sklearn(二十一):Ensemble methods
在sklearn中,ensemble methods有两种类型:
- average method:随机的从trainingdata中抽取多个subdata,训练多个base estimator,在预测new sample的value时,将所有的base estimator的预测结果相加,求平均,作为最终的预测结果。在average method中,尽量使base estimator完全拟合subdata,通过ensemble降低base estimator overfitting的可能,从而得到一个较好的结果。这种类型的方法有:Bagging methods, Forests of randomized trees等。
- boosting method:依次建立多个weak base estimator,每个estimator用来拟合上一个estimator的bias,根据各个estimator拟合效果的优劣,给每个estimator以一定权重,在预测一个new sample时,将各个estimator的prediction乘以权重,相加,得到最终的prediction。这类型的方法有: AdaBoost, Gradient Tree Boosting等。
Bagging meta-estimator
该estimator的工作原理:
从training data中随机抽取n个subdata,用于训练n个base estimator,在训练的过程中,base estimator的bias越小越好(不用怕overfitting,因为在aggregate各个estimator的时候,会降低overfitting的影响)。
当要预测一个new sample时,分别用base estimator进行预测,然后将最终的预测结果相加求平均。
在抽取subdata的过程中,可以抽取data的一个子集,也可以抽取feature中的一个子集,作为最终的subdata。
sklearn.ensemble.BaggingClassifier(base_estimator=None, n_estimators=10, max_samples=1.0, max_features=1.0, bootstrap=True, bootstrap_features=False, oob_score=False, warm_start=False, n_jobs=None, random_state=None, verbose=0)
#base_estimator:选取的estimator
#n_estimators:拟合的estimator数量
#max_samples:subdata中最大的样本量
#max_features:subdata中最大的特征数
#bootstrap:是否实施有放回抽样
#bootstrap_features:是否要对feature实施有放回抽样
#oob_score:是否用out of bag data来估计generalization error
#warm_start:是否利用上一次的结果
code示例:
>>> from sklearn.ensemble import BaggingClassifier
>>> from sklearn.neighbors import KNeighborsClassifier
>>> bagging = BaggingClassifier(KNeighborsClassifier(),
... max_samples=0.5, max_features=0.5)
Forests of randomized trees
在sklearn中有3中类型的“随机森林”,下面分别阐述:
- type I:RandomForestClassifier and RandomForestRegressor RandomForest:随机抽取n分sub_data,在这些data上训练n个“完全长成树”。在预测时:以n个tree的预测结果的average为最终的预测值。虽然“完全长成树”增加了single tree的overfitting。但是,average操作将弱化overfitting,总体来看:虽然single tree的variance增加,但是通过average操作能够降低最终的预测variance。
- type II:ExtraTreesClassifier and ExtraTreesRegressor ExtraTrees与RandomForest最大的不同之处在于,相比于RandomForest在node split中寻找最优的(feature,value)来切割data,ExtraTrees是从随机生成的若干个(feature,value)中选取一个最优的threshold作为切割data的依据。ExtraTrees的这种动作虽然会增大singal tree的bias,但是会降低variance,从而降低最终ensemble model的variance。
- type III:Totally Random Trees Embedding :RandomTreesEmbedding 利用这一model可以transform data feature,具体原理如下: 拟合一棵forests of completely random trees,将data中各个sample归结到该森林的一个叶子节点上,并且以森林的叶子节点index作为特征空间,构建各个sample的特征向量,使得该特征向量,除sample所属的index 维度值为1以外,其它各个维度的值均为0。(这种特征向量类似于文本分类中的one-hot vector)。
利用该tree构建的data的特征向量,可以作为input data拟合其他的模型。
新的特征向量矩阵的size和稀疏性,可以通过控制tree的max_depth来控制。 - 对于RandomForest classifier中参数优化经验:Empirical good default values are max_features=n_features for regression problems, and max_features=sqrt(n_features) for classification tasks (where
n_features is the number of features in the data).
AdaBoost:classification and multi-classification
sklearn中AdaBoost既可以进行classification,又可以进行regression,分别用:AdaBoostClassifier and AdaBoostRegressor
AdaBoost的核心思想是:选定一个base estimator,在一系列reweight的data上拟合一系列的weak estimator,并根据这些estimator预测的准确度,给各个estimator一个权重,然后将所有estimator乘以各自权重,相加,得到最终的prediction。在每次迭代的过程中,都需要给data重新赋予权重,该权重的大小与estimator对sample的分类准确度相关,准确度越大,则权重越小,这样,使得下一轮的model learning,更注重于未正确分类的sample。
#在实际应用中,AdaBoost主要调节的两个参数是:n_estimator,以及base_estimator的复杂度;
sklearn.ensemble.AdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm=’SAMME.R’, random_state=None)
#base_estimator:选用的model
#n_estimators:要拟合的 estimator的数量
#learing_rate:用于缩减每个estimator的prediction权限from 1 to any float
#algorithm:用于实施adaboost的算法{‘SAMME’, ‘SAMME.R’}
#random_state:确定random_state
sklearn.ensemble.AdaBoostRegressor(base_estimator=None, n_estimators=50, learning_rate=1.0, loss=’linear’, random_state=None)
#loss: {‘linear’, ‘square’, ‘exponential’}
这里着重讲一下,传统AdaBoost和SAMME的区别:二者的主要区别在于对estimator的权重alpha的定义不一样:
AdaBoost对alpha的定义:
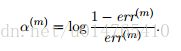
SAMME对alpha的定义:
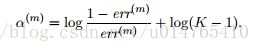
SAMME主要还考虑了多分类问题,在AdaBoost中,alpha的计算只适用于二分类问题,当应用于k分类问题时,由于每个weak estimator的准确率只有1/k,则其错误率为1-(1/k),那么原alpha就会变为负数,则对于一个错分的sample,根据其权重更新公式![]()
下一轮的weight将小于这一轮的weight,这与reweight的原则相反。
而用SAMME的alpha计算公式,可以有效避免alpha<0的问题,从而保证每个sample的reweight方向正确。
参考博文:
AdaBoost
SAMME
Gradient Tree Boosting/Gradient Boosted Regression Trees
Gradient Tree Boosting与AdaBoost都是boosting的方法,虽然二者都是串行的算法,但是,AdaBoost的每次iteration是拟合残差,GTB的每次iteration是拟合损失函数的负梯度(将其作为残差的近似值)。AdaBoost中,base_estimator可以自定义,而GTB中base_estimator为tree。
Gradient Boosted Regression Trees (GBRT)可以用于classification和regression,其优缺点如下:
- 优点:
能够自动处理heterogeneous features data;
具有很强的预测能力;
对于trainingdata中output空间中的outlier具有很强的robustness; - 缺点:
由于boosting方法的 sequential nature,该算法很难用“并行化方法计算”,针对这一问题,可以采用XGBoost解决。
Classification
sklearn.ensemble.GradientBoostingClassifier(loss=’deviance’, learning_rate=0.1, n_estimators=100, subsample=1.0, criterion=’friedman_mse’, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3, min_impurity_decrease=0.0, min_impurity_split=None, init=None, random_state=None, max_features=None, verbose=0, max_leaf_nodes=None, warm_start=False, presort=’auto’, validation_fraction=0.1, n_iter_no_change=None, tol=0.0001)
#learning_rate:可以避免overfitting
#loss:用于计算estimator误差的Loss function。{‘deviance’:logistic regression, ‘exponential’:For loss ‘exponential’ gradient boosting recovers the AdaBoost algorithm.}。exponential仅能由于二分类问题,而deviance则能够用于多分类问题。对于有错分样本的trainingdata而言,exponential没有deviance 鲁棒性强。
#subsample:用于fit base_estimator的subdata,当subsample<1时,GBT将用stocastic gradient descent来进行每次iteration。对此做出解释:GBT本身就像是采用gradient descent的方法,将损失函数当做要优化的目标函数,将base_estimator当做是损失函数中的变量,该损失函数符合凸优化条件,因此,可以用gradient descent来达到最优解,在最优化过程中,只要不断优化每次的base_estimator即可,当subsample=1时,每次base_estimator的更新使用所有sample进行,当subsample<1时,就变成了stacastic gradient descent,每次base_estimator的更新使用的是部分sample进行。
#criterion:用于评判split好坏的标准{friedman_mse,mes,mae}
#init:使用的base_estimator类型
#max_features:在选择best splitting时考虑的feature数量???是指feature的选择范围?还是指一次split要考虑的feature数量?
#validation_fraction:cross-validation的比例,用于确定是否要early stopping iteration
note that:GBC在实施multi-classification任务时,每一次的iteration都要产生n_classes个regression trees,因此,GBC产生tree的总量可达n_estimators * n_classes。在实际multi-classification中,建议用RandomForestClassifier代替GBC。
也就是说RFC中,single tree就可以解决multi-classification问题,而GBC中,采用one vs rest策略来解决multi-classification问题。
Regression
sklearn.ensemble.GradientBoostingRegressor(loss=’ls’, learning_rate=0.1, n_estimators=100, subsample=1.0, criterion=’friedman_mse’, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3, min_impurity_decrease=0.0, min_impurity_split=None, init=None, random_state=None, max_features=None, alpha=0.9, verbose=0, max_leaf_nodes=None, warm_start=False, presort=’auto’, validation_fraction=0.1, n_iter_no_change=None, tol=0.0001)
#loss:目标函数{‘ls’:least squares regression, ‘lad’:least absolute deviation, ‘huber’:combine ls and lad, ‘quantile’:allows quantile regression }, optional (default=’ls’}
#learning_rate:trade off between n_estimators and learning_rate。learning_rate可以看作是正则化项,小的learning_rate会降低每个base_estimator的predictive power,建议在调参时选用小的Learning_rate(<0.1),learning_rate越小,n_estimators越大,因为,此时需要更多的base_estimator来维持同等水平的training error。
#alpha:loss function中huber和quantile 的参数
#validation_fraction:利用cross-validation可以决定是否early stopping iteration by test_error < limit。
#warm_start:允许在previous拟合好的model上加入更多的weak estimator。
#经验显示,有learning_rate outperforms no-learning_rate。subsample with learning_rate能够进一步提高accuracy,而subsample without learning_rate则表现较差。
note that:用一个小的max_feature能够降低运行时间。
参考博文:
分位数回归模型学习笔记
分位数回归
GBDT&GBRT与XGBoost
决策树之CART(分类回归树)详解
绘制Partial dependence plots
如果你想要绘制one feature和target y之间的相关关系(one-way plots),或者绘制two features和target y之间的相关关系(two-way plots),你可以用以下moudle。给出示例code,详情查官网。
>>> from sklearn.datasets import make_hastie_10_2
>>> from sklearn.ensemble import GradientBoostingClassifier
>>> from sklearn.ensemble.partial_dependence import plot_partial_dependence #绘制partial dependence plots。
>>> X, y = make_hastie_10_2(random_state=0)
>>> clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0,
... max_depth=1, random_state=0).fit(X, y)
>>> features = [0, 1, (0, 1)]
>>> fig, axs = plot_partial_dependence(clf, X, features)
>>> from sklearn.ensemble.partial_dependence import partial_dependence #给出partial dependence function 的值
>>> pdp, axes = partial_dependence(clf, [0], X=X)
>>> pdp
array([[ 2.46643157, 2.46643157, ...
>>> axes
[array([-1.62497054, -1.59201391, ...
Voting Classifier
其核心思想是:将多种不同的classifier集合起来,最终的预测结果采用“多数服从少数”,或者“average”的方法,给出。
sklearn.ensemble.VotingClassifier(estimators, voting=’hard’, weights=None, n_jobs=None, flatten_transform=None)
#estimators:结合的classifier列表
#voting:{hard:majority rule,soft:average rule}
#weights:各个classifier上的权重
给出average rule的示例code:
>>> from sklearn.model_selection import GridSearchCV
>>> clf1 = LogisticRegression(solver='lbfgs', multi_class='multinomial',
... random_state=1)
>>> clf2 = RandomForestClassifier(random_state=1)
>>> clf3 = GaussianNB()
>>> eclf = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)], voting='soft')#集合多个classifier
>>> params = {'lr__C': [1.0, 100.0], 'rf__n_estimators': [20, 200],}
>>> grid = GridSearchCV(estimator=eclf, param_grid=params, cv=5)#利用gridsearch来寻找eclf中各个classifier的最优参数
>>> grid = grid.fit(iris.data, iris.target)
官方文档:Ensemble methods