mxnet复现SSD之数据集的导入
mxnet复现SSD系列文章目录
一、数据集的导入.
二、SSD模型架构.
三、训练脚本的实现.
四、损失、评价函数.
五、预测结果.
文章目录
- mxnet复现SSD系列文章目录
- 前言
- 一、pascal VOC
- 二、导入数据集
-
- 1. 拆分数据集
- 2.制作用于mxnet中ImageDetIter类读取的rec,lst文件
- 三、读取rec文件,展示结果
- 参考链接
前言
本项目是按照pascal voc的格式读取数据集,数据集为kaggle官网提供的口罩检测数据集,地址:Face Mask Detection,模型架构参考自gluoncv ssd_300_vgg16_atrous_voc源码
一、pascal VOC
首先介绍一下pascal voc格式
.
└── VOCdevkit #根目录
└── VOC2012 #不同年份的数据集
├── Annotations #存放xml文件,文件序号与JPEGImages中的图片一一对应
├── ImageSets #该目录下存放的都是txt文件,txt文件中每一行包含一个图片的名称,末尾会加上±1表示正负样本
│ ├── Action
│ ├── Layout
│ ├── Main
│ └── Segmentation
├── JPEGImages #存放源图片
├── SegmentationClass #存放的是图片,语义分割相关
└── SegmentationObject #存放的是图片,实例分割相关
重点看一下Annotations中的文件内容:
> <annotation>
<folder>VOC2012folder>
<filename>2007_000027.jpgfilename> // 对应的图片名称
<source>
<database>The VOC2007 Databasedatabase>
<annotation>PASCAL VOC2007annotation>
<image>flickrimage>
source>
<size>
<width>486width> // 图片的宽
<height>500height> // 图片的高
<depth>3depth> // 图片通道大小
size>
<segmented>0segmented>
<object>
<name>personname> // 图片包含的类别
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult> // difficult代表是否难以识别
<bndbox> // bndbox的左上角和右下角坐标
<xmin>174xmin>
<ymin>101ymin>
<xmax>349xmax>
<ymax>351ymax>
bndbox>
<part>
<name>headname>
<bndbox>
<xmin>169xmin>
<ymin>104ymin>
<xmax>209xmax>
<ymax>146ymax>
bndbox>
part>
<part>
<name>handname>
<bndbox>
<xmin>278xmin>
<ymin>210ymin>
<xmax>297xmax>
<ymax>233ymax>
bndbox>
part>
<part>
<name>footname>
<bndbox>
<xmin>273xmin>
<ymin>333ymin>
<xmax>297xmax>
<ymax>354ymax>
bndbox>
part>
<part>
<name>footname>
<bndbox>
<xmin>319xmin>
<ymin>307ymin>
<xmax>340xmax>
<ymax>326ymax>
bndbox>
part>
object>
annotation>
二、导入数据集
1. 拆分数据集
从官网下载的数据集并没有分解为训练集和测试集,所以我们要自己拆分,一般按照9:1(训练集:测试集)的比例拆分。
在facemask文件夹下生成train和test两个文件夹
每个文件夹分别包含annotations和images文件夹
代码如下:
import random
import shutil
import os
data_path = '/facemask'
image_path = os.path.join(data_path, 'images')
image_num = len(os.listdir(image_path))
image_index = list(range(0, image_num))
random.shuffle(image_index)
num = int(image_num*0.9)
train_list = image_index[:num]
val_list = image_index[num:]
data_list = {'train':train_list, 'test':val_list}
for set_list in data_list:
set_path = os.path.join(data_path, set_list)
if not os.path.exists(set_path):
os.mkdir(set_path)
for idx in data_list[set_list]:
xml_dir = os.path.join(set_path, 'annotations')
if not os.path.exists(xml_dir):
os.mkdir(xml_dir)
img_dir = os.path.join(set_path, 'images')
if not os.path.exists(img_dir):
os.mkdir(img_dir)
xml_name = 'maksssksksss' + str(idx) + '.xml'
xml_path = os.path.join(data_path, 'annotations', xml_name)
img_name = 'maksssksksss' + str(idx) + '.png'
img_path = os.path.join(data_path, 'images', img_name)
shutil.copy(xml_path, os.path.join(xml_dir, xml_name))
shutil.copy(img_path, os.path.join(img_dir, img_name))
2.制作用于mxnet中ImageDetIter类读取的rec,lst文件
lst文件格式为index, 2+额外的图片信息长度(一般为宽和高), label长度,类别, 真实框的四个坐标, 相对地址
0 4 5 400.0 267.0 0.0000 0.1050 0.4082 0.1650 0.5243 test\images\maksssksksss104.png
因为img2rec中,需要读取数字4来使程序知道哪里为你的label标签起始位置
rec主要是将图片转化问二进制文件存储到.rec的文件中,方便读取
关于rec和lst文件的详细介绍可参考https://blog.csdn.net/u014380165/article/details/78279820
因为mxnet版本原因,有些地方可能有些不同。
首先创建基类imdb:其中只实现了lst文件的读写
import os
class imdb(object):
def __init__(self):
self.num_images = 0
self.image_set = None
def image_path_from_index(self, index):
raise NotImplementedError
def label_from_index(self, index):
raise NotImplementedError
def image_shape_from_index(self, index):
raise NotImplementedError
def save_img_list(self, target_path, shuffle):
"""
生成lst文件,保存指定路径中
:param target_path: 目标路径
"""
# 进度条
def progress_bar(count, total, suffix=''):
import sys
bar_len = 24
filled_len = int(round(bar_len * count / float(total)))
percents = round(100.0 * count / float(total), 1)
bar = '=' * filled_len + '-' * (bar_len - filled_len)
sys.stdout.write('[%s] %s%s ...%s\r' % (bar, percents, '%', suffix))
sys.stdout.flush()
str_list = []
for idx in range(self.num_images):
progress_bar(idx, self.num_images)
label = self.label_from_index(idx) # 图片类别和bbox标签
img_shape = self.image_shape_from_index(idx) # 图片宽高标签
path = self.image_path_from_index(idx) # 图片路径
str_list.append('\t'.join([str(idx), str(4),
str(label.shape[1]), str(img_shape[0]), str(img_shape[1])] +
['{0:.4f}'.format(x) for x in label.ravel()] + [path]) + '\n')
if str_list:
if shuffle:
import random
random.shuffle(str_list)
fname = os.path.join(target_path, self.image_set + '.lst')
with open(fname, 'w+') as f: # 写入.lst文件中
for line in str_list:
f.write(line)
else:
raise RuntimeError("No image in this file")
继承imdb类,具体实现内容在此类
import os, sys
import numpy as np
import xml.etree.ElementTree as ET
curr_path = os.path.abspath(os.path.dirname(__file__))
sys.path.append(os.path.join(curr_path, '..'))
from tools.imdb import imdb
import mxnet
import argparse
import subprocess
class FaceMask(imdb):
def __init__(self, mask_path, image_set, class_names, shuffle):
super(FaceMask, self).__init__()
self.mask_path = mask_path
self.image_set = image_set
self.class_names = class_names.strip().split(',') # 类别列表
self.num_class = len(self.class_names)
self.image_shape_labels = []
self.image_index = self._load_image_index(shuffle) # 索引列表
self.num_images = len(self.image_index)
self.labels = self._load_image_labels() # 标签
print(self.class_names)
def _load_image_index(self, shuffle):
image_index = []
image_path = os.path.join(self.mask_path, self.image_set, 'images')
image_file = os.listdir(image_path)
for name in image_file:
idx = name.split('maksssksksss')[1][:-4]
image_index.append(idx)
if shuffle:
import random
random.shuffle(image_index)
return image_index
def image_path_from_index(self, index):
image_file = os.path.join(self.image_set, 'images', 'maksssksksss' + str(self.image_index[index]) + '.png')
assert image_file, 'path {} is not exist'.format(image_file)
return image_file
def label_from_index(self, index):
assert self.labels is not None, "Labels not processed"
return self.labels[index]
def image_shape_from_index(self, index):
assert self.image_shape_labels is not None, "Image shape labels not processed"
return self.image_shape_labels[index]
def _label_path_from_index(self, index):
label_file = os.path.join(self.mask_path, 'annotations', 'maksssksksss' + str(index) + '.xml')
assert label_file, 'path {} is not exist'.format(label_file)
return label_file
def _load_image_labels(self):
"""
加载图片标签,存入self.image_labels变量中
:return 返回图片标签
"""
temp = []
for idx in self.image_index:
label_file = self._label_path_from_index(idx) # 返回该图片的annotation文件路径
tree = ET.parse(label_file) # 解析xml文件
root = tree.getroot() # 获得第一标签
size = root.find('size')
width = float(size.find('width').text)
height = float(size.find('height').text)
self.image_shape_labels.append([width, height])
label = []
for obj in root.iter('object'):
# difficult = int(obj.find('difficult').text)
# if not self.config['use_difficult'] and difficult == 1:
# continue
cls_name = obj.find('name').text
if cls_name not in self.class_names:
continue
# self.class_names.append(cls_name)
cls_id = self.class_names.index(cls_name) # 查找当前class_name的序号
xml_box = obj.find('bndbox')
xmin = float(xml_box.find('xmin').text) / width
ymin = float(xml_box.find('ymin').text) / height
xmax = float(xml_box.find('xmax').text) / width
ymax = float(xml_box.find('ymax').text) / height
label.append([cls_id, xmin, ymin, xmax, ymax])
temp.append(np.array(label))
return temp
def parse_args():
parser = argparse.ArgumentParser(description='Prepare lst and rec for dataset')
parser.add_argument('--root', dest='root_path', help='dataset root path',
default=None, type=str)
parser.add_argument('--target', dest='target_path', help='output list path',
default=None, type=str)
parser.add_argument('--set', dest='set', help='train, val',
default='train,val', type=str)
parser.add_argument('--class-names', dest='class_names', help='choice class to use',
default='without_mask,with_mask,mask_weared_incorrect', type=str)
parser.add_argument('--shuffle', dest='shuffle', help='shuffle list',
default=False, type=bool)
args = parser.parse_args()
return args
def load_facemask(mask_path, target_path, image_set, class_names, shuffle):
image_set = [y.strip() for y in image_set.split(',')]
assert image_set, "No image_set specified"
for s in image_set:
imdb = FaceMask(mask_path, s, class_names, shuffle)
imdb.save_img_list(target_path, shuffle)
if __name__ == '__main__':
args = parse_args()
print("saving list to disk...")
load_facemask(args.root_path, args.target_path, args.set, args.class_names, args.shuffle)
print('{} list file {} is generated ...'.format(args.set, args.target_path))
im2rec_path = os.path.join(mxnet.__path__[0], 'tools/im2rec.py')
if not os.path.exists(im2rec_path):
im2rec_path = os.path.join(os.path.dirname(os.path.dirname(mxnet.__path__[0])), 'tools/im2rec.py')
subprocess.check_call(['python', im2rec_path,
os.path.abspath(args.target_path),
os.path.abspath(args.root_path),
'--pack-label'])
print('Record file is generated ...')
三、读取rec文件,展示结果
直接调用ImageDetIter类中已实现的draw_next()。
值得注意的是shuffle=True时,必须提供idx文件否则会报错
import mxnet as mx
rec ='facemask/train.rec'
idx ='facemask/train.idx'
train_iter = mx.image.ImageDetIter(
path_imgrec=rec,
path_imgidx=idx,
batch_size=20,
data_shape=(3, 300, 300),
shuffle=False,
)
for image in train_iter.draw_next(waitKey=0, window_name='disp'):
pass
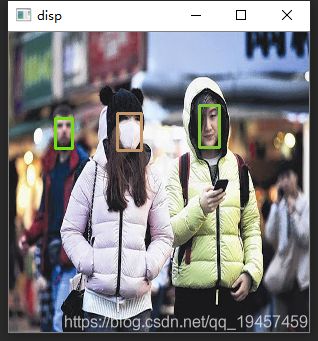
label标签内容:
其中-1为额外的填充,为了使所有标签都有相同的形状
[[ 0. 0.1543 0.2869 0.2129 0.388 ]
[ 1. 0.3613 0.2732 0.4414 0.3934]
[ 0. 0.6348 0.2459 0.7031 0.3852]
[-1. -1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. ].....]
参考链接
https://blog.csdn.net/u014380165/article/details/78279820
https://github.com/Sparks-zs/mxnet-ssd