单细胞分析实录(10): 消除细胞周期的影响
如果读过一些单细胞的文献,应该会经常看到一群名为"cycling cell"的亚群,T细胞、B细胞、上皮细胞等等在分亚群的时候,都可能碰到。实际上,这群细胞只是因为高表达一些与细胞周期相关的基因,才会被单独聚成一群,里面可能包含多种细胞亚群的混合,只要它们处于细胞周期/增殖状态。
当这群细胞占比很少时,可以不做处理;占比较大,或者处于不同细胞周期时间点(G1, S, G2, M)的细胞相互分开,这时就需要消除细胞周期的影响,留下有意义的生物学差异。下图是比较极端的例子,所有细胞都处于细胞周期,且不同时间点的细胞分开:
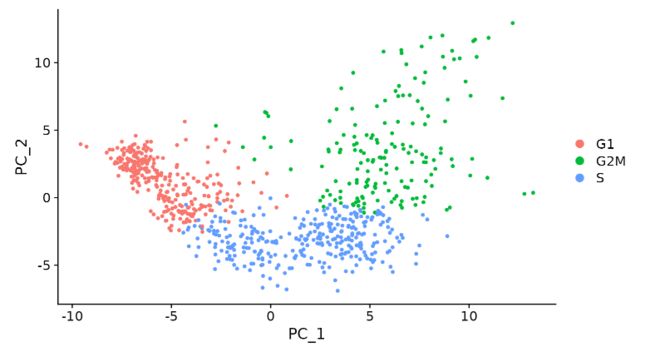
这张图中的细胞是什么类型,有几类亚群暂且不论,仅仅是细胞周期相关基因主导聚类,干扰聚类结果,就挺影响后续分析的。这个例子来自Seurat官网,我也借此例子进行具体演示,我改了其中一些流程代码,希望能说明得清楚一些,后台回复20210316可获取全部代码和测试数据集。
总的来说,Seurat中的函数可以根据经典的细胞周期基因计算周期得分,推断细胞所处的cell-cycle时间点,然后在预处理过程中将其回归掉。
先把标准流程跑下来,
library(Seurat)
library(tidyverse)
test.mat=read.table("nestorawa_forcellcycle_expressionMatrix.remove_some_lines.txt",header = T,row.names = 1,sep = "\t",stringsAsFactors = F)
test.seu=CreateSeuratObject(counts = test.mat)
test.seu <- NormalizeData(test.seu)
test.seu <- FindVariableFeatures(test.seu, selection.method = "vst")
test.seu <- ScaleData(test.seu, features = rownames(test.seu))
test.seu <- RunPCA(test.seu, npcs = 50, verbose = FALSE)
test.seu <- FindNeighbors(test.seu, dims = 1:30)
test.seu <- FindClusters(test.seu, resolution = 0.4)
test.seu <- RunUMAP(test.seu, dims = 1:30)
test.seu <- RunTSNE(test.seu, dims = 1:30)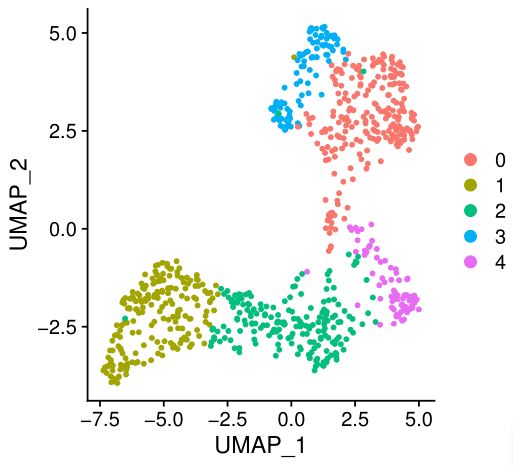
DimPlot(test.seu,reduction = "umap")
FeaturePlot(test.seu,features = c("PCNA","MKI67"),reduction = "umap")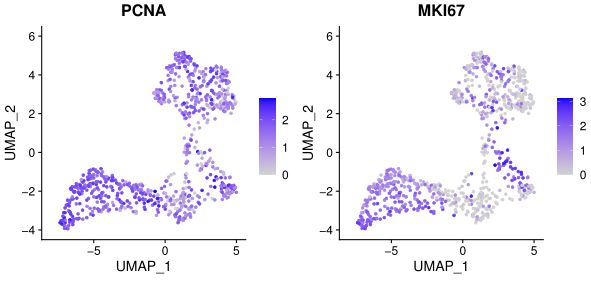
s期基因PCNA,G2/M期基因MKI67均高表达,说明细胞均处于细胞周期
接下来判断这些细胞分别处于什么期,用到Seurat的CellCycleScoring()函数,依据的基因集已内置在Seurat中
s.genes=Seurat::cc.genes.updated.2019$s.genes
g2m.genes=Seurat::cc.genes.updated.2019$g2m.genes
test.seu <- CellCycleScoring(test.seu, s.features = s.genes, g2m.features = g2m.genes, set.ident = TRUE)set.ident参数是将时间点的推断结果赋值为每个细胞的身份,之前聚类之后每个细胞的身份是seurat_clusters 这一步之后[email protected]数据框会多4列:S.Score、G2M.Score、Phase、old.ident
> head([email protected],2)
orig.ident nCount_RNA nFeature_RNA RNA_snn_res.0.4 seurat_clusters S.Score
Prog_013 Prog 2562453 10206 0 0 -0.1230880
Prog_019 Prog 3030553 9987 3 3 -0.1407003
G2M.Score Phase old.ident
Prog_013 -0.4613545 G1 0
Prog_019 0.5763395 G2M 3我们来看一下两个评分和细胞周期phase的关系
[email protected] %>% ggplot(aes(S.Score,G2M.Score))+geom_point(aes(color=Phase))+
theme_minimal()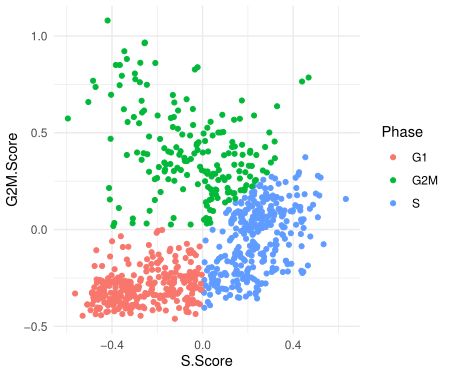
从这个图中,我们可以看出S.Score较高的为S期,G2M.Score较高的为G2M期,都比较低的为G1期
再回过头来看看前面得到的降维图
DimPlot(test.seu,reduction = "umap")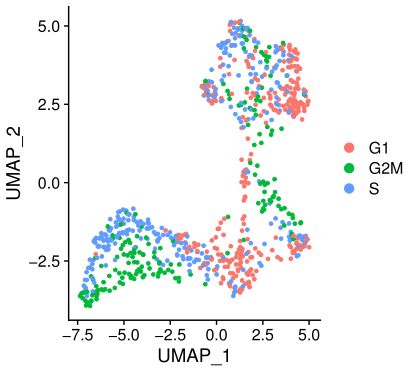
右上角混得还行,左下角这些基本就是细胞周期基因表达谱引起的聚类了,这就是我们要消除的影响
Seurat主要是在数据缩放过程中回归细胞周期分数,用到的仍然是ScaleData()函数,这一步中,对于每个基因,Seurat建模了基因表达值与S、G2M细胞周期分数之间的关系。模型的残差表示一个矫正后的表达矩阵,用于下游降维。
test.seu <- ScaleData(test.seu, vars.to.regress = c("S.Score", "G2M.Score"), features = rownames(test.seu))
#耗时较长之后重新跑标准流程
test.seu <- RunPCA(test.seu, npcs = 50, verbose = FALSE)
test.seu <- FindNeighbors(test.seu, dims = 1:30)
test.seu <- FindClusters(test.seu, resolution = 0.4)
test.seu <- RunUMAP(test.seu, dims = 1:30)
test.seu <- RunTSNE(test.seu, dims = 1:30)
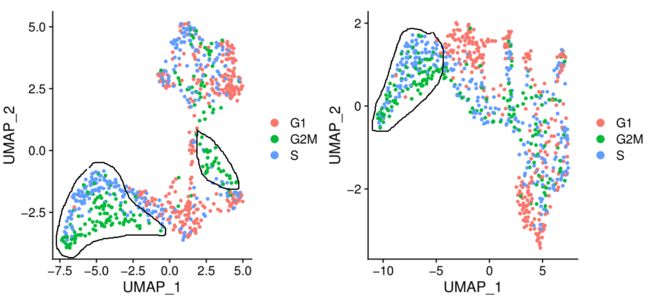
DimPlot(test.seu,reduction = "umap",group.by = "Phase")将新图和之前的图对比可以发现,此时细胞周期对聚类结果的影响已经减少了,不同时间点的细胞混合得更均匀,但也不是100%,没有工具可以保证这个效果
因水平有限,有错误的地方,欢迎批评指正!