Pytorch 创建Dataset类,加载我们自己的数据集及优化
为什么要学习加载自己的数据集
Pytorch自带有许多数据集,他们的格式都已经指定,如:
MNIST
COCO(用于图像标注和目标检测)(Captioning and Detection)
LSUN Classification
ImageFolder
Imagenet-12
CIFAR10 and CIFAR100
STL10
这些都是可以供我们初学者学习使用的训练集,在使用过程中我们一般通过函数调用的方式,将数据集拿到,如下:
def get_data_loader(BATCH_SIZE=128,train=True):
transform_fn=Compose([
ToTensor(),
Normalize(mean=(0.1307,),std=(0.3081,))
])
dataset=MNIST(root="./data",train=train,transform=transform_fn)
data_loader=DataLoader(dataset,batch_size=BATCH_SIZE,shuffle=True)
return data_loader
在这里,我们可以把这个得到的dataset看作是一个list,那么很显然DataLoader这个方法就是对list进行的一个指定转化。
(不是list,但是可以看作list)
这些数据集相对工整,且都是别人整理好的,如果我们要自己训练数据,设计模型呢?该怎么导入加载我们自己的数据,向上面一样,那肯定是不行的!那我们怎么加载呢,Pytorch提供了Dataset类。
怎么加载我们的数据集
下面,我们去翻翻Pytorch的源代码,发现了:Pytorch自定义Dataset的相关用法:
第一种:Dataset class
torch.utils.data.Dataset是一个抽象类,用户想要加载自定义的数据只需要继承这个类,并且覆写其中的两个方法即可:
1. __len__ :实现len(dataset)返回整个数据集的大小。
2. __getitem__用来获取一些索引的数据,使dataset[i]返回数据集中第i个样本。
3. 不覆写这两个方法会直接返回错误。
即写法如下:
写法一
#导入相关模块
from torch.utils.data import DataLoader,Dataset
from PIL import Image
import os
import torch
from torchvision import transforms
import numpy as np
class Pic_Data(Dataset): #继承Dataset
def __init__(self, root_dir, transform=None): #__init__是初始化该类的一些基础参数
self.root_dir = root_dir #文件目录
self.transform = transform #变换
self.images = os.listdir(self.root_dir)#目录里的所有文件
def __len__(self):#返回整个数据集的大小
return len(self.images)
def __getitem__(self,index):#根据索引index返回dataset[index]
image_index = self.images[index]#根据索引index获取该图片
img_path = os.path.join(self.root_dir, image_index)#获取索引为index的图片的路径名
img = Image.open(img_path)# 读取该图片
label = int(image_index[-5])# 根据该图片的路径名获取该图片的label,具体根据路径名进行分割。我这里是"E:\\Python Project\\Pytorch\\dogs-vs-cats\\train\\cat.0.jpg",所以先用"\\"分割,选取最后一个为['cat.0.jpg'],然后使用"."分割,选取[cat]作为该图片的标签
# sample = (img,label)#根据图片和标签创建字典
if self.transform:
sample = self.transform(img)#对样本进行变换
return sample,label#返回该样本
总体思路是继承Dataset这个类,然后重写相关方法,这种写法的一个优势在于不直接读取全部数据,减小了内存等资源的消耗,可以在***getitem*** 这里看到,没有直接将所有数据读取到,这里运用了类生成器的方法,通过DataLoader读取,坏处是比较耗费时间,后面会详解。
写法二
class Pic_Data(Dataset): #继承Dataset
def __init__(self, root_dir, transform=None): #__init__是初始化该类的一些基础参数
self.root_dir = root_dir #文件目录
self.transform = transform #变换
self.data=self.load_img()
def load_img(self):
imgs=os.listdir(self.root_dir)#目录里的所有文件
data_list=[]
for im in imgs:
img_path = os.path.join(self.root_dir, im)#获取索引为index的图片的路径名
img = Image.open(img_path)# 读取该图片
img_arr=np.array(img,dtype=np.float32)/255
# img = Image.open(img_path)# 读取该图片
label = int(im[-5])# 根据该图片的路径名获取该图片的label,具体根据路径名进行分割。我这里是"E:\\Python Project\\Pytorch\\dogs-vs-cats\\train\\cat.0.jpg",所以先用"\\"分割,选取最后一个为['cat.0.jpg'],然后使用"."分割,选取[cat]作为该图片的标签
data_list.append((img_arr,label))
return data_list
def __len__(self):#返回整个数据集的大小
return len(self.data)
def __getitem__(self,index):#根据索引index返回dataset[index]
image_info,img_label = self.data[index]#根据索引index获取该图片
if self.transform:
sample = self.transform(image_info)#对样本进行变换
return image_info,img_label#返回该样本
在load_img方法中,将所有的图片数据都获取到了。
第二种:torchvision
写法:
from torchvision import transforms,utils
from torchvision import datasets
import torch
import matplotlib.pyplot as plt
import torch.utils.data
train_data = datasets.ImageFolder(r'E:\Python Project\PyTorch\data\hotdog\train',transform=transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
]))
print(train_data.classes)#获取标签
train_loader = torch.utils.data.DataLoader(train_data,batch_size=4,shuffle=True)
print(len(train_loader))
for i_batch, img in enumerate(train_loader):
if i_batch == 0:
print(img[1]) #标签转化为编码
fig = plt.figure()
grid = utils.make_grid(img[0])
plt.imshow(grid.numpy().transpose((1, 2, 0)))
plt.show()
break
这里由于本人没用过这个方法,参考的 链接,本人这篇文章开始也参考的他的。
选择加载数据集的方式
在这里,我推荐使用Dataset class这种方法,尤其是其中的第二种方法,这是一个用空间换取时间的好手段,具体如下。
- 将MNIST的图片数据集加载,训练,为了模拟我们真实的加载方式,我们需要将数据转换成图片,代码如下
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from PIL import Image
dataset=MNIST(root="./data",train=False)
for idx,(x,target) in enumerate(dataset):
img=x
fileName = "./data/MNIST/test/"+ str(idx) + "_" + str(target) + ".jpg"
img.save(fileName)
- 这样我们的图片数据都已图片保存在本地了,那我们怎么导入数据呢,上面已经讲解了两种方式,下面我们来看两种方式对全部数据进行10次训练所需要的时间吧,除了图片数据的加载方式不一样,其余代码完全一致。
- 代码一:
#导入相关模块
from torch.utils.data import Dataset,DataLoader
from torchvision.transforms import Compose,ToTensor,Normalize
from torch import optim
from PIL import Image
from torch import nn
import torch.nn.functional as F
import numpy as np
import torch
import time
import os
t1=time.time()
BATCH_SIZE=128
class Pic_Data(Dataset): #继承Dataset
def __init__(self, root_dir, transform=None): #__init__是初始化该类的一些基础参数
self.root_dir = root_dir #文件目录
self.transform = transform #变换
self.images = os.listdir(self.root_dir)#目录里的所有文件
def __len__(self):#返回整个数据集的大小
return len(self.images)
def __getitem__(self,index):#根据索引index返回dataset[index]
image_index = self.images[index]#根据索引index获取该图片
img_path = os.path.join(self.root_dir, image_index)#获取索引为index的图片的路径名
img = Image.open(img_path)# 读取该图片
label = int(image_index[-5])# 根据该图片的路径名获取该图片的label,具体根据路径名进行分割。我这里是"E:\\Python Project\\Pytorch\\dogs-vs-cats\\train\\cat.0.jpg",所以先用"\\"分割,选取最后一个为['cat.0.jpg'],然后使用"."分割,选取[cat]作为该图片的标签
# sample = (img,label)#根据图片和标签创建字典
if self.transform:
sample = self.transform(img)#对样本进行变换
return sample,label#返回该样本
transform_fn=Compose([ToTensor(), Normalize(mean=(0.1307,),std=(0.3081,))])
train_data = Pic_Data("./data/MNIST/train", transform=transform_fn)
test_data = Pic_Data("./data/MNIST/test")
class Mlp(nn.Module):
def __init__(self):
super(Mlp,self).__init__()
self.model=nn.Sequential(
nn.Linear(784,200),
nn.ReLU(inplace=True),
nn.Linear(200,200),
nn.ReLU(inplace=True),
nn.Linear(200,10),
nn.ReLU(inplace=True)
)
def forward(self,x):
x=x.view([x.size(0),1*28*28])
x=self.model(x)
return F.log_softmax(x,dim=-1)
# model=MnistModel()
model=Mlp()
optimizer=optim.Adam(model.parameters(),lr=0.001)
# if os.path.exists("./model/model_info.pkl"):
# model.load_state_dict(torch.load("./model/model_info.pkl"))
# optimizer.load_state_dict(torch.load("./model/optimizer_info.pkl"))
def train(epoch):
"""实例化训练过程"""
data_loader=DataLoader(data,batch_size=BATCH_SIZE,shuffle=True)
for idx,(x,target) in enumerate(data_loader):
#梯度设置为0
optimizer.zero_grad()
# 计算得到预测值
# print(x.size())
output=model(x)
# 得到损失
loss=F.nll_loss(output,target)
# 反向传播,计算损失
loss.backward()
# 参数更新
optimizer.step()
if idx%100==0:
print(epoch,idx,loss.item())
# torch.save(model.state_dict(),"./model/model_info.pkl")
# torch.save(optimizer.state_dict(),"./model/optimizer_info.pkl")
def test():
loss_list=[]
acc_list=[]
test_dataloader=DataLoader(test_data,batch_size=BATCH_SIZE,shuffle=True)
for idx,(x,target) in enumerate(test_dataloader):
with torch.no_grad():
output=model(x)
cur_loss=F.nll_loss(output,target)
loss_list.append(cur_loss)
# output.argmax(dim=1)
pred=output.max(dim=-1)[-1]
cur_acc=pred.eq(target).float().mean()
acc_list.append(cur_acc)
print("平均准确率","平均损失",np.mean(acc_list),np.mean(loss_list))
if __name__=="__main__":
for i in range(10):
train(i)
test()
t2=time.time()
print("完成任务用时",t2-t1)
test_dataloader=DataLoader(test_data,batch_size=1,shuffle=True)
for idx,(x,target) in enumerate(test_dataloader):
print(target)
x=x
target=target
# break
with torch.no_grad():
output=model(x)
# cur_loss=F.nll_loss(output,target[0])
# loss_list.append(cur_loss)
pred=output.max(dim=-1)[-1]
print(pred)
break
- 代码二:
#导入相关模块
from torch.utils.data import Dataset,DataLoader
from torchvision.transforms import Compose,ToTensor,Normalize
from torch import optim
from PIL import Image
from torch import nn
import torch.nn.functional as F
import numpy as np
import torch
import time
import os
t1=time.time()
BATCH_SIZE=128
class Pic_Data(Dataset): #继承Dataset
def __init__(self, root_dir, transform=None): #__init__是初始化该类的一些基础参数
self.root_dir = root_dir #文件目录
self.transform = transform #变换
self.data=self.load_img()
def load_img(self):
imgs=os.listdir(self.root_dir)#目录里的所有文件
data_list=[]
for im in imgs:
img_path = os.path.join(self.root_dir, im)#获取索引为index的图片的路径名
img = Image.open(img_path)# 读取该图片
img_arr=np.array(img,dtype=np.float32)/255
# img = Image.open(img_path)# 读取该图片
label = int(im[-5])# 根据该图片的路径名获取该图片的label,具体根据路径名进行分割。我这里是"E:\\Python Project\\Pytorch\\dogs-vs-cats\\train\\cat.0.jpg",所以先用"\\"分割,选取最后一个为['cat.0.jpg'],然后使用"."分割,选取[cat]作为该图片的标签
data_list.append((img_arr,label))
return data_list
def __len__(self):#返回整个数据集的大小
return len(self.data)
def __getitem__(self,index):#根据索引index返回dataset[index]
image_info,img_label = self.data[index]#根据索引index获取该图片
if self.transform:
sample = self.transform(image_info)#对样本进行变换
return image_info,img_label#返回该样本
transform_fn=Compose([ToTensor(), Normalize(mean=(0.1307,),std=(0.3081,))])
train_data=Pic_Data("./data/MNIST/train",transform=transform_fn)
test_data=Pic_Data("./data/MNIST/test")
class Mlp(nn.Module):
def __init__(self):
super(Mlp,self).__init__()
self.model=nn.Sequential(
nn.Linear(784,200),
nn.ReLU(inplace=True),
nn.Linear(200,200),
nn.ReLU(inplace=True),
nn.Linear(200,10),
nn.ReLU(inplace=True)
)
def forward(self,x):
x=x.view([x.size(0),1*28*28])
x=self.model(x)
return F.log_softmax(x,dim=-1)
# model=MnistModel()
model=Mlp()
optimizer=optim.Adam(model.parameters(),lr=0.001)
# if os.path.exists("./model/model_info.pkl"):
# model.load_state_dict(torch.load("./model/model_info.pkl"))
# optimizer.load_state_dict(torch.load("./model/optimizer_info.pkl"))
def train(epoch):
"""实例化训练过程"""
train_dataloader=DataLoader(train_data,batch_size=BATCH_SIZE,shuffle=True)
for idx,(x,target) in enumerate(train_dataloader):
#梯度设置为0
optimizer.zero_grad()
# 计算得到预测值
# print(x.size())
output=model(x)
# 得到损失
loss=F.nll_loss(output,target)
# 反向传播,计算损失
loss.backward()
# 参数更新
optimizer.step()
if idx%100==0:
print(epoch,idx,loss.item())
# torch.save(model.state_dict(),"./model/model_info.pkl")
# torch.save(optimizer.state_dict(),"./model/optimizer_info.pkl")
def test():
loss_list=[]
acc_list=[]
test_dataloader=DataLoader(test_data,batch_size=BATCH_SIZE,shuffle=True)
for idx,(x,target) in enumerate(test_dataloader):
with torch.no_grad():
output=model(x)
cur_loss=F.nll_loss(output,target)
loss_list.append(cur_loss)
# output.argmax(dim=1)
pred=output.max(dim=-1)[-1]
cur_acc=pred.eq(target).float().mean()
acc_list.append(cur_acc)
print("平均准确率","平均损失",np.mean(acc_list),np.mean(loss_list))
if __name__=="__main__":
for i in range(10):
train(i)
test()
t2=time.time()
print("完成任务用时",t2-t1)
test_dataloader=DataLoader(test_data,batch_size=1,shuffle=True)
for idx,(x,target) in enumerate(test_dataloader):
print(target)
x=x
target=target
# break
with torch.no_grad():
output=model(x)
# cur_loss=F.nll_loss(output,target[0])
# loss_list.append(cur_loss)
pred=output.max(dim=-1)[-1]
print(pred)
break
这里贴出我电脑训练十次的结果
代码一运行时长:

代码二运行时长:
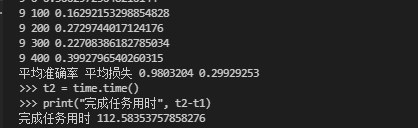
正常的直接用MNIST加载训练的时长:

因此,在进行大量的epoch时,十分推荐第二种方法。
参考文章链接:
https://blog.csdn.net/xuan_liu123/article/details/101145366
https://blog.csdn.net/qq_38237214/article/details/109559791
https://www.jianshu.com/p/2d9927a70594
https://blog.csdn.net/loveliuzz/article/details/108756253