【SLAM论文阅读笔记】Multi-modal Semantic SLAM for Complex Dynamic Environments
Multi-modal Semantic SLAM for Complex Dynamic Environments
复杂动态环境下多模态语义SLAM
发布期刊或者会议
2022.5.10 发布在arxiv上 南洋理工大学
背景
目前SLAM技术是机器人应用领域最重要的技术之一。缺点是当前SLAM系统主要面向静态场景。目前语义SLAM的出现提高机器人对环境的理解,同时能通过图像分割来区分动态信息。但是目前语义分割存在分割不完整的问题。鉴于这个问题,作者提出了一个鲁棒的多模态语义框架去解决slam在复杂和动态环境下的问题。
本文学习更强大的对象特征表示,并将三思机制部署到主干网络,从而为我们的基线实例分割模型带来更好的识别结果。
此外,论文将纯几何聚类和视觉语义信息相结合,以减少由于小尺度物体、遮挡和运动模糊导致的分割误差的影响。
在识别不完整和运动模糊的动态物体实验中,该方法的识别精度都是比较精确的。同时可以以10hz的频率对静态场景进行稠密建图,从而可以应用到许多场景当中
目前数据集和代码已经开放:
https://github.com/wh200720041/MMS_SLAM
论文地址:https://arxiv.org/abs/2205.04300
贡献
- 提出了一个强大且快速的多模态语义 SLAM 框架,旨在解决复杂和动态环境中的 SLAM 问题。具体来说,我们将仅几何聚类和视觉语义信息相结合,以减少由于小尺度对象、遮挡和运动模糊导致的分割误差的影响。
2.学习更强大的对象特征表示,并将三思机制部署到主干网络,从而为我们的基线实例分割模型带来更好的识别结果。 - 对所提出的方法进行了全面的评估。结果表明,我们的方法能够提供可靠的定位和语义密集的地图
常见的动态SLAM的处理方法有:
特征一致性验证方法;基于深度学习的方法,以及基于多模态的方法。
特征一致性验证:
“Rgb-d slam in dynamic environments using point correlations
利用点之间的关联性 区分动态物体和静止场景的分割方法。该方法计算要求低。
“Rgb-d slam in dynamic environments using static point weighting
介绍了一种基于实时深度边缘的 RGB-D SLAM 系统来处理动态环境。提出了静态加权方法来测量边缘点作为静态环境一部分的可能性,并进一步用于帧到关键帧点云的配准。
优点:这些方法的优点是可以实时实现,因为并没有增加时间。此外并不需要先验物体信息。
缺点:无法做到连续跟踪潜在移动的物体,例如,在以上的工作中,在移动之间暂时停在某个位置的人被视为静态对象。
基于深度学习的动态SLAM:
视觉SLAM
- 基于orbslam2, 利用语义分割方法去除动态物体的特征点,对相机位姿进行优化,以此来提高相机跟踪的鲁棒性
- 语义分割方法结合运动一致性方法减少动态物体的影响
- 利用动态物体检测器
缺点:由于耗时的问题,导致智能离线进行。
激光SLAM:
1.通过使用完全卷积神经网络将这些标签嵌入到基于密集面元的地图表示中来集成语义信息。然而,所采用的分割网络是基于 3D 点云的,与 2D 分割网络相比效率较低。
2.参考文献 [19] 开发了一种激光惯性里程计和映射方法,该方法由四个顺序模块组成,用于为大规模高速公路环境执行实时和稳健的姿态估计。
3.通过将分割图像重叠到 LiDAR 扫描中,提出了一种动态无对象 LOAM 系统。虽然基于深度学习的方法可以有效缓解动态对象对 SLAM 性能的影响,但由于深度学习神经网络的实现具有较高的计算复杂度,它们通常难以实时操作
基于多模态的动态SLAM:
- Towards a meaningful 3d map using a 3d lidar and a camera
介绍了一种基于多模态传感器的语义映射算法,以改进大规模和无特征环境中的语义 3D 地图。尽管这项工作与本文提出的方法相似,但与本文提出的方法相比,它会产生更高的计算成本。 - Static-map and dynamic object reconstruction in outdoor scenes using 3-d motion segmentation 雷达和视觉相机的多模态SLAM
应用基于稀疏子空间聚类的运动分割方法 去构造一个静态地图在动态环境中。 - Sensor fusion of monocular cameras and laser range finders for line-based simultaneous localization and mapping (slam) tasks in autonomous mobile robots 整合了单目相机和雷达相机去移除与动态物对应的特征外点。
2和3的方法只使用低 动态场景的,并不使用高度动态的场景。本文提出的方法说是可以适用高度动态的环境中!!!
方法
流程图:
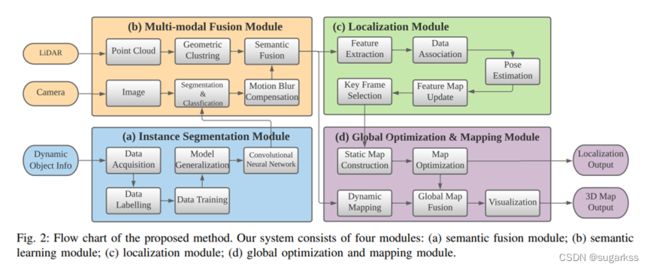
主要分为四块 1.多模态信息融合(视觉相机和雷达的信息的融合);2.实例分割模块(主要是为多模态信息融合模块提供动态物体分割的语义信息,可以实时)3.定位模块 4.全局优化和建图模块。
本文说是多模态融合过程是将有关语义数据传输给激光雷达,随后在使用多模态信息去强化分割结果!!!
在定位模块中使用静态信息来寻找机器人位姿,而在全局优化和建图模块中同时使用静态信息和动态信息来构建 3D 密集语义图
A. 实例分割和语义学习
使用2D实例分割网络
一张图像的实例分割结果:

C代表类别 M是物体的掩码信息 n代表当前图像中存在物体数量
图像在空间上被分成 N × N 个网格单元。如果一个对象的中心落入一个网格单元,该网格单元负责分别预测类别分支Bc和掩码分支P m 中对象的语义类别Cij和语义掩码Mij:
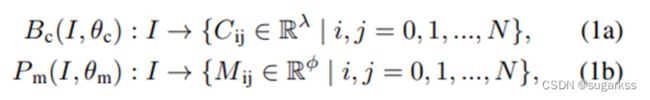
λ 是类的数量。 φ 是网格单元的总数。
类别分支和掩码分支通过全连接网络 (FCN) 实现
为了满足实时性的要求:采用SOLOv2 的轻量级版本,但精度较低,可实现实时实例分割。
为了提高分割精度:实施了多种方法来在骨干网络中构建更有效和更健壮的特征表示鉴别器。
- 主干架构从原来的特征金字塔网络(FPN)修改为递归特征金字塔网络(RFP)[25]。
Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution 2020CVPR
从理论上讲,RFP 通过将来自 FPN 的额外反馈集成到自下而上的主干层中,灌输了查看两次或更多次的想法。这递归地加强了现有的 FPN 并提供了越来越强大的特征表示。???没怎么懂
通过在较低级别的特征图中用较小的感受野抵消更丰富的信息,提高对小对象的分割性能。??
同时,RFP 自适应增强和抑制神经元激活的能力使实例分割网络能够更有效地处理被遮挡的对象。 - 用 Switchable Atrous Convolution (SAC) 替换了主干架构中的卷积层。 SAC 作为软开关功能运行,用于收集具有不同开口率的卷积计算的输出。因此,能够从 SAC 中学习最优系数,并且可以自适应地选择感受野的大小。这使得 SOLOv2 能够有效地提取重要的空间信息。
输出的结果:
输出是每个动态对象的像素级实例掩码,以及它们对应的边界框和类类型。为了更好地将动态信息集成到 SLAM 算法中,输出二进制掩码被转换为包含场景中所有像素级实例掩码的单个图像。蒙版落在其上的像素被认为是“动态状态”,否则被认为是“静态”。然后将二进制掩码应用于语义融合模块以生成 3D 动态掩码。
B. 多模态融合
- 移动模糊补偿: 目前实例分割的性能已经是不错的,但是移动的物体会出现物体识别不完整 导致物体的边界不明确 最终影响定位精度。
因此,本文首先实现形态膨胀,将 2D 像素级掩模图像与结构元素进行卷积,以逐渐扩展动态对象的区域边界。
形态膨胀结果标志着动态对象周围的模糊边界。我们将动态对象及其边界作为动态信息,将在多模态融合部分进一步细化。 - 几何聚类 语义融合
通过欧几里得空间 [27] 的连通性分析进行补偿也在本文的工作中实现。
结合点云聚类结果和分割结果来更好地细化动态对象。特别是,我们对几何信息进行连通性分析,并与基于视觉的分割结果合并。
为了提高工作效率,首先将 3D 点云缩小以减少数据规模,并将其用作点云聚类的输入。然后将实例分割结果投影到点云坐标上,对每个点进行标注。当大多数点(90%)是动态标记点时,点云簇将被视为动态簇。当静态点靠近动态点簇时,它会被重新标记为动态标签。并且当附近没有动态点聚类时,动态点将被重新标记。
C.定位与位姿估计
- 特征提取:
在经过多模态融合后,点云被分为 静态点云PD 和动态点云PS
静态点云 可用于定位与 见图中 在先前的工作已被提出。
Lightweight 3-d localization and mapping for solid-state lidar
该方法的优点是可以达到30HZ 与LOAM相比。
与 ORB-SLAM2 和 VINS-MONO视觉 SLAM 相比,它还可以抵抗光照变化。
对于每个静态点PS找到他附近的静态点几何SK(欧拉空间中).
因此,局部平滑度定义为:
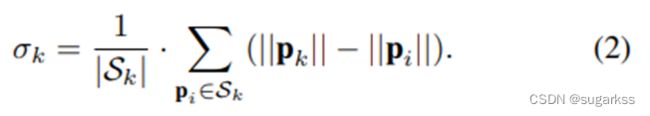
边缘特征由 σk 大的点定义,平面特征由 σk 小的点定义。
- 数据关联
对于每个边界特征点:
转换到局部地图中位置:![]()
来表示当前的位姿.
然后从酷不边界特征地图中找到两个最近的边界特征点 P1 P2
点到边残差计算公式为:
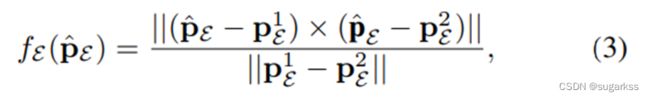
同样的方法,平面特征点: 
转换到局部地图中的位置: 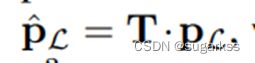
然后从局部平面地图中 找到最近的三个点
点到面的残差公式 计算可以表示为:

-
位姿估计
最后机器人位姿通过计算点到平面和点到边的残差和最小值 算出 T
本文通过高斯牛顿的方法解决非线性优化问题 -
特征地图更新和关键帧选择
一旦位姿优化解决,特征点将被更新到局部地图和平面地图当中。这些点将被用于一下帧的数据关联。
当平移或者旋转的值大于阈值时候,该帧将被选作关键帧。
D.全局地图构建
全局语义地图由静态地图和动态地图构成。视觉信息用于构建测色密集静态地图。
视觉信息能够反投影3D点到图像平面。
为防止内存溢出的问题 采用“3d is here: Point cloud library (pcl)
动态物体可以用高层次的任务 运动规划
实验
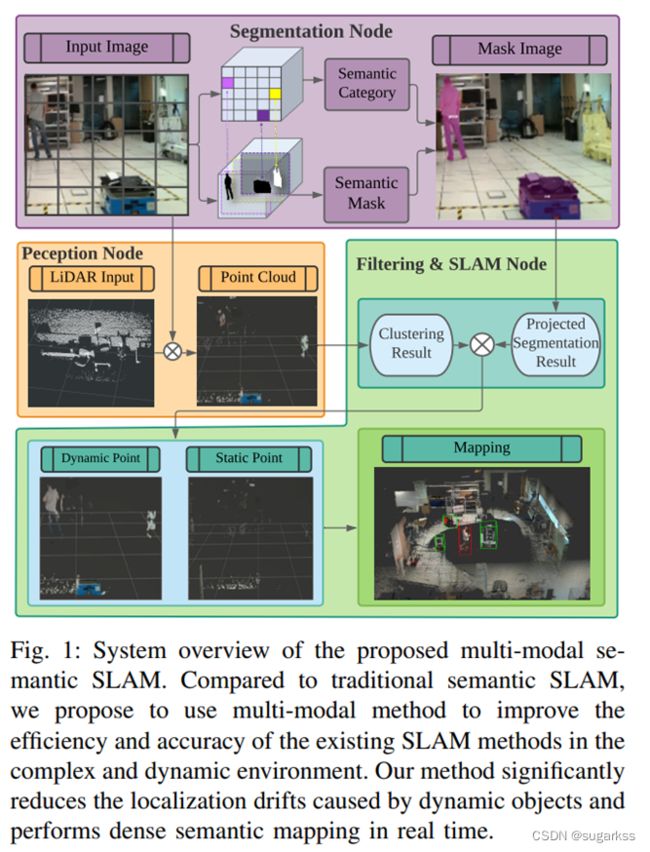
图一是多模态语义SLAM的整体框架
A. 实验设备介绍
B. 数据获取
从coco数据集中选取5000个人类图像
AGV 自动引导车获取了3000张图像
未解决数据少的问题,仿真生成图片:
使用的方法:Simple copy-paste is a strong data augmentation method for instance segmentation, CVPR2020
C. 评估实例分割性能
两个评估指标:分割损失、平均精度(mAP)
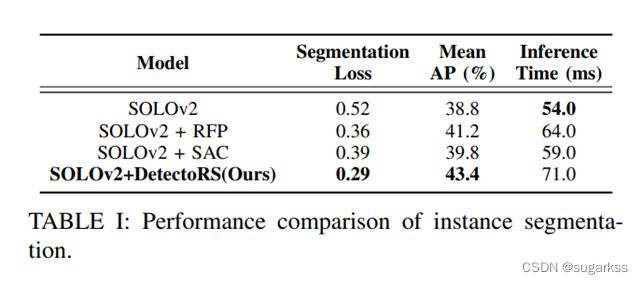
为了公平比较,所有模型都在相同的配置下进行训练,它们使用同步随机梯度下降进行训练,每个 minibatch 总共有 8 张图像,持续 36 个 epoch。

C. 稠密建图和动态跟踪
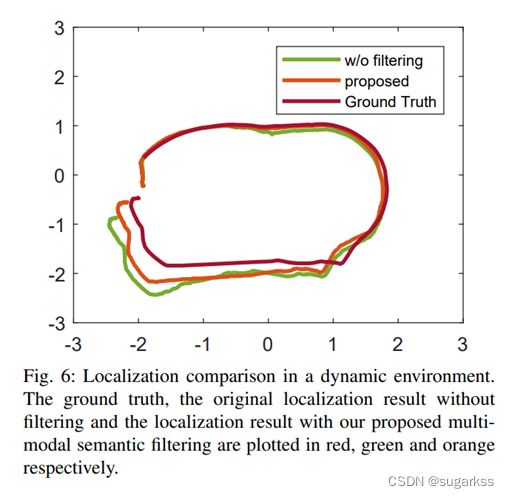
实验中,人工控制AGV走动,同时搭建仓库环境地图,人工操作人员在仓库内频繁行走。
定位结果 如图6所示
建图如 图5所示
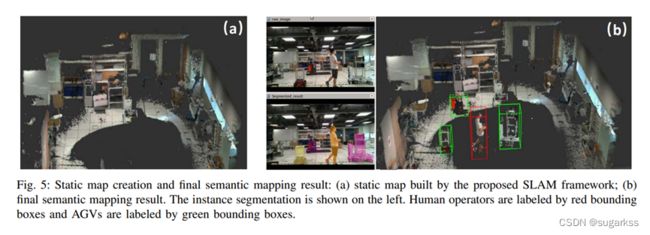
能够识别潜在移动的物体并且从静态地图中将其分离开来。
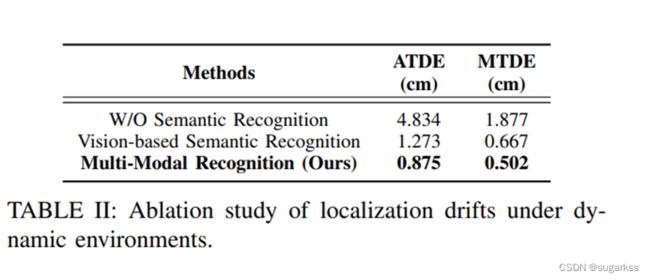
D. 定位漂移的消融实验 ablation study
总结及个人看法
本文的总结: 提出一种语义多模态的框架 处理 在动态环境中的SLAM问题,能够有效降低动态物体对系统的影响。
本方法旨在提供一个模块化管道,以允许在动态环境中的实际应用程序。同时,在去除动态信息的情况下,构建了一个 3D 密集的静态地图。
在智能工厂 仓库引导叉车 中测试
个人看法:
1、 摘要部分作者声称 与以往的动态SLAM不同 该框架是面向高度动态SLAM 的 但是从实验部分中并没有很好的提现 。测验环境也仅仅是在室内自动引导车场景。不是特别理解他的高度动态环境。
2、 对于本文对实例分割网络的改进工作点并不是特别理解 是否是一个创新点保持疑问!!!(由于不是高深度学习 并不了解这方面的知识点)
3、 对于实验室测试环境 作者测试环境并不是特别大,如果可以再大尺度场景下进行测试 ,更能说明该方法的优越性,尤其是本文也提到自动叉车是用在智能仓库的 想必仓库面积应该是比较大的。
以上仅是个人阅读笔记和个人心得!欢迎交流探讨!!!