DPCM编码
一.实验目的
掌握DPCM编解码系统的基本原理。初步掌握实验用C/C++/Python等语言编程实现DPCM编码器,并分析其压缩效率。
二.实验原理
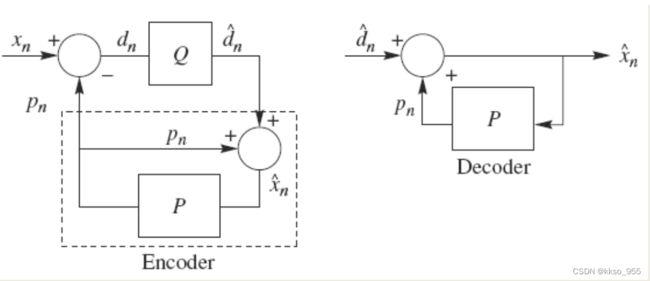
DPCM是差分预测编码调制的缩写,是比较典型的预测编码系统。在DPCM系统中,需要注意的是预测器的输入是已经解码以后的样本。之所以不用原始样本来做预测,是因为在解码端无法得到原始样本,只能得到存在误差的样本。因此,在DPCM编码器中实际内嵌了一个解码器,如编码器中虚线框中所示。
在一个DPCM系统中,有两个因素需要设计:预测器和量化器。理想情况下,预测器和量化器应进行联合优化。实际中,采用一种次优的设计方法:分别进行线性预测器和量化器的优化设计。
三.核心模块代码
DPCM
//我这里用的是左侧预测
void DPCM(unsigned char* yBuf, unsigned char* qBuf, unsigned char* rebuildBuf,int w, int h,int dif)
for(i=0;iPSNR计算
void PSNR(unsigned char* ybuffer, unsigned char* bitbuffer, int w, int h) {
double mse,psnr,bottle;
double sum = 0;
int i;
for (i = 0; i < w * h; i++) {
bottle = pow((ybuffer[i] - bitbuffer[i]), 2);
sum += bottle;
}
mse = sum / (w * h);
psnr = 10 * log10((pow(2, 8) - 1) * (pow(2, 8) - 1) / mse);
cout << "psnr: " << psnr << endl;
}
主程序相关核心代码
int main(int argc, char* argv[]) {
char* COLORAD= argv[1];
char* YUVB= argv[2];
int W = atoi(argv[3]);
int H = atoi(argv[4]);
char* REYUV = argv[5];
int A = W * H * 3 / 2;
int q = atoi(argv[6]);
unsigned char* COLORAD = new unsigned char[A];
unsigned char* ybuffer = new unsigned char[A * 2 / 3];
unsigned char* ubuffer = new unsigned char[A / 6];
unsigned char* vbuffer = new unsigned char[A/ 6];
unsigned char* yuce = new unsigned char[A * 2 / 3];
unsigned char* bitbuffer = new unsigned char[A* 2 / 3];
FILE* fp= fopen(COLORAD, "rb");
FILE* FILE1= fopen(YUVB, "w");
FILE* FILE2 = fopen(REYUV, "w");
fread(COLORAD, sizeof(unsigned char), A, fp);
for (int i = 0; i < A * 2 / 3; i++) {
ybuffer[i] = COLORAD[i];
}
for (int i = 0; i < A/ 6; i++) {
ubuffer[i] = COLORAD[i + A * 2 / 3];
}
for (int i = 0; i < A / 6; i++) {
vbuffer[i] = COLORAD[i + A* 2 / 3 + A/ 6];
}
DPCM(ybuffer, yuce, bitbuffer, H, W, q);
fwrite(bitbuffer, sizeof(unsigned char), W * H, FILE1);
fwrite(ubuffer, sizeof(unsigned char), W * H / 4, FILE1);
fwrite(vbuffer, sizeof(unsigned char), W * H / 4, FILE1);
for (i = 0; i 相关命令行参数

四.实验结果
| 原图 | 预测误差 | 重建图 |
 |
 |
 |
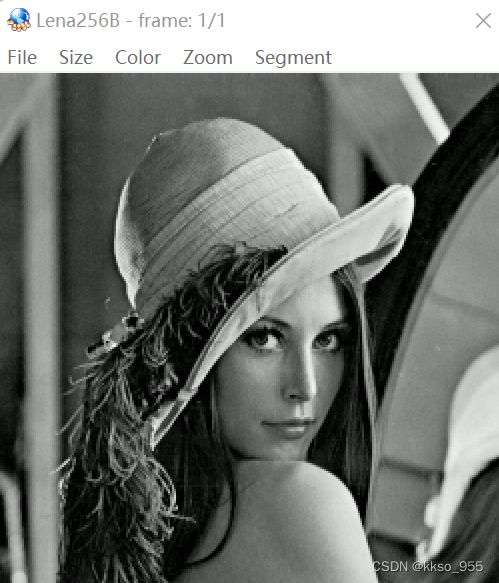 |
 |
 |
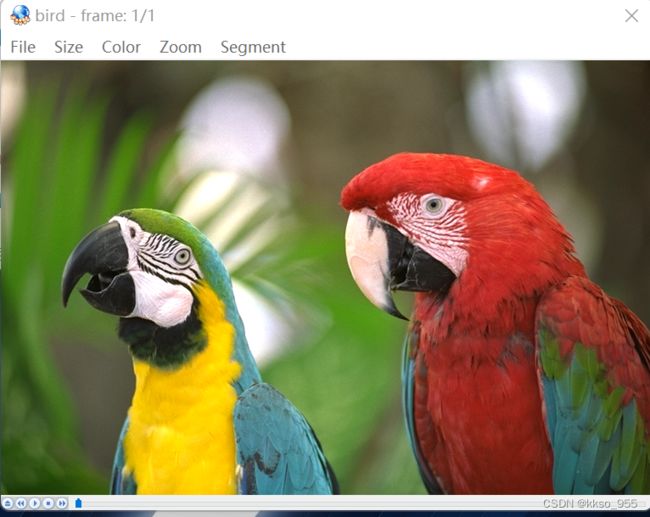 |
 |
|
 |
 |
 |
 |
 |
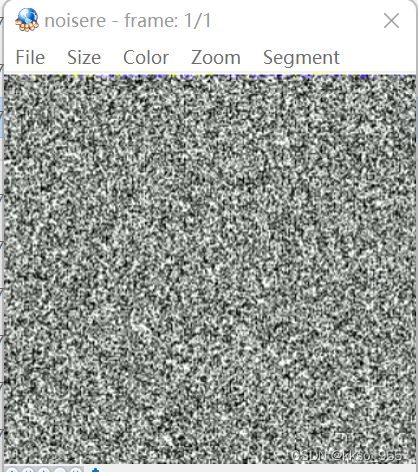 |

对lena进行2bit,4bit量化
| 4bit | 2bit |
 |
 |
以鹦鹉和lena为例子,画出预测误差概率分布曲线
bird预测误差概率分布图

lena预测误差概率分布图

比较压缩比
| 名称 | 原始大小 | 仅熵编码大小 | 仅熵编码压缩比 | DPCM+熵编码后大小 | DPCM+熵编码后压缩比 |
| Odie | 96kb | 19.7kb | 4.87 | 17.2kb | 5.58 |
| lena | 96kb | 68.2kb | 1.41 | 45kb | 2.13 |
| bird | 576kb | 519kb | 1.11 | 192kb | 3 |
| fruit | 96kb | 71.9kb | 1.34 | 41.1kb | 2.33 |
| noise | 96kb | 69.8 | 1.38 | 73.4 | 1.31 |

比较PSNR
| 名称 | psnr值 |
| Odie | 51.2614 |
| lena | 51.1321 |
| bird | 51.1408 |
| fruit | 51.1671 |
| noise | 51.1439 |
五.实验结果分析
对于概率分布图来说,lena和bird空间上相邻像素灰度变化不大,预测误差的动态范围小,不难得知概率分布图应该离128越近越高
变化不同量化比特数,发现量化比特数越小失真越严重
可以看出,经过DCPM再熵编码的有压缩效率要比直接进行熵编码要高.但是noise这张图却出现了意外,根据DPCM的原理,不难得知,这是因为水平方向像素点黑白的灰度变化很大,相关性低,所以不适合用DPCM+熵编码