLO是第一个被提出的one-stage目标检测器,其主要贡献是对整幅图像和摄像头输入的实时检测,也就是说YOLO的最大优势是速度。首先,相对于Fast R-CNN使用selective research的方法对每张图片提取出2000个region proposals,YOLO仅仅对每张图片预测100多个bounding boxes。其次,YOLO将检测看作是一个回归(regression)问题,所以可以用一个统一的(unified)网络直接去预测边界框(bounding boxes)和分类类别。在Tian X GPU上,YOLO可以实现每秒45张图片的检测速度,作为对比,Fast R-CNN和Faster R-CNN分别为0.5和7。
YOLO的网络结构如下:
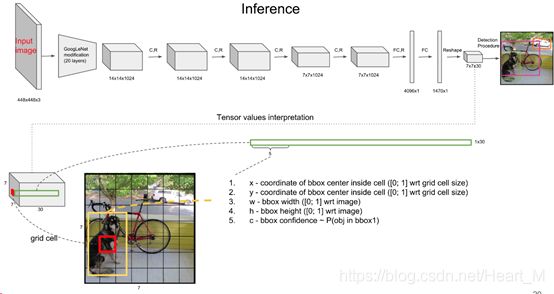
YOLO首先把输入图像划分成S×S个网格(grid),每个网格负责检测中心落在此网格内的物体,每一个网格(grid)预测B个边界框(x,y,w,h)和他们的置信度分数,还有一个C维的类别分数(总共有C个分类)。最后生成S×S×(B×(5+C))维的特征图。按照上图来说S=7,B=2,C=20。每一个格点是一个30维的向量,如上图所示。其中,置信度分数(confidence score)由两部分组成:confidence= P(object)* IOU 。P(object)表示的是方框内包含物体的可能性;IOU(intersection over union)表示的是边界框包含物体的准确性。
为了得到细粒度(finegrained)可视化信息来提升检测精度,在检测阶段,将预训练时的224×224的分辨率加倍。YOLO直接使用整幅图来进行检测,因此可以encode全局信息,所以可以减少将背景检测为物体的错误。Fast R-CNN会犯许多背景误报的错误,YOLO在这方面少了接近3倍。
YOLO还有一些不足之处,虽然每一个格点有两个预测框,但是只能预测一个类别;YOLO是直接预测的bbox的位置,而不是预测的框的offset,增加了训练的难度;此外进行多次下采样,使得得到的特征图分辨率较低,使得目标定位不准确,对于小尺寸目标检测有待加强;
实验表明,YOLO不擅长精确预测物体位置,位置误差(localization error)是预测误差的主要部分。在PASCAL VOC数据集上训练测试,YOLO达到63.4%mAP的检测准确度,速度达到45fps,作为比较,Fast R-CNN(70.0% mAP,0.5fps),Faster R-CNN(73.2%mAP,7fps)。
YOLOv2
YOLOv2是YOLO的第二个版本,其借鉴了其他一些新颖的(novel)的工作成果,使得YOLOv2在精确度和速度方面都有了很大的提升。
批归一化---Batch Normalization:批归一化有助于解决反向传播过程中的梯度消失和梯度爆炸问题,并且每个batch分别进行归一化的时候,起到了一定的正则化效果(YOLO2不再使用dropout),从而能够获得更好的收敛速度和收敛效果。YOLOv2在每一个卷积层前面都加了一个BN层用来加速网络拟合,帮助规则网络模型,在mAP上取得了2%的提升。
高分辨率图像分类---High Resolution Classifier:YOLO2在采用 224*224 图像进行分类模型预训练后,再采用 448*448 的高分辨率样本对分类模型进行微调(10个epoch),使网络特征逐渐适应 448*448 的分辨率。然后再使用 448*448 的检测样本进行训练,缓解了分辨率突然切换造成的影响。mAP提升了3.7%。
采用先验框---Convolutional with Anchor Boxes:在之前的YOLO模型中,预测框的坐标由全连接层直接生成。Faster R-CNN使用的是anchor box,推理生成预测框相对于anchor box的偏移量(offset)。YOLOv2采用的是这种预测机制,首先移除全连接层,然后为每一个anchor预测类别和偏移量。这个操作使得召回率提升7%,mAP轻微下降了0.3%。
聚类预测anchor的尺寸和长宽比---Predicting the size and aspect ratio of anchor boxes using dimension clusters:在Faster R-CNN里,anchor box的尺寸和长宽比是以经验给出的,为了得到更好的预测结果,YOLOv2对训练集的bounding box进行K-means聚类自动得到先验框。mAP提升了5%。
细粒度特征---Fine-Grained Features:高分辨率的特征图对于检测小物体很有用,YOLOv2通过将相邻的特征叠加到不同的通道的方式实现将高分辨率特征和低分辨率特征连接起来。mAP提升1%。
多尺度训练---Multi-Scale Training:由于去掉了全连接层,网络可以接收任意尺寸的输入,因此为了提高不同尺寸图像的检测效果,作者采用了{320,352,...,608}等10种输入图像的尺寸,每10个batch更换一种尺寸训练,使其适应不同尺度的输入。
Darknet-19---新的网络:由19个卷积层和5个池化层组成,在保持精度的同时能够快速的对一幅图片进行检测。
YOLOv3
YOLOv3是YOLOv2的提升版本,其基本结构如下:
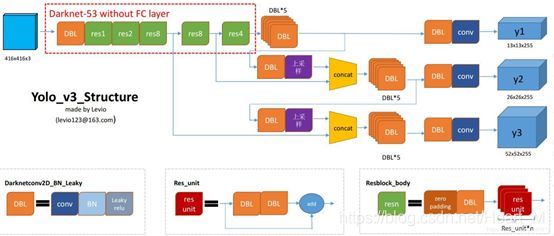
可以看到YOLOv3具有以下改进:
首先,YOLOv3提出了一个更深度的鲁棒性的特征提取器Darknet-53。借鉴了ResNet网络的结构,大量使用残差的跳层连接,为了降低池化带来的梯度负面效果,作者直接摒弃了pooling,用conv的stride来实现降采样。
其次,YOLOv3使用了3个不同尺度的特征图预测边界框。每一张特征图的每一个单元预测3个边界框,每个特征图的每个单元所对应的感受野不同,因此anchor的尺寸也不同,具体如下:

最后,YOLOv3使用多标签分类来适应包含许多重叠标签的更复杂数据集。也就是对于分类使用logistic来代替softmax。早期YOLO,作者曾用softmax获取类别得分并用最大得分的标签来表示包含再边界框内的目标,但是前提是类别是独立的,非此即彼才行,如果是狗和哈巴狗就不行了,而用logistic就是对每种类别使用二分类的logistic回归,即你要么是这种类别要么就不是,然后便利所有类别,得到所有类别的得分,选取大于阈值的类别。
在MSCOCO数据集上对其进行测验,与SSD变体进行相同的操作,YOLOv3为33%,DSSD513为33.2%,但是速度却是后者的3倍快,精确度稍微落后RetinaNet一点(40.8%)。但是在IOU=0.5的时候使用旧版的mAP,YOLOv3为57.9%,DSSD513为53.3%,RetinaNet为61.1%。由于多尺度预测的优势,YOLOv3在小物体检测上很有优势。
SSD
SSD是one-stage的多类别single-shot检测器,目前在工程上SSD的应用非常广泛。SSD在准确度和速度上都有着不错的表现,其网络结构如图所示:
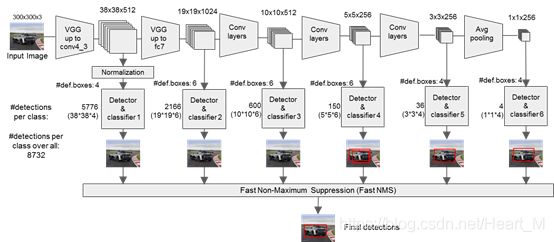
我们可以看到,SSD的网络结构在不同尺度的特征图上通过对默认的边界框进行回归预测和分类,对于不同水平的特征图,每个点有的有4个边界框,有的有6个边界框(这些边界框在Faster R-CNN中叫做anchor,其每个点有9个固定的anchor)。不同特征图上的默认边界框的尺寸是通过最高层和最低层之间的规则空间计算的,计算公式如下:

其中:Smin指的是最底层特征图边界框尺寸,Smax指的是最高层特征图边界框尺寸
在训练阶段,将边界框与ground truth进行匹配以分出正负样本,匹配规则如下:首先,寻找与每一个ground truth有最大的IoU的default box,这样就能保证ground truth至少有default box匹配;SSD之后又将剩余还没有配对的default box与任意一个ground truth尝试配对,只要两者之间的IoU大于阈值(SSD 300 阈值为0.5),就认为match;配对到ground truth的default box就是positive,没有配对的default box就是negative。但是这样的负样本数量过大,于是作者又采用hard negative mining的方法对负样本进行采样,对所有的负样本按照置信度从高到低排列,然后挑选置信度高的样本使正负样本的比例保持在1:3。而且作者也采用了数据增强(data augmentation)的技巧,被证明能够很大程度上增加精确度。
实验证明,采用VGG-16作为骨架的SSD512在mAP和速度上都有良好的表现。在PASCAL VOC2017和2012数据集上,SSD512分别达到81.6%mAP和80.0%mAP,作为对比,Faster R-CNN在两种数据集上分别是78.8%mAP和75.9%mAP;YOLO在VOC2012上为57.9%mAP。在MS COCODET数据集上,SSD512在所有评估标准下都优于Faster R-CNN。
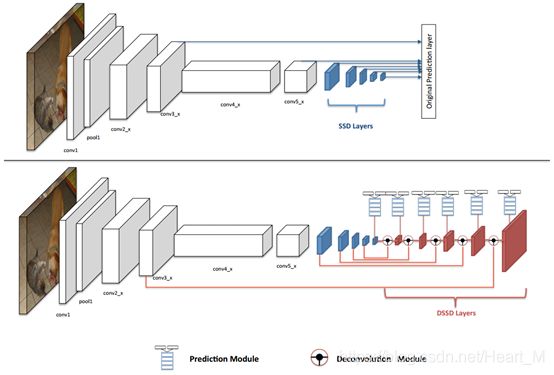
DSSD(Deconvolutional Single Shot Detector)
DSSD为SSD的修改版本,增加了预测模块和反卷积模块并且采用ResNet-101作为主干网络。SSD和DSSD的网络结构对比如下所示:
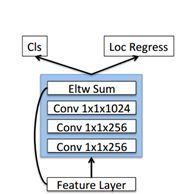
对于预测模块,给每一个预测层增加了一个残差块,对预测层和残差块的输出进行元素相加。这么做的目的是提取更深维度的特征用于分类和回归。基本结构如下所示:
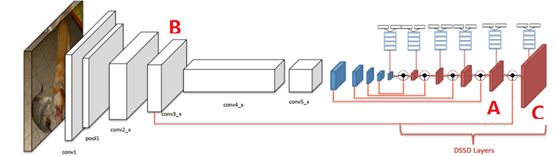
至于为什么要增加反卷积,这是因为虽然SSD在低层特征图上对小目标进行检测,但是由于高层语义特征较少,检测效果并不理想,因此采用反卷积操作将高层语义信息和低层的高分辨率特征进行融合,提高检测精确度。如下所示,DM模块里的要反卷积的高层特征图(图中以A表示)和SSD的卷积的低层特征图(图中以B表示)和最后得到的融合后的卷积图(图中以C表示),然后将C送入预测模块进行回归和分类。
训练分为3步:在ILSVRC CLSLOC数据集上预训练ResNet-101,然后在检测数据集上使用321×321或者513×513的输入训练原始的SSD模型,最后冻结所有SSD模型的权重训练反卷积模块。
在PASCAL VOC和MS COCO数据集上的实验证实了DSSD513模型的有效性,增加的预测模块和反卷积模块在VOC2007数据集上带来了2.2%的精确度的提升,但是速度却没有优势,主要原因是采用ResNet网络推理时间更长。
RetinaNet
RetinaNet是2018年2月份提出的用focal loss作为分类损失函数的one-stage目标检测器。长此以来,one-stage检测精度落后于two-stage,而RetinaNet在保持速度优势的同时,检测精度达到了媲美two-stage检测器的水平。网络模型示意图如下:
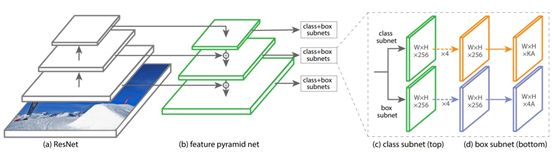
R-CNN是一个典型的two-stage目标检测器,第一阶段生成一组稀疏的候选区域(region proposals),第二阶段为每一个候选区域进行分类。由于第一阶段过滤掉了大部分的负样本区域,two-stage目标检测器相比于one-stage检测器能够达到更高的精确度,one-stage目标检测器提取了一组稠密的候选区域。主要原因是one-stage检测器在训练拟合的时候正负样本的极度不平衡。为了解决这个问题,作者提出了名为focal loss的损失函数。那为什么focal loss可以克服类别不平衡问题呢?因为通过focal loss,量大的类别所贡献的loss被大幅砍削,训练过程中量少的类别拥有了更大的话语权,更加被model所关心了。所以RetinaNet在保留了之前one-stage目标检测器的速度优势的同时,也解决了one-stage检测器难以训练正负样本不平衡的问题。
实现证明,在COCO数据集上,采用ResNet-101-FPN作为主干网络的RetinaNet达到39.1%AP,采用ResNeXt-101-FPN作为主干网络时达到40.8%AP,作为对比,DSSD513为33.2%AP。RetinaNet也极大的提升了对于小目标和中等目标的检测效果。
M2Det
为了满足目标实例间各种各样的尺度变化,SSD型、FPN型特征金字塔被提出来解决这个问题,但是本文作者认为对于目标检测而言特征表示可能还不够,于是MLFPN(multilevel feature pyramid network)被提出来构建特征金字塔,其结构如下所示:
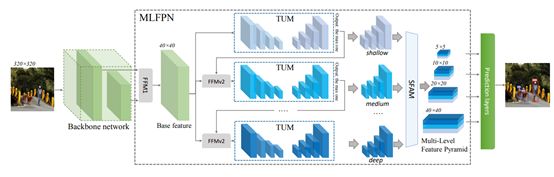
FFM为特征融合模块,TUM为细化U型模块,SFAM为尺度特征聚合模块。作者采用了3步来获得最后的增强的特征金字塔(feature pyramids):首先,从主干网络多个层被提取的多尺寸特征被作为基础特征。其次,基础特征被喂到一个block里面,这个block由交替连接的Thinned Ushape Module(TUM)和Feature Fusion Module(FFM)组成,然后获得TUM的decoder layer作为下一步的特征。最后,SFAM聚合multi-level&multi-scale的特征。到目前为止,多尺度(multi-scale)和多级(multi-level)的特征就准备好了,接下来以一种端对端(end-to-end)的方式利用SSD模型结构获得边界框位置和分类结果。
在COCO数据上采用VGG-16作为主干网络进行推理,M2Det在single-scale推理上精确度为41.0%AP,速度为11.8fps,在multi-scale推理上精确度为44.2%,在单尺度推理方面,其在精确度方面优于RetinaNet800(ResNet-101-FPN)0.9%,但是速度却慢了2倍多。
参考文章:
https://zhuanlan.zhihu.com/p/47575929
https://zhuanlan.zhihu.com/p/49556105
https://blog.csdn.net/litt1e/article/details/88907542
https://zhuanlan.zhihu.com/p/33544892
https://www.cnblogs.com/MY0213/p/9858383.html
https://blog.csdn.net/zj15939317693/article/details/80599596
https://blog.csdn.net/JNingWei/article/details/80038594
https://blog.csdn.net/sinat_37532065/article/details/87385302
参考文献:
[1] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 779–788, June 2016.
[2] J. Redmon and A. Farhadi, “Yolo9000: Better, faster, stronger,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6517–6525, July 2017.
[3] J. Redmon and A. Farhadi, “Yolov3: An incremental improvement,” CoRR, vol. abs/1804.02767, 2018.
[4] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “Ssd: Single shot multibox detector,” in Computer Vision– ECCV 2016 (B. Leibe, J. Matas, N. Sebe, and M. Welling, eds.), (Cham), pp. 21–37, Springer International Publishing, 2016.
[5] C.-Y. Fu, W. Liu, A. Ranga, A. Tyagi, and A. C. Berg, “Dssd: Deconvolutional single shot detector,” arXiv preprint arXiv:1701.06659, 2017.
[6] T. Lin, P. Goyal, R. Girshick, K. He, and P. Dollr, “Focal loss for dense object detection,” in 2017 IEEE International Conference on Computer Vision (ICCV), pp. 2999–3007, Oct 2017.
[7] Q. Zhao, T. Sheng, Y. Wang, Z. Tang, Y. Chen, L. Cai, and H. Ling, “M2det: A single-shot object detector based on multi-level feature pyramid network,” arXiv preprint arXiv:1811.04533, 2018.
[8] Z. Zou, Z. Shi, Y. Guo, and J. Ye, “Object detection in 20 years: A survey,” CoRR, vol. abs/1905.05055, 2019.
[9] L. Jiao, F. Zhang, F. Liu, "A Survey of Deep Learning-based Object Detection", arXiv:1907.09408v2 [cs.CV] 10 Oct 2019