Python电影爬虫,用Excel存储并进行数据可视化分析
目录
- 一、爬取网页数据
-
- 1、分析网页
-
- (1)网页数据类型
- (2)不同类型电影排行榜 url 的区别
-
- 电影分类对应关系表
- 2、编写爬虫
-
- (1)先寻找网页的 url
- (2)编写请求中使用的相应数据
- (3)发送响应
- 3、保存数据到Excel,格式为xlsx
-
- (1)用列表存储暂存数据
- (2)用字典来进一步存储数据
-
- 爬虫函数
- (3)将数据存入Excel中
- (4)将多个 sheet 合并成一个 sheet
- 4、完整代码
- 二、可视化数据分析
-
- 1、准备工作
-
- (1)导入库并且设置绘图参数
- (2)导入数据
- 2、数据预处理
-
- (1)缺失值处理
- (2)重复值处理
- 3、可视化分析
-
- (1)电影出品国的情况分析
- (2) 电影类型情况分析
- (3)电影数量分析
- 三、分析结果总结
-
-
- (1)电影高产国家或地区:
- (2)电影产业的高速发展年代:
- (3)评分排名:
-
一、爬取网页数据
1、分析网页
(1)网页数据类型
先查看网页中的数据是属于哪种类型,例如:text、json等。
(2)不同类型电影排行榜 url 的区别
然后我们分析各排行榜中的url有何不同:
https://movie.douban.com/typerank?type_name=剧情&type=11&interval_id=100:90&action=
https://movie.douban.com/typerank?type_name=喜剧&type=24&interval_id=100:90&action=
https://movie.douban.com/typerank?type_name=爱情&type=13&interval_id=100:90&action=
这边列举了三个观察很容易发现其中的对应关系是一种字典的对应,即每个分类名字(type_name)都有自己对应的数字(type)对应。
所以我就将其记录下来用一个字典进行存储:
type_name={"剧情":"11","喜剧":"24","动作":"5","爱情":"13","科幻":"17","动画":"25","悬疑":"10", \
"惊悚":"19","恐怖":"20","纪录片":"1","短片":"23","情色":"6","同性":"26",\
"音乐":"14","歌舞":"7","家庭":"28","儿童":"8","传记":"2","历史":"4","战争":"22","犯罪":"3","西部":"27",\
"奇幻":"16","冒险":"15","灾难":"12","武侠":"29","古装":"30","运动":"18","黑色电影":"31"}
电影分类对应关系表
下表是我查看并统计的,表比较长可以直接跳过
| type_name | type |
|---|---|
| 剧情 | 11 |
| 喜剧 | 24 |
| 动作 | 5 |
| 爱情 | 13 |
| 科幻 | 17 |
| 动画 | 25 |
| 悬疑 | 10 |
| 惊悚 | 19 |
| 恐怖 | 20 |
| 纪录片 | 1 |
| 短片 | 23 |
| 情色 | 6 |
| 同性 | 26 |
| 音乐 | 14 |
| 歌舞 | 7 |
| 家庭 | 28 |
| 儿童 | 8 |
| 传记 | 2 |
| 历史 | 4 |
| 战争 | 22 |
| 犯罪 | 3 |
| 西部 | 27 |
| 奇幻 | 16 |
| 冒险 | 15 |
| 灾难 | 12 |
| 武侠 | 29 |
| 古装 | 30 |
| 运动 | 18 |
| 黑色电影 | 31 |
2、编写爬虫
有了上述准备之后,就可以开写爬虫了。
(1)先寻找网页的 url
因为我已经写好了,所以就直接给出来。
url = "https://movie.douban.com/j/chart/top_list"
(2)编写请求中使用的相应数据
先是 Params :
# A dictionary of parameters that are used in the request.
# 请求中使用的参数字典。
Params = {
'type': f"{type_name[word1]}",
'interval_id': "100:90",
'action': None,
'start': "0",
'limit': f"{Number}",
}
其中的 type_name 就是上方的电影分类对应字典;后面的 word1 来表示字典中的key;Number 就是就是我们每个类型排行榜爬取电影的数量(可以比排行榜中的电影总数要大,我当时设置的是1000)
然后就是 headers(必须要有):
# A header that is used to identify the browser.
# 用于标识浏览器的标头。
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36"
}
(3)发送响应
用 response 发送请求,然后将响应数据转换为 json 对象
# Sending a request to the url with the parameters and headers.
# 向带有参数和标头的 url 发送请求。
response = requests.get(url=url , params=Params , headers=headers)
# Converting the response to a json object.
# 将响应转换为 json 对象。
result = response.json()
3、保存数据到Excel,格式为xlsx
(1)用列表存储暂存数据
因为每个数据标签(就是数据代表的意思)都不一样,所以用列表来分开存储:
# Creating a list of the column names.
# 创建列名列表。
title=["film_title",] # 片名
release_date=["release_date",] # 发布日期
actors=["actors",] # 演员
regions = ["country_of_production"] # 制片国家/地区
rating=["rating",] # 分数
vote_count = ["vote_count"] # 评分人数
rank=["rank",] # 在单分类榜中的排名
types = ["types"] # 影片类型
url=["url",] # 影片简介链接
(2)用字典来进一步存储数据
用字典来存储列表中的数据并形成键值对,然后生成 DataFrame
# Creating a dictionary with the keys being the column names and the values being the lists of values.
# 创建一个字典,键是列名,值是值列表。
output_excel = {"film_title": title, "release_date": release_date, "actors": actors, "regions": regions, "rating": rating, "vote_count": vote_count, "rank": rank, "types": types, "url": url}
output = pd.DataFrame(output_excel)
爬虫函数
到这里我们就已经大概写好我们用的爬虫了,然后我们将它写成一个函数方便使用
import requests
import pandas as pd
def DouBan_Movie_Sperider(word1,Number):
type_name={"剧情":"11","喜剧":"24","动作":"5","爱情":"13","科幻":"17","动画":"25","悬疑":"10", \
"惊悚":"19","恐怖":"20","纪录片":"1","短片":"23","情色":"6","同性":"26",\
"音乐":"14","歌舞":"7","家庭":"28","儿童":"8","传记":"2","历史":"4","战争":"22","犯罪":"3","西部":"27",\
"奇幻":"16","冒险":"15","灾难":"12","武侠":"29","古装":"30","运动":"18","黑色电影":"31"}
url = "https://movie.douban.com/j/chart/top_list"
Params = {
'type': f"{type_name[word1]}",
'interval_id': "100:90",
'action': None,
'start': "0",
'limit': f"{Number}",
}
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36"
}
response = requests.get(url=url , params=Params , headers=headers)
result = response.json()
title=["film_title",] # 片名
release_date=["release_date",] # 发布日期
actors=["actors",] # 演员
regions = ["country_of_production"] # 制片国家/地区
rating=["rating",] # 分数
vote_count = ["vote_count"] # 评分人数
rank=["rank",] # 在单分类榜中的排名
types = ["types"] # 影片类型
url=["url",] # 影片简介链接
for i in result:
title.append(i["title"])
release_date.append(i["release_date"])
actors.append(i["actors"])
regions.append(i["regions"])
rating.append(i["rating"][0])
vote_count.append(i["vote_count"])
rank.append(i["rank"])
types.append(i["types"])
url.append(i["url"])
output_excel = {"film_title": title, "release_date": release_date, "actors": actors, "regions": regions, "rating": rating, "vote_count": vote_count, "rank": rank, "types": types, "url": url}
output = pd.DataFrame(output_excel)
return output
(3)将数据存入Excel中
接下来我们将它数据存储到 Excel 中,我是用的是 exec(因为我觉得它比较好用) 语句来执行存储
# Creating a new dataframe for each word in the word_list and saving it to a new sheet in the excel file.
# 为 word_list 中的每个单词创建一个新的数据框,并将其保存到 excel 中的新工作表文件。
for m, i in enumerate(word_list, start=1):
exec(f'output{m} = DouBan_Movie_Sperider(i,Number)')
exec(f'output{m}.to_excel(writer,i)')
writer.save()
因为是分类型存储的,所以存储下来的表格也是分类的,也就是说我们还需要在将不同的 sheet 合并成一个 sheet ,这样会方便我们之后的数据分析。
(4)将多个 sheet 合并成一个 sheet
编写的这个函数传入两个参数,一个是原始的文件名,另一个是要合并后的文件名:读取每个工作表,将其附加到数据框,然后将数据框保存。
def merge_sheets(file, save_file):
file = pd.ExcelFile(file)
sheet_names = file.sheet_names
print(sheet_names)
sheet_concat = pd.DataFrame()
for sheet in sheet_names:
df = pd.read_excel(file, sheet_name=sheet, header=1, index_col=0)
sheet_concat = sheet_concat.append(df)
sheet_concat.to_excel(save_file)
file = 'Movie_douban.xlsx'
save_file = 'Movie_douban_classification_rankings.xlsx'
merge_sheets(file, save_file)
其中 file 是原始文件的文件名,save_file 是合并后的文件名,到这我们就可以进行数据分析了。
4、完整代码
# Importing the requests library.
# 导入 requests 库。
import requests
# Importing the pandas library and renaming it to pd.
# 导入 pandas 库并将其重命名为 pd.
import pandas as pd
"""
It takes a list of words and a number, and returns a dataframe of the top movies of each word in the
list.
:param word1: The type of movie you want to search for
:param Number: The number of movies you want to crawl
:return: A DataFrame.
它接受一个单词列表和一个数字,并返回每个单词的热门电影的数据帧
列表。
:param word1: 你要搜索的电影类型
:param Number: 要抓取的电影数量
:return: 一个 DataFrame。
"""
def DouBan_Movie_Sperider(word1,Number):
type_name={"剧情":"11","喜剧":"24","动作":"5","爱情":"13","科幻":"17","动画":"25","悬疑":"10", \
"惊悚":"19","恐怖":"20","纪录片":"1","短片":"23","情色":"6","同性":"26",\
"音乐":"14","歌舞":"7","家庭":"28","儿童":"8","传记":"2","历史":"4","战争":"22","犯罪":"3","西部":"27",\
"奇幻":"16","冒险":"15","灾难":"12","武侠":"29","古装":"30","运动":"18","黑色电影":"31"}
url = "https://movie.douban.com/j/chart/top_list"
# A dictionary of parameters that are used in the request.
# 请求中使用的参数字典。
Params = {
'type': f"{type_name[word1]}",
'interval_id': "100:90",
'action': None,
'start': "0",
'limit': f"{Number}",
}
# A header that is used to identify the browser.
# 用于标识浏览器的标头。
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36"
}
# Sending a request to the url with the parameters and headers.
response = requests.get(url=url , params=Params , headers=headers)
# Converting the response to a json object.
# 将响应转换为 json 对象。
result = response.json()
# Creating a list of the column names.
# 创建列名列表。
title=["film_title",] # 片名
release_date=["release_date",] # 发布日期
actors=["actors",] # 演员
regions = ["country_of_production"] # 制片国家/地区
rating=["rating",] # 分数
vote_count = ["vote_count"] # 评分人数
rank=["rank",] # 在单分类榜中的排名
types = ["types"] # 影片类型
url=["url",] # 影片简介链接
# A for loop that iterates through the result and appends the values of the keys to the lists.
# 遍历结果并将键的值附加到列表的 for 循环。
for i in result:
title.append(i["title"])
release_date.append(i["release_date"])
actors.append(i["actors"])
regions.append(i["regions"])
rating.append(i["rating"][0])
vote_count.append(i["vote_count"])
rank.append(i["rank"])
types.append(i["types"])
url.append(i["url"])
# Creating a dictionary with the keys being the column names and the values being the lists of values.
# 创建一个字典,键是列名,值是值列表。
output_excel = {"film_title": title, "release_date": release_date, "actors": actors, "regions": regions, "rating": rating, "vote_count": vote_count, "rank": rank, "types": types, "url": url}
output = pd.DataFrame(output_excel)
return output
def merge_sheets(file, save_file):
"""
It takes an Excel file and a save file name, reads in each sheet, appends it to a dataframe, and then saves the dataframe to the save file name
:param file: the file path of the excel file
:param save_file: the file name of the merged file
读取每个工作表,将其附加到数据框,然后将数据框保存。
:param file:excel文件的文件路径
:param save_file: 合并文件的文件名
"""
file = pd.ExcelFile(file)
sheet_names = file.sheet_names
print(sheet_names)
sheet_concat = pd.DataFrame()
for sheet in sheet_names:
df = pd.read_excel(file, sheet_name=sheet, header=1, index_col=0)
print(df.shape)
sheet_concat = sheet_concat.append(df)
sheet_concat.to_excel(save_file)
print('合并之后的数据大小:',sheet_concat.shape)
word_list=["剧情","喜剧","动作","爱情","科幻","动画","悬疑","惊悚","恐怖",\
"纪录片","短片","情色","同性","音乐","歌舞","家庭","儿童","传记","历史","战争","犯罪","西部",\
"奇幻","冒险","灾难","武侠","古装","运动","黑色电影"]
writer = pd.ExcelWriter("Movie_douban.xlsx")
Number = 1000
# Creating a new dataframe for each word in the word_list and saving it to a new sheet in the excel file.
# 为 word_list 中的每个单词创建一个新的数据框,并将其保存到 excel 中的新工作表文件。
for m, i in enumerate(word_list, start=1):
exec(f'output{m} = DouBan_Movie_Sperider(i,Number)')
exec(f'output{m}.to_excel(writer,i)')
writer.save()
file = 'Movie_douban.xlsx'
save_file = 'Movie_douban_classification_rankings.xlsx'
merge_sheets(file, save_file)
二、可视化数据分析
可视化数据分析建议使用 Jupyter notebook 的环境,我这里用的是 Jupyter notebook 有 % 的地方在一些 IDE 里面是不需要的,注意一下。
1、准备工作
(1)导入库并且设置绘图参数
# 导入所必须使用的库
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
#运行配置参数中的字体(font)为 黑体(SimHei)
matplotlib.rcParams['font.family'] = 'Microsoft YaHei'
#加sans-serif,这样如果所列出的字体都不能用,则默认的sans-serif字体能保证调用
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
#解决默认生成的统计图表不清楚问题,设定输出表格为SVG
%config InlineBackend.figure_format = 'svg'
#坐标轴符号无法正常显示问题
matplotlib.rcParams['axes.unicode_minus'] = False
#设置绘图风格
matplotlib.style.use('tableau-colorblind10')
(2)导入数据
导入数据然后查看一下数据
# 导入所使用的数据excel表(加载数据)
df = pd.read_excel("Movie_douban_classification_rankings.xlsx", sheet_name="Sheet1")
# 查看 df 的内容
df
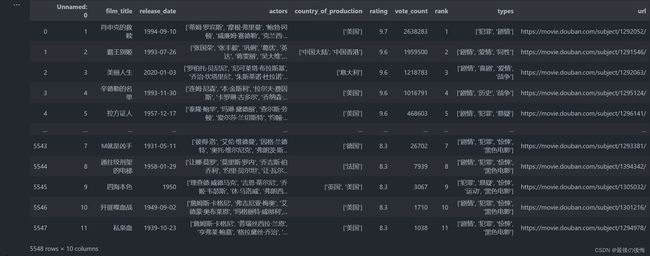
其中第一行中的导入数据表操作需要在工作目录中,如果是在别的地方,可以将其路径复制黏贴上去,例如:
D:\Python\Movie_douban_classification_rankings.xlsx
这里对表中数据进行一下标签
film_title = 片名
release_date = 发布日期
actors = 演员
country_of_production = 制片国家/地区
rating = 分数
vote_count = 评分人数
rank = 在单分类榜中的排名
types = 影片类型
url = 影片简介链接
2、数据预处理
(1)缺失值处理
先是查找缺失值:
# 数据预处理之缺失值发现
df.isnull()
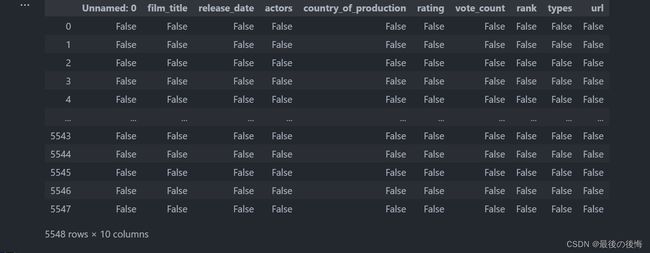
因为上述数据比较多,所以换种办法统计缺失,用这种办法可以直接显示有缺失值的行。
# 由于数据量较大,接下来调用 any 的方法判断是否表中有缺失值
nan_any_rows = df.isnull().any(axis=1)
df[nan_any_rows]
![]()
上面结果说明表中没有缺失值
(2)重复值处理
先检测是否有重复值:
# 调用 duplicated 方法检测是否有重复值
df['film_title'].duplicated()
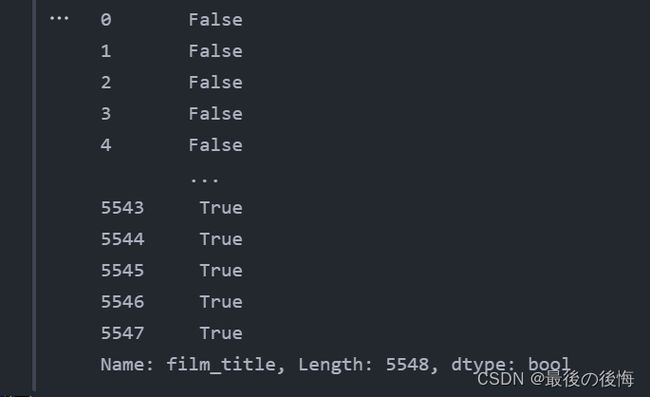
从结果发现还是有许多电影的片名是重复的,也就是说有电影不只有一种类别,所以接下来要删除重复值使它成为唯一值。
接下来就进行重复值的去除:
# 这边需要先删除掉第一列也就是合并之后出来的 unnamed(无名)列,因为这一列数据会阻碍我删除重复行,所以我们先把它删除
# 删除列的两种方法我们选择用 drop 方法,目的是为了让原始数据继续存在
new_df = df.drop(columns=["Unnamed: 0"])
# 然后我们用 drop_duplicates 方法将重复值去掉
new_df = new_df.drop_duplicates(subset= 'film_title')
# 查看删除重复之后的数据
new_df
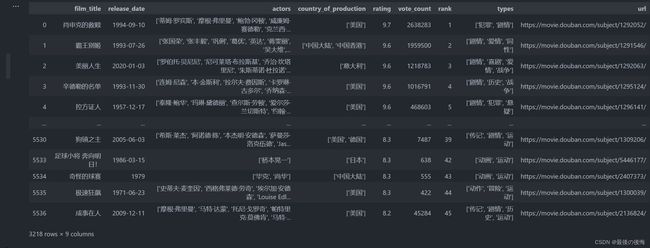
看下面的 3218 rows,明显已经将数据中重复值删去了。
3、可视化分析
(1)电影出品国的情况分析
因为之前我们使用了列表来存储,所以会有列表的符号也被存储进入了表中,所以要先将数据中多余的符号删除
# (1) 首先处理一下数据内部,将列表符号给删去
new_df_country1 = new_df['country_of_production'].str.replace('[', '', regex=False)
new_df_country2 = new_df_country1.str.replace(']', '', regex=False)
new_df_country3 = new_df_country2.str.replace("'", '', regex=False)
new_df_country3
接下来就是统计数据,这里我只选取了电影出品国家前十名的数据(太多了会很挤在画图的时候会看不清字)
# (2) 开始进行统计
movies_country = []
for country1 in new_df_country3:
country2 = country1.split(', ' or '/')
movies_country.extend(iter(country2))
new_df_country_number1 = pd.DataFrame({'country_of_production':movies_country})
new_df_country_number2 = new_df_country_number1['country_of_production'].value_counts()
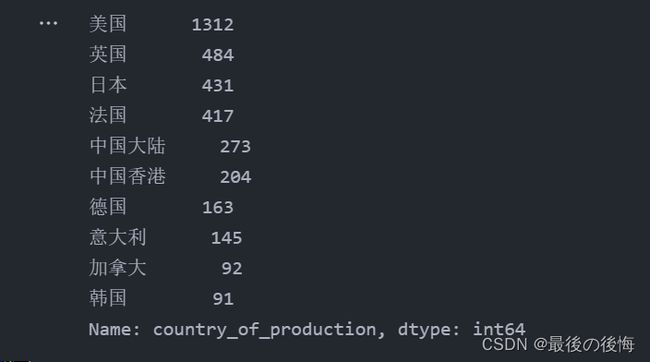
new_df_country_number2.head(10)
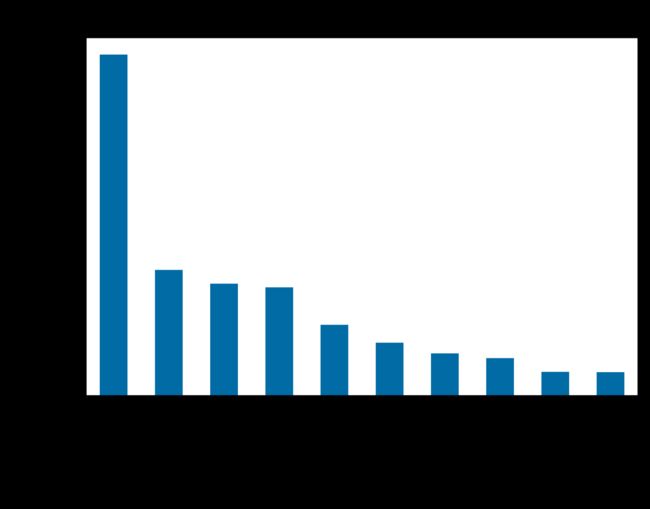
然后就是画图,画图这个很简单就不多解释了,设置好X轴和Y轴标题还有主标题就结束了
# (3) 绘制电影出品排名前十的柱形图
plt.title('Country/Numders') # 设立主标题
plt.xlabel('Country') # 设置X轴标题
plt.ylabel('Numders') # 设置Y轴标题
new_df_country_number2.head(10).plot(kind = "bar") # 绘图
如果用的不是 Jupyter notebook 的话,最后要加上一行 plt.show() ,作用是将图表显示出来,ps:括号一定不能少!!!
(2) 电影类型情况分析
跟上面一样,因为这个也是用列表存储的,所以也会带有列表符,所以也要先把它删掉:
# (1) 首先处理一下数据内部,将列表符号给删去
new_df_types1 = new_df['types'].str.replace('[', '', regex=False)
new_df_types2 = new_df_types1.str.replace(']', '', regex=False)
new_df_types3 = new_df_types2.str.replace("'", '', regex=False)
new_df_types3
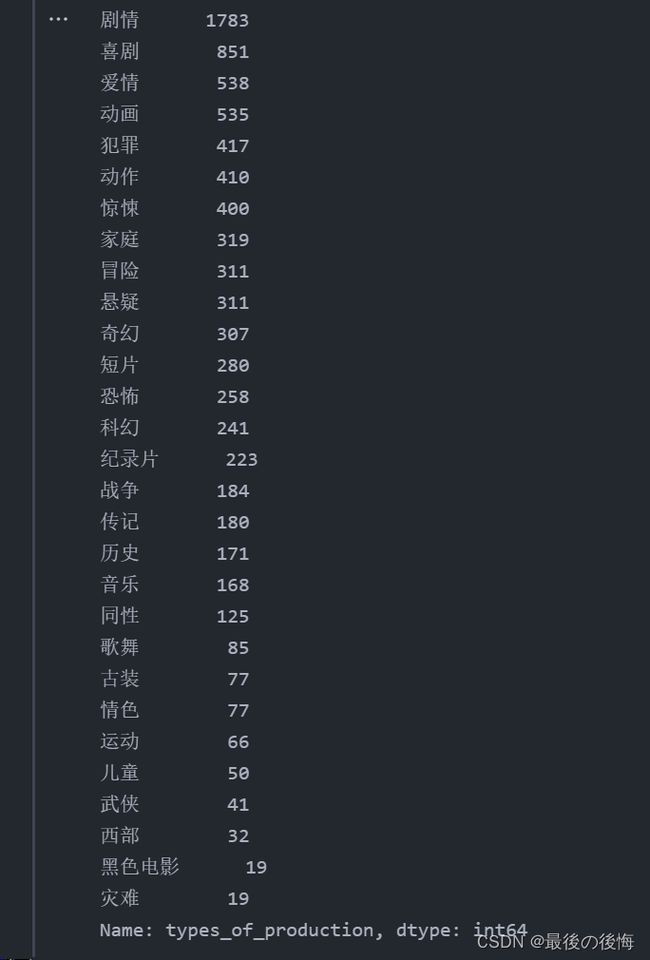
然后再进行统计数据,看每种类型有多少部电影
# (2) 进行统计(后期可优化与上代码进行合并成算法)
movies_types = []
for types1 in new_df_types3:
types2 = types1.split(', ')
movies_types.extend(iter(types2))
new_df_types_number1 = pd.DataFrame({'types_of_production':movies_types})
new_df_types_number2 = new_df_types_number1['types_of_production'].value_counts()
new_df_types_number2
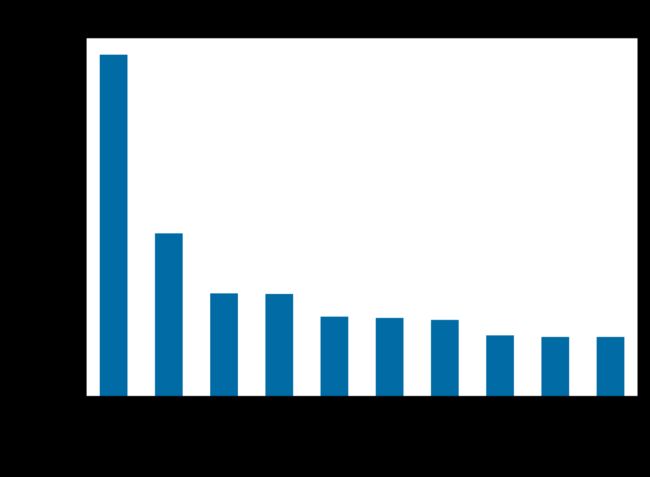
然后也是画图,设置好X轴和Y轴标题还有主标题,记住要是你用的不是 Jupyter notebook 要加上 plt.show() 才能看见图像!!!
# (3) 绘制不同类型电影的数量前十名的图像
new_df_types_number2.head(10).plot(kind = 'bar') # 绘图
plt.xlabel('Types') # 设置X轴标题
plt.ylabel('Numders') # 设置Y轴标题
plt.title('Types/Numbers') # 设立主标题
(3)电影数量分析
按年统计电影数量,因为我们存储的是文本数据,所以要先将文本数据进行转换:
# (1) 先将字符数据转换成年份
new_df_datetime = pd.to_datetime(new_df['release_date']).apply(lambda x:x.strftime('%Y'))
new_df_datetime
只一个 %Y 是因为按年统计只需要年份,所以我就不写多余的,如果要是需要月份或者日期的可以写成 %Y-%m-%d 类似这种格式。
然后就是按照年份统计电影的数量:
# (2) 按年份统计每年的电影数量
new_df_datetime_numbers_years = new_df_datetime.value_counts().sort_index()
(new_df_datetime_numbers_years
绘制图像,这次画的是折线图,因为看的是趋势,所以就画一个折线图:
# (3) 根据所统计的绘图
fig = plt.figure(figsize = (7, 5), dpi = 100)
plt.xlabel('Years')
plt.ylabel('Numders')
plt.title('Years/Numbers')
new_df_datetime_numbers_years.plot(kind = 'line')
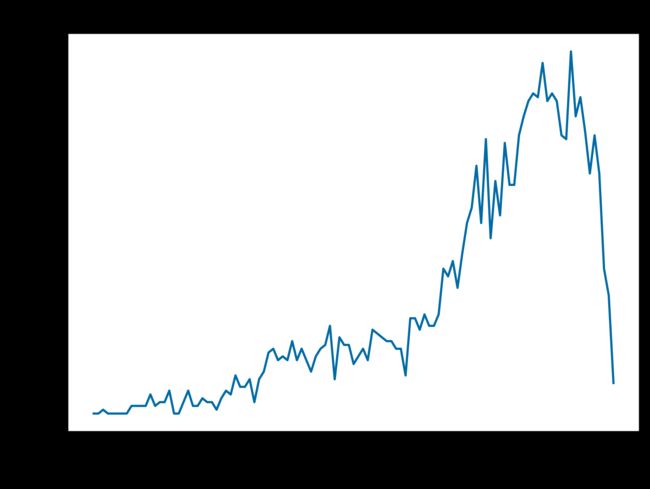
三、分析结果总结
(1)电影高产国家或地区:
美国、英国、日本、法国、中国大陆、中国香港、德国、意大利、加拿大、韩国。
(2)电影产业的高速发展年代:
1991-2013年
(3)评分排名:
多数分布于8-9分之间,有少数<7.5或者>9.6
感谢各位能耐心看到这里,如果对上面有什么疑惑或者建议可以评论或者私信我,一起讨论。