论文阅读-ATLAS: A Sequence-based Learning Approach for Attack Investigation
论文代码:
https://github.com/purseclab/ATLAS
代码预处理写的太乱了,很多预处理过程都不是特别合理。不过这篇论文思想还是挺合理的,相比其实溯源图工作在路径上的处理更加合理一些。
背景简介
高级可持续威胁攻击(Advanced Persistent Threat,APT)涉及较长时间内的多个攻击步骤,其调查需要分析大量日志以识别其攻击步骤,这些即为运行 APT 攻击而进行的一组活动。然而,在企业中,入侵检测系统每天都会生成许多可疑事件的威胁警报(攻击症状)。网络分析师必须调查此类事件,以确定事件是否属于攻击的一部分。由于有许多警报需要调查,网络分析人员往往最终会产生警报疲劳,导致他们忽略大量警报,错过真正的攻击事件。
- 无论所利用的漏洞和执行的有效载荷如何,不同的攻击可能共享相似的抽象攻击策略。
ATLAS利用因果关系分析,自然语言处理和机器学习技术的新颖组合来构建基于序列的模型,该模型从因果图建立攻击和非攻击行为的关键模式。在推断时间,给定威胁警报事件,确定因果图中的攻击症状节点。然后,ATLAS构造一组与攻击症状节点关联的候选序列,使用基于序列的模型来识别顺序中有助于攻击的节点,并将识别出的攻击节点统一起来构建攻击记录。
分析方法从多个主机、应用程序和网络接口收集不同的审计日志。大量日志通常需要离线分析或实时监控,以调试系统故障并识别复杂的威胁和漏洞。
- 虽然安全调查人员希望确定攻击步骤,即进行攻击所采取的具体活动,但这些方法在很大程度上无法准确定位关键攻击步骤,从而有效地突出端到端的攻击记录。
ATLAS目标是从审计日志中识别关键实体(节点),帮助网络分析师构建 APT 攻击的关键步骤。ATLAS是一个攻击记录恢复框架,将自然语言处理 (NLP) 和深度学习技术集成到数据来源分析中,以识别攻击和非攻击序列。
ATLAS分三个阶段进行操作:
- 处理系统日志并构建自己的优化因果相关图
- 通过NLP技术从因果图构造语义增强的序列(时间戳事件)
- 学习了一个表示攻击语义的基于序列的模型,这有助于在推理时恢复描述攻击故事的关键攻击实体。
主要挑战在于:
- 因果图通常是大而复杂的,这使得序列构建困难
- 需要一种精确构建序列的方法来有效地建模合法和可疑的活动
- 需要一种自动方法来从给定的攻击行为中识别攻击事件
主要的贡献:
- 引入了ATLAS,一种用于恢复攻击故事的框架,该框架利用自然语言处理和基于序列的模型学习技术- 来帮助从审计日志中恢复攻击步骤。
- 提出了一种新的序列表示方法,通过词序化和词嵌入将攻击和非攻击语义模式抽象出来,序列允许ATLAS建立有效的基于序列的模型,以识别构成攻击链的攻击事件
- 在受控环境中的真实报告中验证了始终APT攻击,表明ATLAS能够以较高的准确性和最小的开销来识别攻击事件中的关键攻击条目。
方法概述

审计日志预处理
针对因果溯源图的复杂性,ATLAS通过预处理来构建一个优化的因果溯源图,可以在不“牺牲”攻击调查的关键语义的情况下降低日志复杂性(即减少节点和边的数量)。
如果来实现预处理以达到其目标:
- ATLAS删除掉从攻击节点或攻击症状节点无法达到的所有节点。(攻击症状节点是什么节点)
- 删除重复边,只保存source到target的最早触发的边

ATLAS会把同种类型事件进行聚合,这里的聚合方法是同种类型的节点具有相同类型的入边与出边同时有相同source与target。(合理与否???)
针对预处理方法的疑问:
- 1 只保留初始时间戳的边会不会破坏攻击的时序模式???
- 2 这种聚合会大量的减少边的数量,突发性的异常会不会被淹没
- 3 这种聚合有没有时间窗口??
然这可能会在构建序列时打破事件的原始时间顺序,但它不会影响预期攻击模式的识别,因为构建的序列中事件的时间顺序在模型学习和攻击调查阶段之间是一致的。 通过这个过程,与原始因果图相比,ATLAS 在实体数量方面平均减少了 81.81%。(现在一个场景大约只有2万左右的数据量)。
序列构建与序列学习
ATLAS首先从因果溯源图提取出攻击或非攻击序列,并将引理化与选择性采样应用到序列构建中以实现对攻击与非攻击模式的有效提取。最后,利用embedding方法对序列进行向量化并利用LSTM来学习序列的模式。
- 从溯源图提取攻击序列与非攻击序列
- 利用引理化与选择性采样来增强攻击模式与非攻击模式的提取
- 利用embedding对序列进行向量化表示,并利用LSTM学习序列模式
攻击与非攻击序列的抽取
攻击序列
攻击序列包括攻击实体按时间顺序排列的事件。ATLAS首先从因果图中获取所有攻击实体的集合,并构建包含两个或多个实体的实体子集。

如上图所示,因果溯源图中包含了三个攻击实例{A,C,F},攻击子集为{A,C},{A,F},{C,F}和{A,C ,F}。攻击实体子集的数量可以是指数级的。然而,在实践中,攻击实体的数量通常并不多(通常少于 40 个),因为攻击者通常试图隐藏和最小化其活动的痕迹。例如,放置一个后门(表示为一个攻击实体)而不是留下n个后门(表示为n个实体),这符合攻击者保持隐身的最佳利益。
对于每个攻击实体子集,ATLAS 通过以下步骤从优化的因果图中提取攻击序列。 首先,对于攻击实体子集中的每个实体,ATLAS 提取其邻域图(一跳节点以及节点之间的边)。 这一步使 ATLAS 能够捕获所有与攻击实体有因果关系的实体。
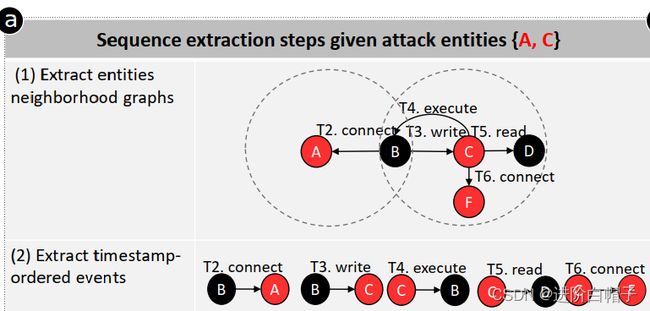
其次,ATLAS 从构建的邻域图中获取按时间戳排序的攻击事件。如果源节点或目标节点代表攻击实体,则事件被标记为攻击。其中攻击事件表示由攻击实体A和C的邻域图中提取的边连接的时间戳排序节点。最后,ATLAS 将提取的时间戳排序的攻击事件转换为一个序列,如果它只包含攻击事件,并且包括实体子集的所有攻击事件,则将其标记为攻击。 例如,子集{A,C}的提取序列被标记为attack,因为它由包含攻击实体A或C的所有攻击事件组成。
非攻击序列

一识别非攻击序列的方法类似于构建攻击序列。即按照上述步骤获取因果图中的所有非攻击实体并提取它们的序列。然而,由于非攻击实体的指数数量,这个过程很复杂。 ATLAS 不会尝试学习或识别任何良性活动(即非攻击序列),它旨在准确地学习和识别恶意和非恶意活动之间的界限。为此,ATLAS 为每个攻击子集添加了一个非攻击实体以提取非攻击序列。添加的非攻击实体可以潜在地将非攻击事件添加到序列中,这使得 ATLAS 能够提取攻击序列偏差(即非攻击序列),并精确学习攻击和非攻击序列之间的异同。形式上,如果因果图包括攻击实体和k’个非攻击实体,则非攻击实体子集的数量是

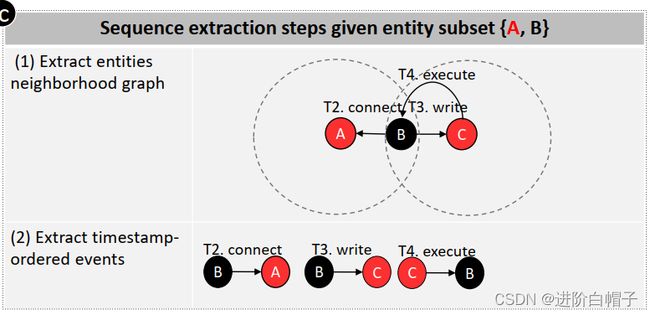
上图展示了三个攻击实体{A,C,F},用于提取包含一个或多个攻击实体的所有可能的攻击子集{A}, …,{A,C,F}。 为了生成非攻击子集,ATLAS 一次从三个非攻击实体{B,D,E}中附加一个实体到提取的攻击实体子集。
对于每个非攻击实体子集,ATLAS然后通过以下步骤从类似于攻击序列的因果图中提取非攻击序列:
- 首先,对于子集中的每个实体,ATLAS提取实体节点的邻域图。例如,对于非攻击实体子集{A,B},ATLAS提取实体A和B的邻域图,如图5(右)步骤(1)所示。
- 其次,ATLAS从邻域图中提取有序事件。图(右)步骤(2)显示了非攻击实体子集{A,B}的提取事件,其中包括由从实体A和B的邻域图中提取的边表示的有序事件。
- 最后,如果一个序列与任何提取的攻击序列都不匹配,则 ATLAS 将其标记为非攻击序列,否则丢弃处理过的序列。例如,子集{A,B}的提取序列被标记为非攻击,因为它不匹配任何攻击序列。
(这样标记的非攻击序列是攻击序列的一个子序列,标为非攻击序列的意义何在???)
序列长度和序列数量:序列长度是序列中实体和动作的总数。ATLAS的序列构建过程不会导致固定长度的序列,因为每个序列可能由从因果图中获得的不同数量的事件组成(序列长度不固定)。此外,从随机图中提取的攻击和非攻击序列的数量取决于因果图的大小,因果图可以包括与攻击和非攻击实体相关联的不同数量的实体和事件。 因此,ATLAS能够从给定的因果图中提取不同长度和数量的攻击和非攻击序列。
序列的抽象归并
ATLAS 使用词形还原技术(Lemmatization)将序列转换为表示用于语义解释的序列模式的通用文本。词形还原通常用于自然语言处理,主要是把单词的词缀部分除去,从而得到单词的词干部分。 这个过程保留了完整序列的原始语义,有利于基于序列的模型学习。

表 1 显示了四种不同的词汇类型以及 ATLAS 用于按顺序抽象实体和动作的每种类型中的词汇。该词汇表共包含30个词,将词的形态和派生相关形式简化为一个共同的基本形式。 词汇表根据词的细粒度语义分为四种不同的类型:进程、文件、网络和动作。 进程、文件和网络类型用于对实体进行词形还原。这些类型足以捕获因果图中实体的上下文、语义和句法相似性以及与其他词的关系。ATLAS 解析每个序列,找到实体并将它们中的每一个映射到相应的词汇表。
例如转化为
选择性序列采样
构建的攻击和非攻击序列的数量通常是不均衡的。原因是日志条目中的攻击实体一般比非攻击实体少。例如,我在评估中通过分析审计日志发现攻击实体的平均数为 61,而非攻击实体的平均数约为21K。使用这种极度不平衡的数据集训练分类器会使其偏向于多数(非攻击)类或无法学习少数(攻击)类。
为了平衡训练数据集,ATLAS首先对具有一定相似度阈值的非攻击序列进行欠采样。然后,它使用过采样机制随机变异那些攻击序列,直到它们的总数达到相同数量的非攻击序列。一种平衡训练数据集的简单技术是复制少数攻击序列中的序列或随机删除多数非攻击序列中的序列子集。不幸的是,这会导致模型过拟合于特定的攻击模式或错过许多重要的非攻击模式。为了解决这些问题,ATLAS 使用了下面详述的两种机制:
- 欠采样:ATLAS 通过 Levenshtein 距离(编辑距离)减少非攻击序列的数量,以计算词形化序列之间的相似性。 然后,当它们的相似性超过确定的阈值时,它会过滤掉结果。
虽然 Levenshtein Distance 在 NLP 中经常被用于寻找句子之间的相似性,但 ATLAS 计算编辑步骤的数量,例如在序列中添加或删除词汇单词,以将一个序列转换为另一个词形化序列。 对于训练集中的所有序列,此过程的复杂度为 O(n2)。对于每个序列,当它们的相似度超过某个阈值时,ATLAS 将删除这些序列。 特别是,通过实验发现序列之间 80% 的相似性阈值会产生良好的欠采样率,足以过滤掉高度相似和冗余的序列。
- 过采样:ATLAS 采用基于突变的过采样机制,将更多种类的攻击序列包含在训练序列中。ATLAS 定义了代表不同进程和文件类型(例如,system_process 和 program_process)的不同词汇。这里,对于每个词形还原后提取的攻击序列,ATLAS 随机将一种词汇类型变异为另一种相同类型的词汇。 这个过程并没有从根本上改变变异序列。但是,它增加了在用于模型训练的攻击中未触发但由于上下文差异而在其
他攻击中仍然可能发生的相似序列的数量。(这种过采样的原理是啥??)
序列向量表示与模型学习
ATLAS 使用词表示嵌入将词形化序列转换为表示序列模式的广义文本以进行语义解释。这个过程保留了完整序列的原始语义,有利于基于序列的模型学习。
- Sequence Embedding:ATLAS 将词嵌入整合到模型学习中,将词形还原的序列转化为数值向量。 词嵌入(例如词表示和 word2vec)已在 NLP 中广泛用于文本表示,因为它们精确地推断出不同词之间的语义关系。这些向量定义了词汇之间的特定领域语义关系,并有助于突出不同序列的模式以进行模型训练。用于训练词嵌入的语料库包括审计日志中的所有词形还原攻击和非攻击序列。与其他广泛使用的方法(例如单热编码)相比,嵌入式序列改进了模型学习。
- 基于序列的模型学习:ATLAS 使用长短期记忆 (LSTM) 网络,这是循环神经网络 (RNN) 的一个子类型,从攻击或非攻击序列中学习模型。 LSTM 被广泛应用并被证明对于不同任务中的基于序列的学习是有效的,例如机器翻译和情感分析。LSTM 使 ATLAS 能够自动学习一个模型,该模型区分攻击和非攻击序列中的反射模式。该模型还包括一个卷积神经网络 (CNN),它有助于 ATLAS 捕获 APT 攻击的隐蔽性和动态性。
- 具体来说,学习模型使用(1)用于正则化的 Dropout 层以减少过拟合并改善泛化误差,(2)具有最大池化的 Conv1D 层来处理词形化序列,(3)具有 sigmoid 激活的密集全连接层来预测这些序列的攻击相关概率。

攻击调查
本文描述了 ATLAS 如何在训练基于序列的模型后辅助安全调查员进行攻击调查。调查通常从一个或多个攻击症状实体开始。例如,攻击症状可能是恶意网站或安全分析师识别的 IP 地址,或由网络监控系统(如 Nagios)报告为威胁警报。这里,ATLAS通过查询基于序列的学习模型,通过给定的攻击征兆实体帮助安全运营人员自动发现更多的攻击相关实体。 下面将详细介绍这个过程。
- 攻击实体识别。ATLAS 调查阶段的目标是溯源与给定攻击症状实体相关的所有攻击实体。 这里,ATLAS 枚举所有未知实体,并识别因果图中的实体是攻击实体还是非攻击实体。这个过程的时间复杂度为 O(n),用于遍历因果图中的所有未知实体 (n)。 ATLAS 能够用不同数量的(一个或多个)攻击症状实体开始调查,因为它用不同数量的攻击实体详尽地训练模型。
为了说明这一点,图 5(中)显示了在因果图中表示攻击实体 {A,C,F} 的三个图节点。在调查期间,这些实体中的一个或多个可以作为已知的攻击症状给出,而其余的实体,无论它们是攻击还是非攻击,都是未知的。为了识别未知攻击实体,ATLAS首先从因果图中获取一组所有未知实体,并构建其包含一个未知实体的子集。然后ATLAS将攻击症状实体附加到每个子集中;因此,每个子集包含所有已知的攻击征兆实体和仅一个未知实体。例如,给定图 5(中)中的攻击症状实体 A,ATLAS 构造其子集{A,B},…,{A,F}。ATLAS 使用这些子集从因果图中提取序列。然后使用 LSTM 模型通过预测分数来预测每个序列是攻击还是非攻击。该过程通过检查这两个实体的时间顺序事件是否形成模型先前学习的攻击模式来识别未知实体是否与攻击症状实体密切相关。识别出的攻击序列表明未知实体是攻击实体的一部分。
为了说明,图5(左)显示了子集{A,C}的序列构建示例,其中A是攻击征兆,C是未知实体。 为了提取A和C的序列,ATLAS首先提取邻域图以找到它们的相关事件,并将邻域图节点和边转化为时间戳排序的事件序列。该过程应用于所有实体子集,从而产生一组不同长度的不同序列 .ATLAS 然后对序列进行词形还原并将其词嵌入传递给模型。 如果该序列被归类为攻击序列,则 ATLAS 推断子集中的未知实体(即 C)是攻击实体。
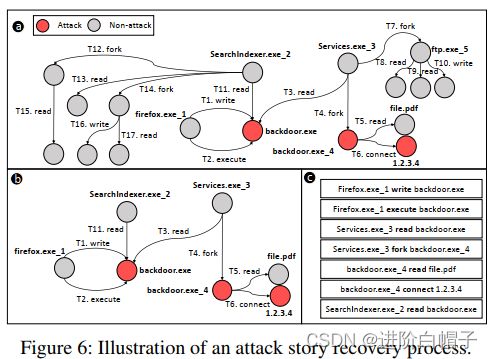
- 攻击场景(story)还原:ATLAS攻击场景还原的目标是从攻击调查阶段识别出与识别出的攻击实体相关的攻击事件。ATLAS提取识别出的攻击实体的邻域图,得到所有包含的事件作为攻击事件。 这些事件按时间戳进一步排序,作为还原的攻击场景。已识别的攻击实体与攻击事件之间的映射高度依赖于被调查的攻击。
例如,如果 ATLAS 在攻击调查中还原了30个攻击实体,则根据攻击操作(例如,读取或写入文件)的数量,与这 30 个实体相关联的事件数量可能会有所不同。图 6(b)-© 说明了 ATLAS从图6(a)的因果图中构建攻击场景的步骤。我们认为在攻击调查阶段ATLAS已经成功恢复了攻击实体{ backdoor.exe(后门文件)、backdoor.exe_4(后门进程)和1.2.3.4(恶意主机)}。ATLAS 使用这些攻击实体在图 6(b) 中提取它们的邻域图,其中包括攻击事件。攻击实体和事件之间的这种映射允许 ATLAS 自动提取那些相关的攻击事件,而无需网络分析师执行任何手动调查。
例如,非攻击实体SearchIndexer.exe_2(WindowsNT程序)不断枚举和读取文件元数据,对backdoor.exe文件进行正常读取。注意到 ATLAS 将此作为攻击事件包含在图 6(b)中的邻域图中,因为它包含攻击实体 backdoor.exe。 一般来说,如果一个进程读取了恶意文件,该进程很可能成为攻击的一部分,攻击者可以利用它来发起进一步的攻击行动。 但是,ATLAS 不包括源自进程SearchIndexer.exe_2 的其他事件(例如,(SearchIndexer.exe_2, fork,ε, T12)),即使它们发生在攻击事件(SearchIndexer.exe_2,read, backdoor.exe, T11)之后。 最后,ATLAS 从构建的邻域图中报告按时间戳排序的攻击事件,如图6(c)。
- 处理多主机攻击:为了调查针对多个主机的攻击,网络分析师通常从一个主机开始,随着调查的进行,包括更多的主机。因此,从主机中恢复的攻击实体表明跨主机包括更多的主机攻击调查。考虑调查受感染的Web服务器,其Web目录中有恶意程序backdoor.exe。当ATLAS识别backdoor.exe的攻击实体时,它会将此实体作为新的攻击症状实体来调查其他已下载backdoor.exe的主机 . 这使得 ATLAS 能够以可扩展的方式自然地支持多主机攻击场景。
因此,ATLAS 调查不需要将不同宿主之间的因果图关联起来,这对于来源跟踪技术来说通常是必要的。我们在评估中表明,ATLAS 的有效性不受跨多个主机执行的攻击的影响,它只需要对来自单个主机的审计日志进行分析以发现所有攻击实体(参见第 6.2 节)。 为了构建多主机攻击故事,ATLAS 合并来自受感染主机的审计日志,并构建一个统一的优化因果图表示受感染主机的日志。 ATLAS 然后使用从这些主机中识别出的攻击实体来提取邻域图, 包括因果图中的所有攻击事件。 最后,ATLAS 构建了一个序列,该序列详细说明了跨多个主机的攻击事件的时间顺序。
实验分析
数据集
缺乏公开可用的攻击数据集和系统日志是取证分析中的常见挑战。例如,DARPA TC的数据缺少活动期间生成的审计日志。为了解决这些问题,ATLAS根据真实世界 APT 活动的详细报告实施了10 次攻击,并在受控的测试平台环境中生成了审计日志。此外,类似于先前构建良性系统事件的工作,在每次攻击执行期间尽最大努力在同一台机器上模拟不同的正常用户活动。更具体地说,手动生成了各种良性用户活动,包括浏览不同的网站、执行不同的应用程序(例如,阅读电子邮件、下载附件)以及连接到其他主机。类似于典型的白天工作环境,此类活动在白天的 8 小时窗口内随机执行(Windows 7 32 位虚拟机上开发和执行)。

评估过程:模型训练好后,攻击调查分两步进行。首先,通过从真实攻击实体中随机选择单个攻击症状来生成序列。这些已识别的攻击症状实体自然地代表了安全分析师经常分析的真实案例。其次,通过将因果图中的每个未知实体与症状实体组合而生成的序列,并检查每个构建的序列是否被识别为攻击或非攻击。这使我们能够找到确实与攻击相关的未知实体。由于 ATLAS 调查是基于实体的,因此以实体的形式呈现攻击调查结果。此外,根据与其他攻击调查工作类似的事件来呈现攻击识别结果。通过使用识别的攻击实体生成基于事件的结果。遍历审计日志中的所有事件,如果事件的主题或对象与识别出的攻击实体之一匹配,那么我们将该事件标记为攻击。最后,我们将分类攻击和非攻击实体和事件的数量与其真实标签进行比较,并报告分类指标。
攻击调查结果
ATLAS 在识别每次攻击的攻击实体和事件方面的有效性:

实验对比

Graph Traversal
基于溯源的backward and forward溯源,由于没有之前相关工作。本文实现了该方法,主要有两步:1 forward从症状节点溯源到攻击的根因节点;2 backword从根因节点到症状节点。整个过程的所有节点与路径作为其识别结果。