NNDL 作业11:优化算法比较


1. 编程实现图6-1,并观察特征
代码如下:
import numpy as np
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
def func(x, y):
return x * x / 20 + y * y
def paint_loss_func():
x = np.linspace(-50, 50, 100) # x的绘制范围是-50到50,从改区间均匀取100个数
y = np.linspace(-50, 50, 100) # y的绘制范围是-50到50,从改区间均匀取100个数
X, Y = np.meshgrid(x, y)
Z = func(X, Y)
fig = plt.figure() # figsize=(10, 10))
ax = Axes3D(fig)
plt.xlabel('x')
plt.ylabel('y')
ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='rainbow')
plt.show()
paint_loss_func()输出结果:
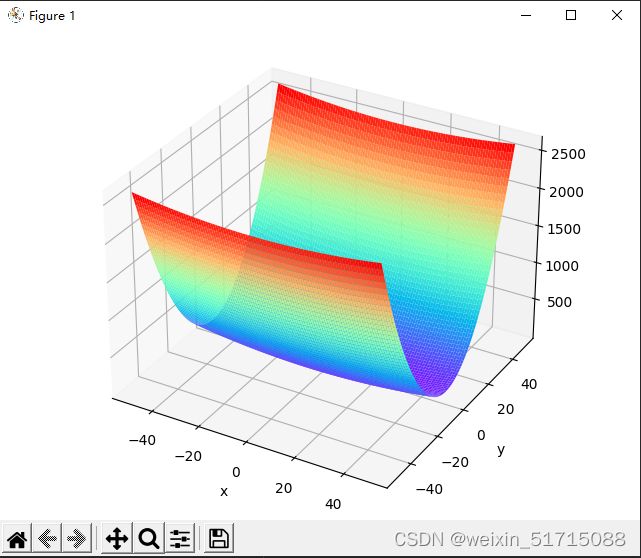

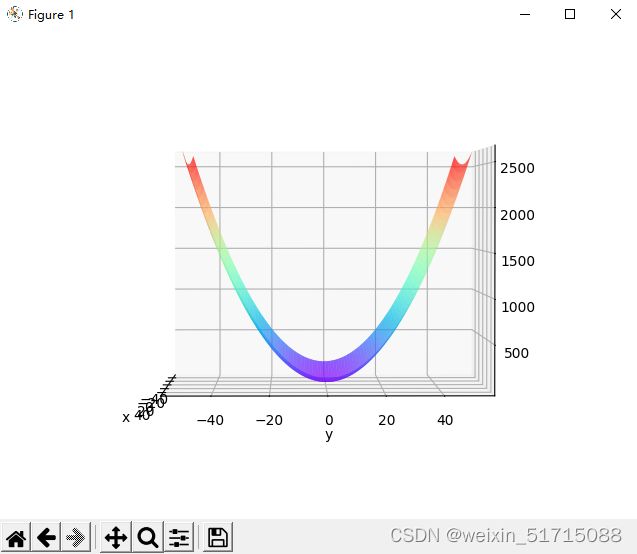
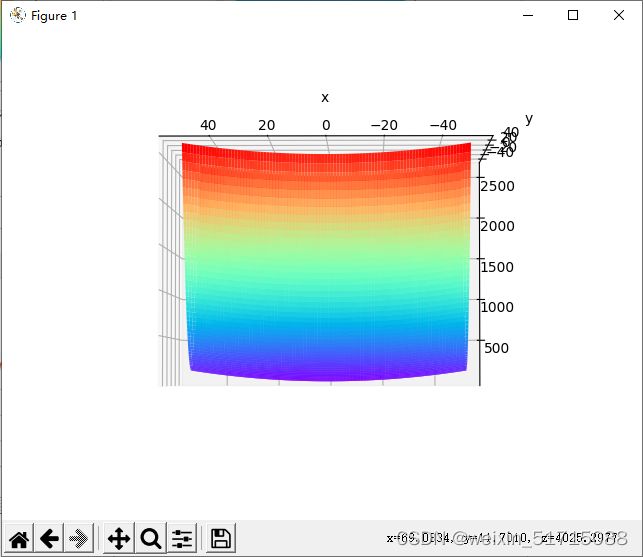
特征:有全局最小值、是一个向x轴方向延申的“碗”状函数,等高线呈向x轴方向延申的椭圆状。
2. 观察梯度方向
这个梯度的特征是,y轴方向上大,x轴方向上小。换句话说, 就是y轴方向的坡度大,而x轴方向的坡度小。这里需要注意的是,虽然式 (6.2)的最小值在(x, y)= (0, 0)处,但是图6-2中的梯度在很多地方并没有指向(0,0)。
3. 编写代码实现算法,并可视化轨迹
SGD、Momentum、Adagrad、Adam

实现代码:
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
class SGD:
"""随机梯度下降法(Stochastic Gradient Descent)"""
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
class Momentum:
"""Momentum SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]
class Nesterov:
"""Nesterov's Accelerated Gradient (http://arxiv.org/abs/1212.0901)"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] *= self.momentum
self.v[key] -= self.lr * grads[key]
params[key] += self.momentum * self.momentum * self.v[key]
params[key] -= (1 + self.momentum) * self.lr * grads[key]
class AdaGrad:
"""AdaGrad"""
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class RMSprop:
"""RMSprop"""
def __init__(self, lr=0.01, decay_rate=0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2 ** self.iter) / (1.0 - self.beta1 ** self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key] ** 2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
def f(x, y):
return x ** 2 / 20.0 + y ** 2
def df(x, y):
return x / 10.0, 2.0 * y
init_pos = (-7.0, 2.0)
params = {}
params['x'], params['y'] = init_pos[0], init_pos[1]
grads = {}
grads['x'], grads['y'] = 0, 0
optimizers = OrderedDict()
optimizers["SGD"] = SGD(lr=0.95)
optimizers["Momentum"] = Momentum(lr=0.1)
optimizers["AdaGrad"] = AdaGrad(lr=1.5)
optimizers["Adam"] = Adam(lr=0.3)
idx = 1
for key in optimizers:
optimizer = optimizers[key]
x_history = []
y_history = []
params['x'], params['y'] = init_pos[0], init_pos[1]
for i in range(30):
x_history.append(params['x'])
y_history.append(params['y'])
grads['x'], grads['y'] = df(params['x'], params['y'])
optimizer.update(params, grads)
x = np.arange(-10, 10, 0.01)
y = np.arange(-5, 5, 0.01)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
# for simple contour line
mask = Z > 7
Z[mask] = 0
# plot
plt.subplot(2, 2, idx)
idx += 1
plt.plot(x_history, y_history, 'o-', color="red")
plt.contour(X, Y, Z) # 绘制等高线
plt.ylim(-10, 10)
plt.xlim(-10, 10)
plt.plot(0, 0, '+')
plt.title(key)
plt.xlabel("x")
plt.ylabel("y")
plt.subplots_adjust(wspace=0, hspace=0) # 调整子图间距
plt.show()输出结果:
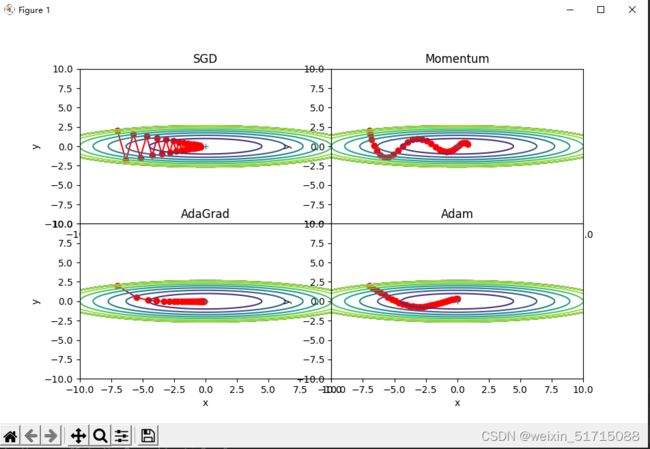
4. 分析上图,说明原理(选做)
1.为什么SGD会走“之字形”?其它算法为什么会比较平滑?
由于图像的变化并不均匀,所以y方向变化很大时,x方向变化很小,只能迂回往复地寻找,效率很低,但对于算法自己来说这是不可避免的“最优路径”。其他算法在下降开始阶段,历史速度变量和当前梯度方向相反,就会使下降的过程更为平滑。
2.Momentum、AdaGrad对SGD的改进体现在哪里?速度?方向?在图上有哪些体现?
SGD:因为BGD的迭代速度在大数据量的情况下会变得非常慢,所以提出了随机梯度下降算法,即每一次迭代只使用一个样本,根据这一个样本来计算梯度。优劣点:迭代速度快,不是全局最优解。
迭代公式:

Momentum:因为SGD只依赖于当前迭代的梯度,十分不稳定,加一个“动量”的话,相当于有了一个惯性在里面,梯度方向不仅与这次的迭代有关,还与之前一次的迭代结果有关。“当前一次效果好的话,就加快步伐;当前一次效果不好的话,就减慢步伐”;而且在局部最优值处,没有梯度但因为还存在一个动量,可以跳出局部最优值。
迭代公式:
AdaGrad:对学习率加了一个约束,但依赖于一个全局学习率。根据迭代公式,学习率 α 乘上了一个系数,这个系数与梯度有关,且当梯度大的时候,这个系数小;当梯度小的时候,这个系数大。这样的实际表现就是在面对频繁出现的特征时,使用小学习率;在面对不频繁出现的特征时,使用大学习率。这就使得这一算法非常适合处理稀疏数据。比如在训练单词嵌入时,常用单词和不常用单词分别用小学习率和大学习率能达到更好的效果。
迭代公式:

3.仅从轨迹来看,Adam似乎不如AdaGrad效果好,是这样么?
是的,AdaGrad擅长学习稀疏feature和稀疏梯度。学习率衰减的Adam算法在imdb数据集上,可以取得和AdaGrad一样的效果。
5. 总结SGD、Momentum、AdaGrad、Adam的优缺点(选做)
SGD:
算法收敛速度快(在Batch Gradient Descent算法中, 每轮会计算很多相似样本的梯度, 这部分是冗余的),可以在线更新,有几率跳出一个比较差的局部最优而收敛到一个更好的局部最优甚至是全局最优。缺点是容易收敛到局部最优,并且容易被困在鞍点。
Momentum:
Momentum算法借用了物理中的动量概念,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力。
Momentum算法会观察历史梯度,若当前梯度的方向与历史梯度一致(表明当前样本不太可能为异常点),则会增强这个方向的梯度,若当前梯度与历史梯方向不一致,则梯度会衰减。
AdaGrad:
上述方法中,对于每一个参数θ的训练都使用了相同的学习率α。Adagrad算法能够在训练中自动的对learning rate进行调整,对于出现频率较低参数采用较大的α更新;相反,对于出现频率较高的参数采用较小的α更新。因此,Adagrad非常适合处理稀疏数据。
缺点:
在训练的中后期,分母上梯度平方的累加将会越来越大,从而梯度趋近于0,使得训练提前结束。
Adam:
Adam(Adaptive Moment Estimation)是另一种自适应学习率的方法。它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
在数据比较稀疏的时候,adaptive的方法能得到更好的效果,例如Adagrad,RMSprop, Adam 等。Adam 方法也会比 RMSprop方法收敛的结果要好一些, 所以在实际应用中 ,Adam为最常用的方法,可以比较快地得到一个预估结果。
总结:
这次作业让我对SGD、Momentum、AdaGrad、Adam有了一定的了解,主要是总结了它们的优缺点以及内在联系,整体有一个更加清晰的认识。