ElasticSearch学习笔记(二)
API创建索引及文档
找文档
网上的es教程大都十分老旧,而且es的版本众多,个别版本的差异还较大,另外es本身提供多种api,导致许多文章各种乱七八糟实例!所以后面直接放弃,从官网寻找方案,这里我使用elasticsearch最新的7.6.1版本来讲解。
1、进入es的官网指导文档 https://www.elastic.co/guide/index.html
2、找到 Elasticsearch Clients(这个就是客户端api文档)

3、我们使用java rest风格api,大家可以根据自己的版本选择特定的 other versions。

4、rest又分为 high level 和 low level (下面会讲解差异),我们直接选择 high level 下面的 Getting started

5、向下阅读找到Maven依赖和基本配置!

Java REST Client 说明
Java REST Client 有两种风格
Java Low Level REST Client :
- 用于Elasticsearch的官方低级客户端。
- 它允许通过 http 与 Elasticsearch 集群通信。
- 将【请求编排】和【响应反编排】留给用户自己处理。
- 它兼容所有的Elasticsearch版本。
- PS:学过WebService的话,对编排与反编排这个概念应该不陌生。
- 可以理解为【对请求参数的封装】,以及【对响应结果的解析】
Java High Level REST Client :
- 用于Elasticsearch的官方高级客户端。
- 它是基于低级客户端的,它提供很多API,并负责请求的编排与响应的反编排。
(PS)
-
就好比是,一个是传自己拼接好的字符串,并且自己解析返回的结果;
-
而另一个是传对象,返回的结果也已经封装好了,直接是对象。
-
更加规范了参数的名称以及格式,更加面对对象一点
-
所谓低级与高级,我觉得一个很形象的比喻是,【面向过程编程】与【面向对象编程】
-
网上很多教程比较老旧,都是使用TransportClient操作的
-
在 Elasticsearch 7.0 中不建议使用 TransportClient,并且在8.0中会完全删除TransportClient。
-
因此,官方更建议我们用 Java High Level REST Client
-
它执行HTTP请求,而不是序列化的Java请求。
-
既然如此,这里我们就直接用高级了。
配置基本项目依赖
1、新建一个springboot(2.2.5版)项目 kuang-elasticsearch ,导入web依赖即可!
2、配置es的依赖!
<properties>
<java.version>1.8java.version>
<elasticsearch.version>7.6.1elasticsearch.version>
properties>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
3、继续阅读文档到Initialization ,我们看到需要构建RestHighLevelClient对象;
// 构建客户端对象
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http"),
new HttpHost("localhost", 9201, "http"))
);
// 操作代码........................................
// 高级客户端内部会创建低级客户端,用基于其提供的 builder 执行请求。
// 低级客户端维护一个连接池,并启动一些线程,因此当你用完以后应该关闭高级客户端,这在内部它也会关闭低级客户端,以释放这些资源。
// 关闭客户端可以使用close()方法:
client.close();
4、我们编写一个配置类,提供 RestHighLevelClient 这个 bean 来进行操作
package com.kuang.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticsearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));
return client;
}
}
5、常用方法工具类封装
package com.kuang.utils;
import com.alibaba.fastjson.JSON;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.FetchSourceContext;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.util.List;
import java.util.concurrent.TimeUnit;
@Component
public class EsUtils<T> {
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
/**
* 判断索引是否存在
* @param index
* @return
* @throws IOException
*/
public boolean existsIndex(String index) throws IOException {
GetIndexRequest request = new GetIndexRequest(index);
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
return exists;
}
/**
* 创建索引
* @param index
* @throws IOException
*/
public boolean createIndex(String index) throws IOException {
CreateIndexRequest request = new CreateIndexRequest(index);
CreateIndexResponse createIndexResponse = client.indices().create(request,RequestOptions.DEFAULT);
return createIndexResponse.isAcknowledged();
}
/**
* 删除索引
* @param index
* @return
* @throws IOException
*/
public boolean deleteIndex(String index) throws IOException {
DeleteIndexRequest deleteIndexRequest = new
DeleteIndexRequest(index);
AcknowledgedResponse response = client.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
return response.isAcknowledged();
}
/**
* 判断某索引下文档id是否存在
* @param index
* @param id
* @return
* @throws IOException
*/
public boolean docExists(String index, String id) throws IOException {
GetRequest getRequest = new GetRequest(index,id);
//只判断索引是否存在不需要获取_source
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);
return exists;
}
/**
* 添加文档记录
* @param index
* @param id
* @param t 要添加的数据实体类
* @return
* @throws IOException
*/
public boolean addDoc(String index,String id, T t) throws IOException {
IndexRequest request = new IndexRequest(index);
request.id(id);
//timeout
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
request.source(JSON.toJSONString(t), XContentType.JSON);
IndexResponse indexResponse = client.index(request,
RequestOptions.DEFAULT);
RestStatus Status = indexResponse.status();
return Status==RestStatus.OK||Status== RestStatus.CREATED;
}
/**
* 根据id来获取记录
* @param index
* @param id
* @return
* @throws IOException
*/
public GetResponse getDoc(String index, String id) throws IOException {
GetRequest request = new GetRequest(index,id);
GetResponse getResponse = client.get(request,
RequestOptions.DEFAULT);
return getResponse;
}
/**
* 批量添加文档记录
* 没有设置id的话, ES会自动生成一个,如果要设置 IndexRequest的对象.id()即可
* @param index
* @param list
* @return
* @throws IOException
*/
public boolean bulkAdd(String index, List<T> list) throws IOException {
BulkRequest bulkRequest = new BulkRequest();
//timeout
bulkRequest.timeout(TimeValue.timeValueMinutes(2));
bulkRequest.timeout("2m");
for (int i =0;i<list.size();i++){
bulkRequest.add(new IndexRequest(index)
.source(JSON.toJSONString(list.get(i))));
}
BulkResponse bulkResponse = client.bulk(bulkRequest,
RequestOptions.DEFAULT);
return !bulkResponse.hasFailures();
}
/**
* 批量删除和更新就不写了可根据上面几个方法来写
*/
/**
* 更新文档记录
* @param index
* @param id
* @param t
* @return
* @throws IOException
*/
public boolean updateDoc(String index,String id,T t) throws IOException
{
UpdateRequest request = new UpdateRequest(index,id);
request.doc(JSON.toJSONString(t));
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
UpdateResponse updateResponse = client.update(
request, RequestOptions.DEFAULT);
return updateResponse.status()==RestStatus.OK;
}
/**
* 删除文档记录
* @param index
* @param id
* @return
* @throws IOException
*/
public boolean deleteDoc(String index,String id) throws IOException {
DeleteRequest request = new DeleteRequest(index,id);
//timeout
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
DeleteResponse deleteResponse = client.delete(
request, RequestOptions.DEFAULT);
return deleteResponse.status()== RestStatus.OK;
}
/**
* 根据某字段来搜索
* @param index
* @param field
* @param key 要收搜的关键字
* @throws IOException
*/
public void search(String index,String field ,String key,Integer from,Integer size) throws IOException {
SearchRequest searchRequest = new SearchRequest(index);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.termQuery(field, key));
//控制搜素
sourceBuilder.from(from);
sourceBuilder.size(size);
//最大搜索时间。
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits()));
}
}
API 测试
在测试类中进行
测试创建索引:
//最好在 Maven 的 runner 中,选择:Skip test ,否则会创建两次,报错
@Test
void testCreateIndex() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("mytest_index");
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}

测试获取索引:
@Test
void testExistsIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("kuang_index");
boolean exists = restHighLevelClient.indices().exists(request,RequestOptions.DEFAULT);
System.out.println(exists);
}

测试删除索引:
@Test
void testDeleteIndexRequest() throws IOException {
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("kuang_index");
AcknowledgedResponse response = restHighLevelClient.indices().delete(deleteIndexRequest,RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
}

测试添加文档记录:
创建一个实体类User
@Data
@AllArgsConstructor
@NoArgsConstructor
@Component
public class User {
private String name;
private int age;
}
测试添加文档记录
@Test
void testAddDocument() throws IOException {
// 创建对象
User user = new User("大靓仔", 18);
// 创建请求
IndexRequest request = new IndexRequest("mytest_index");
// 规则
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
request.source(JSONUtil.toJsonStr(user), XContentType.JSON);
// 发送请求
IndexResponse indexResponse = restHighLevelClient.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
RestStatus Status = indexResponse.status();
System.out.println(Status == RestStatus.OK || Status == RestStatus.CREATED);
}

测试:判断某索引下文档id是否存在
// 判断此id是否存在这个索引库中
@Test
void testIsExists() throws IOException {
GetRequest getRequest = new GetRequest("mytest_index","1");
// 不获取_source 上下文, storedFields = none
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
// 判断此id是否存在!
boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
测试:根据id获取记录
// 获得文档记录
@Test
void testGetDocument() throws IOException {
GetRequest getRequest = new GetRequest("kuang_index","3");
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString()); // 打印文档内容
System.out.println(getResponse);
}
![]()
测试:更新文档记录
// 更新文档记录
@Test
void testUpdateDocument() throws IOException {
UpdateRequest request = new UpdateRequest("mytest_index","1");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
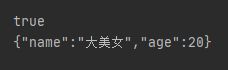
User user = new User("大美女", 20);
request.doc(JSONUtil.toJsonStr(user), XContentType.JSON);
UpdateResponse updateResponse = restHighLevelClient.update(request, RequestOptions.DEFAULT);
System.out.println(updateResponse.status() == RestStatus.OK);
//再获取
GetRequest getRequest = new GetRequest("mytest_index","1");
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString()); // 打印文档内容
}
测试:删除文档记录
// 删除文档测试
@Test
void testDelete() throws IOException {
DeleteRequest request = new DeleteRequest("mytest_index","1");
//timeout
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
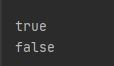
DeleteResponse deleteResponse = restHighLevelClient.delete(request, RequestOptions.DEFAULT);
System.out.println(deleteResponse.status() == RestStatus.OK);
//再判断是否存在
GetRequest getRequest = new GetRequest("mytest_index","1");
// 不获取_source 上下文, storedFields = none
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
// 判断此id是否存在!
boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
测试:批量添加文档
// 批量添加数据
@Test
void testBulkRequest() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
//timeout
bulkRequest.timeout(TimeValue.timeValueMinutes(2));
bulkRequest.timeout("2m");
ArrayList<User> userList = new ArrayList<>();
userList.add(new User("戈登",33));
userList.add(new User("企鹅人",28));
userList.add(new User("谜语人",27));
userList.add(new User("布鲁斯韦恩",16));
userList.add(new User("哈维",35));
for (int i =0;i<userList.size();i++){
bulkRequest.add(
new IndexRequest("mytest_index")
.id(""+(i+1))
.source(JSONUtil.toJsonStr(userList.get(i)), XContentType.JSON)
);
}
// bulk
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(!bulkResponse.hasFailures());
}

查询测试:
// 查询测试
/**
* 使用 QueryBuilder
* termQuery("key", obj) 完全匹配
* termsQuery("key", obj1, obj2..) 一次匹配多个值
* matchQuery("key", Obj) 单个匹配, field不支持通配符, 前缀具高级特性
* multiMatchQuery("text", "field1", "field2"..); 匹配多个字段, field有通配符
* matchAllQuery(); 匹配所有文件
*/
@Test
void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("mytest_index");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name","人");
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
sourceBuilder.query(matchAllQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSONUtil.toJsonStr(response.getHits())); // response.getHits() 来获取匹配到的数据
System.out.println("================SearchHit==================");
for (SearchHit documentFields : response.getHits().getHits()) {
System.out.println(documentFields.getSourceAsMap());
}
}

查询测试 2

实战测试
初始化项目
1、启动es服务和客户端
2、使用springboot快速构建服务

3、修改版本依赖!
<properties>
<java.version>1.8java.version>
<elasticsearch.version>7.6.1elasticsearch.version>
properties>
4、配置 application.properties 文件
server.port=9090
# 关闭thymeleaf缓存
spring.thymeleaf.cache=false
5、导入前端的素材!修改为Thymeleaf支持的格式!
<html xmlns:th="http://www.thymeleaf.org">
6、编写IndexController进行跳转测试是否能正常访问 search 页面!
jsoup讲解
爬虫:
- python 常用的是 BeautifulSoup
- java 常用的是 Jsoup
1、导入jsoup的依赖
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.13.1version>
dependency>
2、编写一个工具类 HtmlParseUtil
public class HtmlParseUtil {
public static void main(String[] args) throws IOException {
// jsoup不能抓取ajax的请求,除非自己模拟浏览器进行请求!
// 1、https://search.jd.com/Search?keyword=java
String url = "https://search.jd.com/Search?keyword=java";
// 2、解析网页(需要联网)
Document document = Jsoup.parse(new URL(url), 30000);
// 3、抓取搜索到的数据!
// Document 就是我们JS的Document对象,你可以看到很多JS语法
Element element = document.getElementById("J_goodsList");
// 4、分析网页,找到需要的数据
//找到所有的li元素
Elements elements = element.getElementsByTag("li");
// 获取京东的商品信息
for (Element el : elements) {
// 这种网站,一般为了保证效率,一般会延时加载图片
// String img = el.getElementsByTag("img").eq(0).attr("src");
String img = el.getElementsByTag("img").eq(0).attr("source-data-lazy-img");
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
System.out.println(img);
System.out.println(price);
System.out.println(title);
System.out.println("================================");
}
}
}
3、封装一个实体类保存爬取下来的数据
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Content {
private String title; // 商品名称
private String price; // 商品价格
private String img; // 商品封面
// 可以自行扩展
}
4、封装为工具使用!
/**
* @author 狂神说Java 公众号:狂神说
* @param keywords 要搜索的关键字!
* @return 抓取的商品集合
*/
public List<Content> parseJD(String keywords) throws Exception {
String url = "https://search.jd.com/Search?keyword="+keywords;
Document document = Jsoup.parse(new URL(url), 30000);
Element element = document.getElementById("J_goodsList");
Elements elements = element.getElementsByTag("li");
ArrayList<Content> goodsList = new ArrayList<>();
// 获取京东的商品信息
for (Element el : elements) {
String img = el.getElementsByTag("img").eq(0).attr("source-data-
lazy-img");
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
// 封装获取的数据
Content content = new Content();
content.setImg(img);
content.setPrice(price);
content.setTitle(title);
goodsList.add(content);
}
return goodsList;
}
5、测试工具类的使用!
public static void main(String[] args) throws Exception {
new HtmlParseUtil().parseJD("vue").forEach(System.out::println);
}
搞定收工!简单爬虫编写完毕!
我们这里的数据就使用爬取的即可,平时开发es的数据可能来自多个地方,你们可以从数据库查询获取也是一样的,后面我们来测试下效果!

业务编写
1、导入ElasticsearchClientConfig 配置类
@Configuration
public class ElasticsearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("127.0.0.1", 9200, "http"))
);
return client;
}
}
2、编写业务
@Service
public class ContentService {
@Autowired
private RestHighLevelClient restHighLevelClient;
// 1、解析数据存入es
public Boolean parseContent(String keywords) throws Exception {
// 解析查询出来的数据
List<Content> contents = new HtmlParseUtil().parseJD(keywords);
// 封装数据到索引库中!
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout(TimeValue.timeValueMinutes(2));
bulkRequest.timeout("2m");
for(int i =0;i<contents.size();i++){
bulkRequest
.add(new IndexRequest("jd_goods")
.source(JSON.toJSONString(contents.get(i)),XContentType.JSON));
}
BulkResponse bulkResponse =
restHighLevelClient.bulk(bulkRequest,RequestOptions.DEFAULT);
return !bulkResponse.hasFailures();
}
// 2、实现搜索功能,带分页处理
public List<Map<String, Object>> searchContentPage(String keyword, int pageNo, int pageSize) throws IOException {
// 基本的参数判断!
if(pageNo <= 1){
pageNo = 1;
}
// 基本的条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 分页
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
// 精准匹配 QueryBuilders 根据自己要求配置查询条件即可!
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyword);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
// 搜索
searchRequest.source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 解析结果!
List<Map<String, Object>> list = new ArrayList<>();
for (SearchHit documentFields : response.getHits().getHits()) {
list.add(documentFields.getSourceAsMap());
}
return list;
}
}
3、controller
@RestController
public class ContentController {
@Autowired
private ContentService contentService;
@GetMapping("/parse/{keyword}")
public Boolean parse( @PathVariable("keyword") String keyword) throws Exception {
return contentService.parseContent(keyword);
}
//http://localhost:9090/search/java/1/10
@GetMapping("/search/{keyword}/{pageNo}/{pageSize}")
public List<Map<String, Object>> search(
@PathVariable("keyword") String keyword,
@PathVariable("pageNo") int pageNo,
@PathVariable("pageSize") int pageSize) throws Exception {
return contentService.searchContentPage(keyword,pageNo,pageSize);
}
}
前端逻辑
1、定义导入vue和axios的依赖
<script th:src="@{/js/axios.js}">script>
<script th:src="@{/js/vue.min.js}">script>
2、初始化Vue对象,给外层div绑定app对象
<script>
new Vue({
el: '#app',
data: {
keyword: '', // 搜索关键字
results: [] // 搜索的结果
}
})
script>
3、绑定搜索框及相关事件

4、编写方法,获取后端传递的数据
<script>
new Vue({
el: '#app',
data: {
keyword: '',
results: []
},
methods: {
searchKey(){
var keyword = this.keyword;
console.log(keyword);
axios.get('search/'+keyword+"/1/10").then(response=>{
console.log(response);
this.results = response.data;
});
}
}
})
script>
5、渲染解析回来的数据

搜索高亮
1、编写业务类,处理高亮字段
// 3、实现搜索功能,带高亮
public List<Map<String, Object>> searchContentHighlighter(String keyword,
int pageNo, int pageSize) throws IOException {
// 基本的参数判断!
if(pageNo <= 1){
pageNo = 1;
}
// 基本的条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 分页
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
// 精准匹配 QueryBuilders 根据自己要求配置查询条件即可!
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyword);
sourceBuilder.query(termQueryBuilder);
// 高亮构建!
HighlightBuilder highlightBuilder = new HighlightBuilder(); //生成高亮查询器
highlightBuilder.field("title"); //高亮查询字段
highlightBuilder.requireFieldMatch(false); //如果要多个字段高亮,这项要为 false
highlightBuilder.preTags(""); //高亮设置
highlightBuilder.postTags("");
sourceBuilder.highlighter(highlightBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
// 搜索
searchRequest.source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 解析结果!
List<Map<String, Object>> list = new ArrayList<>();
for (SearchHit hit : response.getHits()) {
//获取高亮字段
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField titleField = highlightFields.get("title");
Map<String, Object> source = hit.getSourceAsMap();
//千万记得要记得判断是不是为空,不然你匹配的第一个结果没有高亮内容,那么就会报空指针异常,这个错误一开始真的搞了很久
if(titleField!=null){
Text[] fragments = titleField.fragments();
String name = "";
for (Text text : fragments) {
name += text;
}
source.put("title", name); //高亮字段替换掉原本的内容
}
list.add(source);
}
return list;
}
2、controller层调用新的高亮业务
//http://localhost:9090/search/java/1/10
@GetMapping("/search/{keyword}/{pageNo}/{pageSize}")
public List<Map<String, Object>> search(
@PathVariable("keyword") String keyword,
@PathVariable("pageNo") int pageNo,
@PathVariable("pageSize") int pageSize) throws Exception {
return contentService.searchContentHighlighter(keyword,pageNo,pageSize);
}
3、前端vue指令解析html
<p class="productTitle">
<a v-html="result.title"> a>
p>
4、最终效果

ES集群
为什么要实现集群
ES基本概念名词
Cluster
- 代表一个集群
- 集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的
- 主从节点是对于集群内部来说的。
- es的一个概念就是去中心化,字面上理解就是无中心节点,这是对集群外部来说的
- 因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
Shards
- 代表索引分片
- es 可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。
- 【分片的数量】只能在索引创建前指定,并且索引创建后不能更改。
Replicas
- 代表索引副本
- es可以设置多个索引的副本
- 副本的作用
- 提高系统的容错性:当某个节点某个分片损坏或丢失时可以从副本中恢复。
- 提高es的查询效率:es会自动对搜索请求进行【负载均衡】。
Recovery
- 代表数据恢复,或叫数据重新分布
- es在有节点加入或退出时,会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
ES 为什么要实现集群
在单台ES服务器节点上,随着业务量的发展索引文件慢慢增多,会影响到效率和内存存储问题等。
我们可以采用ES集群,将单个索引的分片到多个不同分布式物理机器上存储,从而可以实现高可用、容错性等。
ES集群中,索引可能由多个分片构成,并且每个分片可以拥有多个副本。
通过将一个单独的索引分为多个分片,我们可以处理不能在一个单一的服务器上面运行的大型索引,
简单的说就是索引的大小过大,导致效率问题。
不能运行的原因可能是内存也可能是存储。
由于每个分片可以有多个副本,通过将副本分配到多个服务器,可以提高查询的负载能力。
ES 如何解决高并发
ES是一个分布式全文检索框架,隐藏了复杂的处理机制,内部使用 分片机制、集群发现、分片负载均衡请求路由。
-
Shards 分片:
- 代表索引分片(A = B + C + D …)
- es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上,构成分布式搜索。
- 分片的数量只能在索引创建前指定,并且索引创建后不能更改。
-
Replicas分片:
- 代表索引副本(A = B = C = D …)
- es可以设置多个索引的副本,副本的作用
- 提高系统的容错性:当某个节点某个分片损坏或丢失时可以从副本中恢复。
- 提高es的查询效率:es会自动对搜索请求进行负载均衡。
集群规划
搭建一个集群我们需要考虑如下几个问题:
1、我们需要多大规模的集群?
2、集群中的节点角色如何分配?
3、如何避免脑裂问题?
4、索引应该设置多少个分片?
5、分片应该设置几个副本?
下面我们就来分析和回答这几个问题:
我们需要多大规模的集群?
需要从以下两个方面考虑:
1、当前的数据量有多大?数据增长情况如何?
2、你的机器配置如何?cpu、多大内存、多大硬盘容量?
推算的依据:
- ES JVM heap 最大可以设置32G 。
- 30G heap 大概能处理的数据量 10 T。
- 如果内存很大如128G,可在一台机器上运行多个ES节点实例。
- 备注:集群规划满足当前数据规模 + 适量增长规模即可,后续可按需扩展。
两类应用场景:
A、用于构建业务搜索功能模块,且多是垂直领域的搜索。数据量级几千万到数十亿级别。一般2-4台机器的规模。
B、用于大规模数据的实时OLAP(联机处理分析),经典的如ELK Stack,数据规模可能达到千亿或更多。几十到上百节点的规模。
集群中的节点角色如何分配?
节点角色:
Master
- node.master: true 节点可以作为主节点
DataNode
- node.data: true 默认是数据节点。
Coordinate node
- 如果仅担任协调节点,将上两个配置设为 false。
- 协调节点:
- 该节点只提供【接收请求、转发请求到其他节点、汇总各个节点返回数据】等功能。
说明
一个节点可以充当一个或多个角色,默认三个角色都有
如何分配:
A、小规模集群,不需严格区分。
B、中大规模集群(十个以上节点),应考虑单独的角色充当。
- 特别并发查询量大,查询的合并量大,可以增加独立的协调节点。
- 角色分开的好处是分工分开,不互影响。
- 不会因协调角色负载过高而影响数据节点的能力。
如何避免脑裂问题?
脑裂问题:
-
一个集群中只有一个A主节点
-
A主节点因为需要处理的东西太多或者网络过于繁忙,从而导致其他从节点ping不通A主节点
-
其他从节点就会认为A主节点不可用了,就会重新选出一个新的主节点B。
-
过了一会A主节点恢复正常了
-
这样就出现了两个主节点
-
导致一部分数据来源于A主节点,另外一部分数据来源于B主节点,出现数据不一致问题
-
这就是脑裂。
尽量避免脑裂,需要添加最小数量的主节点配置:
discovery.zen.minimum_master_nodes: (有master资格的节点数/2) + 1
这个参数控制的是,选举主节点时,需要看到最少多少个具有master资格的【活节点】,才能进行选举。
官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量。
常用做法(中大规模集群):
1、Master 和 dataNode 角色分开,配置奇数个master,如3
2、单播发现机制,配置master资格节点:
- discovery.zen.ping.multicast.enabled: false
- 关闭多播发现机制,默认是关闭的
- discovery.zen.ping.unicast.hosts: [“master1”, “master2”, “master3”]
- 配置单播发现的主节点ip地址
- 其他从节点要加入进来,就得去询问单播发现机制里面配置的主节点:我想加入到集群里面了?
- 主节点同意以后才能加入,然后主节点再通知集群中的其他节点有新节点加入
3、配置选举发现数,及延长ping master的等待时长
- discovery.zen.ping_timeout: 30(默认值是3秒)
- 其他节点ping主节点多久时间没有响应就认为主节点不可用了
- discovery.zen.minimum_master_nodes: 2
- 选举主节点时需要看到最少多少个具有master资格的活节点,才能进行选举
索引应该设置多少个分片?
说明:分片数指定后不可变,除非重索引。
思考:
分片对应的存储实体是什么?
- 本质上就是一个Lucene索引
存储的实体是索引分片是不是越多越好?
- 不是
分片多有什么影响?
- 分片多浪费存储空间、占用资源、影响性能
分片过多的影响:
- 每个分片本质上就是一个Lucene索引,因此会消耗相应的文件句柄,内存和CPU资源。
- 每个搜索请求会调度到索引的每个分片中。
- 如果分片分散在不同的节点倒是问题不太
- 但当分片开始竞争相同的硬件资源时, 性能便会逐步下降。
- ES使用词频统计来计算相关性
- 当然这些统计也会分配到各个分片上
- 如果在大量分片上只维护了很少的数据,则将导致最终的文档相关性较差。
分片设置的可参考原则:
-
ElasticSearch推荐的最大JVM堆空间是30~32G
-
所以把你的分片最大容量限制为30GB, 然后再对分片数量做合理估算
-
例如,你认为你的数据能达到200GB,推荐你最多分配7到8个分片。
-
在开始阶段,一个好的方案是根据你的节点数量按照1.5~3倍的原则来创建分片
-
例如,如果你有3个节点,则推荐你创建的分片数最多不超过9(3x3)个。
-
当性能下降时,增加节点,ES会平衡分片的放置。
-
对于基于日期的索引需求,并且对索引数据的搜索场景非常少,也许这些索引量将达到成百上千
-
但每个索引的数据量只有1GB甚至更小。
-
对于这种类似场景,建议只需要为索引分配1个分片。
-
如日志管理就是一个日期的索引需求,日期索引会很多,但每个索引存放的日志数据量就很少。
分片应该设置几个副本?
说明:副本数是可以随时调整的!
思考:
1、副本的用途是什么?
- 备份数据保证高可用数据不丢失,高并发的时候参与数据查询
2、针对它的用途,我们该如何设置它的副本数?
- 一般一个分片有1-2个副本即可保证高可用
3、集群规模没变的情况下副本过多会有什么影响?
- 副本多浪费存储空间、占用资源、影响性能
副本设置基本原则:
- 为保证高可用,副本数设置为2即可。
- 要求集群至少要有3个节点,来分开存放主分片、副本。
- 如发现并发量大时,查询性能会下降,可增加副本数,来提升并发查询能力。
注意:新增副本时主节点会自动协调,然后拷贝数据到新增的副本节点
集群核心原理分析
1、
主分片
- 每个索引会被分成多个分片shards进行存储,默认创建索引是分配5个分片进行存储。
- 每个分片都会分布式部署在多个不同的节点上进行部署,该分片成为primary shards。
注意:索引的主分片primary shards定义好后,后面不能做修改。
2、
副分片
- 为了实现高可用数据的高可用,主分片可以有对应的副分片replics shards,
- replic shards分片承载了负责容错、以及请求的负载均衡。
注意:
- 每一个主分片为了实现高可用,都会有自己对应的备分片
- 主分片对应的备分片不能存放同一台服务器上。
- 主分片primary shards可以和其他replics shards存放在同一个node节点上。
3、
documnet routing(数据路由)
-
当客户端发起创建 document 的时候,es需要确定这个 document 放在该 index 哪个 shard 上。
-
这个过程就是数据路由。
-
路由算法:shard = hash(routing) % number_of_primary_shards
-
如果 number_of_primary_shards 在查询的时候取余发生的变化,则无法获取到该数据
-
所以索引的主分片数量定义好后,不能被修改

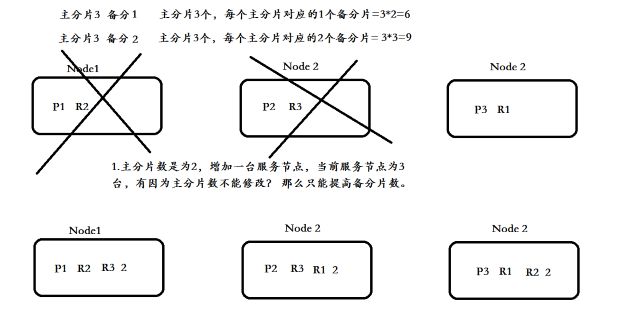
高可用视图分析
下图所示:上面的图,如果节点1与节点2宕机了,es集群数据就不完整了。
下图,如果节点1与节点2宕机了,es集群数据还是完整的
集群搭建
1、复制三个 elasticsearch 的整个文件夹
2、进入 elasticsearch的config 目录,修改elasticsearch.yml的配置
# ================= Elasticsearch Configuration ===================
# 配置es的集群名称, es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个
属性来区分不同的集群。
cluster.name: elasticsearch
# 节点名称(要修改)
node.name: node-001
# 指定该节点是否有资格被选举成为node
node.master: true
# 指定该节点是否存储索引数据,默认为true。
node.data: true
# 设置绑定的ip地址还有其它节点和该节点交互的ip地址,本机ip
network.host: 127.0.0.1
# 指定http端口,你使用head、kopf等相关插件使用的端口 (要修改)
http.port: 9200
# 设置节点间交互的tcp端口,默认是9300。 (要修改)
transport.tcp.port: 9300
#设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。
#因为下两台elasticsearch的port端口会设置成9301 和 9302 所以写入两台#elasticsearch地
址的完整路径
discovery.zen.ping.unicast.hosts:
["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
#如果要使用head,那么需要解决跨域问题,使head插件可以访问es
http.cors.enabled: true
http.cors.allow-origin: "*"
配置解析
IP访问限制、默认端口修改9200
这里有两个需要提醒下
-
一:IP访问限制
-
二:es实例的默认端口号9200
-
IP访问限制可以限定具体的IP访问服务器,这有一定的安全过滤作用。
# Set the bind address to a specific IP (IPv4 or IPv6):
network.host: 0.0.0.0
如果设置成0.0.0.0则是不限制任何IP访问。
一般在Dev阶段的服务器会限定几台IP,用于管理使用。
默认的端口9200在一般情况下也有点风险,可以将默认的端口修改成另外一个,还有一个原因就是怕开发人员误操作,连接上集群。
当然,如果你的公司网络隔离做的很好也无所谓。
这里的9300是集群内部通讯使用的端口,这个也可以修改掉。
因为连接集群的方式有两种,通过扮演集群node也是可以进入集群的,所以还是安全起见,修改掉默认的端口。
说明:记得修改安装了ES的3台虚拟机(三个节点)的相同配置,要不然节点之间无法建立连接工作,也会报错。
集群发现IP列表、node、cluster名称
紧接着修改集群节点IP地址,这样可以让集群在规定的几个节点之间工作。
elasticsearch,默认是使用自动发现IP机制。
就是在当前网段内,只要能被自动感知到的IP就能自动加入到集群中。
这有好处也有坏处。
好处就是自动化了,当你的es集群需要云化的时候就会非常方便。
但是也会带来一些不稳定的情况,如,master的选举问题、数据复制问题。
导致master选举的因素之一就是集群有节点进入。
当数据复制发生的时候也会影响集群,因为要做数据平衡复制和冗余。
这里面可以独立master集群,剔除master集群的数据节点能力。
固定列表的IP发现有两种配置方式,一种是互相依赖发现,一种是全量发现。
这有个很重要的参考标准,就是你的集群扩展速度有多快。
因为这有个问题就是,当全量发现的时候,如果是初始化集群会有很大的问题,就是master全局会很长,然后节点之间的启动速度各不一样。
所以我采用了靠谱点的依赖发现。
你需要在192.168.152.128的elasticsearch中配置成:
# --------------------------------- Discovery -------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.zen.ping.unicast.hosts: ["192.168.152.129:9300","192.168.152.130:9300" ]
让他去发现129,130的机器,以此内推,完成剩下的129和130机器的配置。
然后你需要配置下集群名称,就是你当前节点所在集群的名称,这有助于你规划你的集群。集群中的所有节点的集群名称必须一样,只有集群名称一样才能组成一个逻辑集群。
# ---------------------------------- Cluster --------------------------------
# Use a descriptive name for your cluster:
#
cluster.name: mycluster
配置你当前节点的名称
# ------------------------------------ Node ---------------------------------
# Use a descriptive name for the node:
#
node.name: node-1
以此类推,完成另外两个节点的配置。cluster.name的名称必须保持一样。然后分别设置node.name。
说明:
这里搭建的是一个简单的集群,没有做集群节点角色的区分,所以3个节点默认的角色有主节点、数据节点、协调节点
选举ES主节点的逻辑:
选举的大概逻辑,它会根据分片的数据的前后新鲜程度来作为选举的一个重要逻辑。(日志、数据、时间都会作为集群master全局的重要指标)
因为考虑到数据一致性问题,当然是用最新的数据节点作为master,然后进行新数据的复制和刷新其他 node。