大数据之数据湖---flink 整合hudi
1.hudi 简介
Huid支持流式的读写操作,流数据可以通过Huid的增量来进行数据追加,精准的保存Index位置,如果一旦写入或者读出的时候出现问题,可以进行索引回滚数据,因为在Hudi写入和写出的时候他是要记录元数据信息的。
Hudi最大的特点就是会进行预写日志功能,也就是把所有的操作都先预写,然后一旦发生问题就会先找预写日志Log,进行回滚或者其他操作,所以你会发现在Hudi中,它会写很多Log日志。
三大特点:流式读写、自我管理、万物皆日志
2.hudi 应用
2.1 特性
1.快速upsert,可插入索引
2.以原子方式操作数据并具有回滚功能
3.写入器之和查询之间的快照隔离
4.savepoint用户数据恢复的保存点
5.管理文件大小,使用统计数据布局
6.异步压缩行列数据
7.具有时间线来追踪元数据血统
8.通过聚类优化数据集
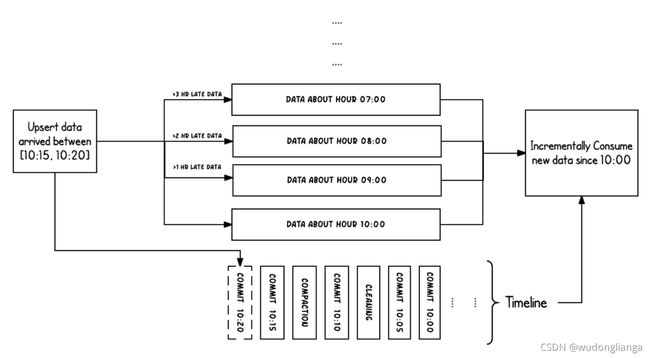
2.2 Timeline
hudi的核心是维护在不同时刻在表上执行的所有操作的时间表,提供表的即时视图,同时还有效地支持按时间顺序检索数据。
Hudi的时刻由以下组件组成:
(1)Instant action: 在表上执行的操作类型
(2)Instant time: 即时时间,通常是一个时间戳,它安装action的开始时间单调递增
(3)State: 时刻的当前状态
Hudi在时间线上的操作都是基于即时时间的, 两者的时间保持一致并且是原子性的。
acion操作包括:
1. commits: 表示将一批数据原子写入表中
2. cleans: 清除表中不在需要的旧版本文件的后台活动。
3. delta_commit:增量提交是指将一批数据原子性写入MergeOnRead类型的表中,其中部分或者所有数据可以写入增量日志中。
4. compaction: 协调hudi中差异数据结构的后台活动,例如:将更新从基于行的日志文件变成列格式。在内部,压缩的表现为时间轴上的特殊提交。
5. rollback:表示提交操作不成功且已经回滚,会删除在写入过程中产生的数据
savepoint:将某些文件标记为“已保存”,以便清理程序时不会被清楚。在需要数据 恢复的情况下,有助于将数据集还原到时间轴上某个点。
任何时刻都会处于以下state:
1. requested:表示一个动作已被安排,但尚未启动
2. inflight:表是当前正在执行操作
3.completed:表是在时间线上完成了操作
2.3 File Layout
Hudi会在DFS分布式文件系统上的basepath基本路径下组织成目录结构。每张对应的表都会成多个分区,这些分区是包含该分区的数据文件的文件夹,与hive的目录结构非常相似。
在每个分区内,文件被组织成文件组,文件id为唯一标识。每个文件组包含多个切片,其中每个切片包含在某个提交/压缩即时时间生成的基本列文件(parquet文件),以及自生成基本文件以来对基本文件的插入/更新的一组日志文件(*.log)。Hudi采用MVCC设计,其中压缩操作会将日志和基本文件合并成新的文件片,清理操作会将未使用/较旧的文件片删除来回收DFS上的空间。
MVCC(Multi-Version Concurrency Control):多版本并行发控制机制
Multi-Versioning:产生多版本的数据内容,使得读写可以不互相阻塞
Concurrency Control:并发控制,使得并行执行的内容能保持串行化结果
2.4 Index
Hudi通过索引机制将映射的给定的hoodie key(record key+partition path)映射到文件id(唯一标示),从而提供高效的upsert操作。记录键和文件组/文件ID之间的这种映射,一旦记录的第一个版本写入文件就永远不会改变。
2.5 Table Types& Queries
Hudi表类型定义了如何在DFS上对数据进行索引和布局,以及如何在此类组织上实现上述操作和时间轴活动(即如何写入数据)。同样,查询类型定义了底层数据如何暴露给查询(即如何读取数据)。
| Table Type | Supported Query types |
|---|---|
| Copy on Write (写时复制) | 快照查询+增量查询 |
| Merge on Read (读时合并) | 快照查询+增量查询+读取优化查询(近实时) |
2.6 Table Types:
1. Copy on Write:使用列式存储来存储数据(例如:parquet),通过在写入期间执行同步合并来简单地更新和重现文件
2. Merge on Read:使用列式存储(parquet)+行式文件(arvo)组合存储数据。更新记录到增量文件中,然后进行同步或异步压缩来生成新版本的列式文件。
2.7 总结了两种表类型之间的权衡
| 权衡 | CopyOnWrite | MergeOnRead |
|---|---|---|
| 数据延迟 | 高 | 低 |
| 查询延迟 | 低 | 高 |
| Update(I/O) 更新成本 | 高(重写整个Parquet文件) | 低(追加到增量日志) |
| Parquet File Size | 低(更新成本I/O高) | 较大(低更新成本) |
| Write Amplification(WA写入放大) | 大 | 低(取决于压缩策略) |
2.7 Query Types:
1. Snapshot Queries:快照查询,在此视图上的查询将看到某个提交和压缩操作的最新快照。对于merge on read的表,它通过即时合并最新文件切片的基本文件和增量文件来展示近乎实时的数据(几分钟)。对于copy on write的表,它提供了对现有parquet表的直接替代,同时提供了upsert/delete和其他写入功能。
2.Incremental Queries:增量查询,该视图智能看到从某个提交/压缩写入数据集的新数据。该视图有效地提供了chang stream,来支持增量视图
3.Read Optimized Queries:读优化视图,在此视图上的查询将查看到给定提交或压缩操作中的最新快照。该视图将最新文件切片的列暴露个查询,并保证与非hudi列式数据集相比,具有相同列式查询功能。
总结了两种查询的权衡
| 权衡 | Snapshot | Read Optimized |
|---|---|---|
| 数据延迟 | 数据延迟 | 高 |
| 查询延迟 | 高(合并列式基础文件+行式增量日志文件) | 低(原始列式数据) |
2.8Copy on Write Table
Copy on Write表中的文件切片仅包含基本/列文件,并且每次提交都会生成新版本的基本文件。换句话说,每次提交操作都会被压缩,以便存储列式数据,因此Write Amplification写入放大非常高(即使只有一个字节的数据被提交修改,我们也需要重写整个列数据文件),而读取数据成本则没有增加,所以这种表适合于做分析工作,读取密集型的操作。
下图说明了copy on write的表是如何工作的
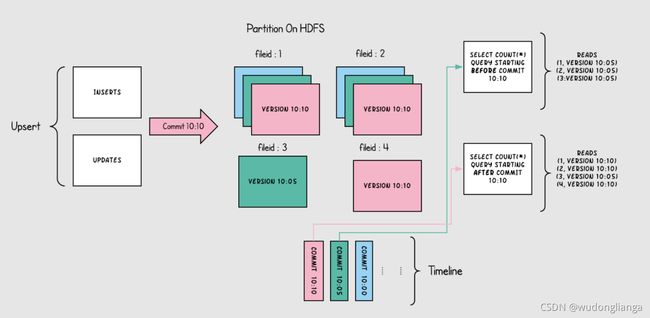
随着数据被写入,对现有文件组的更新会为该文件组生成一个带有提交即时间标记的新切片,而插入分配一个新文件组并写入该文件组第一个切片。这些切片和提交即时时间在上图用同一颜色标识。针对图上右侧sql查询,首先检查时间轴上的最新提交并过滤掉之前的旧数据(根据时间查询最新数据),如上图所示粉色数据在10:10被提交,第一次查询是在10:10之前,所以出现不到粉色数据,第二次查询时间在10:10之后,可以查询到粉色数据(以被提交的数据)。
Copy on Write表从根本上改进表的管理方式
(1)在原有文件上进行自动更新数据,而不是重新刷新整个表/分区
(2)能够只读取修改部分的数据,而不是浪费查询无效数据
(3)严格控制文件大小来保证查询性能(小文件会显著降低查询性能)
2.9 Merge on Read Table
Merge on Read表是copy on write的超集,它仍然支持通过仅向用户公开最新的文件切片中的基本/列来对表进行查询优化。用户每次对表文件的upsert操作都会以增量日志的形式进行存储,增量日志会对应每个文件最新的ID来帮助用户完成快照查询。因此这种表类型,能够智能平衡读取和写放大(wa),提供近乎实时的数据。这种表最重要的是压缩器,它用来选择将对应增量日志数据压缩到表的基本文件中,来保持查询时的性能(较大的增量日志文件会影响合并时间和查询时间)
下图说明了该表的工作原理,并显示两种查询类型:快照查询和读取优化查询
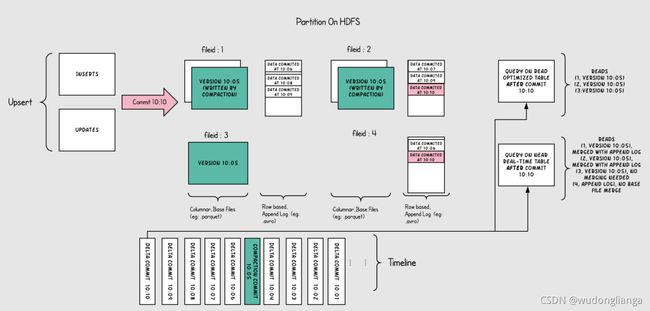
(1)如上图所示,现在每一分钟提交一次,这种操作是在别的表里(copy on write table)无法做到的
(2)现在有一个增量日志文件,它保存对基本列文件中记录的传入更新(对表的修改),在图中,增量日志文件包含从10:05到10:10的所有数据。基本列文件仍然使用commit来进行版本控制,因此如果只看基本列文件,那么表的表的布局就像copy on write表一样。
(3)定期压缩过程会协调增量日志文件和基本列文件进行合并,并生成新版本的基本列文件,就如图中10:05所发生的情况一样。
(4)查询表的方式有两种,Read Optimized query和Snapshot query,取决于我们选择是要查询性能还是数据新鲜度
(5)如上图所示,Read Optimized query查询不到10:05之后的数据(查询不到增量日志里的数据),而Snapshot query则可以查询到全量数据(基本列数据+行式的增量日志数据)。
(6)压缩触发是解决所有难题的关键,通过实施压缩策略,会快速缩新分区数据,来保证用户使用Read Optimized query可以查询到X分钟内的数据
Merge on Read Table是直接在DFS上启用近实时(near real-time)处理,而不是将数据复制到外部专用系统中。该表还有些次要的好处,例如通过避免数据的同步合并来减少写入放大(WA)
2.10 版本
0.9.0 适配 flink 1.12.2
0.10.0 适配 flink 1.13.1
3. 官网
https://hudi.apache.org/cn/
4.下载编译
4.1 修改flink 版本和hive 的版本
<properties>
<maven-jar-plugin.version>2.6</maven-jar-plugin.version>
<maven-surefire-plugin.version>3.0.0-M4</maven-surefire-plugin.version>
<maven-failsafe-plugin.version>3.0.0-M4</maven-failsafe-plugin.version>
<maven-shade-plugin.version>3.1.1</maven-shade-plugin.version>
<maven-javadoc-plugin.version>3.1.1</maven-javadoc-plugin.version>
<maven-compiler-plugin.version>3.8.0</maven-compiler-plugin.version>
<maven-deploy-plugin.version>2.4</maven-deploy-plugin.version>
<genjavadoc-plugin.version>0.15</genjavadoc-plugin.version>
<build-helper-maven-plugin.version>1.7</build-helper-maven-plugin.version>
<maven-enforcer-plugin.version>3.0.0-M1</maven-enforcer-plugin.version>
<java.version>1.8</java.version>
<fasterxml.version>2.6.7</fasterxml.version>
<fasterxml.jackson.databind.version>2.6.7.3</fasterxml.jackson.databind.version>
<fasterxml.jackson.module.scala.version>2.6.7.1</fasterxml.jackson.module.scala.version>
<fasterxml.jackson.dataformat.yaml.version>2.7.4</fasterxml.jackson.dataformat.yaml.version>
<fasterxml.spark3.version>2.10.0</fasterxml.spark3.version>
<kafka.version>2.0.0</kafka.version>
<confluent.version>5.3.4</confluent.version>
<glassfish.version>2.17</glassfish.version>
<parquet.version>1.10.1</parquet.version>
<junit.jupiter.version>5.7.0-M1</junit.jupiter.version>
<junit.vintage.version>5.7.0-M1</junit.vintage.version>
<junit.platform.version>1.7.0-M1</junit.platform.version>
<mockito.jupiter.version>3.3.3</mockito.jupiter.version>
<log4j.version>1.2.17</log4j.version>
<slf4j.version>1.7.15</slf4j.version>
<joda.version>2.9.9</joda.version>
<hadoop.version>3.1.1</hadoop.version>
<hive.groupid>org.apache.hive</hive.groupid>
<hive.version>3.1.0</hive.version>
<hive.exec.classifier>core</hive.exec.classifier>
<metrics.version>4.1.1</metrics.version>
<orc.version>1.6.0</orc.version>
<airlift.version>0.16</airlift.version>
<prometheus.version>0.8.0</prometheus.version>
<http.version>4.4.1</http.version>
<spark.version>${spark2.version}</spark.version>
<sparkbundle.version>${spark2bundle.version}</sparkbundle.version>
<flink.version>1.12.2</flink.version>
<spark2.version>2.4.4</spark2.version>
<spark3.version>3.0.0</spark3.version>
<spark2bundle.version></spark2bundle.version>
<spark3bundle.version>3</spark3bundle.version>
<hudi.spark.module>hudi-spark2</hudi.spark.module>
<avro.version>1.8.2</avro.version>
<scala11.version>2.11.12</scala11.version>
<scala12.version>2.12.10</scala12.version>
<scala.version>${scala11.version}</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<apache-rat-plugin.version>0.12</apache-rat-plugin.version>
<scala-maven-plugin.version>3.3.1</scala-maven-plugin.version>
<scalatest.version>3.0.1</scalatest.version>
<surefire-log4j.file>file://${project.basedir}/src/test/resources/log4j-surefire.properties</surefire-log4j.file>
<thrift.version>0.12.0</thrift.version>
<jetty.version>9.4.15.v20190215</jetty.version>
<htrace.version>3.1.0-incubating</htrace.version>
<hbase.version>1.2.3</hbase.version>
<codehaus-jackson.version>1.9.13</codehaus-jackson.version>
<h2.version>1.4.199</h2.version>
<awaitility.version>3.1.2</awaitility.version>
<skipTests>false</skipTests>
<skipUTs>${skipTests}</skipUTs>
<skipFTs>${skipTests}</skipFTs>
<skipITs>${skipTests}</skipITs>
<skip.hudi-spark2.unit.tests>${skipTests}</skip.hudi-spark2.unit.tests>
<skip.hudi-spark3.unit.tests>${skipTests}</skip.hudi-spark3.unit.tests>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<main.basedir>${project.basedir}</main.basedir>
<spark.bundle.hive.scope>provided</spark.bundle.hive.scope>
<spark.bundle.hive.shade.prefix />
<spark.bundle.avro.scope>compile</spark.bundle.avro.scope>
<spark.bundle.spark.shade.prefix>org.apache.hudi.spark.</spark.bundle.spark.shade.prefix>
<utilities.bundle.hive.scope>provided</utilities.bundle.hive.scope>
<utilities.bundle.hive.shade.prefix />
<argLine>-Xmx2g</argLine>
<jacoco.version>0.8.5</jacoco.version>
<presto.bundle.bootstrap.scope>compile</presto.bundle.bootstrap.scope>
<presto.bundle.bootstrap.shade.prefix>org.apache.hudi.</presto.bundle.bootstrap.shade.prefix>
<shadeSources>true</shadeSources>
<zk-curator.version>2.7.1</zk-curator.version>
<antlr.version>4.7</antlr.version>
<aws.sdk.version>1.12.22</aws.sdk.version>
</properties>
4.2 编译
git clone https://github.com/apache/hudi.git
mvn clean package -DskipTests
[INFO] Dependency-reduced POM written at: /opt/module/hudi/hudi0.9/Hudi/packaging/hudi-flink-bundle/target/dependency-reduced-pom.xml
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary for Hudi 0.9.0:
[INFO]
[INFO] Hudi ............................................... SUCCESS [ 7.475 s]
[INFO] hudi-common ........................................ SUCCESS [ 32.991 s]
[INFO] hudi-timeline-service .............................. SUCCESS [ 4.414 s]
[INFO] hudi-client ........................................ SUCCESS [ 0.178 s]
[INFO] hudi-client-common ................................. SUCCESS [ 16.918 s]
[INFO] hudi-hadoop-mr ..................................... SUCCESS [ 10.067 s]
[INFO] hudi-spark-client .................................. SUCCESS [ 36.746 s]
[INFO] hudi-sync-common ................................... SUCCESS [ 1.850 s]
[INFO] hudi-hive-sync ..................................... SUCCESS [ 8.815 s]
[INFO] hudi-spark-datasource .............................. SUCCESS [ 0.144 s]
[INFO] hudi-spark-common_2.11 ............................. SUCCESS [ 18.074 s]
[INFO] hudi-spark2_2.11 ................................... SUCCESS [ 24.700 s]
[INFO] hudi-spark_2.11 .................................... SUCCESS [01:11 min]
[INFO] hudi-utilities_2.11 ................................ SUCCESS [ 15.554 s]
[INFO] hudi-utilities-bundle_2.11 ......................... SUCCESS [ 20.892 s]
[INFO] hudi-cli ........................................... SUCCESS [ 23.277 s]
[INFO] hudi-java-client ................................... SUCCESS [ 4.321 s]
[INFO] hudi-flink-client .................................. SUCCESS [ 9.971 s]
[INFO] hudi-spark3_2.12 ................................... SUCCESS [ 16.785 s]
[INFO] hudi-dla-sync ...................................... SUCCESS [ 2.176 s]
[INFO] hudi-sync .......................................... SUCCESS [ 0.101 s]
[INFO] hudi-hadoop-mr-bundle .............................. SUCCESS [ 6.277 s]
[INFO] hudi-hive-sync-bundle .............................. SUCCESS [ 3.464 s]
[INFO] hudi-spark-bundle_2.11 ............................. SUCCESS [ 12.308 s]
[INFO] hudi-presto-bundle ................................. SUCCESS [ 6.020 s]
[INFO] hudi-timeline-server-bundle ........................ SUCCESS [ 5.296 s]
[INFO] hudi-hadoop-docker ................................. SUCCESS [ 2.008 s]
[INFO] hudi-hadoop-base-docker ............................ SUCCESS [ 1.146 s]
[INFO] hudi-hadoop-namenode-docker ........................ SUCCESS [ 0.976 s]
[INFO] hudi-hadoop-datanode-docker ........................ SUCCESS [ 1.237 s]
[INFO] hudi-hadoop-history-docker ......................... SUCCESS [ 1.817 s]
[INFO] hudi-hadoop-hive-docker ............................ SUCCESS [ 1.973 s]
[INFO] hudi-hadoop-sparkbase-docker ....................... SUCCESS [ 1.756 s]
[INFO] hudi-hadoop-sparkmaster-docker ..................... SUCCESS [ 1.120 s]
[INFO] hudi-hadoop-sparkworker-docker ..................... SUCCESS [ 1.020 s]
[INFO] hudi-hadoop-sparkadhoc-docker ...................... SUCCESS [ 0.924 s]
[INFO] hudi-hadoop-presto-docker .......................... SUCCESS [ 0.974 s]
[INFO] hudi-integ-test .................................... SUCCESS [ 15.944 s]
[INFO] hudi-integ-test-bundle ............................. SUCCESS [ 41.721 s]
[INFO] hudi-examples ...................................... SUCCESS [ 11.811 s]
[INFO] hudi-flink_2.11 .................................... SUCCESS [ 8.756 s]
[INFO] hudi-flink-bundle_2.11 ............................. SUCCESS [ 27.942 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 08:02 min
[INFO] Finished at: 2021-10-04T23:33:08+08:00
[INFO] ------------------------------------------------------------------------
[root@basenode Hudi]#
注意:默认是用scala-2.11编译的
如果我们用的是flink1.12.2-2.12版本,可以自己编译成scala-2.12版本的
mvn clean package -DskipTests -Dscala-2.12
包的路径在packaging/hudi-flink-bundle/target/hudi-flink-bundle_2.12-*.*.*-SNAPSHOT.jar
4.3 需要拷贝
编译好的jar 都在
[root@basenode Hudi]# cd packaging/
[root@basenode packaging]# ll
总用量 4
drwxr-xr-x 4 root root 46 10月 4 23:32 hudi-flink-bundle
drwxr-xr-x 4 root root 46 10月 4 23:30 hudi-hadoop-mr-bundle
drwxr-xr-x 4 root root 46 10月 4 23:30 hudi-hive-sync-bundle
drwxr-xr-x 4 root root 46 10月 4 23:31 hudi-integ-test-bundle
drwxr-xr-x 4 root root 46 10月 4 23:30 hudi-presto-bundle
drwxr-xr-x 4 root root 46 10月 4 23:30 hudi-spark-bundle
drwxr-xr-x 4 root root 101 10月 5 12:10 hudi-timeline-server-bundle
drwxr-xr-x 4 root root 46 10月 4 23:29 hudi-utilities-bundle
-rw-r--r-- 1 root root 2206 10月 4 22:55 README.md
[root@basenode packaging]# pwd
/opt/module/hudi/hudi0.9/Hudi/packaging
[root@basenode packaging]#
1.需要将 hudi-flink-bundle (hudi-flink-bundle_2.11-0.9.0.jar)和
hudi-hadoop-mr-bundle (hudi-hadoop-mr-bundle-0.9.0.jar) 拷贝到flink lib 中
5. flink jar
[root@node01 flink-1.12.2]# cd lib/
[root@node01 lib]# ll
总用量 386336
-rw-r--r-- 1 root root 197325 10月 5 11:40 flink-connector-jdbc_2.11-1.12.3.jar
-rw-r--r-- 1 root root 91744 10月 5 01:54 flink-csv-1.12.2.jar
-rw-r--r-- 1 root root 120338377 10月 5 02:16 flink-dist_2.11-1.12.2.jar
-rw-r--r-- 1 root root 81363 10月 5 11:38 flink-hadoop-compatibility_2.12-1.12.0.jar
-rw-r--r-- 1 root root 137004 10月 5 01:54 flink-json-1.12.2.jar
-rw-r--r-- 1 root root 43317025 10月 5 11:37 flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
-rw-r--r-- 1 root root 7709741 10月 5 01:16 flink-shaded-zookeeper-3.4.14.jar
-rw-r--r-- 1 root root 38101480 10月 5 11:37 flink-sql-connector-hive-2.3.6_2.11-1.11.0.jar
-rw-r--r-- 1 root root 36150119 10月 5 01:51 flink-table_2.11-1.12.2.jar
-rw-r--r-- 1 root root 40316477 10月 5 01:54 flink-table-blink_2.11-1.12.2.jar
-rw-r--r-- 1 root root 52111789 10月 5 11:40 hudi-flink-bundle_2.11-0.9.0.jar
-rw-r--r-- 1 root root 17409553 10月 5 11:40 hudi-hadoop-mr-bundle-0.9.0.jar
-rw-r--r-- 1 root root 36563462 10月 5 11:40 hudi-timeline-server-bundle-0.9.0.jar
-rw-r--r-- 1 root root 67114 10月 5 00:55 log4j-1.2-api-2.12.1.jar
-rw-r--r-- 1 root root 276771 10月 5 00:55 log4j-api-2.12.1.jar
-rw-r--r-- 1 root root 1674433 10月 5 00:55 log4j-core-2.12.1.jar
-rw-r--r-- 1 root root 23518 10月 5 00:55 log4j-slf4j-impl-2.12.1.jar
-rw-r--r-- 1 root root 1007502 10月 5 11:37 mysql-connector-java-5.1.47.jar
[root@node01 lib]# pwd
/opt/module/flink/flink12.2/flink-1.12.2/lib
[root@node01 lib]#
6.启动flink 连接flink
[root@node01 bin]# ./sql-client.sh embedded
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR or HADOOP_CLASSPATH was set.
Setting HBASE_CONF_DIR=/etc/hbase/conf because no HBASE_CONF_DIR was set.
No default environment specified.
Searching for '/opt/module/flink/flink12.2/flink-1.12.2/conf/sql-client-defaults.yaml'...found.
Reading default environment from: file:/opt/module/flink/flink12.2/flink-1.12.2/conf/sql-client-defaults.yaml
No session environment specified.
Command history file path: /root/.flink-sql-history
▒▓██▓██▒
▓████▒▒█▓▒▓███▓▒
▓███▓░░ ▒▒▒▓██▒ ▒
░██▒ ▒▒▓▓█▓▓▒░ ▒████
██▒ ░▒▓███▒ ▒█▒█▒
░▓█ ███ ▓░▒██
▓█ ▒▒▒▒▒▓██▓░▒░▓▓█
█░ █ ▒▒░ ███▓▓█ ▒█▒▒▒
████░ ▒▓█▓ ██▒▒▒ ▓███▒
░▒█▓▓██ ▓█▒ ▓█▒▓██▓ ░█░
▓░▒▓████▒ ██ ▒█ █▓░▒█▒░▒█▒
███▓░██▓ ▓█ █ █▓ ▒▓█▓▓█▒
░██▓ ░█░ █ █▒ ▒█████▓▒ ██▓░▒
███░ ░ █░ ▓ ░█ █████▒░░ ░█░▓ ▓░
██▓█ ▒▒▓▒ ▓███████▓░ ▒█▒ ▒▓ ▓██▓
▒██▓ ▓█ █▓█ ░▒█████▓▓▒░ ██▒▒ █ ▒ ▓█▒
▓█▓ ▓█ ██▓ ░▓▓▓▓▓▓▓▒ ▒██▓ ░█▒
▓█ █ ▓███▓▒░ ░▓▓▓███▓ ░▒░ ▓█
██▓ ██▒ ░▒▓▓███▓▓▓▓▓██████▓▒ ▓███ █
▓███▒ ███ ░▓▓▒░░ ░▓████▓░ ░▒▓▒ █▓
█▓▒▒▓▓██ ░▒▒░░░▒▒▒▒▓██▓░ █▓
██ ▓░▒█ ▓▓▓▓▒░░ ▒█▓ ▒▓▓██▓ ▓▒ ▒▒▓
▓█▓ ▓▒█ █▓░ ░▒▓▓██▒ ░▓█▒ ▒▒▒░▒▒▓█████▒
██░ ▓█▒█▒ ▒▓▓▒ ▓█ █░ ░░░░ ░█▒
▓█ ▒█▓ ░ █░ ▒█ █▓
█▓ ██ █░ ▓▓ ▒█▓▓▓▒█░
█▓ ░▓██░ ▓▒ ▓█▓▒░░░▒▓█░ ▒█
██ ▓█▓░ ▒ ░▒█▒██▒ ▓▓
▓█▒ ▒█▓▒░ ▒▒ █▒█▓▒▒░░▒██
░██▒ ▒▓▓▒ ▓██▓▒█▒ ░▓▓▓▓▒█▓
░▓██▒ ▓░ ▒█▓█ ░░▒▒▒
▒▓▓▓▓▓▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒░░▓▓ ▓░▒█░
______ _ _ _ _____ ____ _ _____ _ _ _ BETA
| ____| (_) | | / ____|/ __ \| | / ____| (_) | |
| |__ | |_ _ __ | | __ | (___ | | | | | | | | |_ ___ _ __ | |_
| __| | | | '_ \| |/ / \___ \| | | | | | | | | |/ _ \ '_ \| __|
| | | | | | | | < ____) | |__| | |____ | |____| | | __/ | | | |_
|_| |_|_|_| |_|_|\_\ |_____/ \___\_\______| \_____|_|_|\___|_| |_|\__|
Welcome! Enter 'HELP;' to list all available commands. 'QUIT;' to exit.
6.1 创建表插入数据
创建表
Flink SQL> CREATE TABLE t6(
> uuid VARCHAR(20),
> name VARCHAR(10),
> age INT,
> ts TIMESTAMP(3),
> `partition` VARCHAR(20)
> )
> PARTITIONED BY (`partition`)
> WITH (
> 'connector' = 'hudi',
> 'path' = 'hdfs://192.168.1.161:8020/hudi/t6',
> 'table.type' = 'MERGE_ON_READ'
> );
插入数据
Flink SQL> INSERT INTO t6 VALUES
> ('id11','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'),
> ('id12','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),
> ('id13','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),
> ('id14','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'),
> ('id15','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),
> ('id16','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),
> ('id17','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),
> ('id18','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');
[INFO] Submitting SQL update statement to the cluster...
[INFO] Table update statement has been successfully submitted to the cluster:
Job ID: 855442379d4a88701372ff0570a1a1db
6.2 查看flink 日志

6.3 查看hdfs 中的
[root@node01 module]# hdfs dfs -ls /hudi/t6
Found 6 items
drwxr-xr-x - root hdfs 0 2021-10-05 03:24 /hudi/t6/.hoodie
drwxr-xr-x - root hdfs 0 2021-10-05 03:24 /hudi/t6/par1
drwxr-xr-x - root hdfs 0 2021-10-05 02:58 /hudi/t6/par2
drwxr-xr-x - root hdfs 0 2021-10-05 03:11 /hudi/t6/par3
drwxr-xr-x - root hdfs 0 2021-10-05 02:58 /hudi/t6/par4
drwxr-xr-x - root hdfs 0 2021-10-05 03:24 /hudi/t6/par5
[root@node01 module]#
在分区中的数据
[root@node01 module]# hdfs dfs -ls /hudi/t1/par1/
Found 9 items
-rw-r--r-- 3 root hdfs 1074 2021-10-05 02:58 /hudi/t6/par1/.cad14418-3e18-42f7-a0a1-6e2145ca228c_20211005025818.log.1_0-4-0
-rw-r--r-- 3 root hdfs 960 2021-10-05 02:59 /hudi/t6/par1/.cad14418-3e18-42f7-a0a1-6e2145ca228c_20211005025818.log.2_0-4-0
-rw-r--r-- 3 root hdfs 960 2021-10-05 03:03 /hudi/t6/par1/.cad14418-3e18-42f7-a0a1-6e2145ca228c_20211005025818.log.3_0-4-0
-rw-r--r-- 3 root hdfs 965 2021-10-05 03:04 /hudi/t6/par1/.cad14418-3e18-42f7-a0a1-6e2145ca228c_20211005025818.log.4_0-4-0
-rw-r--r-- 3 root hdfs 969 2021-10-05 03:06 /hudi/t6/par1/.cad14418-3e18-42f7-a0a1-6e2145ca228c_20211005025818.log.5_0-4-0
-rw-r--r-- 3 root hdfs 1078 2021-10-05 03:11 /hudi/t6/par1/.cad14418-3e18-42f7-a0a1-6e2145ca228c_20211005025818.log.6_0-4-0
-rw-r--r-- 3 root hdfs 1079 2021-10-05 03:12 /hudi/t6/par1/.cad14418-3e18-42f7-a0a1-6e2145ca228c_20211005025818.log.7_0-4-0
-rw-r--r-- 3 root hdfs 961 2021-10-05 03:24 /hudi/t6/par1/.cad14418-3e18-42f7-a0a1-6e2145ca228c_20211005025818.log.8_0-4-0
-rw-r--r-- 3 root hdfs 93 2021-10-05 02:58 /hudi/t6/par1/.hoodie_partition_metadata
[root@node01 module]#
7查看数据
Flink SQL> select * from t6;
SQL Query Result (Table)
Table program finished. Page: Last of 1 Updated: 11:56:09.865
uuid name age ts partition
id13 Julian 53 1970-01-01T00:00:03 par2
id14 Fabian 31 1970-01-01T00:00:04 par2
id1 Danny 19 1970-01-01T00:00:01 par1
id11 Danny 23 1970-01-01T00:00:01 par1
id12 Stephen 33 1970-01-01T00:00:02 par1
id16 Emma 20 1970-01-01T00:00:06 par3
id15 Sophia 18 1970-01-01T00:00:05 par3
id17 Bob 44 1970-01-01T00:00:07 par4
id18 Han 56 1970-01-01T00:00:08 par4
7.1 在插入一条数据有点
Flink SQL> INSERT INTO t6 VALUES ('id1','Danny',33,TIMESTAMP '1970-01-01 00:00:01','par1');
[INFO] Submitting SQL update statement to the cluster...
[INFO] Table update statement has been successfully submitted to the cluster:
Job ID: 465e6db08a26348926226edfd796ea8c
遇到个问题:插入成功后,日志也没有报错日志
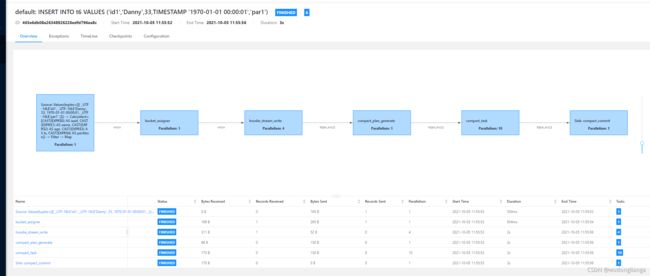
7.2 查询 出来还是没有更新, 不知道哪个环节出问题了。
Flink SQL> INSERT INTO t6 VALUES ('id1','Danny',33,TIMESTAMP '1970-01-01 00:00:01','par1');
[INFO] Submitting SQL update statement to the cluster...
[INFO] Table update statement has been successfully submitted to the cluster:
Job ID: 465e6db08a26348926226edfd796ea8c
Flink SQL> select * from t6;
SQL Query Result (Table)
Table program finished. Page: Last of 1 Updated: 11:56:09.865
uuid name age ts partition
id13 Julian 53 1970-01-01T00:00:03 par2
id14 Fabian 31 1970-01-01T00:00:04 par2
id1 Danny 19 1970-01-01T00:00:01 par1
id11 Danny 23 1970-01-01T00:00:01 par1
id12 Stephen 33 1970-01-01T00:00:02 par1
id16 Emma 20 1970-01-01T00:00:06 par3
id15 Sophia 18 1970-01-01T00:00:05 par3
id17 Bob 44 1970-01-01T00:00:07 par4
id18 Han 56 1970-01-01T00:00:08 par4