【论文阅读笔记】Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
RepLKNet代码地址Github
RepLKNet论文地址Arixiv
有效感受野论文地址Arxiv
论文总结
本文设计的网络名为RepLKNet(Reparam Large Kernel Network),其证明了少量的大kernel卷积可以获得比堆叠小kernel卷积的网络架构设计更好的效果。RepLKNet使用的最大卷积核大小为 31 ∗ 31 \mathbf{31}*\mathbf{31} 31∗31,是一个纯CNN网络,极大缩减了CNNs和ViTs(Vision Transformer)的性能差距。同时,作者进一步表示,相比较于小Kernel的CNNs,大Kernel的CNNs有更大的有效感受野(effective receptive fields)和更高的形状偏差(higher shape bias),而不是纹理偏差(texture bias)。
RepLKNet的网络架构设计总体遵循Swin Transformer的宏观架构,进行了一些修改,比如使用大Kernel的depthwise Conv代替多头注意力(multi-head self-attention,MHSA)。
本文实验的重点在中型(middle-size)网络和大型(large-size)网络上,因为过去人们认为 ViTs 在大数据和大模型上超过了 CNN(大的kernel size,也小不了呀)。本文的baseline模型RepLKNet-B(和Swin-B模型大小相近)最大的kernel size为 31 ∗ 31 31*31 31∗31,在ImageNet上达到了 84.8 % 84.8\% 84.8%的Top1准确率。RepLKNET-B比Swin-B的性能要好 0.3 % 0.3\% 0.3%,但在延迟上更加高效。在下游任务中,作者发现大Kernel设计的网络实际上提升比在ImageNet上更高。比如,在相同的复杂度和参数预算前提下,RepLKNet设计的网络,对比ResNeXT-101或ResNet-101为backbone的网络,在COCO目标检测上高 4.4 % 4.4\% 4.4%,在ADE20K语义分割上高 6.1 % 6.1\% 6.1%。
作者认为RepLKNet的高性能是因为大的卷积Kernel带来的大的有效感受野(effective receptive fields,ERFs)带来的提升,如下图1所示。同时,RepLKNet可利用更多的形状信息(相比传统的堆叠小kernel CNNs),这部分是符合人类的认知体系的。
有效感受野的相关知识,在2016年的有效感受野论文中提出,但鲜少有人会去使用和基于此计算感受野。

论文介绍
之前ViTs整体表现要优于CNNs的时候,有些论文研究了其中的原因。一些研究认为是MHSA(multi-head self-attention)使得ViTs效果要比CNNs更好。而本文认为CNNs和ViTs性能差距的重点在于感受野上,ViTs使用大kernel,而CNN中使用大Kernel的网络设计则没那么受欢迎。所以作者将疑问放到了“是否使用大Kernel Conv构建的神经网络是缩小CNNs和ViTs差距的关键?”。所以在后续实验中,进行了大Kernel卷积的相关实验。
实验证明,大的Kernel卷积是能有效提升CNNs的性能的,但对CNN简单地应用大卷积核通常会导致性能和速度下降,所以在使用上需要遵循一些设计指导原则。大Kernel卷积网络的设计指导原则有5条,是实验性结果:
- 大的depthwise Conv在实践中可以是高效的。
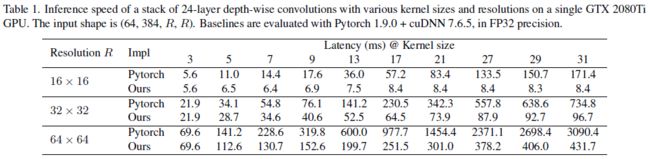
- 使用大 kernel的普通卷积会带来昂贵的计算量,使用大kernel 的depthwise卷积则能相对缓解这些问题。比如本文提出的RepLKNet(见<>下表5),将不同stage的卷积核大小从 [ 3 , 3 , 3 , 3 ] [3, 3, 3, 3] [3,3,3,3]提升到了 [ 31 , 29 , 27 , 13 ] [31, 29, 27, 13] [31,29,27,13]只提升了 18.6 % 18.6\% 18.6%的FLOPS和 10.4 % 10.4\% 10.4%的参数量,这是可以接受的。剩下的 C o n v 1 ∗ 1 Conv1*1 Conv1∗1实际上主导了大部分的复杂性。
- 虽然传统的depthwise Conv3*3会DW 操作引入了较低的计算与内存访问成本的比率 [64],这对现代计算架构(GPU)不友好。但随着卷积核大小的提升,计算就变得密集了。所以根据roofline模型,当kernel size变大时,实际延迟应该不会随着FLOPs的增加而增加。现有的深度学习推理框架对大kernel depthwise Conv的支持很差,所以作者尝试了几种方法进行了优化。最后采用分块(逆)隐式gemm算法(block-wise(inverse) implicit gemm algorithm),作者认为这是最好的选择,实现方法已集成到开源框架MegEngine中,同时作者还为pytorch更新了一版高效的实现方式,地址在https://github.com/DingXiaoH/RepLKNet-pytorch。优化速度见下表1。

- Identity shortcut对于非常大Kernel Size设计的网络是至关重要的。
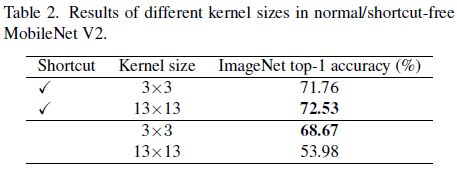
- 为验证残差的作用,作者使用MobileNetv2作为基准,使用有无shortcut的两个辩题。为做大kernel的对照试验,使用 13 ∗ 13 13*13 13∗13的depthwise Conv代替 3 ∗ 3 3*3 3∗3的depthwise conv。使用相同的训练配置在ImageNet上训练 100 100 100个epoch。结果如下表2所示,提升了Kernel Size后,有shortCut的mobileNetv2提升了 0.77 % 0.77\% 0.77%,没有shortCut的mobileNetv2则减少到只有 53.98 % 53.98\% 53.98%。
- 该指南也适用于 ViT。 最近的一项工作 [33] 发现,如果没有Identity shortcut,attention会随着深度成倍地下降,从而导致过度平滑问题。从与 [91] 类似的角度来看,shortcut使模型成为由具有不同感受野 (RF) 的众多模型组成的隐式集合,因此它可以从更大的最大 RF 中受益,同时不会失去捕获小规模模式的能力。
- 使用小kernel的重参数技术有助于改善优化问题。
- depthwise的重参数如下图2所示,也是将小的kernel融合进大的kernel中,这里只用了并行的方式;

- 下表3展示了,如果直接将kernel Size从 9 9 9提升到 13 13 13是会降低准确率的,但使用了重参数后则解决了该问题。
-

- 同时,作者发现,在ImageNet分类任务上,如果将训练数据提升到 7300 7300 7300万张图像时,可以省略重参数化技术而不会产生“增大Kernel Size,但降准确率”的问题。
- 大kernel Conv网络对下游任务(分割、目标检测等)的提升是大于ImageNet分类的。
- 从上表3可以看出,从 C o n v 3 ∗ 3 Conv3*3 Conv3∗3增大到 C o n v 9 ∗ 9 Conv9*9 Conv9∗9在ImageNet只提升了 1.33 % 1.33\% 1.33%,但在 C i t y s p a c e s Cityspaces Cityspaces上的mIoU指标增加了 3.99 % 3.99\% 3.99%。下表5展示了同样的趋势:kernel size上升,ImageNet只升了 0.96 % 0.96\% 0.96%,但ADE20K数据集上的分割任务上提升了 3.12 % 3.12\% 3.12%。

- 大kernel提升了有效感受野,很多工作证明了上下文信息的重要性,如在下游任务目标检测,语义分割等。作者认为大kernel设计贡献了更多的形状偏差(shape bias)。ImageNet分类任务可以通过纹理或形状来正确分类。然而,人类主要通过形状线索(shape cue)而不是纹理来识别对象。所以如果一个模型能学习到更强的形状偏差,可能迁移到下游任务会更好。最近也有文章[88]说ViTs的形状偏差很强,这部分解释了ViTs在迁移任务重的强大。相反,传统CNN更倾向于纹理信息。幸运的是,作者发现简单地扩大CNN中的kernel size,可以有效地改善形状偏差。
- 大Kernel(比如 13 ∗ 13 13*13 13∗13)甚至对于小的feature map(比如 7 ∗ 7 7*7 7∗7)都是有帮助的。
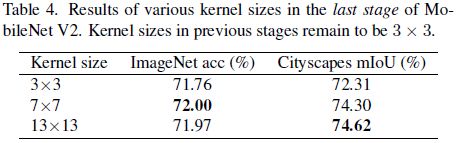
- 为了验证这个结果,作者在MobileNet的最后一个stage上应用 C o n v 7 ∗ 7 Conv7*7 Conv7∗7或者 C o n v 13 ∗ 13 Conv13*13 Conv13∗13,而最后一个 s t a g e stage stage的feature map大小为 7 ∗ 7 7*7 7∗7。下表4展现了结果,可以看出比 7 ∗ 7 7*7 7∗7的feature map更大的卷积也有效增加了准确率,尤其是在Cityscape数据集上。
- 当kernel size的大小大于feature map时,CNN的卷积平移平等性并不是严格遵守的。如下图3所示,窗口在平移时,使用的权重不是相等的。

网络设计
据作者所知,CNNs支配小模型,视觉Transformer被认为在高复杂度容量上比CNN要好。本文提供了一种大模型的思路。
本文设计的网络叫RepLKNet,如下图4所示。每个stage有数个RepLK Block,每个Block都带有shortCut和大kernel Depthwise Conv。在每个stage中,都先用 C o n v 1 Conv1 Conv1,再用 D e p t h w i s e C o n v Depthwise\ Conv Depthwise Conv,但下图4没显示的是,depthwise Conv训练的时候有一个 5 ∗ 5 5*5 5∗5 kernel size的重参数分支。
FFN广泛用于transformers和MLPs中。受这些启发,作者使用了一个类似的CNN风格block,它由shortcut,BN,2个 C o n v 1 Conv1 Conv1和GELU组成,故称为ConvFFN Block,如下图4所示。相比较FFN在FC层之前使用的LN(Layer Normalization),ConvFFN使用的BN可以融入Conv中以提升推理速度。依据实践结果,ConvFFN Block中的内部channel为输入的4倍。为提供更多的非线性和跨通道的信息通信,作者使用 C o n v 1 Conv1 Conv1来提高深度。
Transition Block在不同的stage之间使用。先用 C o n v 1 Conv1 Conv1提升channel维度,再用stride为2的 D e p t h w i s e C o n v Depthwise \ Conv Depthwise Conv下采样。
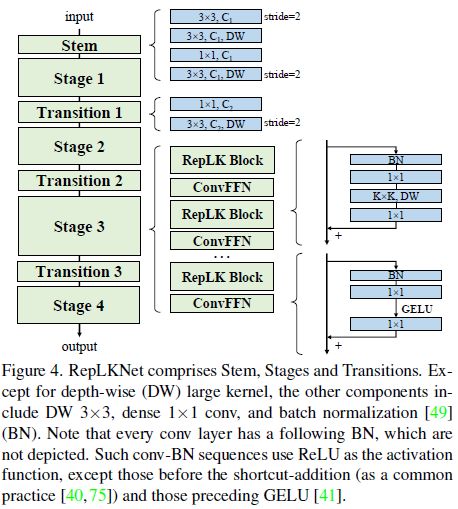
总结下来,RepLKNet的网络设计上,每个stage有3个结构超参数:RepLK Block的数量B,channel维度C和kernel size K。所以RepLKNet的架构定义为 [ B 1 , B 2 , B 3 , B 4 ] , [ C 1 , C 2 , C 3 , C 4 ] , [ K 1 , K 2 , K 3 , K 4 ] \mathbf{[B1,B2,B3,B4],[C1,C2,C3,C4],[K1,K2,K3,K4]} [B1,B2,B3,B4],[C1,C2,C3,C4],[K1,K2,K3,K4]。
论文实验
RepLKNet-B为基础模型,其架构参数为 B = [ 2 , 2 , 18 , 2 ] , C = [ 128 , 256 , 512 , 1024 ] , K = [ 31 , 29 , 27 , 13 ] B=[2, 2, 18, 2],\mathbf{C=[128, 256, 512, 1024]}, K=[31, 29, 27, 13] B=[2,2,18,2],C=[128,256,512,1024],K=[31,29,27,13]。RepLKNet-L为大一些的模型,其架构参数为 B = [ 2 , 2 , 18 , 2 ] , C = [ 192 , 384 , 768 , 1536 ] , K = [ 31 , 29 , 27 , 13 ] B=[2, 2, 18, 2],\mathbf{C=[192, 384, 768, 1536]}, K=[31, 29, 27, 13] B=[2,2,18,2],C=[192,384,768,1536],K=[31,29,27,13]。而RepLKNet-XL为最大的模型,其架构参数为 B = [ 2 , 2 , 18 , 2 ] , C = [ 256 , 512 , 1024 , 2048 ] , K = [ 31 , 29 , 27 , 13 ] B=[2, 2, 18, 2],\mathbf{C=[256, 512, 1024, 2048]}, K=[31, 29, 27, 13] B=[2,2,18,2],C=[256,512,1024,2048],K=[31,29,27,13],同时RepLK Blocks中的invert bottleneck的Depchwise Conv Channel数放大 1.5 1.5 1.5倍。
ImageNet分类任务
各个网络在ImageNet的准确率和相关参数如下表所示:◇表示使用半监督数据集MegData73K进行了预训练。尽管RepLKNet-XL的FLOPs要比Swin-L高,但RepLKNet-XL更快,这强调了非常大Kernel的性能。

语义分割任务
用预训练model作为backbone,在Cityscapes和ADE20K数据集上训练。使用UperNet在Cityscapes上迭代80K次,在ADE20K数据集迭代160K次。因为只想评估backbone,故不适用任何先进技术、技巧或自定义算法。
Cityscapes数据集,在ImageNet-1K上预训练的RepLKNet-B要优于Swin-B一大截(单尺度mIoU提升2.7),甚至优于ImageNet22k上预训练的Swin-L模型。
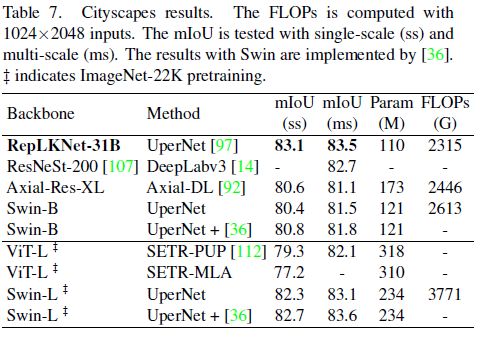
在ADE20K上的结果。

COCO目标检测任务
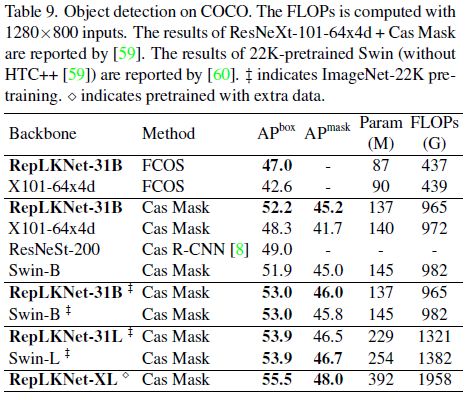
在COCO目标检测任务上的结果如下。使用RepLKNet作为FCos和Cascade Mask R-CNN的backbone。这两个算法分别是一阶和二阶的目标检测算法。
Discussion
大kernel的CNN模型比深层小Kernel模型有更大的有效感受野。作者认为,根据有效感受野理论,ERF是与 O ( K L ) \mathbf{O(K\sqrt{L})} O(KL)成比例的,其中 K K K是kernel size, L L L是深度。其次,网络变深了会给训练带来优化困难的问题。下图展示了ResNet-101、ResNeXt-101和RepLKNet的有效感受野,可以看出,浅层的大Kernel有效感受野要大一些。所以大卷积核的设计仅需要更少的层就可以达到预定的有效感受野,同时避免了深度增加带来的优化问题。

大Kernel的模型在形状偏差特征提取会更好,这和人类相近。
大Kernel设计是一个可以通用的设计,也可以使用在ConvNeXt中。使用 31 ∗ 31 31*31 31∗31的depthwise Conv代替ConvNeXt原本的 7 ∗ 7 7*7 7∗7普通卷积能带来巨大的提升。比如 ConvNeXt-Tiny + large Kernel 是要优于 ConvNeXt-Small的,而ConvNeXt + large Kernel 是要优于 ConvNeXt-Base的。
大Kernel模型的表现要比小Kernel带高空洞率(dilation rates)要好。空洞卷积是一个常用的扩大卷积范围的方法.。尽管最大感受野可能一样,但空洞卷积的表达能力要弱很多,准确率下降非常明显,原因则是空洞卷积计算所用的特征非常少。