机器学习第3集——随机森林 详解+案例
一、集成学习(ensemble learning)
1、什么是集成学习
集成学习(ensemble learning)是时下非常流行的机器学习算法,它本身不是一个单独的机器学习算法,而是通 过在数据上构建多个模型,集成所有模型的建模结果。
2、常用的集成学习算法
在现在的各种算法竞赛中,随机森林,梯度提升树(GBDT),Xgboost等集成 算法的身影也随处可见,可见其效果之好,应用之广。
多个模型集成成为的模型叫做集成评估器(ensemble estimator),组成集成评估器的每个模型都叫做基评估器 (base estimator)。通常来说,有三类集成算法:装袋法(Bagging),提升法(Boosting)和stacking。

3、集成学习的应用
基本上所有的机器学习领域都可以看到集成学习的身影,在 现实中集成学习也有相当大的作用,它可以用来做市场营销模拟的建模,统计客户来源,保留和流失,也可用来预测疾病的风险和病患者的易感性。
4、集成算法的目标
5、sklearn中的集成算法
sklearn中的集成算法模块:ensemble

二、随机森林分类器(RandomForestClassififier)
1、先看看随机森林分类器类
class sklearn.ensemble.RandomForestClassifier (
n_estimators=’10’,
criterion=’gini’,
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=’auto’,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
in_impurity_split=None,
bootstrap=True,
oob_score=False,
n_jobs=None,
random_state=None,
verbose=0,
arm_start=False,
class_weight=None
)随机森林是非常具有代表性的Bagging集成算法,它的所有基评估器都是决策树,分类树组成的森林就叫做随机森林分类器,回归树所集成的森林就叫做随机森林回归器。
2、重要参数
2.1 控制基评估器的参数
①criterion,用来决定不纯度的计算方法,可选项有两个为:entropy(信息熵)、gini(基尼系数);在实际使用中,信息熵和基尼系数的效果基本相同。
②max_depth,限制树的最大深度,超过设定深度的树枝全部剪掉 。
③min_samples_split,一个节点必须要包含至少min_samples_split个训练样本,这个节点才允许被分枝,否则 分枝就不会发生。
④min_samples_leaf,一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分枝就不会发生。或者理解为所有的叶子结点必须至少包含min_samples_split个训练样本。
⑤max_feature,限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃。和max_depth异曲同工。
⑥min_impurity_decrease,限制信息增益的大小,信息增益小于设定数值的分枝不会发生。这是在0.19版本中更新的 功能,在0.19版本之前时使用min_impurity_split。
2.2 n_estimators
这是森林中树木的数量,即基评估器的数量。这个参数对随机森林模型的精确性影响是单调的,n_estimators越 大,模型的效果往往越好。但是相应的,任何模型都有决策边界,n_estimators达到一定的程度之后,随机森林的精确性往往不在上升或开始波动,并且,_estimators越大,需要的计算量和内存也越大,训练的时间也会越来越长。对于这个参数,我们是渴望在训练难度和模型效果之间取得平衡。
2.3 bootstrap
bootstrap就是用来控制抽样技 术的参数。bootstrap参数默认True,代表采用这种有放回的随机抽样技术。通常,这个参数不会被我 们设置为False。
2.4 oob_score
如果希望用袋外数据来测试,则需要在实例化时就将oob_score这个参数调整为True,训练完毕之后,我们可以用随机森林的另一个重要属性:oob_score_来查看我们的在袋外数据上测试的结果
3、实例:建立一篇森林
树模型的优点是简单易懂,可视化之后的树人人都能够看懂,可惜随机森林是无法被可视化的。所以为了更加直观地让大家体会随机森林的效果,我们来进行一个随机森林和单个决策树效益的对比。我们使用红酒数据集。
# 本代码运行环境为 jupyter lab 或 jupyter notebook
# 导入需要的模块
%matplotlib inline
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
# 导入数据集
wine = load_wine()
# 分别查看一下数据集中的“特征矩阵”和“目标标签”
wine.data
wine.target
# 先建立一棵决策树和一个随机森林,用以相互对比
from sklearn.model_selection import train_test_split # 导入划分训练集测试集的模块
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3) # 设置训练集和测试集
clf = DecisionTreeClassifier(random_state=0) #实例化决策树
rfc = RandomForestClassifier(random_state=0) #实例化随机森林
clf = clf.fit(Xtrain,Ytrain) #训练决策树
rfc = rfc.fit(Xtrain,Ytrain) #训练随机森林
score_c = clf.score(Xtest,Ytest) #给决策树评分
score_r = rfc.score(Xtest,Ytest) #给随机森林评分
print("Single Tree:{}".format(score_c),"Random Forest:{}".format(score_r)) #输出结果结果如下:
Single Tree:0.9444444444444444 Random Forest:0.9814814814814815
#下面对决策树和随机森林的得分进行一下比较
#画出随机森林和决策树在一组交叉验证下的效果对比
#交叉验证:是数据集划分为n分,依次取每一份做测试集,每n-1份做训练集,多次训练模型以观测模型稳定性的方法
from sklearn.model_selection import cross_val_score # 导入交叉验证方法
import matplotlib.pyplot as plt # 导入画图模块
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf,wine.data,wine.target,cv=10)
plt.plot(range(1,11),rfc_s,label = "RandomForest")
plt.plot(range(1,11),clf_s,label = "Decision Tree")
plt.legend()
plt.show()结果如下:

#画出随机森林和决策树在十组交叉验证下的效果对比
rfc_l = [] #用于存放随机森林分类树十次交叉验证的得分
clf_l = [] #用于存放单棵决策树十次交叉验证的得分
for i in range(10):
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
rfc_l.append(rfc_s)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf,wine.data,wine.target,cv=10).mean()
clf_l.append(clf_s)
plt.plot(range(1,11),rfc_l,label = "Random Forest")
plt.plot(range(1,11),clf_l,label = "Decision Tree")
plt.legend()
plt.show()
#验证了单个决策树的准确率越高,随机森林的准确率也会越高输出结果为:

下面观察一下不同的的 n_estimators 参数,对应的模型得分
也就是森林中不同的树木数量所对应的模型得分情况
#####【TIME WARNING: 2mins 30 seconds】#####
superpa = []
for i in range(200):
rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
superpa.append(rfc_s)
print(max(superpa),superpa.index(max(superpa))+1)#打印出:最高精确度取值,max(superpa))+1指的是森林数目的数量n_estimators
plt.figure(figsize=[20,5])
plt.plot(range(1,201),superpa)
plt.show()输出结果为:
0.9888888888888889 15

4、重要属性和接口
.estimators_
.obb_score_
.apply
.fit
.predict
.score
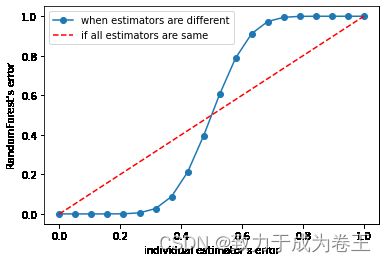
5、能否使用随机森林一定要去判断的一个条件
import numpy as np
x = np.linspace(0,1,20)
y = []
for epsilon in np.linspace(0,1,20):
E = np.array([comb(25,i)*(epsilon**i)*((1-epsilon)**(25-i)) for i in range(13,26)]).sum()
y.append(E)
plt.plot(x,y,"o-",label="when estimators are different")
plt.plot(x,x,"--",color="red",label="if all estimators are same")
plt.xlabel("individual estimator's error")
plt.ylabel("RandomForest's error")
plt.legend()
plt.show()