第九章 聚类
9.1 聚类任务
在无监督学习中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律。为进一步的数据分析提供基础。此类学习任务中研究最多、应用最广的是“聚类”。
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个簇。通过这样的划分,每个簇可能对应于一些潜在的概念。这些概念对聚类算法而。言事先是未知的,聚类过程仅能自动形成簇结构,簇所对应的概念语义需由使用者来把握和命名。
9.2 性能度量
聚类性能度量亦称聚类“有效性指标”,聚类是将样本集D划分为若干互不相交的子集,即样本簇。直观上,我们希望物以类聚,即同一簇的样本尽可能彼此相似,不同簇的样本尽可能不同。换言之,聚类结果的簇内相似度高且簇间相似度低。
聚类性能度量大致有两类,一类是将聚类结果与某个参考模型进行比较,称为外部指标;另一类是直接考察聚类结果而不利用任何参考模型,称为内部指标。

1、Jaccard系数(Jaccard Coefficient,简称JC)

2、FM指数(Fowlkes and Mallows Index,简称FMI)
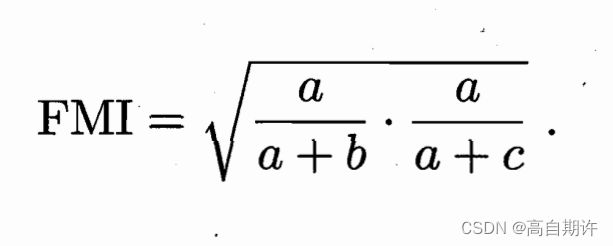
3、Rand指数(Rand Index,简称RI)

显然上述性能度量的结果值均在[0,1]区间,值越大越好。

4、DB指数(Davies-Bouldin Index,简称DBI)
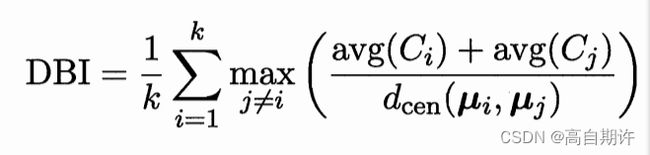
5、Dunn指数(Dunn Index,简称DI)
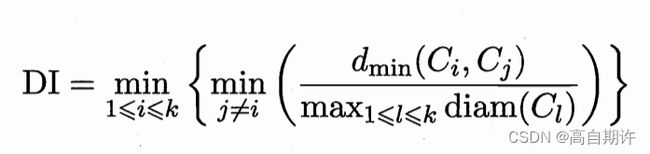
显然,DBI的值越小越好,而DI则相反,值越大越好。
9.3 距离计算
对函数dist(.,.),若它是一个距离度量,则需满足一些基本性质:
非负性:dist(xi,xj) >= 0;
同一性:dist(xi,xj) = 0当且仅当xi = xj;
对称性:dist(xi,xj) = dist(xj,xi)
直递性:dist(xi,xj) <= dist(xi,xk) + dist(xk, xj)
给定样本xi = (xi1; xi2; …; xin)与xj = (xj1; xj2; …; xjn), 最常用的是闵可夫斯基距离:

当p>=1,上式显然满足上面四个性质的距离度量基本性质。
p = 2时,闵可夫斯基距离即欧式距离:
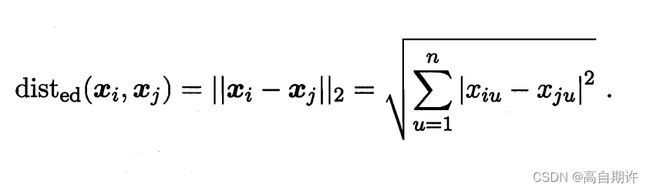
p = 1时,闵可夫斯基距离即曼哈顿距离:
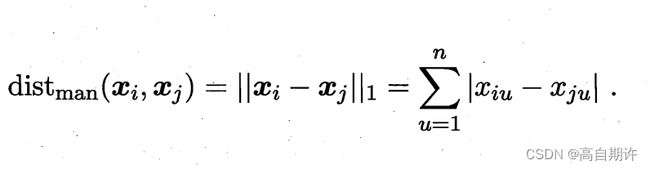
我们常将属性划分为连续属性和离散属性,前者在定义域上有无穷多个可能的取值,后者在定义域上是有限个取值。
然而,在讨论距离计算时,属性上是否定义了序关系更为重要。例如定义域为{1,2,3}的离散属性与连续属性的性质更接近一些,能直接在属性值上计算距离:“1” 与 “2”比较接近、与“3”比较远,这样的属性称为有序属性,而定义域为{飞机,火车,轮船}这样的离散属性则不能在属性值上计算距离,称为无序属性。显然,闵可夫斯基距离可用于有序属性。
对无序距离可采用VDM:

于是,将闵可夫斯基距离和VDM结合即可处理混合属性。假定有Nc个有序属性、N - Nc个无序属性,不失一般性,令有序属性排列在无序属性之前,则:

当样本空间中不同属性的重要性不同时,可使用加权距离,以加权闵可夫斯基距离为例。

9.4 原型聚类
原型聚类亦称”基于原型的聚类“,此类算法假设聚类结构能通过一组原型刻画,在现实聚类任务中极为常用。
9.4.1 k均值算法

最小化上式并不容易,找到它的最优解需考察样本集D所有可能的簇划分,这是一个NP难问题。因此,k均值算法采用了贪心策略,通过迭代优化来近似求解式,算法流程如下:

9.4.2 学习向量量化
与K均值算法类似,学习向量量化(Learning Vector Quantization,简称LVQ)也是试图找到一组原型向量来刻画聚类结构,但与一般聚类算法不同的是,LVQ假设数据样本带有类别标记。学习过程利用样本的这些监督信息来辅助聚类。
给定样本集D={(x1,y1),(x2,y2),…,(xm, ym)}, 每个样本xj是由n个属性描述的特征向量(xj1;xj2;…;xjn),yj∈Y是样本xj的类别标记。LVQ的目标是学得一组n维原型向量{p1,p2,…,pq},每个原型向量代表一个聚类簇,簇标记ti∈Y。LVQ算法如下所示:

9.4.3 高斯混合聚类
与k均值、LVQ用原型向量来刻画聚类结构不同,高斯聚类采用概率模型来表达聚类原型。
高斯分布的定义:对n维样本空间X中的随机向量x,若x服从高斯分布,其概率密度函数为:
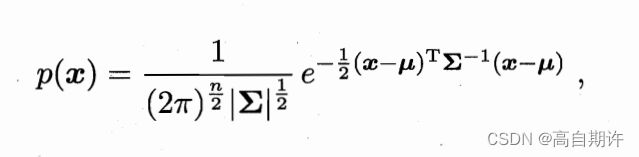
其中μ是n维均值向量,是∑是nxn的协方差矩阵。由上式可看出,高斯分布完全由均值向量μ和协方差矩阵∑这两个参数确定。将概率密度函数记为p(x|μ,∑)。

假设样本的生成过程由高斯混合分布给出:首先根据a1, a2, …, ak定义的先验分布选择高斯混合成分,其中ai为选择第i个混合成分的概率;然后,根据被选择的混合成分的概率密度函数进行采样,从而生成相应的样本。下面给出高斯混合聚类算法:

9.5 密度聚类
密度聚类亦称“基于密度的聚类”,此类算法假设聚类结构能通过样本分布的紧密程度确定。通常情形下,密度聚类算法从样本密度的角度来考察样本之间的可连续性,并基于可连续样本不断扩展聚类簇以获得最终的聚类结果。
DBSCAN是一种著名的密度聚类算法,它基于一组领域参数来刻画样本分布的紧密程度。给定数据集D={x1,x2,…,xm},定义下面这几个概念:




下图给出DBSCAN算法流程:

9.6 层次聚类
层次聚类试图在不同层次对数据集进行划分,从而形成树形地聚类结构。数据集地划分可采用自底向上地聚合策略,也可采用自顶向下地分拆策略。
AGNES是一种采用自底向上聚合策略的层次聚类算法。AGNES算法描述如图所示
