A Context-Dependent Gated Module for Incorporating Symbolic Semantics into Event Coreference Resolut
标题、作者

摘要
动机:
- 共指消解的输入来自于上游任务的信息抽取的输出,自动抽取的符号特征存在噪声和错误
- 上下文能提供有用信息
主要贡献
- 上下文相关的门控模型:自适应地控制从符号特征输入的信息
- 有噪声的训练模型
结论
在ACE2005和KBP2016数据集上实验
相关工作
利用mention-pair模型计算每个mention之间的距离,然后使用聚类算法,除了触发词特征外,也有使用事件类型、属性、论元等特征,但没有使用上下文embedding,或者只使用了一种符号特征
导言
现有方法
- 利用有关触发词的特征信息
- 利用额外的符号特征,如事件类型、属性、论元等
- 利用上下文无关的词嵌入
- 简单地直接拼接特征会引入噪声和误差
文中方法
- 包含广泛的符号特征的通用、有效的方法
- 利用上下文相关的门控制模型从符号特征中有选择地抽取信息
- 使用正则化方法随机的在训练过程中加入噪声
模型
预定义
-
文档 D D D 有 k k k 个事件提及(由预测得出)
-
每个事件提及 m i m_i mi 中触发词的起始索引分别为 s i s_i si、 e i e_i ei
-
每个事件提及 m i m_i mi 有 K K K 个类别特征,每个类别特征 c i ( u ) ∈ { 1 , 2 , . . . , N u } c_i^{(u)}\in \{1,2,...,N_u\} ci(u)∈{1,2,...,Nu}
-
ACE数据集中利用的符号特征:
- 类型、极性、形态、指属、时态
-
KBP数据集利用的符号特征:
- 类型、现实含义
-
使用OneIE识别事件提及(mentions)及其子类型
-
使用基于SpanBERT的联合分类模型提取其他符号特征
Single-Mentions Encoder(单个事件提及的编码器)
给定一个文档 D D D ,先使用 Transformer 编码器对输入的每个tokens形成上下文的表示
X = ( x 1 , . . . , x n ) , x i ∈ R d X=(x_1,...,x_n), x_i\in \mathbb{R}^d X=(x1,...,xn),xi∈Rd
对于每个事件提及 m i m_i mi ,它的触发词的表达 t i t_i ti 定义为触发词的每个token的平均值:
t i = ∑ j = s i e i x j e i − s i + 1 t_i=\sum_{j=s_i}^{e_i}\dfrac{x_j}{e_i-s_i+1} ti=j=si∑eiei−si+1xj
另外,使用 K K K 个可训练的embedding矩阵,将每个事件提及 m i m_i mi 的 K K K 符号特征转为 K K K 个向量
{ h i ( 1 ) , h i ( 2 ) , . . . , h i ( K ) } \{h_i^{(1)},h_i^{(2)},...,h_i^{(K)}\} {hi(1),hi(2),...,hi(K)}
Mention-Pair Encoder and Scorer(事件提及对的编码和得分计算)
-
给定两个事件提及 m i m_i mi和 m j m_j mj ,定义它们的触发词对 t i j t_{ij} tij的表示为:
t i j = F F N N t ( [ t i , t j , t i ∘ t j ] ) t_{ij}=FFNN_t([t_i,t_j,t_i \circ t_j]) tij=FFNNt([ti,tj,ti∘tj])
F F N N t FFNN_t FFNNt是一个前向网络, t i ∈ R d t_i\in \mathbb{R}^d ti∈Rd, t i j ∈ R p t_{ij}\in \mathbb{R}^p tij∈Rp, ∘ \circ ∘表示按元素相乘 -
定义特征对的表示 { h i j ( 1 ) , h i j ( 2 ) , . . . , h i j ( K ) } \{h_{ij}^{(1)},h_{ij}^{(2)},...,h_{ij}^{(K)}\} {hij(1),hij(2),...,hij(K)}(对应特征的组合)
h i j ( u ) = F F N N u ( [ h i ( u ) , h j ( u ) , h i ( u ) ∘ h j ( u ) ] ) h_{ij}^{(u)}=FFNN_u([h_{i}^{(u)},h_{j}^{(u)},h_{i}^{(u)} \circ h_{j}^{(u)}]) hij(u)=FFNNu([hi(u),hj(u),hi(u)∘hj(u)])
F F N N u FFNN_u FFNNu是一个前向网络, h i ( u ) ∈ R l h_i^{(u)}\in \mathbb{R}^l hi(u)∈Rl, h i j ( u ) ∈ R p h_{ij}^{(u)}\in \mathbb{R}^p hij(u)∈Rp -
(非最优的方法)将事件提及 m i m_i mi和 m j m_j mj 对的表示为触发词对和特征对的拼接:
f i j = [ t i j , h i j ( 1 ) , h i j ( 2 ) , . . . , h i j ( K ) ] f_{ij}=[t_{ij}, h_{ij}^{(1)}, h_{ij}^{(2)},...,h_{ij}^{(K)}] fij=[tij,hij(1),hij(2),...,hij(K)]
直接利用符号特征易引入噪声和误差,于是文中提出新的方法 CDGM
上下文相关的门控模型 CDGM
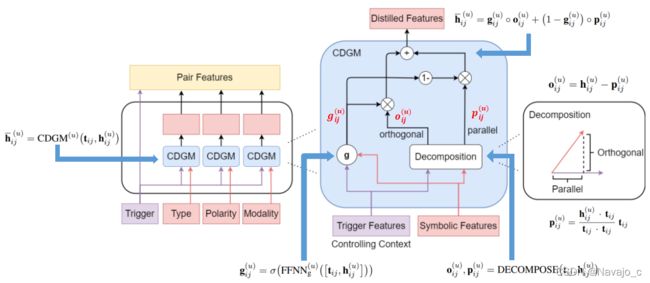
给定两个事件提及 m i m_i mi和 m j m_j mj,利用得到的触发词特征 t i j t_{ij} tij 去计算过滤后的特征对表示
h ˉ i j ( u ) = C D G M ( u ) ( t i j , h i j ( u ) ) \bar{h}_{ij}^{(u)}=CDGM^{(u)}(t_{ij},h_{ij}^{(u)}) hˉij(u)=CDGM(u)(tij,hij(u))
其他门控机制,对 u ∈ { 1 , 2 , . . . , K } u\in\{1,2,...,K\} u∈{1,2,...,K}:
-
g i j ( u ) = σ ( F F N N g ( u ) ( [ t i j , h i j ( u ) ] ) ) g_{ij}(u)=\sigma(FFNN_g^{(u)}([t_{ij}, h_{ij}^{(u)}])) gij(u)=σ(FFNNg(u)([tij,hij(u)]))
-
o i j ( u ) , p i j ( u ) = D E C O M P O S E ( t i j , h i j ( u ) ) o_{ij}^{(u)}, p_{ij}^{(u)}=DECOMPOSE(t_{ij},h_{ij}^{(u)}) oij(u),pij(u)=DECOMPOSE(tij,hij(u))
-
p i j ( u ) = h i j ( u ) ⋅ t i j t i j ⋅ t i j t i j p_{ij}^{(u)}=\dfrac{h_{ij}^{(u)}\cdot t_{ij}}{t_{ij}\cdot t_{ij}}t_{ij} pij(u)=tij⋅tijhij(u)⋅tijtij
-
p i j ( u ) p_{ij}^{(u)} pij(u) 是 h i j ( u ) h_{ij}^{(u)} hij(u) 在 t i j t_{ij} tij上的投影,包含 t i j t_{ij} tij 的信息
\\[3pt] -
o i j ( u ) = h i j ( u ) − p i j ( u ) o_{ij}^{(u)}=h_{ij}^{(u)}-p_{ij}^{(u)} oij(u)=hij(u)−pij(u)
-
o i j ( u ) o_{ij}^{(u)} oij(u) 正交于 h i j ( u ) h_{ij}^{(u)} hij(u),相当于去除一部分信息
-
-
h ˉ i j ( u ) = g i j ( u ) ∘ o i j ( u ) + ( 1 − g i j ( u ) ) ∘ p i j ( u ) \bar{h}_{ij}^{(u)}=g_{ij}^{(u)}\circ o_{ij}^{(u)}+(1-g_{ij}^{(u)})\circ p_{ij}^{(u)} hˉij(u)=gij(u)∘oij(u)+(1−gij(u))∘pij(u)
F F N N g ( u ) FFNN_g^{(u)} FFNNg(u)将 R 2 × p \mathbb{R}^{2\times p} R2×p映射为 R p \mathbb{R}^{p} Rp,经过CDGMs的蒸馏后得到事件提及对 m i m_i mi和 m j m_j mj 的最终表示为:
f i j = [ t i j , h ˉ i j ( 1 ) , h ˉ i j ( 2 ) , . . . , h ˉ i j ( K ) ] f_{ij}=[t_{ij}, \bar{h}_{ij}^{(1)}, \bar{h}_{ij}^{(2)}, ..., \bar{h}_{ij}^{(K)}] fij=[tij,hˉij(1),hˉij(2),...,hˉij(K)]
事件提及 m i m_i mi和 m j m_j mj 的共指得分 s ( i , j ) s(i,j) s(i,j) 为:
s ( i , j ) = F F N N a ( f i j ) s(i,j)=FFNN_a(f_{ij}) s(i,j)=FFNNa(fij)
F F N N a FFNN_a FFNNa将 R ( K + 1 ) × p \mathbb{R}^{(K+1)\times p} R(K+1)×p映射为 R \mathbb{R} R
Training and Inference
训练过程
特征预测器的训练精度通常比它在开发/测试集上的精度高得多。如果简单地训练模型而不进行任何正则化,CDGM在训练过程中很少遇到噪声符号特征。因此,为了让CDGM真正学会提取可靠的信号,文中还提出了一种简单但有效的噪声训练方法(具体操作见算法)。
噪声加入算法
-
输入: 文档 D D D
-
超参数: { ϵ 1 , ϵ 2 , . . . , ϵ K } \{\epsilon_1, \epsilon_2, ..., \epsilon_K\} {ϵ1,ϵ2,...,ϵK}
-
for i = 1... k i = 1... k i=1...k do
-
for u = 1... K u = 1 ...K u=1...K do
- with prob. ϵ u \epsilon_u ϵu, replace c i ( u ) c_i^{(u)} ci(u) by
- c ^ i ( u ) ∼ U n i f o r m ( N u ) \hat{c}_i^{(u)}\sim Uniform(N_u) c^i(u)∼Uniform(Nu)
-
end
-
-
end
噪声训练方法不是为了减少传统意义上的过拟合。它的主要功能是帮助CDGM学会从噪声特征中提取可靠的信号
推理过程
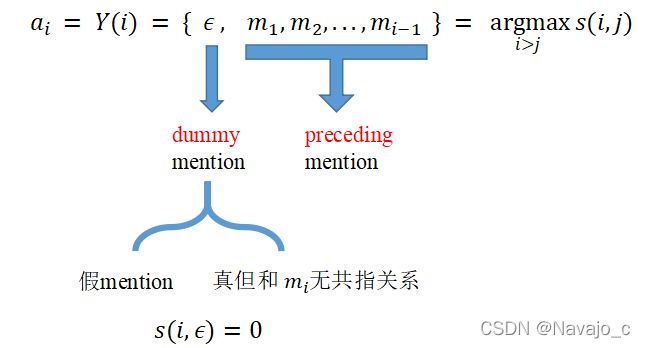
给每个事件提及 m i m_i mi 分配一个 先例 a i a_i ai,这个先例来自于 m i m_i mi之前抽取的事件提及或一个假的事件提及