广告行业中那些趣事系列48:如何快速得到效果好性能快的文本分类器?
导读:本文是“数据拾光者”专栏的第四十八篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇主要总结了小X语音助手安全服务模型的优化实践,对于希望快速得到效果好性能快的文本分类模型的小伙伴可能有所帮助。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者
摘要:本篇主要总结了小X语音助手安全服务模型的优化实践。首先介绍了小X语音助手安全服务模型背景以及任务类型;然后重点介绍了在优化任务中的实践,包括线上算法服务介绍、第一阶段样本优化实践和第二阶段通过知识蒸馏的方式优化模型,最后分享了后续的优化思路。对于希望快速得到效果好性能快的文本分类模型的小伙伴可能有所帮助。
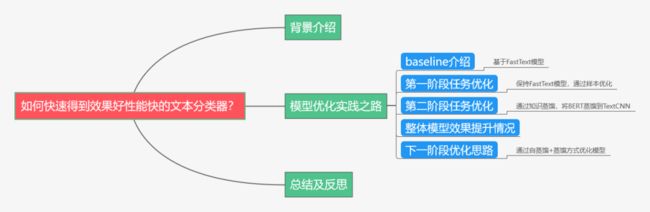
下面主要按照如下思维导图进行学习分享:
01
背景介绍
最近一段时间主要工作是优化小X语音助手的安全服务模型,有了一些阶段性的成果,这里整理成一篇文章和小伙伴们分享。语音助手服务大家应该也用了很多,我做的主要是对用户的语音query请求进行安全拦截操作,业务意义在于将一些违法、涉政、低俗等相关的请求进行拦截,提升用户体验,从任务类型来看就是一个文本二分类问题。
02
模型优化实践之路
2.1 baseline介绍
当时接手任务的时候已经有线上算法服务了,我们的工作属于算法优化任务。由于每天的query请求是千万级别的,对线上的性能要求很高,模型使用的是基于FastText模型构建的文本分类器。关于FastText模型的详细介绍可以参考下我之前写过的一篇文章《广告行业中那些趣事系列44:NLP不可不学的FastText模型》。简单来说FastText算法非常简单高效,线上性能很好,模型效果也还说的过去。当然相比于当前NLP主流的BERT等预训练模型来说效果可能要差很多。这里我们评估模型的效果主要是控制一定的召回率情况下查看精度,线上业务使用的是保持召回率0.99的前提下查看精度。线上服务中样本方面之前的同事也做了一些样本增强工作,比如同义词替换等操作。
2.2 第一阶段任务优化
由于刚接手任务,第一阶段目标是熟悉当前算法整个流程,并进行一定程度的优化。为了达到这个目标,最简单有效并且能快速出成果的方法是保持算法不变通过优化样本得到一个更好的模型权重,将这个模型权重部署到线上即可,并不用大改线上的算法服务。这样做的好处在于可以快速了解线上算法服务流程,同时还能进行一定程度的优化。对于我们这种业务优先的团队来说,能快速的看到业务效果是非常重要的。很多算法小伙伴可能接到这一类需求之后,会从模型到服务大改,想一步优化到位。但是实际情况是这种优化套路可能会存在问题,可能新的模型尝试、线上算法服务变更会花费过长的时间,导致业务长期没有阶段性的成果产出。
确定了第一阶段的优化目标是保持模型不变,从样本层面优化算法服务之后,那么重点就是如何优化样本了。我这里的核心思路是使用BERT这一类效果比较好的算法去训练一个分类器,同时让这个分类器去预测线上业务相关数据得到伪标签样本,将伪标签样本用于扩充训练集。BERT这一类预训练模型的优势在于模型效果很好,但缺点是模型权重很大,很难部署到线上。这里利用BERT效果好的优势去扩充训练集,然后用扩充之后的训练集基于FastText训练一个新的分类器去部署上线。这样对于线上服务来说,算法和线上服务代码并没有变化,只是模型权重更新了。
线上随机采样了600W业务相关的数据,使用BERT训练得到的分类器去预测得到伪标签样本并用于扩充训练集,下面是实验组介绍:
对照组:使用线上算法模型原始的训练集数据
Lab1:选择BERT模型预测为1并且概率得分大于0.95的样本
Lab2:选择BERT模型预测为1并且概率得分大于0.9的样本
Lab3:选择BERT模型预测为1并且概率得分大于0.85的样本
Lab4:选择BERT模型预测为1并且概率得分大于0.8的样本
Lab5:选择BERT模型预测为0和1并且概率得分大于0.7,并且正样本采样10W,负样本采样50W
Lab6:将BERT模型打上伪标签的样本全部增加到训练集中
这里lab1-lab4只选择正样本,也就是安全服务模型认为需要拦截的query。因为训练集中正负样本比例差别较大,正样本比较少,所以这里主要增加正样本数量。选择不同的概率得分是为了查看增加的正样本对模型的提升情况。Lab5和lab6会同时选择正负样本,只是lab5会选择置信度较高,得分大于0.7的,并且采样10W正样本和50W负样本。而lab6则将BERT模型打上的伪标签样本全部用于扩充训练集。下面是相比于baseline模型的精度提升百分比情况:

图1 第一阶段各实验组模型效果提升比例
从上面的实验结果中可以看出,通过训练BERT分类器然后去业务相关的线上数据中预测伪标签扩充训练集的思路是正确的,相比于baseline都有不同程度的效果提升。其中效果最好的是lab5,也就是同时增加正负样本,并且选择得分概率大于0.7的,采样10W正样本和50W负样本的策略,提升比例为24.58%。这里关于正负样本的选择其实还有更精细的策略,值得进一步研究。
2.3 第二阶段任务优化
第一阶段任务主要是保持模型不变从样本层面优化提升算法效果。经过第一阶段优化,我对小X安全服务整个线上算法流程有了一定了解,为后面的优化打下了一定的基础,同时算法效果还得到了一定程度的提升,算是初步完成了任务。第二阶段我打算使用稍微复杂的模型,但是因为线上请求量很高,所以需要在保持线上性能的情况下提升模型效果。这里算法打算使用TextCNN,相比于FastText来说算法复杂度有一定提升,难点在于保证性能满足线上的需求。如果单纯使用TextCNN模型替换线上模型,效果提升有限,这时候就需要使用知识蒸馏的方式,将BERT作为老师学到的知识传授给TextCNN了。这里关于知识蒸馏的介绍小伙伴们可以参考我之前写过的一篇文章《广告行业中那些趣事系列21:从理论到实战BERT知识蒸馏》。简单来说知识蒸馏就是将BERT这一类效果比较好的模型学习到的知识蒸馏到轻量级的模型上(比如TextCNN),这样上线的时候只需要部署TextCNN就可以了,不仅可以满足线上的性能,而且效果非常不错,可以媲美老师模型。
这里还是使用之前随机采样的600W数据作为蒸馏样本,分别使用微调和不微调BERT策略去构建实验组:
Lab7:使用不微调的BERT训练分类器,去预测600W数据集得到logits
Lab8:使用微调的BERT训练分类器,去预测600W数据集得到logits
因为蒸馏模型效果的好坏一定程度上决定于老师模型效果的好坏,所以需要让老师模型的效果足够好。这里分别尝试了基于BERT不微调和微调来构建老师模型,下面是实验组结果:

图2 第二阶段各实验组模型效果提升
使用同样的无标签数据集作为蒸馏样本,经过知识蒸馏的方式模型的效果提升非常惊人。不微调BERT构建老师模型,蒸馏到textCNN上模型效果提升为119.18%,微调BERT构建老师模型再进行蒸馏直接效果提升到了195.03%,达到了当前最好效果。从这可以看出知识蒸馏的威力,仅使用600W无标签数据集就可以达到如此大的效果提升。蒸馏效果依赖于两个重要的因素,一个是老师模型效果的好坏,这里可以看出经过微调的BERT模型效果会更好。第二个因素则是蒸馏的数据量级,这里增加无标签数据集的规模模型效果应该还会有不错的提升。而业务相关的无标签数据集是比较容易获得的,所以知识蒸馏技术潜力巨大。
2.4 整体模型效果提升情况
整体来看安全服务模型效果提升经过两个阶段,第一个阶段是保持FastText模型不变通过样本优化来提升模型效果,提升比例为24.58%;第二个阶段则是通过知识蒸馏的方式,将BERT作为老师模型传授知识给TextCNN,从而提升模型效果。当BERT不进行微调模型效果提升119.18%,当BERT进行微调模型效果提升比例为195.03%。下面是安全服务模型效果提升情况:

图3 安全服务模型效果提升图
2.5 下一阶段优化思路
第二阶段通过知识蒸馏的方式可以有效提升安全服务模型的效果,上面也提到了两个重要的优化点,第一个是老师模型效果的好坏会直接决定蒸馏模型的上限。针对这个问题打算采用自蒸馏的方式更好的使用无标签数据集去蒸馏得到一个更好的老师模型。自蒸馏的原因是在实际任务中我们发现一个现象,有时候蒸馏得到的学生模型效果会优于老师模型,也就是可能学生textCNN模型的效果会优于老师BERT模型,这里的主要原因可能是蒸馏的时候会使用大量的无标签数据集,这会提升学生模型的泛化能力。而老师模型使用的训练集有限。这里通过自蒸馏的方式将BERT作为老师1去蒸馏一个学生模型1,只不过这个学生模型也用的BERT。然后用这个蒸馏得到的BERT模型作为老师2把学习到的知识教给TextCNN学生2模型,最后将这个TextCNN部署到线上。整体流程如下图所示:

图3 整体流程图
第二个优化点是使用更多的无标签数据集作为蒸馏样本,因为样本更多蒸馏得到的模型效果也越好。这里主要是无标签数据集的选择以及模型训练性能优化。通过上述两点来进一步优化安全服务模型。
03
总结及反思
本篇主要总结了小X语音助手安全服务模型的优化实践。首先介绍了小X语音助手安全服务模型背景以及任务类型;然后重点介绍了在优化任务中的实践,包括线上算法服务介绍、第一阶段样本优化实践和第二阶段通过知识蒸馏的方式优化模型,最后分享了后续的优化思路。对于希望快速得到效果好性能快的文本分类模型的小伙伴可能有所帮助。
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。

码字不易,欢迎小伙伴们点赞和分享。