Pixel Difference Networks for Efficient Edge Detection论文笔记
文章目录
- 一、背景知识
- 二、Pixel Difference Convolution(PDC)
-
- 1.CPDC
- 2.APDC
- 3.RPDC
- 三、轻量化边缘检测网络
-
- A. Block_x_y
- B. CSAM
- C. CDCM
- D. 1*1卷积层
- E. 深度监督(deep supervision)
- F. 损失函数
- 四、实验结果
-
- 1. 消融实验
- 2.网络可扩展性
- 对比实验
- 参考文献
一、背景知识
现阶段,虽然使用CNN构建的网络可以获得和人类一样的边缘检测能力,但是基于CNN的边缘检测的高性能是通过大型预训练的CNN主干实现的,这既消耗内存有消耗能量。此外传统算法逐渐被人们遗忘。
边缘检测的主要目标是识别清晰的图像亮度变化,例如强度、颜色或纹理的不连续性。传统的边缘检测算法基于图像梯度或导数信息,早期的经典方法使用一阶或二阶导数,后来基于学习的方法进一步利用各种梯度信息来产生更精确的边界。因为梯度可以利用差分来代替,故产生了下述的几种算子。
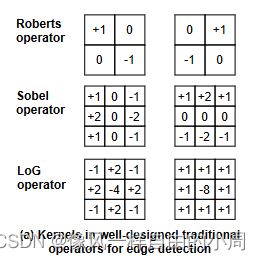
CNN内核是通过从没有对梯度信息进行显式编码的随机初始化开始进行优化的,这使得卷积难以专注于与边缘相关的特征。
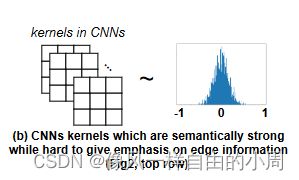
作者想要设计一个新的卷积满足可以保留CNN强大的学习能力,提取语义上有意义的表示,从而实现鲁棒和准确的边缘检测,同时也可以捕获有助于边缘检测的图像梯度信息使得CNN模型能够更专注于于边缘相关的特征。

据此,作者提出了差分卷积,该卷积结合了传统边缘检测算子ELBP和传统CNN。
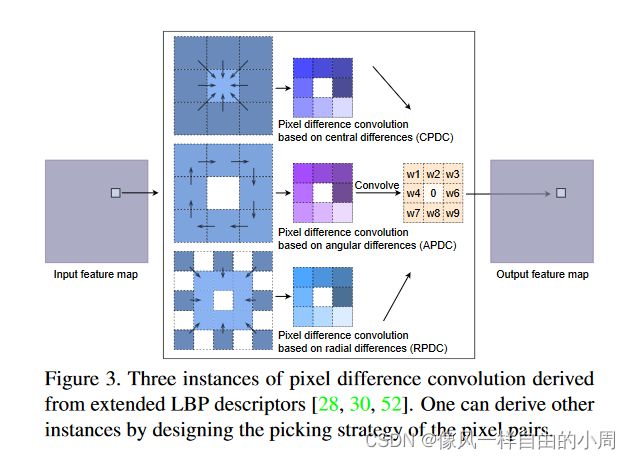
同时,因为基于CNN的边缘检测器存在以下缺陷:内存消耗大,模型规模大;能耗高,计算成本高;运行效率低,吞吐量低;标签效率低,需要在大规模数据集上进行模型预训练。这是由于可用于训练边缘检测模型的标注数据有限,因此需要一个预训练好的(通常是大的)主干。重要的是开发轻量级结构,以在边缘检测的准确性和效率之间实现更好的权衡。据此,作者引入了PDC设计了一个轻量化网络。
综上,作者针对现阶段存在的两个问题,提出了新的卷积PDC和一个轻量化的边缘检测网络。接下来,我们详细看一下PDC和轻量化的网络结构。
二、Pixel Difference Convolution(PDC)
PDC和传统的卷积计算过程类似,只不过PDC中卷积核所覆盖的局部特征图块中的像素被像素差异所取代。传统卷积和PDC计算数学公式如下:
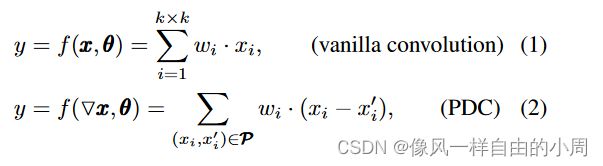
从上述的计算公式不难发现,和传统卷积计算相比,PDC的计算成本和内存占用增加了一倍。然而,一旦卷积核已经学习完毕,就可以根据所选像素对的位置,通过保存模型中和权重的差异,将PDC层转化为普通卷积。以这种方式,便可以在推理期间保持效率。关于转化计算公式,下面会展开说明。
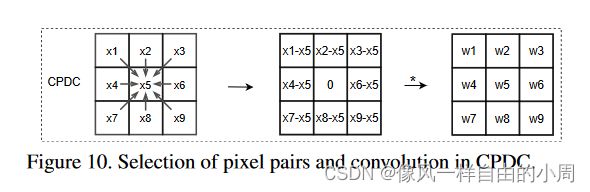
作者受LBP启发将ELBP合并到传统CNN中,提出了三种PDC结构,如图3所示。
下面具体看一下这三个PDC的计算过程以及其如何转化为卷积计算。
1.CPDC
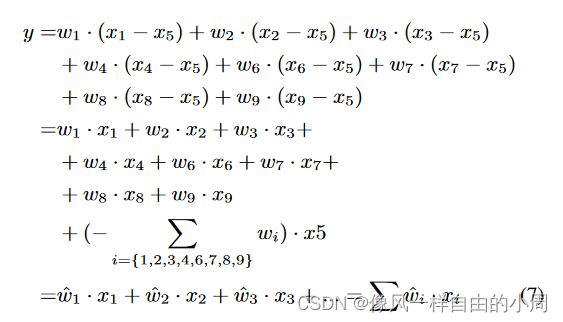
def func(x, weights, bias=None, stride=1, padding=0, dilation=1, groups=1):
assert dilation in [1, 2], 'dilation for cd_conv should be in 1 or 2'
assert weights.size(2) == 3 and weights.size(3) == 3, 'kernel size for cd_conv should be 3x3'
assert padding == dilation, 'padding for cd_conv set wrong'
weights_c = weights.sum(dim=[2, 3], keepdim=True)
yc = F.conv2d(x, weights_c, stride=stride, padding=0, groups=groups)
y = F.conv2d(x, weights, bias, stride=stride, padding=padding, dilation=dilation, groups=groups)
return y - yc
注:这里作者并没有实现当padding=0时候的情形,只实现了当padding=1时的情形,当padding=1时这个时候当运行到计算中间3*3像素时就可以和上述公式对应上了。在调用这个函数的时候注意代码中assert。这里作者是根据PDC和普通卷积之间的关系构建的代码,只实现了在某些情况下的功能,故作者添加了assert。接下来的两个差分卷积也同样存在该问题。
2.APDC

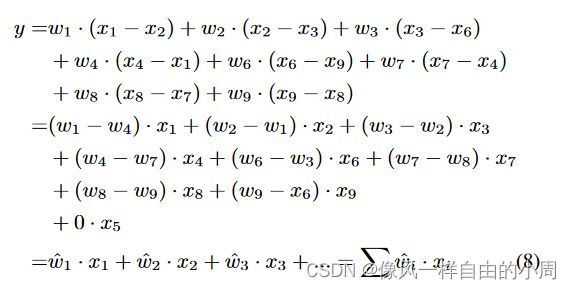
def func(x, weights, bias=None, stride=1, padding=0, dilation=1, groups=1):
assert dilation in [1, 2], 'dilation for ad_conv should be in 1 or 2'
assert weights.size(2) == 3 and weights.size(3) == 3, 'kernel size for ad_conv should be 3x3'
assert padding == dilation, 'padding for ad_conv set wrong'
shape = weights.shape
weights = weights.view(shape[0], shape[1], -1)
weights_conv = (weights - weights[:, :, [3, 0, 1, 6, 4, 2, 7, 8, 5]]).view(shape) # clock-wise
y = F.conv2d(x, weights_conv, bias, stride=stride, padding=padding, dilation=dilation, groups=groups)
return y
3.RPDC
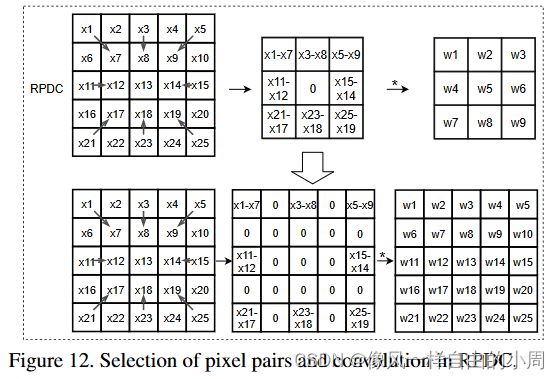

在RPDC的图12中发现一种是转化成3X3大小的矩阵,另一种是转化为5X5大小的矩阵。作者在这里实现了下面这一个5X5大小的矩阵。
def func(x, weights, bias=None, stride=1, padding=0, dilation=1, groups=1):
assert dilation in [1, 2], 'dilation for rd_conv should be in 1 or 2'
assert weights.size(2) == 3 and weights.size(3) == 3, 'kernel size for rd_conv should be 3x3'
padding = 2 * dilation
shape = weights.shape
if weights.is_cuda:
buffer = torch.cuda.FloatTensor(shape[0], shape[1], 5 * 5).fill_(0)
else:
buffer = torch.zeros(shape[0], shape[1], 5 * 5)
weights = weights.view(shape[0], shape[1], -1)
buffer[:, :, [0, 2, 4, 10, 14, 20, 22, 24]] = weights[:, :, 1:]
buffer[:, :, [6, 7, 8, 11, 13, 16, 17, 18]] = -weights[:, :, 1:]
buffer[:, :, 12] = 0
buffer = buffer.view(shape[0], shape[1], 5, 5)
y = F.conv2d(x, buffer, bias, stride=stride, padding=padding, dilation=dilation, groups=groups)
return y
模型调用这三个模块输入的参数值,这里的rd表示RPDC,else控制的是APDC和CPDC。下面这个代码是接下来要讲到的模型框架里面的第一个Init_conv模块。
if pdcs[0] == 'rd':
init_kernel_size = 5
init_padding = 2
else:
init_kernel_size = 3
init_padding = 1
下面这个代码是作者重写了torch.nn.Conv2d,这里的pdc参数传递的是上述的func函数。
class Conv2d(nn.Module):
def __init__(self, pdc, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=False):
super(Conv2d, self).__init__()
if in_channels % groups != 0:
raise ValueError('in_channels must be divisible by groups')
if out_channels % groups != 0:
raise ValueError('out_channels must be divisible by groups')
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.dilation = dilation
self.groups = groups
self.weight = nn.Parameter(torch.Tensor(out_channels, in_channels // groups, kernel_size, kernel_size))
if bias:
self.bias = nn.Parameter(torch.Tensor(out_channels))
else:
self.register_parameter('bias', None)
self.reset_parameters()
self.pdc = pdc
def reset_parameters(self):
nn.init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = nn.init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in)
nn.init.uniform_(self.bias, -bound, bound)
def forward(self, input):
return self.pdc(input, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
在接下来网络框架中,作者调用了该函数。
Conv2d(pdc, inplane, inplane, kernel_size=3, padding=1, groups=inplane, bias=False)
这里面的groups参数涉及到深度可分离卷积,如果有需要请参考我写的另一篇文章:常见的卷积、卷积变体以及其Pytroch实现。
三、轻量化边缘检测网络
该网络结构不仅轻量化同时可以不使用预训练只需要从头开始训练(关于预训练和从头开始的性能差别,何凯明大神的一篇论文通过实验进行了验证,感兴趣的可以看一下我写的博客:预训练+微调+Rethinking ImageNet Pre-training论文阅读笔记)。具体的网络结构如下:
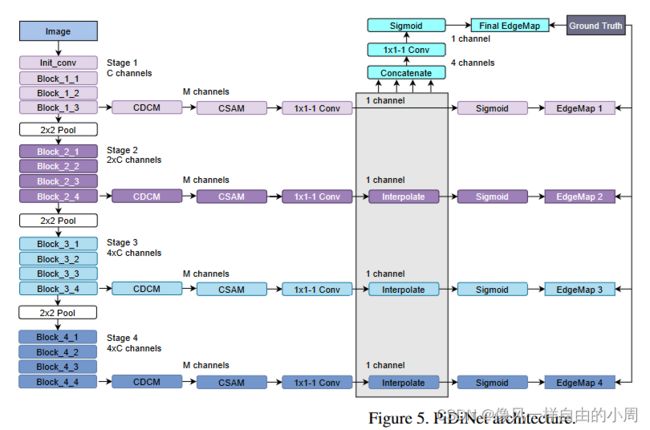
其中Init_conv结构为一个卷积层,该卷积层可以是传统卷积也可以是PDC实现,其余结构如下。
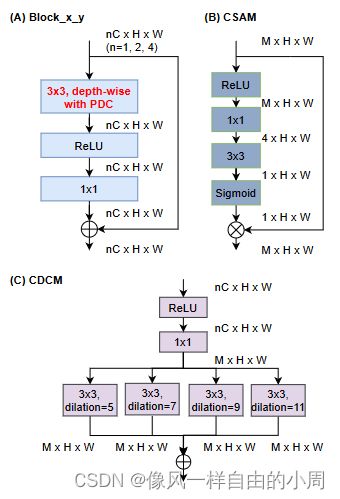
A. Block_x_y
作者为了使得网络结构轻量化的同时能够保持效率,不考虑复杂的多分支轻量化等结构。采用了深度可分离卷积来进行轻量化,采用了残差结构来避免退化,同时在尽量避免通道数的增加(C, 2 × C, 4 × C and 4 × C channels for stage 1, 2, 3, and 4 respectively)。关于深度可分离卷积的介绍可以看一下我的另一篇博客常见的卷积、卷积变体以及其Pytroch实现。
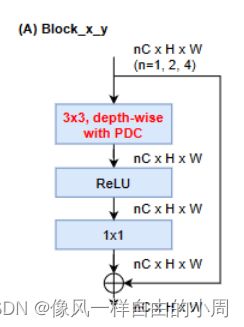
在深度卷积部分作者使用了PDC卷积。但是我看源码发现,作者并不是在每一个Block_x_y上都使用了三种PDC的其中一种,而是也考虑了传统卷积。至于这4中卷积该按照什么样的顺序进行堆叠,我看作者源码考虑了较多的排列情况,我想应该做了不少实验得到相对较好的排列顺序。
下面是Block_x_y的源码,注:nn.Conv2d是传统卷积,没有nn.的Conv2d是作者实现的差分卷积。
class PDCBlock(nn.Module):
def __init__(self, pdc, inplane, ouplane, stride=1):
super(PDCBlock, self).__init__()
self.stride=stride
self.stride=stride
if self.stride > 1:
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.shortcut = nn.Conv2d(inplane, ouplane, kernel_size=1, padding=0)
self.conv1 = Conv2d(pdc, inplane, inplane, kernel_size=3, padding=1, groups=inplane, bias=False)
self.relu2 = nn.ReLU()
self.conv2 = nn.Conv2d(inplane, ouplane, kernel_size=1, padding=0, bias=False)
def forward(self, x):
if self.stride > 1:
x = self.pool(x)
y = self.conv1(x)
y = self.relu2(y)
y = self.conv2(y)
if self.stride > 1:
x = self.shortcut(x)
y = y + x
return y
B. CSAM
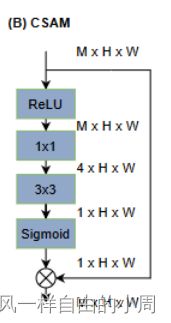
该模块为注意力模块用来消除背景噪声。这里面的注意力(attention)就是Sigmoid后然后相乘,因为注意力机制本质上就是加权求和。为啥能消除背景噪声呢,高斯滤波器大家应该都知道吧,不知道的看一下这篇博客高斯滤波器,图像中出现的噪声大部分是高斯白噪声,高斯滤波器就是在做一种滑动平均来消除高斯白噪声。然后呢,高斯滤波就是一个卷积核,只不过权重固定不变。和高斯滤波器类似,CNN也是取像素和周围像素的滑动平均故能消除背景噪声。
class CSAM(nn.Module):
"""
Compact Spatial Attention Module
"""
def __init__(self, channels):
super(CSAM, self).__init__()
mid_channels = 4
self.relu1 = nn.ReLU()
self.conv1 = nn.Conv2d(channels, mid_channels, kernel_size=1, padding=0)
self.conv2 = nn.Conv2d(mid_channels, 1, kernel_size=3, padding=1, bias=False)
self.sigmoid = nn.Sigmoid()
nn.init.constant_(self.conv1.bias, 0)
def forward(self, x):
y = self.relu1(x)
y = self.conv1(y)
y = self.conv2(y)
y = self.sigmoid(y)
return x * y
C. CDCM
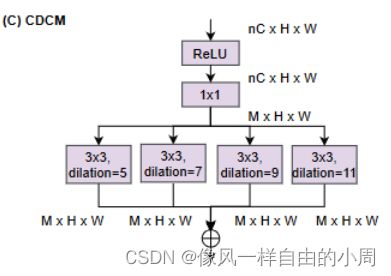
为了细化特征图,从每个阶段结束开始,我们首先构建一个基于紧凑扩张卷积的模块(CDCM)来丰富多尺度边缘信息,它以 n × C个通道为输入,产生 M (M < C)输出中的通道以减轻计算开销。
这里面涉及了空洞卷积,空洞卷积可以用来提高感受野,这个博客里面有介绍:常见的卷积、卷积变体以及其Pytroch实现,emm,为啥总是这篇博客呢,那是因为我看了这个框架发现作者把常见的卷积结构都用了,故进行了简单的整理。
class CDCM(nn.Module):
"""
Compact Dilation Convolution based Module
"""
def __init__(self, in_channels, out_channels):
super(CDCM, self).__init__()
self.relu1 = nn.ReLU()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, padding=0)
self.conv2_1 = nn.Conv2d(out_channels, out_channels, kernel_size=3, dilation=5, padding=5, bias=False)
self.conv2_2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, dilation=7, padding=7, bias=False)
self.conv2_3 = nn.Conv2d(out_channels, out_channels, kernel_size=3, dilation=9, padding=9, bias=False)
self.conv2_4 = nn.Conv2d(out_channels, out_channels, kernel_size=3, dilation=11, padding=11, bias=False)
nn.init.constant_(self.conv1.bias, 0)
def forward(self, x):
x = self.relu1(x)
x = self.conv1(x)
x1 = self.conv2_1(x)
x2 = self.conv2_2(x)
x3 = self.conv2_3(x)
x4 = self.conv2_4(x)
return x1 + x2 + x3 + x4
D. 1*1卷积层
1*1卷积层引入目的主要为了减少通道数。
class MapReduce(nn.Module):
"""
Reduce feature maps into a single edge map
"""
def __init__(self, channels):
super(MapReduce, self).__init__()
self.conv = nn.Conv2d(channels, 1, kernel_size=1, padding=0)
nn.init.constant_(self.conv.bias, 0)
def forward(self, x):
return self.conv(x)
E. 深度监督(deep supervision)
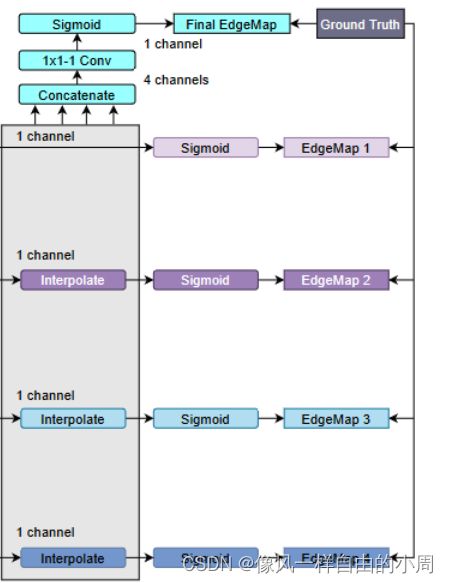
深度监督简单的说我们常见的神经网络都是用输出层的结果和GT计算损失函数,采用深度监督就是把浅层特征经过上下采样等后和GT计算损失函数,然后进行反向传播。如上图,就是本文采用的深度监督。作者在论文中解释到采用深度监督的目的是为了学习丰富的层次边缘。
通常情况下,引入深度监督有以下两个好处:
- 缓解梯度消失或者梯度爆炸的情况
- 添加正则化损失函数,能够提高模型正则性(即提高模型在测试集上的性能)
好了,关于网络结构已经说完了,下面是损失函数。
F. 损失函数

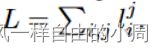
关于该损失函数建议读者读一下原论文的描述。主要是这些特殊符号我打不出来。这里作者考虑到了正负样本对不平衡的问题。
最后,我们看一下作者提供的模型复杂度对比数据。
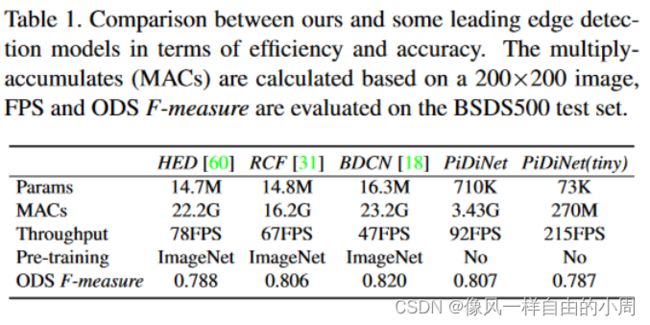
四、实验结果
- 数据集:BSDS500、NYUD、Multicue,对这三个数据集进行翻转、缩放和旋转操作来进行数据增强。
1. 消融实验
主要探讨了Block_x_y模块中的深度可分离卷积到底使用4中卷积中的哪一个以及其排列顺序、Pipeline中的通道数C、CSAM和CDCM和shortcuts是否有存在的必要。下述表中的Baseline指的是Block_x_y模块中的PDC更换为普通卷积。
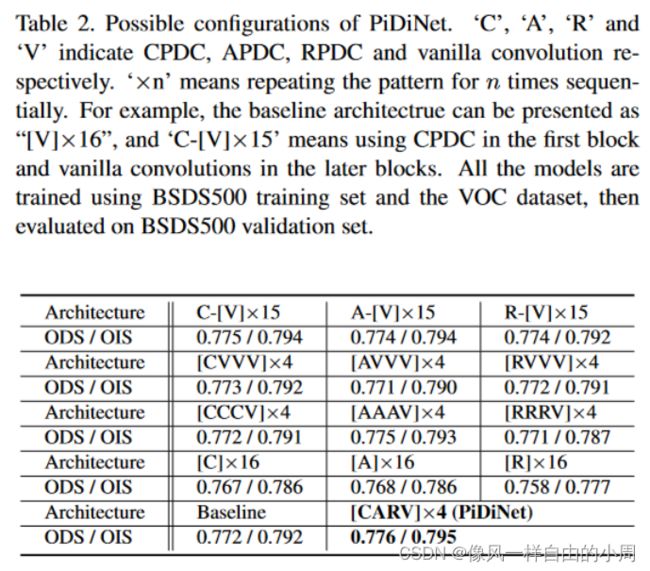
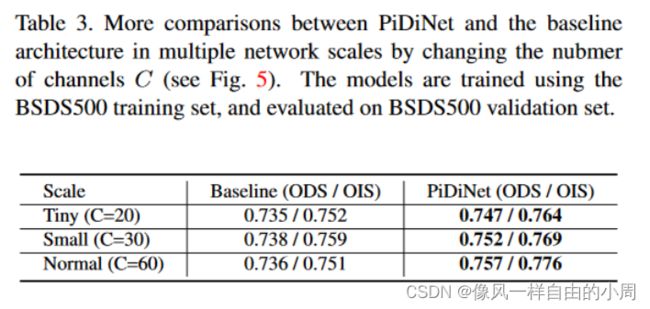
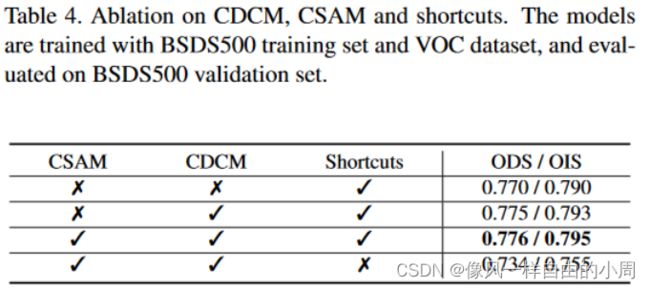
这里说一下作者对于Tabel2和Table4的结果分析。
从Tabell2的结果可以看出,如果只选择某一个卷积(PDC的三个卷积)放入Block_x_y中得到的结果并不是很理想,作者的解释是每一个stage中的第一个块中的PDC已经从原始图像中获得了很多梯度信息,滥用PDC甚至可能导致模型无法保留有用的信息。故最终采用[CARV]X4。具体排列结构如下。
'baseline': {
'layer0': 'cv',
'layer1': 'cv',
'layer2': 'cv',
'layer3': 'cv',
'layer4': 'cv',
'layer5': 'cv',
'layer6': 'cv',
'layer7': 'cv',
'layer8': 'cv',
'layer9': 'cv',
'layer10': 'cv',
'layer11': 'cv',
'layer12': 'cv',
'layer13': 'cv',
'layer14': 'cv',
'layer15': 'cv',
}
'carv4': {
'layer0': 'cd',
'layer1': 'ad',
'layer2': 'rd',
'layer3': 'cv',
'layer4': 'cd',
'layer5': 'ad',
'layer6': 'rd',
'layer7': 'cv',
'layer8': 'cd',
'layer9': 'ad',
'layer10': 'rd',
'layer11': 'cv',
'layer12': 'cd',
'layer13': 'ad',
'layer14': 'rd',
'layer15': 'cv',
}
Table4的结果可以看出使用CSAM、CDCM和shortcuts可以提高模型性能,但是会增加计算成本,故作者载下述实验中又提出了一种新的架构PiDiNet-L(就是去掉CSAM、CDCM这两个模块用来得到更轻量化的结构)。
2.网络可扩展性
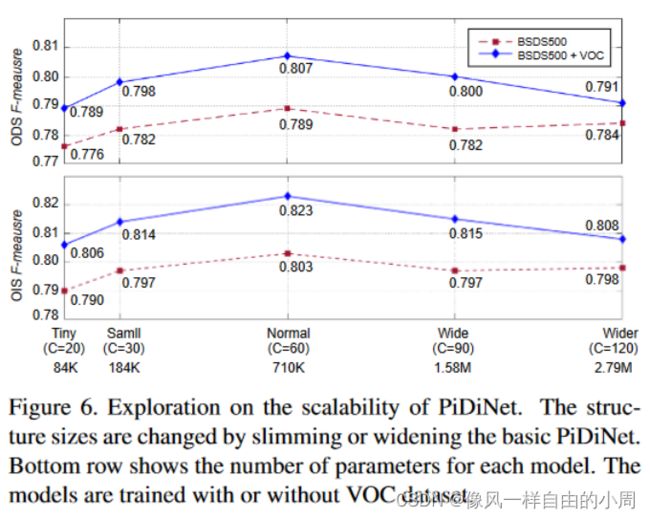
这里作者改变了模型的变量C就是通道数,改变通道数用来改变模型参数量。然后实验发现正如预期的那样,与基本的PiDiNet(Normal)相比,较小的模型网络容量较低,因此在ODS和OIS分数方面性能下降。然而,由于数据集有限,采用参数量大的模型会导致过拟合。
对比实验
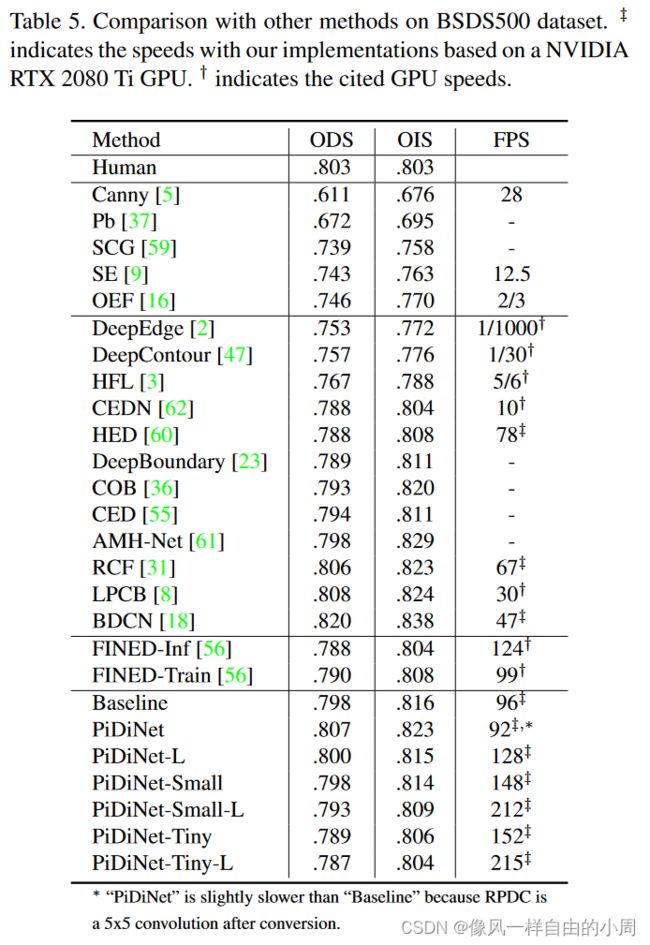
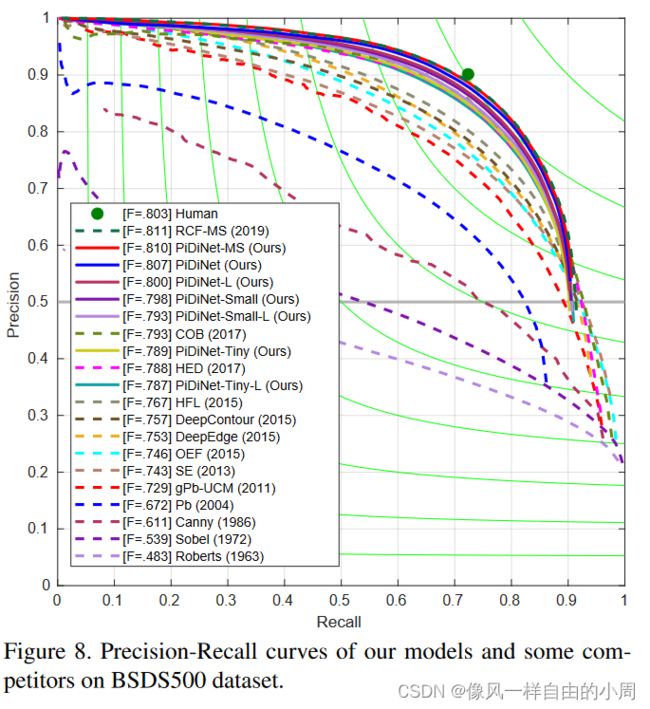
参考文献
1.怎么理解LBP(local binary Pattern)中的灰度不变性?
2.LBP原理介绍以及算法实现
3.DoG和LoG算子
4.深度学习100问-15:什么是深监督(Deep Supervision)?