强化学习1——基本概念、MDP、价值迭代、策略迭代、蒙特卡洛
最近在学伯禹人工智能的强化学习课程,做了一点记录,主要也是为了便于理解和回顾。
1.强化学习简介
1.1 基本概念
强化学习是通过从交互学习来实现目标的计算方法。其交互过程是,在每一步t中,智能体与环境进行交互:
智能体(agent):获得观察O_t,获得奖励R_t,执行动作A_t;
环境:获得行动A_t,给出观察O_{t+1},给出奖励R_{t+1};
以上这种交互的一个完整的过程,我们可以称之为历史(History),这是一串关于观察、奖励、行动的序列,是一串一直到时间t为的所有观测变量。
状态(State):是一种用于确定接下来会发生的事情(动作A、奖励R、观测O),状态是关于历史的函数。状态通常是整个环境的,所观察到的状态可以视为所有状态的一部分,仅仅是智能体agent可以观察到的那一部分。
策略(Policy):是学习智能体在特定时间下的状态的行为方式。即从状态到行为的映射。策略可以分为两种:确定性策略(函数表示)和随机策略(条件概率表示)。
奖励(Reward):一种度量,立即感知到什么是好的,一般情况下是一个标量。
价值函数(Value function):长远来看(long-term),什么是好的。价值函数是对于未来累计奖励的预测,用于评估给定策略下,状态的好坏。
环境的模型(Model):用于模拟环境的行为,预测下一个状态,预测下一个立即奖励(reward)。
策略与状态转移方程的区别:
(1)策略,是在状态s时,可能执行不同的动作a的各自的概率,是一个n*m的矩阵(n个状态,m个动作);

(2)状态转移方程,是在状态s下,执行一个确定的动作a后,转移到各个状态s’的概率,是一个nnm的张量(n个状态,m个动作)
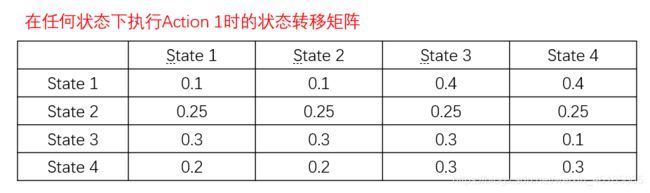
1.2 强化学习智能体agent的分类
强化学习大体可以分为两类:
(1)model-based RL(基于模型的强化学习):模型可以被环境所知道,agent可以直接利用模型执行下一步的动作,而无需与实际环境进行交互学习。
例如:围棋、迷宫、象棋等这类规则明确,且可以枚举下一个状态的所有可能(比如象棋黑方走了一步后,可以列举此时红方可能要走的棋子和要走的方式)
(2)model_free RL(模型无关的强化学习):真正意义上的强化学习,环境是黑箱,比如Atari游戏、王者荣耀游戏,其需要大量的采样。
强化学习的另外一种分类方式:
(1)基于价值:没有策略(隐含)、价值函数。通过估计价值,来推导出最优策略。
(2)基于策略:策略、没有价值函数。与基于价值的关系相反。
(3)Actor-Critic:策略、价值函数相辅相成
2 MDP——强化学习最基础的数学工具
2.1 MDP主要内容和性质
马尔科夫决策过程(Markov Decision Process,MDP):它提供了一套为在结果部分随机、部分在决策者的控制下的决策过程建模的数学框架。
MDP形式化地描述了一种强化学习环境,它的特点是环境完全可观测,即马尔科夫性质(当前状态可以完全表征过程,即根据当前状态,即可推演接下来的状态)。
马尔科夫性质:
“The future is independent of the past given the present.”
当前状态是St,如果给了之前的所有状态,来推演当前的下一个状态St+1,那么只要用到当前状态St,就可以推演出下一个状态St+1了。
数学表达: P[St+1|St] = P[St+1|S1,…,St]
特点:
(0)状态从历史中捕获了所有相关信息,St = f(Ht),即当前状态已经捕获了历史中的相关信息,并且映射为St;
(1)当状态已知的时候,可以抛开历史不管;
(2)当前状态是未来的充分统计量;
(3)MDP五元组;
2.2 MDP的表示
MDP可以由一个五元组表示(S,A,{Psa},γ,R),其中:
(1)S是状态的集合;
(2)A是动作的集合;
(3)Psa是状态转移概率(对每个状态s∈S和动作a∈A,Psa是下一个状态在S中的概率分布);
(4)γ∈[0,1]是对未来奖励的折扣因子,如果γ为1,则对未来的奖励和当前奖励是一样的重要程度;如果γ等于0,就不属于强化学习了,而是一种预测问题,即在什么状态下做什么动作,会对应什么奖励的这么一个二元预测问题。因此,正是由于这个γ,我们才能把预测问题和决策问题区分开;
注意:γ作为未来奖励的折扣因子,能使得和未来奖励相比起来,智能体更加重视即时奖励,以金融为例,今天的1美元,是比明天的1美元更有价值的,因为我们可以拿这一美元投资后,明天一定比一美元多。
(5)R:S×A–>R是奖励函数。
2.3 MDP的动态过程
(1)从状态s0开始;
(2)智能体选择某个动作a0∈A;
(3)智能体得到奖励R(s0,a0);
(4)MDP随机转移到下一个状态s1~Ps0a0,即s0通过Ps0a0的状态概率分布,转移到下一个状态s1;
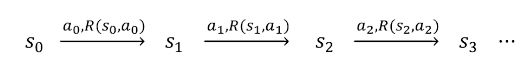
以上该过程不断进行,直到终止状态ST出现为止,或者无止尽地进行下去。
2.4 智能体计算MDP的总回报
2.3的过程执行到一定的状态后,我们需要计算当前状态下智能体的总回报,是一个关于智能体在每个状态得到奖励R(st,at)的函数,为了使这个总回报能够收敛,因此就需要折扣因子γ,这样总回报就是逐渐收敛到一个实数。所以智能体总回报可以用下面公式表示:
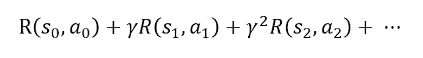
2.5 MDP奖励函数的简化
大部分情况下,奖励只和位置有关,如迷宫中奖励只和当前位置有关,与下一步要做什么动作往哪里走无关;围棋中奖励只基于最终围地大小有关。因此此时奖励函数可以简化为R(s):S–>R。
这样一来,MDP过程为:
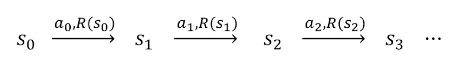
其累积奖励(即总回报)为:
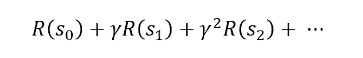
2.6 MDP的价值函数和Bellman等式,以及最优价值函数
MDP的目标是,选择能够最大化累计奖励期望的动作。注意,这里是期望值,这样能确保最后所得是一个确定的标量,是一个可以优化的东西。
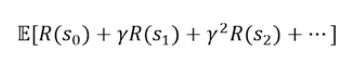
策略表示为
![]()
即在状态s下采取动作a的概率分布,这样就是一个策略。
对应这样一个策略Π(s),其价值函数,即累计奖励的期望,如下:
![]()
即给定起始状态,根据策略Π,采取动作时的累计奖励期望。
上述价值函数还可以变化成Bellman等式:
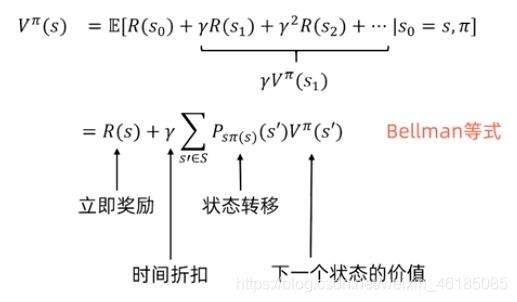
对于状态s来说,最优价值函数是所有策略中,可获得的最大可能的累计奖励。
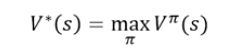
因此,最优价值函数的Bellman等式为:
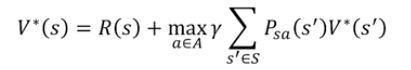
最优策略为
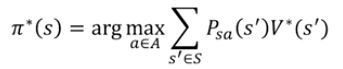
对状态s和策略Π,有如下不等式:
![]()
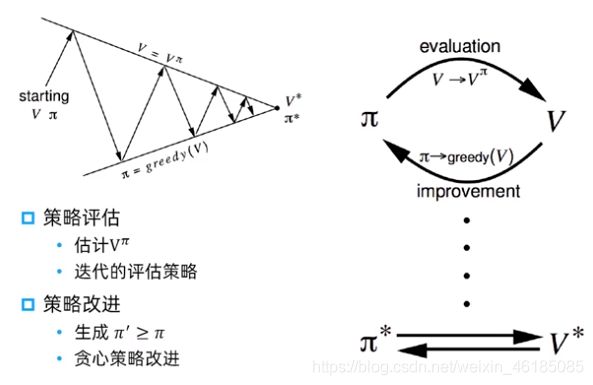
2.7 寻找最优策略的两种方法:价值迭代和策略迭代
价值函数和策略相关函数如下,可以看出价值和策略是息息相关的。
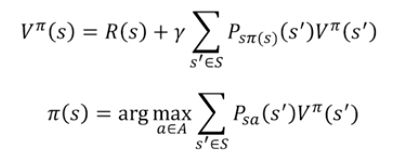
因此有两种求最优策略的迭代方法,分别是价值迭代和策略迭代。
2.7.1 价值迭代
价值迭代方法适用的环境:一个状态空间和动作空间有限的MDP。
价值迭代过程:
1.对每个状态s,初始化V(s) = 0;
2.重复以下过程直到收敛 {
对每个状态,更新其最优价值函数:
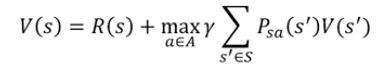
}
注意:在以上计算中没有明确的策略。
3.当最终这个价值函数收敛(即所有状态的价值函数收敛)时,根据策略的关系,计算出最优策略。
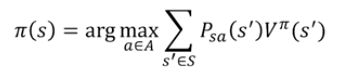
对于价值迭代,又分为同步价值迭代和异步价值迭代两种。
(1)同步价值迭代
同步的价值迭代会存储两份的价值函数的拷贝。
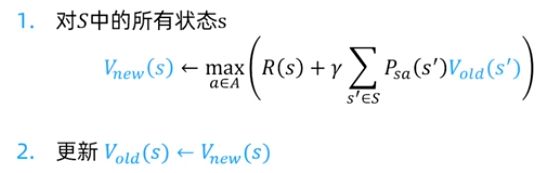
(2)异步价值迭代
异步价值迭代只存储一份价值函数
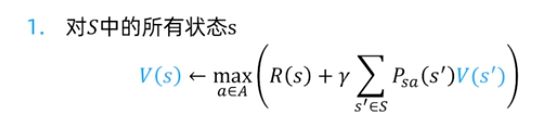
下面是一个价值迭代的一个例子:最短路径
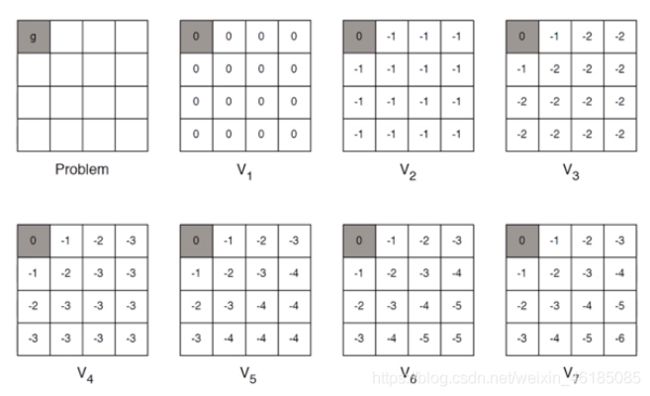
这里即时奖励值R为-1。
2.7.2 策略迭代
适用情况:对于一个状态空间和动作空间有限的MDP。
策略迭代的过程:
1.随机初始化策略Π;
2.重复以下过程直到收敛 {
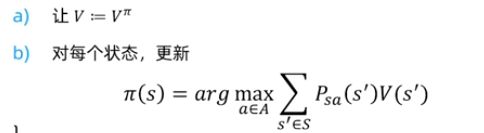
}
注意:在随机初始化策略Π后,会根据策略,计算出follow该策略的价值函数,(这是一个迭代计算的过程,具体例子见2.7.3),公式如下:
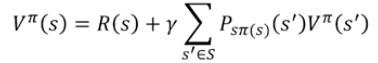
因此,价值迭代可以看成是迭代次数为1的策略迭代。
以上部分如有疑问,可以到这里
进行进一步学习
2.7.3 策略评估的一个例子
如图假设一个4*4矩阵,右下角和左下角是目标状态,其余格子分别代表一个状态,已知:
(1)非折扣MDP(γ = 1)
(2)非终止状态:1…14
(3)两个终止状态;
(4)如果有动作指向所有方格的外面,则这一步不动;
(5)奖励均为-1,直到终止状态;
(6)智能体的策略为均匀随机策略,即上下左右的动作概率各为0.25;
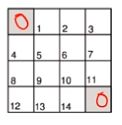
那么,策略评估的迭代过程如下:
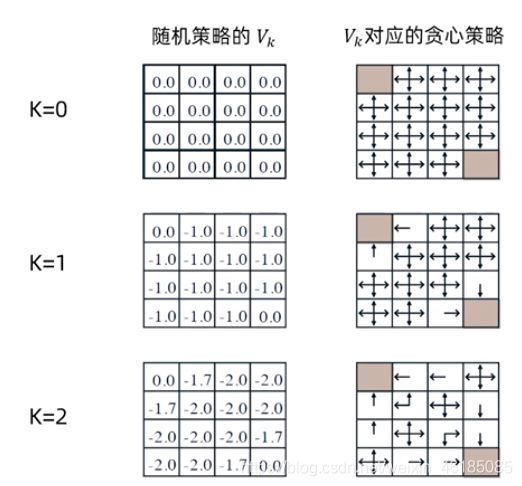
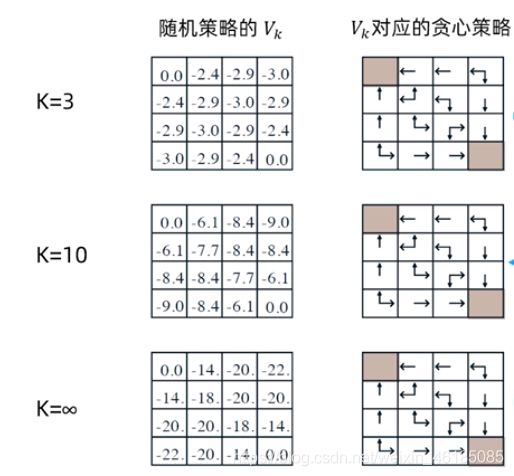
计算实例:
- k=2, -1.75约等于1.7 :0.25*(-1+0) + 0.25*(-1-1) + 0.25*(-1-1) + 0.25*(-1-1) = -1.75
- k=3, -2.9约等于-2.925 : 0.25*(-1-2) + 0.25*(-1-2) + 0.25*(-1-2) + 0.25*(-1-1.7)= -2.925
注意:上面这些过程,仅仅只是策略迭代过程的a)步骤,当最终价值函数收敛后,才开始进行策略的更行(策略更新这一步,在上面并未显示出来,右边的仅仅是通过贪心算法找到的策略而已)。
2.8 基于模型的强化学习
之前的讨论建立在一个已知的MDP模型的基础上,但是在实际问题中,状态转移和奖励函数一般不是明确给出的。
实际的学习中,只看到了一些episodes,是learning from interaction。
从“经验”中学习一个MDP模型:即学习状态转移概率Psa(s’)和学习奖励函数R(s)
算法:
1、随机初始化策略π
2、重复以下过程直到收敛
在MDP中执行π进行一些测验
使用MDP中的累积经验更新对Psa和R的估计
利用对Psa和R的估计执行价值迭代,得到新的估计价值函数V
根据V更新策略π为贪心策略
另一种解决方式是不学习MDP,从经验中直接学习价值函数和策略 (模型无关的强化学习)
3. 蒙特卡洛方法
实际问题中往往不会给出状态转移和奖励函数,只能观察到部分交互片段。
model-free RL:直接从经验中学习价值函数和策略,不建立MDP;其优势是1)直接;2)不用建立MDP,不会把估计MDP的错误传递给DP;
关键步骤,是估计值函数,这里常用到蒙特卡洛方法。
蒙特卡洛的概念:依赖于重复随机采样来获取数值结果。
例子:
(1)计算圆的面积:画一个正方形,和一个内切的圆形,撒一把豆子,统计圆内豆子和正方形内豆子的比值,大数定理。
(2)AlphaGo围棋对弈中估计当前状态下的胜率。
3.1 蒙特卡洛策略评估
使用当前策略从状态s采样N个片段,每个片段大致如下:
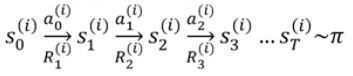
对于每个片段的累计奖励(return),称为总折扣奖励:
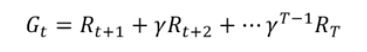
那么对于N个片段来说,就要计算平均的累计奖励,才最有代表性,当采样的片段越多,计算出来的平均的累计奖励就月接近于值函数(value function),即期望累计奖励。

注意:蒙特卡洛策略评估使用的是经验均值累计奖励,而不是期望累计奖励。
3.2 蒙特卡洛策略评估的实现方法
(1)使用策略Π采样N个片段;
(2)在一个片段中的每个实践步长t的状态s都被访问(every-visit MC methods):

还有另外一种计算每个片段的累计奖励的方法,称为first-visit MC methods,即在一个片段内,只记录s的第一次访问,并最终取平均。
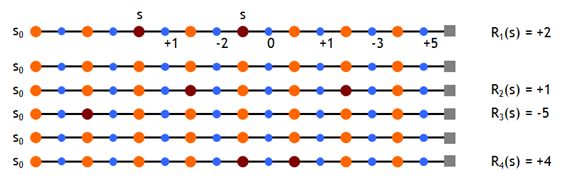
3.3 增量蒙特卡洛更新
增量蒙特卡洛更新,不使用S(s),每个片段结束后直接更新。对于每个状态St和对应的累计奖励Gt,有:
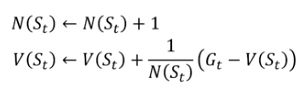
对非平稳问题(环境会随时间变化),跟踪现阶段平均值,不考虑过久之前的片段,因为刚开始的G_t可能会有比较大的方差:
![]()
具体实现往往是用这种非平稳问题的实现方法。
3.4 总结
(1)蒙特卡洛方法是直接用经验片段进行学习
(2)是模型无关的,未知MDP模型(状态转移概率分布和奖励函数);
(3)需要从完整片段学习,所有片段必须有终止状态,最好也不要太长,没有使用bootstrapping;(4)采用最简单的思想: 值(value) = 平均累计奖励(mean return)
(5)若想进一步,用蒙特卡洛方法评估出来的价值函数,进行价值迭代或者策略迭代,从而来更新优化策略,我认为仍然是不可行的,原因如下:
如果我们默认折扣因子为1,那么可能可以通过采样的方法,对即时奖励做平均然后估值,那么可以进行迭代,从而更新策略;但是,如果折扣因子不为1,那么将无法对即时奖励做估值,那么将无法更新价值函数,也就无法更新策略了。因此要有接下来了状态-动作值函数。
另外,即时奖励函数R,是来自环境的,因此它也不一定是一个标量,可能是一个函数,这个严格说起来,是需要建立一个环境模型的。
4.模型无关的控制方法
首先,我们要先理解强化学习中预测(prediction)和控制(control)两个名称的概念:
1)预测问题指的是求解给定策略(policy)下的价值函数(value function)的过程;
2)而控制问题指的是如何获得一个尽量好的策略来最大化乐基奖励(accumulated return)。
总结:强化学习过程常常是在解决预测问题的基础上,进而解决控制问题。
4.1 模型无关的控制能够解决的问题
例如电梯、围棋对弈、机器人行走等问题,可以被建模成马尔可夫决策过程,但这里存在两个特点:
(1)MDP模型为未知的时候,我们需要进行交互,从经验中采样;
(2)MDP模型为已知时,常常因为规模太大,导致利用动态规划求解耗时,只能通过采样方式处理。
以上特点可以用模型无关的控制进行优化处理。
4.2两类模型无关的强化学习
(1)在线策略学习(On-policy)
- Learning on the job;
- 利用策略Π的经验采样,不断学习改进策略Π;
- 利用当前的策略,与环境进行交互,然后进行采样,采样完后马上进行学习;
- 利用当前的策略,进行经验采样,采样出的数据一定是与当前策略有关的,即可以认为,训练数据和测试数据分布一致。(例如,一个推荐系统,给一个喜欢搞笑视频的人推荐搞笑视频这个策略,其用户反馈的数据也是关于搞笑视频)
(2)离线策略学习(Off-policy)
- Look over someone‘s shoulder;
- 利用另一个策略μ的经验采样,不断学习改进策略Π(从别人的经验中去学习);
- 这样就会导致训练数据的分布不一致的问题。
4.3 状态值和状态-动作值
这里解释一下,为什么要有状态值函数和状态动作值函数两个概念。虽然,在模型已知的时候,只用状态值函数就可以完全决定策略,一个状态值函数就可以表征强化学习的目标——最大化回报,但是在模型未知的时候,就必须估计每个动作的值,即状态动作值函数。状态动作值函数的估计方法,是在状态s下采用动作a,后续遵循策略Π获得的期望累计回报,即为状态动作值,实际运用中仍然用平均回报来估计。
累计奖励:
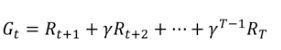
马尔可夫决策过程的状态值函数是指从状态s开始,执行策略Π的期望累计奖励:
![]()
马尔可夫决策过程的状态-动作值函数Q,是指从状态s开始,执行动作a后,执行策略Π的期望累计奖励:![]()
之前,状态值函数(即之前的价值函数,或其贝尔曼等式),被分解为即时奖励加上后续状态的折扣值:
![]()
同理,状态动作值函数Q也能被类似的进行分解:
![]()
我们可以这样来理解,状态动作值函数,是确定了s状态下的动作a后,计算的累计奖励。那么,将s状态下,遍历所有可能执行的动作a后,求和的累计奖励,就是状态值函数V了,公式如下:
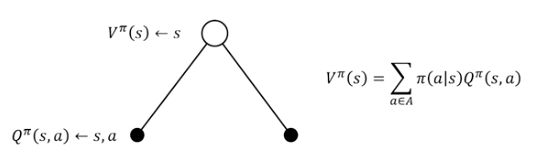
而状态动作值函数则等于,状态s下执行a动作后,环境的即时奖励R(s,a),加上状态s下执行a动作后,转移到各个状态s’的状态转移矩阵乘以下个状态s’的所有动作下的状态动作值函数之和,即状态s‘的状态值函数,然后在乘上折扣因此γ即可,公式如下:
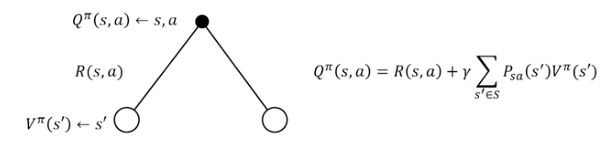
4.4 模型无关的策略迭代
这里又回到off-policy中,由于off-policy中,是利用另一个策略μ的经验采样,不断学习改进策略Π(从别人的经验中去学习)。因此用这种其他分布的数据,去不断学习和改进策略Π的情况,就需要用到状态动作值函数。
为什么不能用状态值函数(价值函数)V呢?这是因为价值迭代方法中,需要知道即时奖励函数R和状态转移概率Psa(s’),而我们不知道,即马尔可夫模型未知。当然,我们也可以根据采集的片段,对R和P进行估值,然后基于状态值函数V(s)的贪心策略改进,但是那就属于基于模型的强化学习了,而我们现在说的是模型无关的强化学习。

这样一来,我们就需要基于状态-动作值函数Q的贪心策略改进,它是模型无关的。而这个Q(s,a)状态动作值函数的估计方法,是在状态s下采用动作a,后续遵循策略Π获得的期望累计回报,即为状态动作值,实际运用中仍然用平均回报来估计。
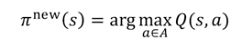
整体来看,如下图所示,我们可以称之为状态-动作值函数的广义策略迭代,在这个过程中:(1)策略评估部分,就是用蒙特卡洛策略评估,即在状态s下采用动作a,后续遵循策略Π获得的期望累计回报,即为状态动作值,实际运用中仍然用平均回报来估计;(2)策略改进部分,用的是贪心策略,即上一个公式。
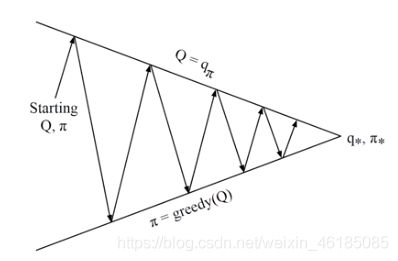
4.4 让策略迭代时仍然保持持续探索的方法——ε-greedy方法
前面我们讲到,我们通过一些样本来估计Q和V,并且在未来执行估值最大的动作。这里就存在一个问题,假设在某个确定状态s0下,能执行a0, a1, a2这三个动作,如果智能体已经估计了两个Q函数值,如Q(s0,a0), Q(s0,a1),且Q(s0,a0)>Q(s0,a1),那么它在未来将只会执行一个确定的动作a0。这样我们就无法更新Q(s0,a1)的估值和获得Q(s0,a2)的估值了。这样的后果是,我们无法保证Q(s0,a0)就是s0下最大的Q函数。
再举个例子,对左右两个随机盒子进行选择,左边盒子中有20%的奖励是0,80%的奖励是5,所以期望奖励是4;右边盒子中有50%奖励是1,50%奖励是3,所以期望奖励是2。假设,第一次选择人左边的门,且观测到奖励为0,那么之后的选择就会一直是右边这个盒子,即使左边这个的盒子期望值最大。因此,如果没有不断的探索,策略将是次优的。
持续探索的思想很简单,就是用soft policies来替换确定性策略,使所有的动作都有可能被执行。比如其中的一种方法是ε-greedy policy,即在所有的状态下,用1-ε的概率来执行当前的最优动作a0,ε的概率来执行其他动作a1, a2。这样我们就可以获得所有动作的估计值,然后通过慢慢减少ε值,最终使算法收敛,并得到最优策略。公式表达如下,假设共有m种动作,那么就以1-ε+ε/m的概率选择贪心动作,以ε/m的概率随机选择一个动作。这里ε是一个参数,越大表示探索的能力越强。
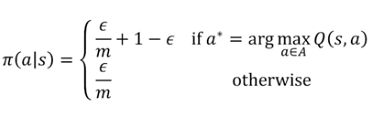
下面是一个ε-greedy策略改进的证明,
![]()
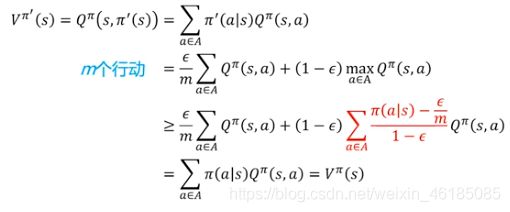
红色这块不太好理解,我自己理解的也不是很透彻,所以暂且不解释,免得误导大家,有看懂的大佬,可以分享一下,感激不尽。
4.5 蒙特卡洛(MC)和时序差分(TD)(后面会讲)的比较
蒙特卡洛的优势:1)不需要建模value function;2)对机制的采样时unbiased;3)算法实现比较简单;
时序差分的优势:1)不需要整个片段的采样,而蒙特卡洛需要,且时序差分可以在无终止状态的片段下学习,蒙特卡洛不可以;2)一般效果比蒙特卡洛要好,应用更广泛;3)方差更低。
因此,总体上,在控制中,时序差分(TD)能代替蒙特卡洛:
1)使用时序差分来更新状态动作值Q;
2)使用ε-greedy进行策略改进;
3)每个事件步长更新状态-动作值函数;