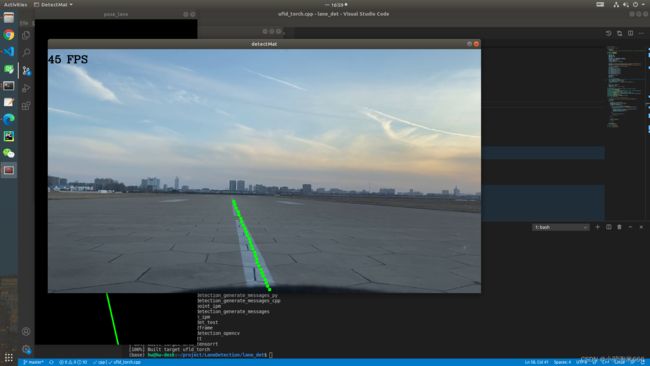
ultra fast lane detection 使用tensorRT加速预测(python+C++版本)
将ufld训练的pytorch模型转换成TRT格式模型使用tensorrt加速运行,目前只完成了使用python版本测试使用,后续会继续探索部署到 nvidia xavier,使用C++完成整个部署流程。
主要参考大神写的工具:https://github.com/KopiSoftware/TRT_Ultra_Fast_Lane_Detect
目录
环境安装
转模型
测试
环境安装
首先需要安装UFLD官方指导中要求的环境以及上边TRT项目中要求的环境,另外需要安装Tensorrt环境。
主要记录安装tensorrt步骤:
- 下载安装包
首先根据自己cuda版本下载安装包:
我的环境对应的tensorrt包(cuda10.2 + cudnn8.2),下载前需要注册nvidia帐号
安装tensorrt时报错缺少pycuda
开始安装(均在conda env 下安装)
- 首先安装pycuda,参看官方指导
注意,我在step 2中是找不到distribute_setup.py这个文件,不过并没有影响安装,并且在step 3中最好指定python版本安装,python3.7 configure.py --cuda-root=/where/ever/you/installed/cuda
- 安装tensorrt
参照这个博客可以成功安装
转模型
转模型参照github项目中的README.mdi
step1 修改配置文件configs/tusimple_4.py,主要是test_model:test_model = 'model.pth'
step2 pytorch模型转onnx
python3 torch2onnx.py configs/tusimple_4.pystep 3 onnx模型转trt模型
python onnx_to_tensorrt.py -p ${mode_in_fp16_or_fp32} --model ${model_name}` 测试
测试模型,不过作者给出的tensorrt_run.py程序是有点问题的,我进行了一下修改,运行后测试以视频数据保存。
python tensorrt_run.py --model ${model_name}# use cmd :python tensorrt_run_video1.py --model model_fp32
from __future__ import print_function
import os
import argparse
import cv2
import tensorrt as trt
import common
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import pycuda.gpuarray as gpuarray
import time
import scipy.special
import torchvision.transforms as transforms
import torch
from PIL import Image
video_path = "path_to_test_video/video_name.mp4"
img_transforms = transforms.Compose([
transforms.Resize((288, 800)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
col_sample = np.linspace(0, 800 - 1, 100)
col_sample_w = col_sample[1] - col_sample[0]
cls_num_per_lane = 56
img_w, img_h = 1280, 720
row_anchor = [ 64, 68, 72, 76, 80, 84, 88, 92, 96, 100, 104, 108, 112,
116, 120, 124, 128, 132, 136, 140, 144, 148, 152, 156, 160, 164,
168, 172, 176, 180, 184, 188, 192, 196, 200, 204, 208, 212, 216,
220, 224, 228, 232, 236, 240, 244, 248, 252, 256, 260, 264, 268,
272, 276, 280, 284]
color = [(255, 255, 0), (255, 0, 0), (0, 0, 255), (0, 255, 0)]
EXPLICIT_BATCH = []
if trt.__version__[0] >= '7':
EXPLICIT_BATCH.append(
1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
def load_engine(trt_file_path, verbose=False):
"""Build a TensorRT engine from a TRT file."""
TRT_LOGGER = trt.Logger(trt.Logger.VERBOSE) if verbose else trt.Logger()
print('Loading TRT file from path {}...'.format(trt_file_path))
with open(trt_file_path, 'rb') as f, trt.Runtime(TRT_LOGGER) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
return engine
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
'-v', '--verbose', action='store_true',
help='enable verbose output (for debugging)')
parser.add_argument(
'-m', '--model', type=str, default='model',
)
args = parser.parse_args()
trt_file_path = '%s.trt' % args.model
if not os.path.isfile(trt_file_path):
raise SystemExit('ERROR: file (%s) not found!' % trt_file_path)
engine_file_path = '%s.trt' % args.model
engine = load_engine(trt_file_path, args.verbose)
h_inputs, h_outputs, bindings, stream = common.allocate_buffers(engine)
cap = cv2.VideoCapture(video_path)
video_write = True
if video_write:
fourcc = cv2.VideoWriter_fourcc(*'MJPG')
time_str = str(int(time.time()))
vout = cv2.VideoWriter('result_' + time_str + '.avi', fourcc, 30.0, (int(cap.get(3)), int(cap.get(4))))
fps = 0.0
with engine.create_execution_context() as context:
while True:
t1 = time.time()
rval, frame = cap.read()
if rval == False :
break
img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
img_ = Image.fromarray(img)
imgs = img_transforms(img_)
trt_input = imgs.numpy()
h_inputs[0].host = trt_input
t3 = time.time()
trt_outputs = common.do_inference_v2(context, bindings=bindings, inputs=h_inputs, outputs=h_outputs,
stream=stream) # 输出结果为一维数组
t4 = time.time()
# print(trt_outputs)
out_j = trt_outputs[0].reshape((101, 56, 4)) # 将一维数组转为 (w+1)* sample_rows * 4 的tensor数据
out_j = out_j[:, ::-1, :]
prob = scipy.special.softmax(out_j[:-1, :, :], axis=0)
idx = np.arange(100) + 1
idx = idx.reshape(-1, 1, 1)
loc = np.sum(prob * idx, axis=0)
out_j = np.argmax(out_j, axis=0)
loc[out_j == 100] = 0
out_j = loc
for i in range(out_j.shape[1]):
if np.sum(out_j[:, i] != 0) > 2:
for k in range(out_j.shape[0]):
if out_j[k, i] > 0:
ppp = (int(out_j[k, i] * col_sample_w * img_w / 800) - 1,
int(img_h * (row_anchor[cls_num_per_lane - 1 - k] / 288)) - 1)
cv2.circle(frame, ppp, 5, (0, 255, 0), -1)
t2 = time.time()
fps = (fps + (1. / (t2 - t1))) / 2
frame = cv2.putText(frame, "fps= %.2f" % (fps), (0, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow('result', frame)
if cv2.waitKey(1) == 27:
break
if video_write:
vout.write(frame)
print('Inference time:', "%.2f" % ((t4 - t3) * 1000))
print('FPS:', "fps= %.2f" % (fps))
vout.release()
if __name__ == '__main__':
main()
使用TensorRT的C++API进行模型预测和结果显示
首先是模型预测部分,在结果整理程序中使用了torch的Tensor数据类型,主要是因为使用tensor整理数据比较简单。
//模型初始化
cudaSetDevice(DEVICE);
char *trtModelStream{nullptr};
size_t size{0};
std::ifstream file("/home/hw/project/LaneDetection/lane_det/src/lane_detection/model/model_fp32.trt", std::ios::in | std::ios::binary);
if (file.good())
{
file.seekg(0, file.end);
size = file.tellg();
file.seekg(0, file.beg);
trtModelStream = new char[size];
assert(trtModelStream);
file.read((char *)trtModelStream, size);
file.close();
}
runtime = createInferRuntime(gLogger);
assert(runtime != nullptr);
engine = runtime->deserializeCudaEngine(trtModelStream, size, nullptr);
assert(engine != nullptr);
context = engine->createExecutionContext();
assert(context != nullptr);
delete[] trtModelStream;
//模型预测部分
const nvinfer1::ICudaEngine &engine = context.getEngine();
assert(engine.getNbBindings() == 2);
void *buffers[2];
// bind the buffers by names of the input and output tensors
const int inputIndex = engine.getBindingIndex(INPUT_BLOB_NAME.c_str());
const int outputIndex = engine.getBindingIndex(OUTPUT_BLOB_NAME.c_str());
// create gpu buffers on device
CUDA_CHECK(cudaMalloc(&buffers[inputIndex], batchsize * 3 * INPUT_H * INPUT_W * sizeof(float)));
CUDA_CHECK(cudaMalloc(&buffers[outputIndex], batchsize * GRID_NUM * CLS_NUM * LANE_NUM * sizeof(float)));
// create stream
cudaStream_t stream;
CUDA_CHECK(cudaStreamCreate(&stream));
CUDA_CHECK(cudaMemcpyAsync(buffers[inputIndex], input, batchsize * 3 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
//auto start1 = std::chrono::system_clock::now();
context.enqueue(batchsize, buffers, stream, nullptr);
//auto end1 = std::chrono::system_clock::now();
//std::cout << std::chrono::duration_cast(end1 - start1).count() << "ms" << std::endl;
CUDA_CHECK(cudaMemcpyAsync(output, buffers[outputIndex], batchsize * GRID_NUM * CLS_NUM * LANE_NUM * sizeof(float), cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
cudaStreamDestroy(stream);
CUDA_CHECK(cudaFree(buffers[inputIndex]));
CUDA_CHECK(cudaFree(buffers[outputIndex]));
//结果整理
torch::Tensor outputTensor = torch::from_blob(out, {101, 56, 4}).to(torch::kCUDA);
outputTensor = outputTensor.squeeze(0); // CUDAHalfType{1,101,56,4} change to CUDAHalfType{101,56,4}
outputTensor = outputTensor.flip(1); // Flip 将行数据倒序
torch::Tensor prob = outputTensor.index({torch::indexing::Slice(torch::indexing::None, -1), torch::indexing::Slice(torch::indexing::None), torch::indexing::Slice(torch::indexing::None)}).softmax(0); // Calculate SoftMax
std::vector idx = arrange(tusimpleGriding_num + 1); // Calculate idx
torch::Tensor c = torch::arange(100) + 1;
auto arrange_idx = torch::reshape(c, {tusimpleGriding_num, 1, 1}).to(torch::kCUDA);
auto mult = prob * arrange_idx;
auto loc = mult.sum(0); //dim=0,对列求和;dim=1,对行求和
outputTensor = outputTensor.argmax(0);
for (int i = 0; i < outputTensor.size(1); i++)
{
for (int j = 0; j < outputTensor.size(0); j++)
{
if (outputTensor[j][i].item() == tusimpleGriding_num)
{
loc[j][i] = 0;
}
}
}
for (int i = 0; i < loc.size(1); i++)
{
for (int k = 0; k < loc.size(0); k++)
{
if (loc[k][i].item() > 0)
{
long widht = int(loc[k][i].item() * double(linSpace * img_w) / 800) - 1;
long height = int(img_h * (double(tusimple_row_anchor[56 - 1 - k]) / 288)) - 1;
cv::circle(frame, cv::Point(widht, height), 5, cv::Scalar(0, 255, 0), -1);
result_point.push_back(cv::Point2i(widht, height));
}
}
}