Wing Loss 论文阅读笔记
Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks
论文链接: https://arxiv.org/abs/1711.06753
一、 Problem Statement
对于人脸关键点检测,作者对比了L1, L2,Smooth-L1 Loss, 发现它们在大误差下表现的很好,但是在小误差下,或者中等区域的误差下,表现较差。
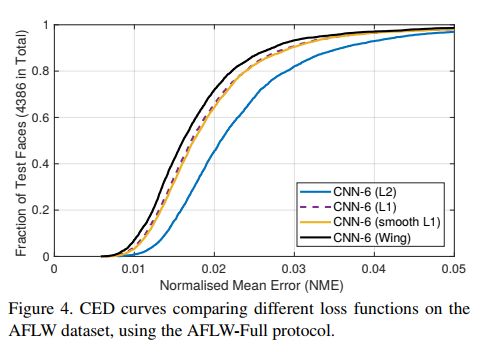
首先我们来看一下CED曲线是怎么去理解的。CED曲线横轴代表归一化误差,纵轴代表小于归一化误差 e e e 的landmarks占所有总landmarks的比例。这样下来,在大误差下,也就是 0.04 − 0.05 0.04-0.05 0.04−0.05范围,样本比例占比较大,但在小误差下,或者中误差下,样本比例占比较小。所以作者认为需要关注这些小误差和中误差的问题,其实我理解应该为精度的问题。
二、 Direction
作者基于上面的实验,提出新的loss function: wing loss。
三、 Method
稍微理解一下facial landmark localisation的问题定义:
给定一张图片 I ∈ R H × W × 3 I \in \R^{H \times W \times 3} I∈RH×W×3, 输出一个向量 s ∈ R 2 L s \in \R^{2L} s∈R2L, 形式为: s = [ x 1 , x 2 , . . . , x L , y 1 , y 2 , . . . , y L ] T s = [x_1, x_2, ..., x_L, y_1, y_2, ..., y_L]^T s=[x1,x2,...,xL,y1,y2,...,yL]T,其中 L L L是预定义的2D facial landmarks的数量, ( x , y ) (x,y) (x,y)代表图像的像素坐标。
接下来,作者先看了L1 loss:
L 1 ( x ) = ∣ x ∣ L1(x) = |x| L1(x)=∣x∣
L2 loss:
L 2 ( x ) = 1 2 x 2 L2(x) = \frac{1}{2}x^2 L2(x)=21x2
和 Smooth-L1 loss:
smooth L 1 ( x ) = { 1 2 x 2 , if ∣ x ∣ < 1 ∣ x ∣ − 1 2 , otherwise \text{smooth}_{L1}(x) = \bigg \{ \begin{matrix} \frac{1}{2} x^2, & \text{if} |x| < 1 \\ |x| - \frac{1}{2},& \text{otherwise} \end{matrix} smoothL1(x)={21x2,∣x∣−21,if∣x∣<1otherwise
具体图像如下图所示:
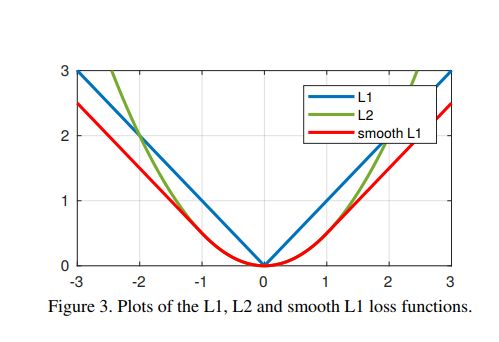
作者认为,L1 和 L2 损失函数的梯度分别为1和 ∣ x ∣ |x| ∣x∣,最优步长为 ∣ x ∣ |x| ∣x∣和1。(引用[1]的理解)而在一些情况下,L1, L2 会被那些大的误差所主导。比如,L1, 对所有的点的梯度都是1,但步长是不成比例地受到较大误差的影响。而对于L2,步长都是相同的,但是梯度是较大误差所主导的。因此,在这两种情况下,很难校正相对较小的位移
- 优化步长:优化步长指得是要达到最优化,需要迭代的次数(步数);L1的梯度是固定的,所以误差越大,采用L1优化就需要更多的迭代次数,也就是他说的“优化步长随着误差增大而增大”;反之,L2的梯度跟误差是成正比的。例如:你与目标距离有100公里,假设没次前进0.01(学习率);第一次L2梯度是100,你前进100*0.01=1公里,第二次,还有99公里,梯度就是99,则一步前进99*0.01=0.99公里,以此类推;而L1的梯度固定是1,则每次前进1*0.01=0.01公里
小误差的影响可以通过loss function来增强,比如 ln x \ln x lnx,它的倒数为 1 x \frac{1}{x} x1, 随着误差接近0而增大,且其最优的步长是 x 2 x^2 x2。当组合多个点的贡献时,梯度将由较小的误差控制,但步长由较大的误差控制。 然而,为了防止在可能错误的方向上进行大的更新步骤,重要的是不要过度补偿小的定位误差的影响。 通过对log function 添加一个positive offset。
上述的设计适合于处理相对较小的定位误差。但是,作者认为,对于facial landmarks detection来说,初始位置误差可能非常大。因此在这种情况下,损失函数应促进这些大错误中快速恢复。 因此,所设计新的损失函数,应该像L1 或者L2 那样。但是由于L2对于对离群点比较敏感,因此作者选择了L1。
wing ( x ) = { w l n ( 1 + ∣ x ∣ / ϵ ) , if ∣ x ∣ < w ∣ x ∣ − C , otherwise \text{wing}(x) = \bigg \{ \begin{matrix} w ln(1+ |x| / \epsilon), & \text{if} |x| < w \\ |x| - C,& \text{otherwise} \end{matrix} wing(x)={wln(1+∣x∣/ϵ),∣x∣−C,if∣x∣<wotherwise
其中, 非负数 w w w 是非线性部分 ( − w , w ) (-w, w) (−w,w), ϵ \epsilon ϵ限制了非线性区域的曲率, C = w − w l n ( 1 + w / ϵ ) C=w - wln(1+w/ \epsilon) C=w−wln(1+w/ϵ) 是个常数,用于平滑连接分段定义的线性和非线性部分。在论文中 w = 10 w = 10 w=10, ϵ = 2 \epsilon = 2 ϵ=2。ϵ的取值不能取很小的数值,因为它会使网络训练变得不稳定,并且会因为很小的误差导致梯度爆炸问题。
后面的Pose-based data balancing和 Two-stage landmark localization在本文就不记录了,以后有需要再去看原文。
四、 Conclusion
wing loss 的关键思想是增加中,小型误差样本对回归网络训练的贡献。
五、 Reference
- https://blog.csdn.net/john_bh/article/details/106302026