转载:LSTM实例
仅作为记录,大佬请跳过。
文章目录
- 源代码
- 展示
- 注
- 参考
源代码
可直接运行
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 2.1 准备数据
def prepare_sequence(seq, to_ix):
idxs = [to_ix[w] for w in seq]
return torch.tensor(idxs, dtype=torch.long)
training_data = [
("The dog ate the apple".split(), ["DET", "NN", "V", "DET", "NN"]),
("Everybody read that book".split(), ["NN", "V", "DET", "NN"])
]
word_to_ix = {}
for sent, tags in training_data:
for word in sent:
if word not in word_to_ix:
word_to_ix[word] = len(word_to_ix)
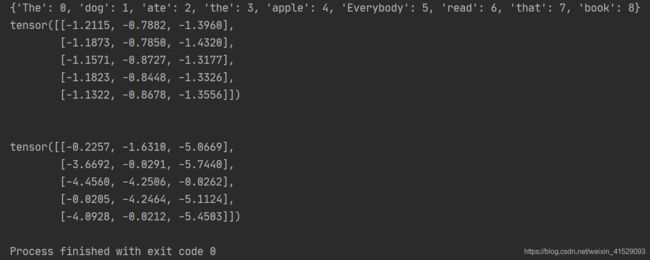
print(word_to_ix)
tag_to_ix = {"DET": 0, "NN": 1, "V": 2}
# 实际中通常使用更大的维度如32维, 64维.
# 这里我们使用小的维度, 为了方便查看训练过程中权重的变化.
EMBEDDING_DIM = 6
HIDDEN_DIM = 6
# 2.1 创建模型
class LSTMTagger(nn.Module):
def __init__(self, embedding_dim, hidden_dim, vocab_size, tagset_size):
super(LSTMTagger, self).__init__()
self.hidden_dim = hidden_dim
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim)
# LSTM以word_embeddings作为输入, 输出维度为 hidden_dim 的隐藏状态值
self.lstm = nn.LSTM(embedding_dim, hidden_dim)
# 线性层将隐藏状态空间映射到标注空间
self.hidden2tag = nn.Linear(hidden_dim, tagset_size)
self.hidden = self.init_hidden()
def init_hidden(self):
# 一开始并没有隐藏状态所以我们要先初始化一个
# 关于维度为什么这么设计请参考Pytoch相关文档
# 各个维度的含义是 (num_layers, minibatch_size, hidden_dim)
return (torch.zeros(1, 1, self.hidden_dim),
torch.zeros(1, 1, self.hidden_dim))
def forward(self, sentence):
embeds = self.word_embeddings(sentence)
lstm_out, self.hidden = self.lstm(
embeds.view(len(sentence), 1, -1), self.hidden)
tag_space = self.hidden2tag(lstm_out.view(len(sentence), -1))
tag_scores = F.log_softmax(tag_space, dim=1)
return tag_scores
# 2.3 训练模型
model = LSTMTagger(EMBEDDING_DIM, HIDDEN_DIM, len(word_to_ix), len(tag_to_ix))
loss_function = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 查看训练前的分数
# 注意: 输出的 i,j 元素的值表示单词 i 的 j 标签的得分
# 这里我们不需要训练不需要求导,所以使用torch.no_grad()
with torch.no_grad():
inputs = prepare_sequence(training_data[0][0], word_to_ix)
tag_scores = model(inputs) # 输出每个单词对应的【词性所在数组的索引——对应的大小值】
print(tag_scores)
print('\n')
for epoch in range(300): # 实际情况下你不会训练300个周期, 此例中我们只是随便设了一个值
for sentence, tags in training_data:
# 第一步: 请记住Pytorch会累加梯度.
# 我们需要在训练每个实例前清空梯度
model.zero_grad()
# 此外还需要清空 LSTM 的隐状态,
# 将其从上个实例的历史中分离出来.
model.hidden = model.init_hidden()
# 准备网络输入, 将其变为词索引的 Tensor 类型数据
sentence_in = prepare_sequence(sentence, word_to_ix)
targets = prepare_sequence(tags, tag_to_ix) # 输出各词性对应词性数组的索引
# 第三步: 前向传播.
tag_scores = model(sentence_in)
# 第四步: 计算损失和梯度值, 通过调用 optimizer.step() 来更新梯度
loss = loss_function(tag_scores, targets)
loss.backward()
optimizer.step()
# 查看训练后的得分
with torch.no_grad():
inputs = prepare_sequence(training_data[0][0], word_to_ix)
tag_scores = model(inputs)
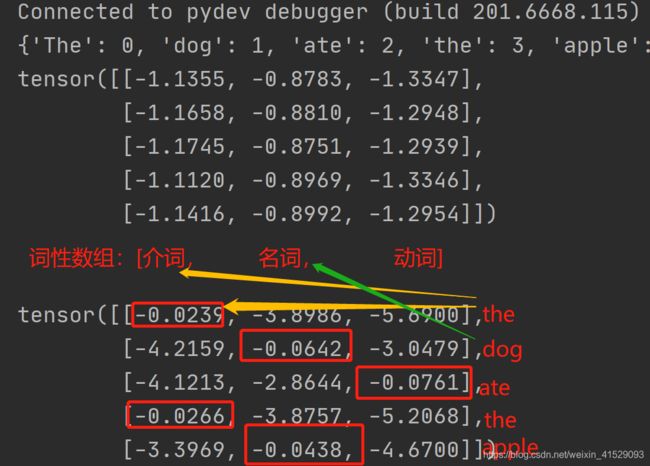
# 句子是 "the dog ate the apple", i,j 表示对于单词 i, 标签 j 的得分.
# 我们采用得分最高的标签作为预测的标签. 从下面的输出我们可以看到, 预测得
# 到的结果是0 1 2 0 1. 因为 索引是从0开始的, 因此第一个值0表示第一行的
# 最大值, 第二个值1表示第二行的最大值, 以此类推. 所以最后的结果是 DET
# NOUN VERB DET NOUN, 整个序列都是正确的!
print(tag_scores)
展示
注
参考
传送门
传送门