企业搜索引擎开发之连接器connector(九)
接下来继续分析PusherFactory类 及Pusher类的相关源码实现
先浏览一下相关UML模型图:
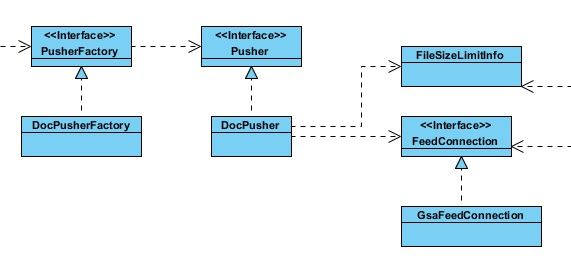
我们从该图可以看到,连接器最终是通过FeedConnection类型对象向应用中心发送xmlfeed数据的
(勘误:企业搜索引擎开发之连接器connector(六)中的UML图 这部分有点出入)
PusherFactory类是Pusher类的工厂类,现在来看PusherFactory源码:
/** * Interface for a factory that creates {@link Pusher} instances for use by a * {@link com.google.enterprise.connector.traversal.Traverser Traverser}. */ public interface PusherFactory { /** * Create a new {@link Pusher} instance appropriate for the supplied * dataSource. * * @param dataSource a data source for a {@code Feed}, typically the name * of a connector instance. * @return a {@link Pusher} * @throws PushException if no {@link Pusher} is assigned to the * {@code dataSource}. */ public Pusher newPusher(String dataSource) throws PushException; }
该接口就是生产Pusher类型对象,实现类DocPusherFactory如下:
/** * Factory that creates {@link DocPusher} instances that feed * {@link FeedConnection}. */ // TODO: Support multiple sinks where different connector instances // might feed different sinks. public class DocPusherFactory implements PusherFactory { /** * FeedConnection that is the sink for our generated XmlFeeds. */ private final FeedConnection feedConnection; /** * Configured maximum document size and maximum feed file size supported. */ private final FileSizeLimitInfo fileSizeLimit; /** * Creates a {@code DocPusherFactory} object from the specified * {@code feedConnection}. * * @param feedConnection a FeedConnection */ public DocPusherFactory(FeedConnection feedConnection) { this(feedConnection, new FileSizeLimitInfo()); } /** * Creates a {@code DocPusherFactory} object from the specified * {@code feedConnection}. The supplied {@link FileSizeLimitInfo} specifies * constraints as to the size of a Document's content and the size of * generated Feed files. * * @param feedConnection a {@link FeedConnection} sink for documents. * @param fileSizeLimit {@link FileSizeLimitInfo} constraints on document * content and feed size. */ public DocPusherFactory(FeedConnection feedConnection, FileSizeLimitInfo fileSizeLimit) { this.feedConnection = feedConnection; this.fileSizeLimit = fileSizeLimit; } //@Override public Pusher newPusher(String dataSource) { return new DocPusher(feedConnection, dataSource, fileSizeLimit); } }
Pusher接口方法如下:
/** * Interface for a Pusher - something that takes spi Documents * and sends them along on their way. */ public interface Pusher { /** * Takes an spi Document and pushes it along, presumably to the GSA Feed. * * @param document A Document * @return true if Pusher may accept more documents, false otherwise. * @throws RepositoryException if transient error accessing the Repository * @throws RepositoryDocumentException if fatal error accessing the Document * @throws FeedException if a transient Feed error occurs in the Pusher * @throws PushException if a transient error occurs in the Pusher */ public boolean take(Document document) throws PushException, FeedException, RepositoryException; /** * Finishes processing a document feed. If the caller anticipates no * further calls to {@link #take(Document)} will be made, * this method should be called, so that the Pusher may send a cached, * accumulated Feed to the feed processor. * * @throws RepositoryException if transient error accessing the Repository * @throws RepositoryDocumentException if fatal error accessing the Document * @throws FeedException if a transient Feed error occurs in the Pusher * @throws PushException if a transient error occurs in the Pusher */ public void flush() throws PushException, FeedException, RepositoryException; /** * Cancels a feed. Discard any accumulated feed data. */ public void cancel(); }
实现类DocPusher源码如下:
/** * Class to generate xml feed for a document from the Document and send it * to GSA. */ public class DocPusher implements Pusher { private static final Logger LOGGER = Logger.getLogger(DocPusher.class.getName()); private static final byte[] SPACE_CHAR = { 0x20 }; // UTF-8 space /** * Separate Logger for Feed Logging. */ private static final Logger FEED_WRAPPER_LOGGER = Logger.getLogger(LOGGER.getName() + ".FEED_WRAPPER"); private static final Logger FEED_LOGGER = Logger.getLogger(FEED_WRAPPER_LOGGER.getName() + ".FEED"); private static final Level FEED_LOG_LEVEL = Level.FINER; /** * Configured maximum document size and maximum feed file size supported. */ private final FileSizeLimitInfo fileSizeLimit; /** * FeedConnection that is the sink for our generated XmlFeeds. */ private final FeedConnection feedConnection; /** * Encoding method to use for Document content. */ private String contentEncoding; /** * The Connector name that is the dataSource for this Feed. */ private final String connectorName; /** * ExcecutorService that submits a Feed to the GSA in a separate thread. * This allows us to overlap I/O reading content from the Repository * in the traversal thread, and submitting content to the GSA in * a submitFeed thread. */ private final ExecutorService feedSender; /** * This is the list of outstanding asynchronous feed submissions. */ private final LinkedList<FutureTask<String>> submissions; /** * This is used to build up a multi-record feed. Documents are added to the * feed until the size of the feed exceeds the FileSizeLimitInfo.maxFeedSize * or we are finished with the batch of documents. The feed is then * submitted to the feed connection. */ private XmlFeed xmlFeed = null; /** * This field is used to construct a feed record in parallel to the main feed * InputStream construction. It is only used if the feed logging level is set * to the appropriate level. It only exists during the time the main feed is * being constructed. Once sufficient information has been appended to this * buffer its contents will be logged and it will be nulled. */ private StringBuilder feedLog = null; // For use by unit tests. private String gsaResponse; /** * Creates a {@code DocPusher} object from the specified * {@code feedConnection} and {@code connectorName}. The supplied * {@link FileSizeLimitInfo} specifies constraints as to the size of a * Document's content and the size of generated Feed files. * * @param feedConnection a FeedConnection * @param connectorName The connector name that is the source of the feed * @param fileSizeLimitInfo FileSizeLimitInfo constraints on document content * and feed size. */ public DocPusher(FeedConnection feedConnection, String connectorName, FileSizeLimitInfo fileSizeLimitInfo) { this.feedConnection = feedConnection; this.connectorName = connectorName; this.fileSizeLimit = fileSizeLimitInfo; // Check to see if the GSA supports compressed content feeds. String supportedEncodings = feedConnection.getContentEncodings().toLowerCase(); this.contentEncoding = (supportedEncodings.indexOf(XmlFeed.XML_BASE64COMPRESSED) >= 0) ? XmlFeed.XML_BASE64COMPRESSED : XmlFeed.XML_BASE64BINARY; // Initialize background feed submission. this.submissions = new LinkedList<FutureTask<String>>(); this.feedSender = Executors.newSingleThreadExecutor(); } /** * Return the Feed Logger. */ public static Logger getFeedLogger() { return FEED_WRAPPER_LOGGER; } /** * Gets the response from GSA when the feed is sent. For testing only. * * @return gsaResponse response from GSA. */ protected String getGsaResponse() { return gsaResponse; } /** * Takes a Document and sends a the feed to the GSA. * * @param document Document corresponding to the document. * @return true if Pusher should accept more documents, false otherwise. * @throws PushException if Pusher problem * @throws FeedException if transient Feed problem * @throws RepositoryDocumentException if fatal Document problem * @throws RepositoryException if transient Repository problem */ public boolean take(Document document) throws PushException, FeedException, RepositoryException { if (feedSender.isShutdown()) { throw new IllegalStateException("Pusher is shut down"); } checkSubmissions(); String feedType; try { feedType = DocUtils.getFeedType(document); } catch (RuntimeException e) { LOGGER.log(Level.WARNING, "Rethrowing RuntimeException as RepositoryDocumentException", e); throw new RepositoryDocumentException(e); } // All feeds in a feed file must be of the same type. // If the feed would change type, send the feed off to the GSA // and start a new one. if ((xmlFeed != null) && (feedType != xmlFeed.getFeedType())) { if (LOGGER.isLoggable(Level.FINE)) { LOGGER.fine("A new feedType, " + feedType + ", requires a new feed for " + connectorName + ". Closing feed and sending to GSA."); } submitFeed(); } if (xmlFeed == null) { if (LOGGER.isLoggable(Level.FINE)) { LOGGER.fine("Creating new " + feedType + " feed for " + connectorName); } try { startNewFeed(feedType); } catch (OutOfMemoryError me) { throw new PushException("Unable to allocate feed buffer. Try reducing" + " the maxFeedSize setting, reducing the number of connector" + " intances, or adjusting the JVM heap size parameters.", me); } } boolean isThrowing = false; int resetPoint = xmlFeed.size(); InputStream contentStream = null; try { // Add this document to the feed. contentStream = getContentStream(document, feedType); xmlFeed.addRecord(document, contentStream, contentEncoding); if (LOGGER.isLoggable(Level.FINER)) { LOGGER.finer("Document " + DocUtils.getRequiredString(document, SpiConstants.PROPNAME_DOCID) + " from connector " + connectorName + " added to feed."); } // If the feed is full, send it off to the GSA. if (xmlFeed.isFull() || lowMemory()) { if (LOGGER.isLoggable(Level.FINE)) { LOGGER.fine("Feed for " + connectorName + " has grown to " + xmlFeed.size() + " bytes. Closing feed and sending to GSA."); } submitFeed(); // If we are running low on memory, don't start another feed - // tell the Traverser to finish this batch. if (lowMemory()) { return false; } // If the number of feeds waiting to be sent has backed up, // tell the Traverser to finish this batch. if ((checkSubmissions() > 10) || feedConnection.isBacklogged()) { return false; } } // Indicate that this Pusher may accept more documents. return true; } catch (OutOfMemoryError me) { xmlFeed.reset(resetPoint); throw new PushException("Out of memory building feed, retrying.", me); } catch (RuntimeException e) { xmlFeed.reset(resetPoint); LOGGER.log(Level.WARNING, "Rethrowing RuntimeException as RepositoryDocumentException", e); throw new RepositoryDocumentException(e); } catch (RepositoryDocumentException rde) { // Skipping this document, remove it from the feed. xmlFeed.reset(resetPoint); throw rde; } catch (IOException ioe) { LOGGER.log(Level.SEVERE, "IOException while reading: skipping", ioe); xmlFeed.reset(resetPoint); Throwable t = ioe.getCause(); isThrowing = true; if (t != null && (t instanceof RepositoryException)) { throw (RepositoryException) t; } else { throw new RepositoryDocumentException("I/O error reading data", ioe); } } finally { if (contentStream != null) { try { contentStream.close(); } catch (IOException e) { if (!isThrowing) { LOGGER.log(Level.WARNING, "Rethrowing IOException as PushException", e); throw new PushException("IOException: " + e.getMessage(), e); } } } } } /** * Finish a feed. No more documents are anticipated. * If there is an outstanding feed file, submit it to the GSA. * * @throws PushException if Pusher problem * @throws FeedException if transient Feed problem * @throws RepositoryException */ public void flush() throws PushException, FeedException, RepositoryException { LOGGER.fine("Flushing accumulated feed to GSA"); checkSubmissions(); if (!feedSender.isShutdown()) { submitFeed(); feedSender.shutdown(); } while (!feedSender.isTerminated()) { try { feedSender.awaitTermination(10, TimeUnit.SECONDS); } catch (InterruptedException ie) { if (checkSubmissions() > 0) { throw new FeedException("Interrupted while waiting for feeds."); } } } checkSubmissions(); } /** * Cancels any feed being constructed. Any accumulated feed data is lost. */ public void cancel() { // Discard any feed under construction. if (xmlFeed != null) { LOGGER.fine("Discarding accumulated feed for " + connectorName); xmlFeed = null; } if (feedLog != null) { feedLog = null; } // Cancel any feeds under asynchronous submission. feedSender.shutdownNow(); } /** * Checks on asynchronously submitted feeds to see if they completed * or failed. If any of the submissions failed, throw an Exception. * * @return number if items remaining in the submissions list */ private int checkSubmissions() throws PushException, FeedException, RepositoryException { int count = 0; // Count of outstanding items in the list. synchronized(submissions) { ListIterator<FutureTask<String>> iter = submissions.listIterator(); while (iter.hasNext()) { FutureTask<String> future = iter.next(); if (future.isDone()) { iter.remove(); try { gsaResponse = future.get(); } catch (InterruptedException ie) { // Shouldn't happen if isDone. } catch (ExecutionException ee) { Throwable cause = ee.getCause(); if (cause == null) { cause = ee; } if (cause instanceof PushException) { throw (PushException) cause; } else if (cause instanceof FeedException) { throw (FeedException) cause; } else if (cause instanceof RepositoryException) { throw (RepositoryException) cause; } else { throw new FeedException("Error submitting feed", cause); } } } else { count++; } } } return count; } /** * Checks for low available memory condition. * * @return true if free memory is running low. */ private boolean lowMemory() { long threshold = ((fileSizeLimit.maxFeedSize() + fileSizeLimit.maxDocumentSize()) * 4) / 3; Runtime rt = Runtime.getRuntime(); if ((rt.maxMemory() - (rt.totalMemory() - rt.freeMemory())) < threshold) { rt.gc(); if ((rt.maxMemory() - (rt.totalMemory() - rt.freeMemory())) < threshold) { return true; } } return false; } /** * Allocates initial memory for a new XmlFeed and feed logger. * * @param feedType */ private void startNewFeed(String feedType) throws PushException { // Allocate a buffer to construct the feed log. try { if (FEED_LOGGER.isLoggable(FEED_LOG_LEVEL) && feedLog == null) { feedLog = new StringBuilder(256 * 1024); feedLog.append("Records generated for ").append(feedType); feedLog.append(" feed of ").append(connectorName).append(":\n"); } } catch (OutOfMemoryError me) { throw new OutOfMemoryError( "Unable to allocate feed log buffer for connector " + connectorName); } // Allocate XmlFeed of the target size. int feedSize = (int) fileSizeLimit.maxFeedSize(); try { try { xmlFeed = new XmlFeed(connectorName, feedType, feedSize, feedLog); } catch (OutOfMemoryError me) { // We shouldn't even have gotten this far under a low memory condition. // However, try to allocate a tiny feed buffer. It should fill up on // the first document, forcing it to be submitted. DocPusher.take() // should then return a signal to the caller to terminate the batch. LOGGER.warning("Insufficient memory available to allocate an optimally" + " sized feed - retrying with a much smaller feed allocation."); feedSize = 1024; try { xmlFeed = new XmlFeed(connectorName, feedType, feedSize, feedLog); } catch (OutOfMemoryError oome) { throw new OutOfMemoryError( "Unable to allocate feed buffer for connector " + connectorName); } } } catch (IOException ioe) { throw new PushException("Error creating feed", ioe); } LOGGER.fine("Allocated a new feed of size " + feedSize); return; } /** * Takes the accumulated XmlFeed and sends the feed to the GSA. * * @throws PushException if Pusher problem * @throws FeedException if transient Feed problem * @throws RepositoryException */ private void submitFeed() throws PushException, FeedException, RepositoryException { if (xmlFeed == null) { return; } final XmlFeed feed = xmlFeed; xmlFeed = null; final String logMessage; if (feedLog != null) { logMessage = feedLog.toString(); feedLog = null; } else { logMessage = null; } try { feed.close(); } catch (IOException ioe) { throw new PushException("Error closing feed", ioe); } try { // Send the feed to the GSA in a separate thread. FutureTask<String> future = new FutureTask<String> ( new Callable<String>() { public String call() throws PushException, FeedException, RepositoryException { try { NDC.push("Feed " + feed.getDataSource()); return submitFeed(feed, logMessage); } finally { NDC.remove(); } } } ); feedSender.execute(future); // Add the future to list of outstanding submissions. synchronized(submissions) { submissions.add(future); } } catch (RejectedExecutionException ree) { throw new FeedException("Asynchronous feed was rejected. ", ree); } } /** * Takes the supplied XmlFeed and sends that feed to the GSA. * * @param feed an XmlFeed * @param logMessage a Feed Log message * @return response String from GSA * @throws PushException if Pusher problem * @throws FeedException if transient Feed problem * @throws RepositoryException */ private String submitFeed(XmlFeed feed, String logMessage) throws PushException, FeedException, RepositoryException { if (LOGGER.isLoggable(Level.FINE)) { LOGGER.fine("Submitting " + feed.getFeedType() + " feed for " + feed.getDataSource() + " to the GSA. " + feed.getRecordCount() + " records totaling " + feed.size() + " bytes."); } // Write the generated feedLog message to the feed logger. if (logMessage != null && FEED_LOGGER.isLoggable(FEED_LOG_LEVEL)) { FEED_LOGGER.log(FEED_LOG_LEVEL, logMessage); } // Write the Feed to the TeedFeedFile, if one was specified. String teedFeedFilename = Context.getInstance().getTeedFeedFile(); if (teedFeedFilename != null) { boolean isThrowing = false; OutputStream os = null; try { os = new FileOutputStream(teedFeedFilename, true); feed.writeTo(os); } catch (IOException e) { isThrowing = true; throw new FeedException("Cannot write to file: " + teedFeedFilename, e); } finally { if (os != null) { try { os.close(); } catch (IOException e) { if (!isThrowing) { throw new FeedException( "Cannot write to file: " + teedFeedFilename, e); } } } } } String gsaResponse = feedConnection.sendData(feed); if (!gsaResponse.equals(GsaFeedConnection.SUCCESS_RESPONSE)) { String eMessage = gsaResponse; if (GsaFeedConnection.UNAUTHORIZED_RESPONSE.equals(gsaResponse)) { eMessage += ": Client is not authorized to send feeds. Make " + "sure the GSA is configured to trust feeds from your host."; } if (GsaFeedConnection.INTERNAL_ERROR_RESPONSE.equals(gsaResponse)) { eMessage += ": Check GSA status or feed format."; } throw new PushException(eMessage); } return gsaResponse; } /** * Return an InputStream for the Document's content. */ private InputStream getContentStream(Document document, String feedType) throws RepositoryException { InputStream contentStream = null; if (!feedType.equals(XmlFeed.XML_FEED_METADATA_AND_URL)) { InputStream encodedContentStream = getEncodedStream( new BigEmptyDocumentFilterInputStream( DocUtils.getOptionalStream(document, SpiConstants.PROPNAME_CONTENT), fileSizeLimit.maxDocumentSize()), (Context.getInstance().getTeedFeedFile() != null), 1024 * 1024); InputStream encodedAlternateStream = getEncodedStream(getAlternateContent( DocUtils.getOptionalString(document, SpiConstants.PROPNAME_TITLE)), false, 1024); contentStream = new AlternateContentFilterInputStream( encodedContentStream, encodedAlternateStream, xmlFeed); } return contentStream; } /** * Wrap the content stream with the suitable encoding (either * Base64 or Base64Compressed, based upon GSA encoding support. */ // TODO: Don't compress tiny content or already compressed data // (based on mimetype). This is harder than it sounds. private InputStream getEncodedStream(InputStream content, boolean wrapLines, int ioBufferSize) { if (XmlFeed.XML_BASE64COMPRESSED.equals(contentEncoding)) { return new Base64FilterInputStream( new CompressedFilterInputStream(content, ioBufferSize), wrapLines); } else { return new Base64FilterInputStream(content, wrapLines); } } /** * Construct the alternate content data for a feed item. If the feed item * has null or empty content, or if the feed item has excessively large * content, substitute this data which will insure that the feed item gets * indexed by the GSA. The alternate content consists of the item's title, * or a single space, if it lacks a title. * * @param title from the feed item * @return an InputStream containing the alternate content */ private static InputStream getAlternateContent(String title) { byte[] bytes = null; // Alternate content is a string that is substituted for null or empty // content streams, in order to make sure the GSA indexes the feed item. // If the feed item supplied a title property, we build an HTML fragment // containing that title. This provides better looking search result // entries. if (title != null && title.trim().length() > 0) { try { String t = "<html><title>" + title.trim() + "</title></html>"; bytes = t.getBytes("UTF-8"); } catch (UnsupportedEncodingException uee) { // Don't be fancy. Try the single space content. } } // If no title is available, we supply a single space as the content. if (bytes == null) { bytes = SPACE_CHAR; } return new ByteArrayInputStream(bytes); } /** * A FilterInput stream that protects against large documents and empty * documents. If we have read more than FileSizeLimitInfo.maxDocumentSize * bytes from the input, we reset the feed to before we started reading * content, then provide the alternate content. Similarly, if we get EOF * after reading zero bytes, we provide the alternate content. */ private static class AlternateContentFilterInputStream extends FilterInputStream { private boolean useAlternate; private InputStream alternate; private final XmlFeed feed; private int resetPoint; /** * @param in InputStream containing raw document content * @param alternate InputStream containing alternate content to provide * @param feed XmlFeed under constructions (used for reseting size) */ public AlternateContentFilterInputStream(InputStream in, InputStream alternate, XmlFeed feed) { super(in); this.useAlternate = false; this.alternate = alternate; this.feed = feed; this.resetPoint = -1; } // Reset the feed to its position when we started reading this stream, // and start reading from the alternate input. // TODO: WARNING: this will not work if using chunked HTTP transfer. private void switchToAlternate() { feed.reset(resetPoint); useAlternate = true; } @Override public int read() throws IOException { if (resetPoint == -1) { // If I have read nothing yet, remember the reset point in the feed. resetPoint = feed.size(); } if (!useAlternate) { try { return super.read(); } catch (EmptyDocumentException e) { switchToAlternate(); } catch (BigDocumentException e) { LOGGER.finer("Document content exceeds the maximum configured " + "document size, discarding content."); switchToAlternate(); } } return alternate.read(); } @Override public int read(byte b[], int off, int len) throws IOException { if (resetPoint == -1) { // If I have read nothing yet, remember the reset point in the feed. resetPoint = feed.size(); } if (!useAlternate) { try { return super.read(b, off, len); } catch (EmptyDocumentException e) { switchToAlternate(); return 0; // Return alternate content on subsequent call to read(). } catch (BigDocumentException e) { LOGGER.finer("Document content exceeds the maximum configured " + "document size, discarding content."); switchToAlternate(); return 0; // Return alternate content on subsequent call to read(). } } return alternate.read(b, off, len); } @Override public boolean markSupported() { return false; } @Override public void close() throws IOException { super.close(); alternate.close(); } } /** * A FilterInput stream that protects against large documents and empty * documents. If we have read more than FileSizeLimitInfo.maxDocumentSize * bytes from the input, or if we get EOF after reading zero bytes, * we throw a subclass of IOException that is used as a signal for * AlternateContentFilterInputStream to switch to alternate content. */ private static class BigEmptyDocumentFilterInputStream extends FilterInputStream { private final long maxDocumentSize; private long currentDocumentSize; /** * @param in InputStream containing raw document content * @param maxDocumentSize maximum allowed size in bytes of data read from in */ public BigEmptyDocumentFilterInputStream(InputStream in, long maxDocumentSize) { super(in); this.maxDocumentSize = maxDocumentSize; this.currentDocumentSize = 0; } @Override public int read() throws IOException { if (in == null) { throw new EmptyDocumentException(); } int val = super.read(); if (val == -1) { if (currentDocumentSize == 0) { throw new EmptyDocumentException(); } } else if (++currentDocumentSize > maxDocumentSize) { throw new BigDocumentException(); } return val; } @Override public int read(byte b[], int off, int len) throws IOException { if (in == null) { throw new EmptyDocumentException(); } int bytesRead = super.read(b, off, (int) Math.min(len, maxDocumentSize - currentDocumentSize + 1)); if (bytesRead == -1) { if (currentDocumentSize == 0) { throw new EmptyDocumentException(); } } else if ((currentDocumentSize += bytesRead) > maxDocumentSize) { throw new BigDocumentException(); } return bytesRead; } @Override public boolean markSupported() { return false; } @Override public void close() throws IOException { if (in != null) { super.close(); } } } /** * Subclass of IOException that is thrown when maximumDocumentSize * is exceeded. */ private static class BigDocumentException extends IOException { public BigDocumentException() { super("Maximum Document size exceeded."); } } /** * Subclass of IOException that is thrown when the document has * no content. */ private static class EmptyDocumentException extends IOException { public EmptyDocumentException() { super("Document has no content."); } } }
这个类的代码是有点长的,take方法首先是将Document转化为InputStream流然后封装到XmlFeed数据载体里面
然后以线程池方式提交XmlFeed数据(调用feedConnection.sendData(feed)方法)
我么可以发现提交xmlfeed数据前,如果我们在属性文件applicationContext.properties配置了teedFeedFile属性,连接器会同时将发送的xml数据写入该属性值的文件
---------------------------------------------------------------------------
本系列企业搜索引擎开发之连接器connector系本人原创
转载请注明出处 博客园 刺猬的温驯
本文链接http://www.cnblogs.com/chenying99/archive/2013/03/19/2968423.html