03 Numpy基础入门
Numpy核心功能
Numpy(Numercial Python)是高性能科学计算与数据分析基础包,其核心功能如下:
1. 多维数组计算(ndarray)
2. 矩阵计算(matrix)
3. 矢量化计算(直接操作矢量,无需循环结构)
4. 高效文件存取(读写磁盘以及内存映射文件等)
5. 数学工具(线性代数,随机数,傅立叶变换等)
6. 集成C、C++、Fortran代码(第三方扩展,提高数据处理性能)
Numpy核心概念
维度和轴
Numpy中的维度概念是指数据的嵌套组织形式,例如,最简单的一维数组 [1,2,3],如果将一维数组中的每一个元素都替换为一个一维数组,那么就形成了一个二维数组,例如[[1,1,1],[2,2,2],[3,3,3]]。继续推广,将二维数组中的每一个元素再替换为一个一维数组,将形成一个三维数组,依次类推。从多维数组的形成过程中可以看出,对一维数组中的元素进行扩充就得到二维数组,对二维数组中的元素进行扩充就得到三维数组。同时规定用0轴表示多维数组的第一个维度,用1轴表示多维数组的第二个维度,用N-1轴表示多维数组的第N维度。也就说一个N维度数组,轴的编号最大是N-1。类比于平面直角坐标系,坐标系中的任意点M(Xi,Yj)都可以看作是二维数组中的一个数据点,坐标系X轴、Y轴分别相当于二维数组的0轴和1轴,点M的坐标(Xi,Yj)表示数据点M在0轴上的上的轴索引为i,在1轴上的轴索引为j

如果选取平面上的点集合组成一个二维数组XYArray,那么M点就可以表示为XYArray[i][j],从左到右的[ ]表示数据M在二维数组的0轴到N轴上的刻度,或者叫做轴索引。每一个维度都对应一个轴,轴上的索引值从0开始,轴上的最大索引值等于轴长度-1
轴主编号与轴次编号
如果将轴的概念进行细化,XYArray可以说有1个0轴,3个1轴,分别可以称之为1-0、1-1、1-2,其中1可以称之为轴主编号,-0、-1、-2可以称之为轴次编号,表示该轴上的元素在低维度空间中的轴索引,如果该轴所在的外维度空间大于1,那么轴次编号可以按照层次化方式表示,如2-0|1,表示主编号是轴2,对应数据的第三维度,该轴上的数据在第二维度上的索引是0,在第一维度上的索引是1(即轴次编号层次排列按照从高维度到低维度排列方式)
投影
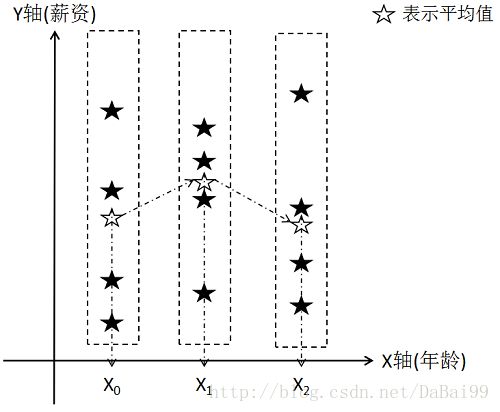
多维数组中,对某一个轴进行运算后,将计算的结果值映射到轴次编号对应的低维度空间中的过程可以称之为投影,投影过程的意义在于保证数据信息的完整性,因为参与计算的轴上元素本身就有外部维度空间的属性信息,所以映射到外部维度后,可以保证计算结果的外部维度信息,更好的分析计算得到的结果。
例如y轴是薪资,x轴是年龄,比如在y轴计算完平均工资后,将计算结果投影到x轴进行分析才更有意义,可以得出例如年龄为x0值时的平均薪资,或者当年龄增大后,平均薪资的变化等等统计信息:
ndarray
ndarray对象是Numpy中的核心概念,是一种通用的“同构数据”、“多维数据”容器, 同构说明了ndarray中存储的数据的类型必须是相同的,(如字符串、int、Object等任意类型),同时ndarray支持在多维度上组织数据,维度的概念在ndarray中体现为ndarray形状。一个ndarray对象可以用以下属性来描述:
1. 数组形状:shape (N1,N2, ...),N1,N2依次表示ndarray在第一维度(0轴),第二维度(1轴)上的元素个数
2. 数组元素数:size 元素个数
3. 数组元素类型;dtype,用于描述数组中存储的元素的实际类型
ndarray中元素的访问遵循多维数组的元素访问方式,使用[ ]来在各个轴上确定轴索引,最终定位到具体的数组元素。ndarray中使用[ ]的嵌套形式表示多维数据,如ndarray[ [ [ ] ] ],外层的[ ]表示低维度轴,嵌套层次越深的[ ]表示的维度轴越大。在访问ndarray对象的元素时,既可以使用”;”号分割轴编号,也可以使用并列的[]来分割轴编号,
如ndarray[index_axis0][index_axis1][index_axis2] <=> ndarray[index_axis0;index_axis1;index_axis2]
import numpy as np
ndarrayObject = np.arange(12).reshape((3,4))
print(ndarrayObject)
print(type(ndarrayObject[0]))
print(ndarrayObject.dtype)
print(ndarrayObject.shape)
print(ndarrayObject.size)[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
int32
(3, 4)
12
从ndarray的打印形式再谈维度、轴概念:
- ndarrayObject是一个二维数组
- 第一个维度含有三个数据,即轴0的长度为3
- 第二个维度含有四个数据,即轴1的长度为4
- ndarrayObject[0]的元素类型为一个ndarray(嵌套)
- ndarrayObject的数据类型为int
- ndarrayObject的形状是(3,4)
- ndarrayObject的大小是12
矢量化
相同形状的数组之间的运算称为数组的矢量化运算,矢量化运算的规则是多维数组中对应相同位置上的元素进行运算后,作为结果数组中对应位置上的元素,也就是说结果数组的形状与原始参与运算的数组的形状是相同的,矢量化运算大大简化了数据分析过程中的代码量,可以有效降低循环结构的使用频率。
import numpy as np
def test_numpy_ndarray():
arr1 = np.array([[1,2,3],[4,5,6]])
arr2 = np.array([[7,8,9],[10,11,12]])
arr3 = arr1+arr2
print(arr1)
print(arr2)
print(arr3)%time test_numpy_ndarray()[[1 2 3]
[4 5 6]]
[[ 7 8 9]
[10 11 12]]
[[ 8 10 12]
[14 16 18]]
Wall time: 3.01 ms
使用python内置的list来完成同样的操作:
def test_list_array():
list1 = [[1,2,3],[4,5,6]]
list2 = [[7,8,9],[10,11,12]]
list3 = list1+list2
list3_vec = []
for i in range(2):
list_internal = []
for j in range(3):
list_internal.append(list1[i][j]+list2[i][j])
list3_vec.append(list_internal)
print(list1)
print(list2)
print(list3)
print(list3_vec)%time test_list_array()[[1, 2, 3], [4, 5, 6]]
[[7, 8, 9], [10, 11, 12]]
[[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]]
[[8, 10, 12], [14, 16, 18]]
Wall time: 1 ms
广播
不同形状且广播兼容的数组之间的运算称之为广播,广播机制满足了不同形状数组之间的运算需求,这里仅仅介绍简单的广播示例,详细的广播内容将在Numpy高级进阶章节中介绍
import numpy as np
arr1 = np.eye(5)
print('*************arr1***************************')
print(arr1)
list2 = [5]
print('*************arr1*list2*********************')
print(arr1*list2)
arr2 = np.array(list2)
print('*************arr1*arr2**********************')
print(arr1*arr2)
print('*************arr1*np.array([2,3])***********')
print(arr1*np.array([2,3]))*************arr1***************************
[[ 1. 0. 0. 0. 0.]
[ 0. 1. 0. 0. 0.]
[ 0. 0. 1. 0. 0.]
[ 0. 0. 0. 1. 0.]
[ 0. 0. 0. 0. 1.]]
*************arr1*list2*********************
[[ 5. 0. 0. 0. 0.]
[ 0. 5. 0. 0. 0.]
[ 0. 0. 5. 0. 0.]
[ 0. 0. 0. 5. 0.]
[ 0. 0. 0. 0. 5.]]
*************arr1*arr2**********************
[[ 5. 0. 0. 0. 0.]
[ 0. 5. 0. 0. 0.]
[ 0. 0. 5. 0. 0.]
[ 0. 0. 0. 5. 0.]
[ 0. 0. 0. 0. 5.]]
*************arr1*np.array([2,3])***********
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
in ()
10 print(arr1*arr2)
11 print('*************arr1*np.array([2,3])***********')
---> 12 print(arr1*np.array([2,3]))
ValueError: operands could not be broadcast together with shapes (5,5) (2,)
再谈维度和轴
多维数组中,在那一个轴向上做运算,其实就是对该轴所对应的* 维度中包含的全部元素 进行操作,操作的过程中再结合 矢量化运算法则、广播机制 来处理被计算维度内部元素仍是 多维数组类型的元素 ,最后将计算得到的结果值 投影 *到被计算轴轴次编号对应的低维度空间中(如果被计算轴不存在次编号则不必投影,如0轴),轴上元素的计算结果值根据计算种类的不同所得到的结果类型也是不同的,如果计算是聚合类型的,如对轴上元素求平均值、求和等操作,则得到的结果值类型为标量,那么最终得到的结果数组维度将比原始数组的维度减少1,如果计算是简单变化类型的,如轴上元素全部增加1等,则得到的结果值类型与轴上元素的类型相同,那么最终得到的结果数组的维度与原始数组维度相同。
import numpy as np
arr = np.arange(12).reshape((3,4))
print('**********arr*****************')
print(arr)
print('**********arr.sum(0)**********')
print(arr.sum(0))
print('**********arr.sum(0)**********')
print(arr)**********arr*****************
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
**********arr.sum(0)**********
[12 15 18 21]
**********arr.sum(0)**********
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
使用array_sum_axis_0函数来模拟在轴0上做求和运算,即遍历arr在第一维度上的所有元素,并进行求和,因为不存在外部维度空间所以不必映射。因为arr是一个二维数组,所以第一维度中的元素类型是一维数组,所以求和的过程本质上是在一维数组元素间的矢量化运算,得到的结果[12 15 18 21]并不是映射的产物,而是因为一维空间中的元素本身就是多维数组类型,所以经过矢量运算后仍然是数组类型
def array_sum_axis_0(arr):
result = None
for index in np.arange(arr.shape[0]):
if index == 0:
# result = arr[index]
# 注意,这里result仅仅是arr数组的一个视图,如果修改result将导致arr的内容的修改,视图问题同样将在
# Numpy高级进阶章节中讲解,这里使用copy方法进行深复制
result = arr[index].copy()
else:
result+=arr[index]
return result
result = array_sum_axis_0(arr)
print('****array_sum_axis_0(arr)*****')
print(result)
print('**********arr.sum(0)**********')
print(arr)****array_sum_axis_0(arr)*****
[12 15 18 21]
**********arr.sum(0)**********
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
使用array_sum_axis_1函数来模拟在轴1上做求和运算,即遍历所有的轴1中的元素,并进行求和,因为存在外部维度空间,也就是轴1存在轴次编号,所以在进行求和运算后需要将计算的结果投影到低维度空间中。因为arr本身就是一个二维数组,所以第二维度中的元素的类型是普通的标量数据,所以求和过程本质上是在标量之间的加法操作,注意,在轴1上的求和过程最重要的步骤就是维护轴次编号并做好最后计算结果的投影。
print(arr.sum(1))[ 6 22 38]
def array_sum_axis_1(arr):
result = []
for axis1_minor_num in range(arr.shape[0]):
axis_1_sum_per_minor = 0
for var in arr[axis1_minor_num]:
axis_1_sum_per_minor+=var #轴1中的标量求和
result.append(axis_1_sum_per_minor) # 将计算得到的标量值投影到低维度空间中
return result
result = array_sum_axis_1(arr)
print(result)[6, 22, 38]
如果对数组进行在某个轴向上做数乘操作且这个轴向所对应的维度中的元素类型仍然是数组类型,则将涉及到广播机制,例如对二维数组在轴0上做加1操作,本质上就是在一维数组上加1,遵循广播机制
print(arr)[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
def element_add(var):
print('var type is:',type(var))
print('var contents:\n',var)
return var+1
def elememt_sum(var):
print('var type is:',type(var))
print('var contents:\n',var)
return np.sum(var)
# 在给定的轴向上应用函数,这里对函数np.sum进行封装,以便于查看numpy在底层是怎么传递数据的
np.apply_along_axis(elememt_sum,arr=arr,axis=0)var type is:
var contents:
[0 4 8]
var type is:
var contents:
[1 5 9]
var type is:
var contents:
[ 2 6 10]
var type is:
var contents:
[ 3 7 11]
array([12, 15, 18, 21])
由以上的代码输出结果可以看出,numpy在底层传递数据的时候,会自动的将给定轴向上的元素内容按照其他轴的轴主编号以及轴次编号进行切片分组,并将分组传递给应用函数,被划分进都同一分组中的元素属于在被计算轴上各个元素的对应位置上的元素,直接在已经分好组的数组上应用计算函数即可。所以,可以认为数组ndarray在指定轴向上的矢量化运算本质是先按照非计算轴的轴主编号和轴次编号将数据进行切片分组,并在已经分组的数组上应用运算函数的过程
arr2 = np.arange(18).reshape((2,3,3))
print(arr2)
np.apply_along_axis(elememt_sum,arr=arr2,axis=0)[[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]]
[[ 9 10 11]
[12 13 14]
[15 16 17]]]
var type is:
var contents:
[0 9]
var type is:
var contents:
[ 1 10]
var type is:
var contents:
[ 2 11]
var type is:
var contents:
[ 3 12]
var type is:
var contents:
[ 4 13]
var type is:
var contents:
[ 5 14]
var type is:
var contents:
[ 6 15]
var type is:
var contents:
[ 7 16]
var type is:
var contents:
[ 8 17]
array([[ 9, 11, 13],
[15, 17, 19],
[21, 23, 25]])
视图
视图是数组的一种逻辑表现方式,视图仅仅是对原始数组在逻辑上的一种展示形式,并不会对原始的数组数据进行复制,对视图的修改将直接影响原始数组数据。数组的视图模型类似于数据库中的数据库视图概念,视图的构建理论依赖于ndarray对象的底层实现原理,将在numpy高级进阶中进行讲解
维度信息表现形式
其实,在多维数组中,嵌套程度最深的维度的信息体现在数据值上,外部维度相当于给数据定义分类,所以要研究某维度上的数据,就应该把这个维度交换到多维数组的最内部。numpy中定义swapaxes函数来交换两个轴(即交换两个维度),Pandas中提供更高级的封装函数unstack 、stack来实现维度的交换。例如在Pandas的DataFrame数据结构中,列Column定义轴1,即第二维度,所以列属性定义了DataFrame数据的实际含义。维度在交换时,如果维度在嵌套层次的最里边,则维度表示的信息体现为数据值,如果维度在外部层次,则维度的信息体现为轴索引值,轴索引值的功能在于为最内部维度定义的数据提供分类标准
Numpy数据类型
numpy的核心数据结构ndarray类中存在一个数据类型属性dtype,数据类型的信息就存储在该dtype对象中,dtype对象中维护的信息决定了ndarray对象如何对内存数据进行解释,常用的numpy数据类型如下:
| 类型 | 类型代码 | 说明 |
|---|---|---|
| int8、uint8 | i1、u1 | 有符号、无符号8位整型(占1字节) |
| int16、uint16 | i2,u2 | 有符号、无符号16位整型(占2字节) |
| int32、unit32 | i4、u4 | 有符号、无符号32位整型(占4字节) |
| int64、uint64 | i8、u8 | 有符号、无符号64位整型(占8字节) |
| float16 | f2 | 半精度浮点数 |
| float32 | f4或f | 标准单精度浮点数,与C语言中的float类型兼容 |
| float64 | f8或d | 标准双精度浮点数,与C语言中的double和python中的float对象兼容 |
| float128 | f16或g | 扩展精度浮点数 |
| complex64 complex128 complex256 |
c8 c16 c32 |
分别用两个32位,64位,128位浮点数表示的复数 |
| bool | ? | 存储True和False值的布尔类型 |
| object | O | Python对象类型 |
| string_ | S | 固定长度的字符串类型,每个字符占一个字节,例如,要创建一个长度为10 的字符串,应该使用S10,且只能表示英文 |
| unicode_ | U | 固定长度的unicode类型(字节数由平台决定) |
与类型最相关的函数就是ndarray的类型转换函数astype,使用astype函数可以将原始数据转为指定的dtype类型
import numpy as np
arr1 = np.array([['ab','cd'],['ef','gh'],['ij','kl'],['mn','op']])
arr2 = arr1.astype('S1')
arr3 = arr1.astype('S2')
arr4 = arr1.astype('S4')
import inspect, re
def varname(p):
for line in inspect.getframeinfo(inspect.currentframe().f_back)[3]:
m = re.search(r'\bvarname\s*\(\s*([A-Za-z_][A-Za-z0-9_]*)\s*\)', line)
if m:
return m.group(1)
def print_ndarray_info(arrList):
for array in arrList:
print('*******************')
print('数组元素类型:',array.dtype)
print('数组元素长度:',len(array[0][0]))
print('数组内容;\n',array)
print('数组对象大小:',array.size)
print('数组占字节数:',array.nbytes)
print_ndarray_info([arr1,arr2,arr3,arr4])*******************
数组元素类型: Numpy通用函数
np.array方法
使用numpy的顶级函数array可以创建ndarray对象
arr1 = np.array([1,2,3,4])
arr2 = np.array([[1,2,3],[4,5,6]])
arr3 = np.array([[1,2,3],[4,5,6,[1,2,3]]])
arr4 = np.array([[[1,2,3],[1,2,3],[1,2,3]],[[1,2,3],[1,2,3],[1,2,3]],[[1,2,3],[1,2,3],[1,2,3]]])
def show_array_info(arr):
print('***********************')
print('数组类型:',type(arr))
print('数组dtype:',arr.dtype)
print('数组dtype字节:',arr.dtype.itemsize)
print('数组形状:',arr.shape)
print('数组维度:',len(arr.shape))
print('数组字节:',arr.nbytes)
print('数组大小:',arr.size)
show_array_info(arr1)
show_array_info(arr2)
show_array_info(arr3)
show_array_info(arr4)***********************
数组类型:
数组dtype: int32
数组dtype字节: 4
数组形状: (4,)
数组维度: 1
数组字节: 16
数组大小: 4
***********************
数组类型:
数组dtype: int32
数组dtype字节: 4
数组形状: (2, 3)
数组维度: 2
数组字节: 24
数组大小: 6
***********************
数组类型:
数组dtype: object
数组dtype字节: 8
数组形状: (2,)
数组维度: 1
数组字节: 16
数组大小: 2
***********************
数组类型:
数组dtype: int32
数组dtype字节: 4
数组形状: (3, 3, 3)
数组维度: 3
数组字节: 108
数组大小: 27
np.zeros、np.zeros_like、np.ones,np.ones_like、
np.empty、np.empty_like、eye、identity方法
| 函数名 | 说明 |
|---|---|
| np.zeros | 根据指定的shape(元组)创建一个全0数组 |
| np.zeros_like | 根据传入的数组,创建一个shape形状相同、dtype数据类型相同的全0数组 |
| np.ones | 根据指定的shape(元组)创建一个全1数组 |
| np.ones_like | 根据传入的数组,创建一个shape形状相同、dtype数据类型相同的全1数组 |
| np.empty | 根据指定的shape(元组)创建一个未初始化数组 |
| np.empty_like | 根据传入的数组,创建一个shape形状相同、dtype数据类型相同的未初始化数组 |
| eye、identity | 创建单位对角二维数组,对角线上元素全部为1,其余元素为0 |
np.asarray方法
将输入对象转变为numpy.ndarray,如果原始数据本身就是ndarray,则不进行复制(充分体现了numpy追求内存使用效率的设计思想)
#print(help(np.asarray))np.arange
np.arange函数类似于Python内置函数range,返回指定范围的整数数组,np.arange函数一次性将全部的元素返回,而range函数返回的是一个可迭代对象,只有在真正访问到元素值的时候元素才被真正创建
arr1 = np.arange(10).reshape(2,5)
print('arr1 类型:\n',type(arr1))
arr2 = range(10)
print('arr2 类型:\n',type(arr2))arr1 类型:
arr2 类型:
数组转置与轴对换
数组转置函数transpose或T属性可以获取转置数组,高维数组中transpose函数需要传入一个轴编号元组,表示将元组中的轴进行对调,也可以使用ndarray.swapaxes来完成
import numpy as np
arr = np.arange(12).reshape(3,4)
print(arr)
print(arr.transpose())
print(arr.swapaxes(1,0))
print(arr.swapaxes(0,1))
print(arr.T)[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
numpy常用函数汇总
| 函数 | 说明 |
|---|---|
| abs、fabs | 计算整数,浮点数或复数的绝对值,对于非复数数值,可以使用更快的fabs |
| sqrt | 计算各元素的平方根,相当于arr**0.5 |
| square | 计算各元素的平方,相当于arr**2 |
| exp | 计算各元素的指数e的x次幂 |
| log、log10、log2、log1p | 分别为自然对数(底数为e),底数为10的对数,底数为2的对数,底数为1+x的对数 |
| sign | 信号函数,计算各个元素的正负号(正数,1) 、(零,0)、(负数,-2) |
| ceil | 计算各元素的ceiling值,即大于等于该值的最小整数 |
| floor | 计算各元素的floor值,即小于等于该值的最大整数 |
| rint | 将各元素值四舍五入到最接近的整数,保留dtype |
| isnan | 返回一个表示“哪些值是NaN”的布尔型数组 |
| isfinite、isinf | 返回一个表示哪些值是有穷的或哪些元素是无穷的布尔型数组 |
| cos、cosh、sin、sinh、tan、tanh | 普通型和双曲型三角函数 |
| arccos、arccosh、arcsin、arcsinh、arctan、arctanh | 反三角函数 |
| logical_not | 计算各个元素not x的真值,相当于-arr |
| add | 数组矢量化加法 |
| subtract | 数组矢量化减法 |
| multiply | 数组矢量化乘法(注意其与np.dot点乘方法的不同) |
| divide、floor_divide | 除法或向下圆整除法(丢弃余数) |
| power | 矢量化幂乘(对第一个数组中的元素A,根据第二个数组中的相应元素B,计算A的B次幂) |
| maximum、fmax | 元素级的最大值计算,fmax将忽略NaN |
| minimum,fmin | 元素级的最小值计算,fmin将忽略NaN |
| mod | 元素级的求模计算,即除法的余数 |
| copysign | 将第二个数组中的值的符号赋值给第一个数组中的值 |
| greater、greater_qual、less、less_equal、equal、not_equal | 执行元素级的比较运算,产生布尔型数组 |
| logical_and、logical_or、logical_xor | 执行元素级的真值逻辑运算 |
Numpy索引与切片
切片
切片是一种数据的访问方式,可以认为是传统的数组索引访问机制的升级版本,切片提供更加高级灵活的语法,切片操作产生的是原始数据的一个视图,对于切片选区上的数据进行修改会直接体现在原始数据上,如果需要返回数据的拷贝副本,则可以调用返回视图的copy方法(其实视图的类型就是numpy.ndarray类型,所以就是调用ndarray的copy方法获取数据副本)。这点与python内置的list切片不同,对list切片产生的是数据副本。
list1 = [1,2,3,4]
list2 = list1[0:2]
print('list1:\n',list1)
print('list2:\n',list2)
list2[0] = 123
print('list1:\n',list1)
print('list2:\n',list2)list1:
[1, 2, 3, 4]
list2:
[1, 2]
list1:
[1, 2, 3, 4]
list2:
[123, 2]
import numpy as np
arr1 = np.arange(12).reshape(3,4)
print(arr1)
arr2 = arr1[0]
print('视图arr2的类型:',type(arr2))
arr2[1] = 123
print('arr2:\n',arr2)
print('arr1:\n',arr1)[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
视图arr2的类型:
arr2:
[ 0 123 2 3]
arr1:
[[ 0 123 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
数组切片访问语法
数组切片语法原语形如ndarray[start_axis0 : end_axis0 : step_axis0 , start_axis1 : end_axis1 : step_axis1 , … ],内部使用‘,’来分割维度选择器,对应的维度从左到右依次升高,其中start为该轴上的起始轴索引闭区间点,start的默认值等于0, end为该轴上的终止轴索引开区间点,end的默认值等于该轴向上的** 最大索引值+1 ,**step为轴索引的跃进步长,默认情况下为1,因为切片返回的是原始数据的视图,类型同样为ndarray,所以可以继续使用切片语法对返回的视图数据再次切片
注意:
- 切片语法必须满足start不断的加上step后最终能够经过end指定的轴索引位置,否则将被视为错误的切片语法,返回[ ]
- 当start或end为负数的时候,表示该轴向上的逆向轴索引
- 当step为负数的时候,表示负数步长
import numpy as np
arr = np.arange(30).reshape(5,6)
def show_arr(name,arr):
print(name,':\n',arr,'\n *********************')
show_arr('arr',arr)
show_arr('arr[0:3]',arr[0:3])
show_arr('arr[::,0:3]',arr[::,0:3])
show_arr('arr[0:3,0:3]',arr[0:3,0:3])
show_arr('arr[0::2]',arr[0::2])
show_arr('arr[::,::]',arr[::,::])
show_arr('arr[:,:]',arr[:,:])
show_arr('arr[:,]',arr[:,])
show_arr('arr[::-1,]',arr[::-1,])
show_arr('arr[:,::-1]',arr[:,::-1])
show_arr('arr[0:3:-1]',arr[3:0:-1])
show_arr('arr[0:3:1]',arr[3:0:1])
show_arr('arr[-1:3:1]',arr[-1:-3:1]) # 注意,切片语法必须满足start不断的加上step后最终能够大于end,否则将被视为错误的切片语法,返回[]
show_arr('arr[-1:-3:-1]',arr[-1:-3:-1])arr :
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]
[24 25 26 27 28 29]]
*********************
arr[0:3] :
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]]
*********************
arr[::,0:3] :
[[ 0 1 2]
[ 6 7 8]
[12 13 14]
[18 19 20]
[24 25 26]]
*********************
arr[0:3,0:3] :
[[ 0 1 2]
[ 6 7 8]
[12 13 14]]
*********************
arr[0::2] :
[[ 0 1 2 3 4 5]
[12 13 14 15 16 17]
[24 25 26 27 28 29]]
*********************
arr[::,::] :
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]
[24 25 26 27 28 29]]
*********************
arr[:,:] :
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]
[24 25 26 27 28 29]]
*********************
arr[:,] :
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]
[24 25 26 27 28 29]]
*********************
arr[::-1,] :
[[24 25 26 27 28 29]
[18 19 20 21 22 23]
[12 13 14 15 16 17]
[ 6 7 8 9 10 11]
[ 0 1 2 3 4 5]]
*********************
arr[:,::-1] :
[[ 5 4 3 2 1 0]
[11 10 9 8 7 6]
[17 16 15 14 13 12]
[23 22 21 20 19 18]
[29 28 27 26 25 24]]
*********************
arr[0:3:-1] :
[[18 19 20 21 22 23]
[12 13 14 15 16 17]
[ 6 7 8 9 10 11]]
*********************
arr[0:3:1] :
[]
*********************
arr[-1:3:1] :
[]
*********************
arr[-1:-3:-1] :
[[24 25 26 27 28 29]
[18 19 20 21 22 23]]
*********************
常见数组切片索引方法
布尔索引
布尔型索引是利用bool型数组,来对原始数组进行切片索引,用于布尔索引的数组与被索引的原始数组必须是同形的,如果不相同则报错。只有当bool索引数组中的数据为True的时候,原始数组中对应位置上的数据才会被计入最终产生的视图ndarray中。
import numpy as np
arr = np.random.randint(1,6,42).reshape(6,7)
print('原始数组:\n',arr)
bool_arr = arr>3
print('布尔数组:\n',bool_arr)
print('布尔索引:\n',arr[bool_arr])
arr[bool_arr] = 0
print(type(arr[bool_arr]))
print('原始数组:\n',arr)原始数组:
[[4 2 3 5 5 1 5]
[4 5 4 3 2 1 1]
[2 5 4 3 1 2 5]
[1 4 5 2 3 5 4]
[5 5 2 5 2 4 2]
[1 5 2 5 4 5 2]]
布尔数组:
[[ True False False True True False True]
[ True True True False False False False]
[False True True False False False True]
[False True True False False True True]
[ True True False True False True False]
[False True False True True True False]]
布尔索引:
[4 5 5 5 4 5 4 5 4 5 4 5 5 4 5 5 5 4 5 5 4 5]
原始数组:
[[0 2 3 0 0 1 0]
[0 0 0 3 2 1 1]
[2 0 0 3 1 2 0]
[1 0 0 2 3 0 0]
[0 0 2 0 2 0 2]
[1 0 2 0 0 0 2]]
花式索引
花式索引又叫做整数数组索引,即在指定的轴上通过整数数组来选取对应的轴索引位置元素,花式索引可以和普通的切片索引组合进行使用。当连续使用多个花式索引数组的时候,必须使用元组(tuple)将各个维度上的索引数组包装起来,或者可以直接使用np.ix_进行包装
import numpy as np
arr = np.arange(30).reshape(5,6)
def show_arr(name,arr):
print(name,':\n',arr,'\n *********************')
show_arr('原始数组',arr)
show_arr('arr[[0,3]]',arr[[0,3]])
show_arr('arr[[0,3],[1,3]]',arr[[0,3],[1,3]])
show_arr('arr[[0,3],1:3]',arr[[0,3],1:3])原始数组 :
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]
[24 25 26 27 28 29]]
*********************
arr[[0,3]] :
[[ 0 1 2 3 4 5]
[18 19 20 21 22 23]]
*********************
arr[[0,3],[1,3]] :
[ 1 21]
*********************
arr[[0,3],1:3] :
[[ 1 2]
[19 20]]
*********************
np.ix_ 索引
np.ix_函数可以将几个数组合并起来构建一个索引器,以选择原始数据上的方形区域
import numpy as np
arr = np.arange(30).reshape(5,6)
def show_arr(name,arr):
print(name,':\n',arr,'\n *********************')
indexer = np.ix_([0,3],[1,4])
show_arr('原始数组',arr)
print('复合索引器',indexer)
print('复合索引器类型:',type(indexer))
show_arr('np.ix_索引:',arr[indexer])原始数组 :
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]
[24 25 26 27 28 29]]
*********************
复合索引器 (array([[0],
[3]]), array([[1, 4]]))
复合索引器类型:
np.ix_索引: :
[[ 1 4]
[19 22]]
*********************
Numpy数学工具
数学和统计方法
| 函数 | 说明 |
|---|---|
| sum | 对数组中全部或某轴向的元素求和。零长度的数组的sum为0 |
| mean | 算术平均值。零长度的数组的mean为NaN |
| std、var | 分别为标准差和方差,自由度可调,默认为N |
| min,max | 最大值和最小值 |
| argmin,argmax | 分别为最大和最小元素的索引 |
| cumsum | 所有元素的累计和,中间的计算结果保留了下来,可以根据中间结果分析出不同阶段的变化趋势 |
| cumprod | 所有元素的累计积 |
集合逻辑运算
| 函数 | 说明 |
|---|---|
| unique(X) | 计算X中的唯一元素,并返回有序结果 |
| intersect1d(X,Y) | 计算X和Y中的公共元素,并返回有序结果 |
| union1d(X,Y) | 计算X和Y的并集,并返回有序结果 |
| in1d(X,Y) | 返回一个表示“X的元素是否在Y中”的布尔型数组 |
| setdiff1d(X,Y) | 集合的差集,即元素在X中且不在Y中 |
| setxor1d(X,Y) | 集合的对称差,即存在于一个数组中但不同时存在于两个数组中的元素 |
线性代数
在numpy中可以使用“二维数组”表示矩阵概念,同时numpy提供matrix类来更加方便的操作矩阵, numpy中关于矩阵的运算的代码基本都在numpy.linalg模块中
| 函数 | 说明 |
|---|---|
| diag | 以一维数组的形式返回方阵的对角线(或非对角线)元素,或将一维数组转换为方阵(非对角线元素为0) |
| dot | 矩阵乘法 |
| trace | 计算对角线元素的和 |
| det | 计算矩阵行列式 |
| eig | 计算方阵的本征值(特征值)和本征向量(特征向量) |
| inv | 计算方阵的逆 |
| pinv | 计算矩阵的Moore-Penrose的伪逆 |
| qr | 计算QR分解 |
| svd | 计算奇异值分解(SVD) |
| solve | 解线性方程组Ax=b,其中A为一个方阵 |
| lstsq | 计算Ax=b的最小二乘解 |
随机数生成
| 函数 | 说明 |
|---|---|
| seed | 确定随机数生成器的种子 |
| permutation | 返回一个序列的随机排列或返回一个随机排列的范围 |
| shuffle | 对一个序列就地随机排列 |
| rand | 产生均匀分布的样本值 |
| randint | 从给定的上下限范围内随机选取整数 |
| randn | 产生正态分布的样本值(平均值为零,标准差为1) |
| binomial | 产生二项分布的样本值 |
| normal | 产生正态分布的样本值 |
| beta | 产生beta分布的样本值 |
| chisqure | 产生卡方分布的样本值 |
| gamma | 产生Gamma分布的样本值 |
| uniform | 产生在[0,1)中均匀分布的样本值 |
数组输入输出
二进制格式
使用np.save函数将数组以二进制文件保存到文件中,np.savez可以以键值对的形式将多个文件保存到同一个文件中,使用np.load方法从二进制文件中加载数组
import numpy as np
arr1 = np.arange(30).reshape(5,6)
arr2 = np.arange(30).reshape(5,6)
def show_arr(name,arr):
print(name,':\n',arr,'\n *********************')
np.save('./LessonData/arr1',arr1)
np.savez('./LessonData/arr1_and_arr2',key_arr1=arr1,key_arr2=arr2)
show_arr('从文件中加载一个数组:',np.load('./LessonData/arr1.npy'))
zipArray = np.load('./LessonData/arr1_and_arr2.npz')
for arr in zipArray.items():
show_arr('从文件中加载两个数组01:',arr)从文件中加载一个数组: :
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]
[24 25 26 27 28 29]]
*********************
从文件中加载两个数组01: :
('key_arr1', array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29]]))
*********************
从文件中加载两个数组01: :
('key_arr2', array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29]]))
*********************
文本格式
np.loadtxt、 np.savetxt与二进制格式存储和加载函数相同,不过是以文本形式进行保存,更加具有可读性,但是加载的速度略慢于二进制格式
