知识图谱-KGE-语义匹配-双线性模型(打分函数用到了双线性函数)-2013:NTN(Neural Tensor Network)
【paper】 Reasoning With Neural Tensor Networks for Knowledge Base Completion
【简介】 本文是斯坦福大学陈丹琦所在团队 2013 年的工作,好像是发表在一个期刊上的。文章提出了用于知识库补全的神经网络框架 NTN(Neural Tensor Network),网络结构/打分函数中同时包含双线性函数和线性函数,并用词向量的平均作为实体的表示。
Intro 和 Related Work
NTN 的模型结构图如下:
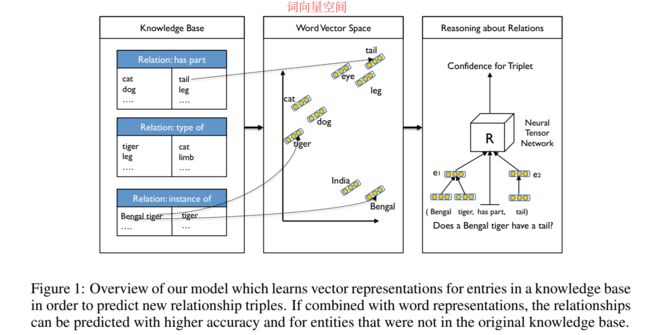
首先得到词向量空间中词的表示,然后用词的组合作为实体的表示,输入神经张量网络,进行置信度打分。
文章的 related work 也值得学习,每一段介绍了一种方法,并阐述了本文方法与前人方法的关联。
文中也提到,NTN 可以被视为学习张量分解的一种方法,类似于 Rescal。
模型
打分函数定义
NTN 定义的打分函数为:
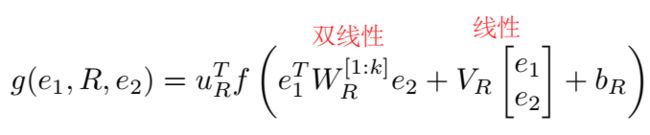
f 是 tanh 非线性激活函数,WRWR 是一个张量。模型示意图如下:

虚线框内的暖色矩阵是张量 WRWR 的一个 slice,对应一个关系,用于头尾实体的交互。
相关模型与 NTN 特例
这部分介绍与 NTN 相关的模型和在特殊情况下 NTN 的表现形式。
- Distance Model(之前看过的翻译模型 SE)

这种模型的缺点是两个实体之间没有交互。
- Single Layer Model(SLM)
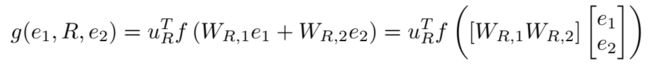
SLM 是普通的线性模型,是 NTN 中去掉双线性部分的表现形式(将 tensor 设置)。昨天看的 LFM 是纯双线性函数,没有线性部分,因此之前有论文说 NTN 是 SLM 和 LFM 的联合,这就对上了。
- Hadamard Model
![]()
这是 Antoine Bordes 2012 年提出的 UM,应该属于从线性到双线性的一个过渡模型。
- Bilinear Model
![]()
这个就是 LFM 双线性模型了,没有线性变换。
训练目标

实体表示初始化
用词向量的平均作为实体向量,文章还试验了 RNN,普通的平均操作效果差不多。
实验
关系三元组分类
整体数据集上的效果:

在每个关系上的效果:
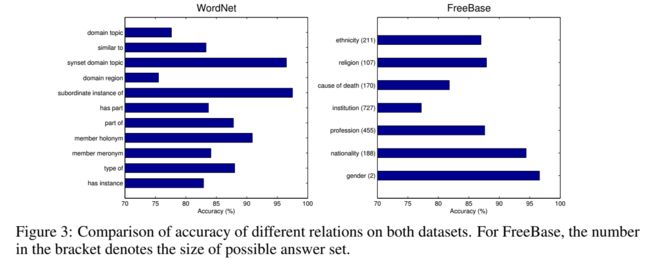
对于每个关系下的分类效果各不相同的现象,文章给出的解释是:由于关系的模糊语义导致难以推断,因此在有些关系下分类效果差。
文章还对比了三种向量初始化方法的效果:不使用词向量初始化(EV);随机初始化的词向量(WV);用无监督语料训练的词向量(WV-init)

Case Study

代码
文中给出的代码链接失效了。Pykg2vec 给出了 NTN 的实现:
class NTN(PairwiseModel):
"""
`Reasoning With Neural Tensor Networks for Knowledge Base Completion`_ (NTN) is
a neural tensor network which represents entities as an average of their constituting
word vectors. It then projects entities to their vector embeddings
in the input layer. The two entities are then combined and mapped to a non-linear hidden layer.
https://github.com/siddharth-agrawal/Neural-Tensor-Network/blob/master/neuralTensorNetwork.py
It is a neural tensor network which represents entities as an average of their constituting word vectors. It then projects entities to their vector embeddings in the input layer. The two entities are then combined and mapped to a non-linear hidden layer.
Portion of the code based on `siddharth-agrawal`_.
Args:
config (object): Model configuration parameters.
.. _siddharth-agrawal:
https://github.com/siddharth-agrawal/Neural-Tensor-Network/blob/master/neuralTensorNetwork.py
.. _Reasoning With Neural Tensor Networks for Knowledge Base Completion:
https://nlp.stanford.edu/pubs/SocherChenManningNg_NIPS2013.pdf
"""
def __init__(self, **kwargs):
super(NTN, self).__init__(self.__class__.__name__.lower())
param_list = ["tot_entity", "tot_relation", "ent_hidden_size", "rel_hidden_size", "lmbda"]
param_dict = self.load_params(param_list, kwargs)
self.__dict__.update(param_dict)
self.ent_embeddings = NamedEmbedding("ent_embedding", self.tot_entity, self.ent_hidden_size)
self.rel_embeddings = NamedEmbedding("rel_embedding", self.tot_relation, self.rel_hidden_size)
self.mr1 = NamedEmbedding("mr1", self.ent_hidden_size, self.rel_hidden_size)
self.mr2 = NamedEmbedding("mr2", self.ent_hidden_size, self.rel_hidden_size)
self.br = NamedEmbedding("br", 1, self.rel_hidden_size)
self.mr = NamedEmbedding("mr", self.rel_hidden_size, self.ent_hidden_size*self.ent_hidden_size)
nn.init.xavier_uniform_(self.ent_embeddings.weight)
nn.init.xavier_uniform_(self.rel_embeddings.weight)
nn.init.xavier_uniform_(self.mr1.weight)
nn.init.xavier_uniform_(self.mr2.weight)
nn.init.xavier_uniform_(self.br.weight)
nn.init.xavier_uniform_(self.mr.weight)
self.parameter_list = [
self.ent_embeddings,
self.rel_embeddings,
self.mr1,
self.mr2,
self.br,
self.mr,
]
self.loss = Criterion.pairwise_hinge
def train_layer(self, h, t):
""" Defines the forward pass training layers of the algorithm.
Args:
h (Tensor): Head entities ids.
t (Tensor): Tail entity ids of the triple.
"""
mr1h = torch.matmul(h, self.mr1.weight) # h => [m, self.ent_hidden_size], self.mr1 => [self.ent_hidden_size, self.rel_hidden_size]
mr2t = torch.matmul(t, self.mr2.weight) # t => [m, self.ent_hidden_size], self.mr2 => [self.ent_hidden_size, self.rel_hidden_size]
expanded_h = h.unsqueeze(dim=0).repeat(self.rel_hidden_size, 1, 1) # [self.rel_hidden_size, m, self.ent_hidden_size]
expanded_t = t.unsqueeze(dim=-1) # [m, self.ent_hidden_size, 1]
temp = (torch.matmul(expanded_h, self.mr.weight.view(self.rel_hidden_size, self.ent_hidden_size, self.ent_hidden_size))).permute(1, 0, 2) # [m, self.rel_hidden_size, self.ent_hidden_size]
htmrt = torch.squeeze(torch.matmul(temp, expanded_t), dim=-1) # [m, self.rel_hidden_size]
return F.tanh(htmrt + mr1h + mr2t + self.br.weight)
def embed(self, h, r, t):
"""Function to get the embedding value.
Args:
h (Tensor): Head entities ids.
r (Tensor): Relation ids of the triple.
t (Tensor): Tail entity ids of the triple.
Returns:
Tensors: Returns head, relation and tail embedding Tensors.
"""
emb_h = self.ent_embeddings(h)
emb_r = self.rel_embeddings(r)
emb_t = self.ent_embeddings(t)
return emb_h, emb_r, emb_t
def forward(self, h, r, t):
h_e, r_e, t_e = self.embed(h, r, t)
norm_h = F.normalize(h_e, p=2, dim=-1)
norm_r = F.normalize(r_e, p=2, dim=-1)
norm_t = F.normalize(t_e, p=2, dim=-1)
return -torch.sum(norm_r*self.train_layer(norm_h, norm_t), -1)
def get_reg(self, h, r, t):
return self.lmbda*torch.sqrt(sum([torch.sum(torch.pow(var.weight, 2)) for var in self.parameter_list]))
【小结】 本文提出了神经张量模型 NTN,在打分函数中同时使用了双线性和线性操作,双线性操作中定义了张量用于捕捉头尾实体间的交互。NTN 使用预训练词向量的平均作为实体向量的初始化表示。
双线性模型(二)(NTN、SLM、SME) - 胡萝不青菜 - 博客园