【论文阅读笔记】A review of the deep learning methods for medical images super resolution problems
摘要
医疗图像中分辨率的限制来源于:图像采集次数的限制,由于硬件限制导致的低辐射(Low irradiation)等。
这篇综述应该比较基础,从深度学习 -> 超分网络架构 -> 再到医疗图像超分问题的介绍。对于医疗方向的介绍可能较少。
论文简介
相较于自然图像SR,医疗图像SR需要额外的先验信息才能用于特定应用。医学图像的数据集相对较小且难以收集,尤其是对于临床高分辨率和低分辨率图像对。在文末的时候,会讨论如何处理数据集缺乏和整合先验信息的挑战。
超分方向的深度学习
图像下采样的过程中,一般包含三个步骤:模糊(blurring)、噪声(noising)、下采样(down sampling)。
损失函数
通过MSE得到的超分辨率图像感官效果较差。感知损失基于深层架构产生的特征得到的。在[47]中,超分网络的优化是通过预训练的VGG16网络产生特征的MSE优化的。特征损失鼓励两个图像从感官相似度匹配,而不是从像素之间匹配。VGG和ResNet是广泛使用的两个预训练CNN网络。在[48]中提出了与不同特征通道之间的相关性相对应的纹理损失,以创建更逼真的纹理。这个是不是y通道单独弄出来损失的意思?还是有其他的通道表示?在GAN的训练方式下,也有使用对抗性损失,判别器和生成器交替训练。
网络架构
介绍了两种使用循环结构的网络DRCN和DRRN。
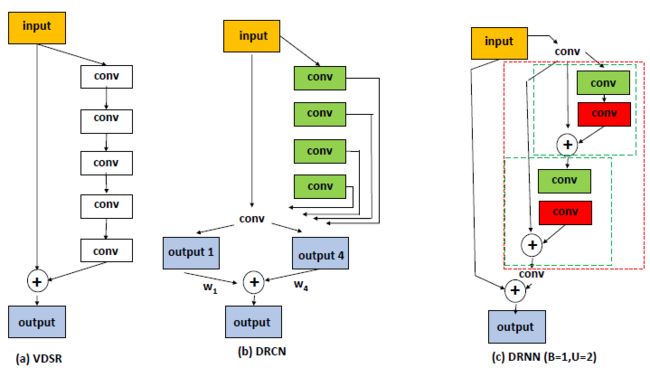
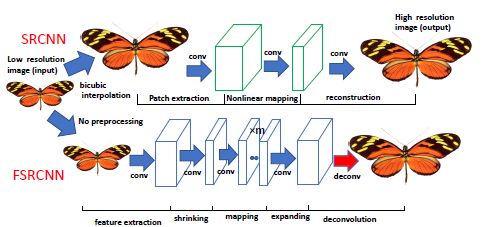
下图展示了加速简单SRCNN的方法FSRCNN,是将上采样层后置。同时,可以注意到,这里已经使用到了在刚开始Channel大,中间Channel小,但最后Channel大的框架设计。
作者提出,亚像素卷积会导致棋盘格伪像,而[56]提出了一种不会产生棋盘格伪像的改良版亚像素卷积:上采样核通过模仿最近邻插值方法初始化,然后在训练的过程中进行参数训练。传统的 CNN 学习移位不变滤波器(shift-invariant filter),而在 [57] 中,作者引入了 Shepard 层以移位变量的方式执行上采样(或修复)操作。 该层的输入被插值到超分辨率尺度,但插值值为 0。掩码用于控制滤波器的影响。
有文章[58]提到,当filters的数量超过1000时,残差会变得不稳定且趋向于丢失它们的学习能力。而添加一个Scale层在identity branch上,会是网络保持稳定性。所以EDSR在ResBlock中添加了一个Constant scaling layer。
SRDenseNet的超分架构如下图所示:和名字一样,使用了密集连接概念。

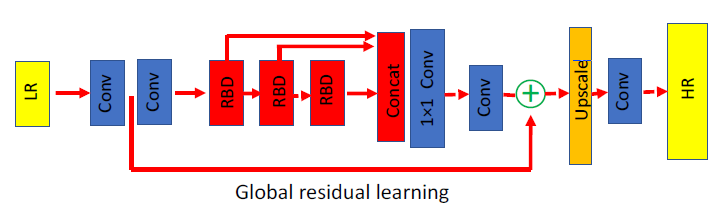
RDN的网络架构如下图所示。
SRGAN使用了三种损失的组合:(1)MSE Loss,用以促进像素相似度;(2)感知相似度距离,通过深层网络特征(VGGNet)。相对于直接使用MSE损失,在VGGNet出来的特征上,更注重感知质量,而不是像素上的改变;(3)标准的GAN loss。
结果对比
表格数值的来源都是原论文,本文没有复现。
在Set5和Set14的PSNR如下所示。下面网络带有+号的是使用了自相似策略(self-similarity strategy [43])改善的模型。其假设是网络对于输入数据的几何变换是不会改变(参数)的。比如一个测试样例有8个几何变换的增强输入,输入到网络中得到8个估计结果。最后的结果是这8个估计结果在经过逆几何变换后得到的平均值。需要注意的是,几何变换的不变性是一个强条件,这样的一个比较结果是部分可靠的,因为每个网络都使用不同方式进行训练。

医疗图像上的超分问题
CT images
[70]提出了一个UNet结构来处理2D脑CT图像的超分和去燥问题,网络结构如下图所示。HR图像来自于PET CT,LR图像来自于3D高分辨率切片的平均值生成的。

[71]使用SRGAN应用在两个图像方式上(CT和MRI),使用VGGNet的feature作为Loss,而不是直接像素级的相似度。在他们的实验中,LR由高斯核带来的平滑 + 下采样生成。
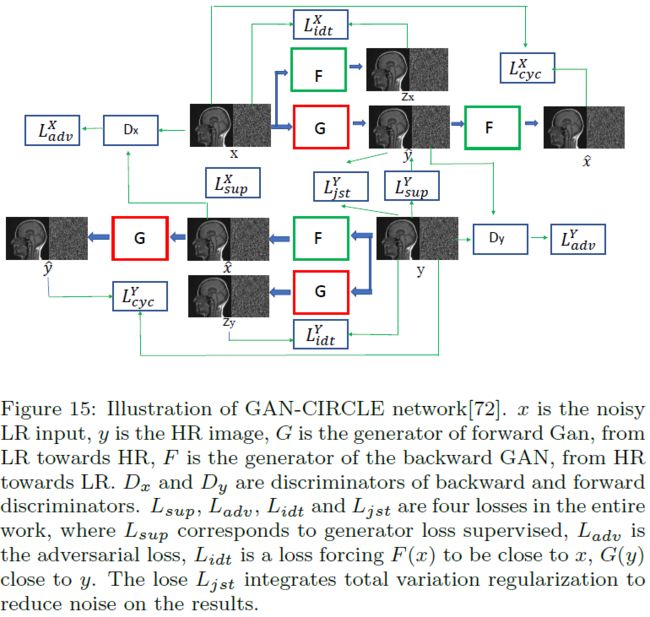
[72]提出了一个GAN-CIRCLE的方式,解决CT图像的超分问题。他们的数据集由胫骨(tibia)数据集和腹部(abdominal)数据集组成。HR图像是由HR图像实验性地模拟而成。
MRI images
MRI超分问题上涉及的图像部位主要是大脑和心脏图像。在这些实验中,LR图像可以是实验图像(experimental images[75, 80, 79])或者模拟图像。准确来说,模拟低分辨率图像,可以通过K空间截断生成,或者通过(带或不带高斯核模糊的)高分辨率图像下采样生成。总结了如下的MRI图像列表:
- http://brainweb.bic.mni.mcgill.ca/brainweb/ (simulation images)
- http://www.bic.mni.mcgill.ca/brainweb/ (simulation image)
- https://sites.google.com/site/brainseg/ (experimental images)
- https://www.smir.ch/BRATS/Start2015 (experimental images)
- http://brain-development.org/ixi-dataset/ (experimental images)
- http://insight-journal.org/midas/collection/view/190 (experimental images)
- https://github.com/UK-Digital-Heart-Project (UK Digital Heart Project, experimental images)
- http://hdl.handle.net/1926/1687 (experimental images)
[80]提出了一个T-L网络,将超分和分割结合了起来,网络如下图所示。其使用的数据集由UK数字心脏项目提供,HR和LR都是实验性图像。训练的时候使用两个损失的结合,分割任务使用“X-Entropy Loss L x L_x Lx”,超分任务使用平滑 L 1 L1 L1损失。

3D MRI images
[4] 的作者认为 SRCNN 3D总是比 SRCNN 2D要好一点。
讨论
缺乏高质量的参考和特定的图像先验或约束是在医学成像中推广深度学习 SR 方法的两个主要瓶颈。由于各种限制,HR ground truth图像在临床成像中很难获得。同时,选择合适的先验也很重要,可能限制于给定的模态。 在下文中,我们总结了一些数据增强方法和注入特定先验的不同方法。
数据缺乏
数据增强用于增加数据集。 传统的数据增强包括翻转、旋转、对称、平移、缩放图像、添加加性噪声、改变亮度、调整对比度、gamma变换、修改颜色等。
除了这些操作之外,研究人员还考虑使用 DL 网络来执行数据扩充。 [54]应用迁移学习来增加数据集。 他们使用尺度不变特征变换(SIFT)在可用医学图像集上提取特征,然后在自然图像集中搜索相似特征。匹配的子区域将添加到数据集中。
增加先验
在 [90] 中提出了一种去噪方法,其中网络仅基于噪声图像进行训练,即数据集中没有干净的图像。在训练过程中,输入和输出都是带噪声的图像,包括相同的干净图像但具有不同的噪声。 在测试阶段,有噪声的图像足以让网络完成去噪任务。 这项工作的一个重要假设是噪声的平均值为 0。作者解释说,如果噪声的平均值为 0,那么一组噪声图像的平均值就是去噪图像。 由于网络是用随机梯度下降法训练的,虽然批次中的每个例子都对应一个不准确的优化方向,但这些例子梯度的平均值指向一个正确的方向。论文名为《Noise2noise: Learning image restoration without clean data》
[91]考虑使用未经训练的深度学习网络从给定的退化图像中探索深度先验。 准确地说,输入是一组均匀分布的随机噪声特征,网络中的参数是随机初始化的,并通过最小化网络输出与给定退化图像之间的 L2 距离来优化。 直观上,网络可以比作优化任务中的正则化器,但比全变正则化等手工正则化项更灵活。 这种方法已经在几个任务上进行了测试,包括去噪、超分辨率,修复。 它在去噪和修复任务中的表现非常令人印象深刻,但对于 SR 来说变得相对有限,因为没有提供进一步的细节信息。
[90, 91] 都研究了如何在没有基本Ground Truth的情况下提高图像质量。 这些方法允许找到隐藏在嘈杂图像中的深层先验。 这样的先验可用于解决 SR 问题。