腾讯 AI Lab 2019 年度回顾
前 言
农历庚子年(鼠年)新年即将到来,我们也已经进入了 21 世纪 20 年代,正是辞旧迎新,总结过去一年发展历程的好时候。在过去的 2019 年里,腾讯 AI Lab 在 2018 年的发展基础上更进一步,不仅在AI前沿技术探索中取得更多丰富成果,也创造了更有价值的新应用。同时,我们继续秉承「科技向善」的信念和「Make AI Everywhere」的愿景,在过去的一年中与国内外的大学、企业和研究机构积极合作,探索了 AI 技术在为人类创造美好世界方面的可能性。

下面将首先介绍我们在 2019 年取得了重大进展的两大研究方向,然后会呈现我们推动实现的行业应用以及我们为「科技向善」做出的贡献。最后会梳理 2019 年我们在前沿研究探索方面的成果。
一、两大难题攻坚:
通用人工智能与数字人
用游戏仿真世界探索通用人工智能
很多游戏任务具有与现实任务相似的复杂性,同时游戏环境又是结构化的,能够为通用决策智能体的训练提供绝佳的训练环境。腾讯 AI Lab 立足于围棋、《王者荣耀》和《星际争霸 2》等游戏,在过去的一年里取得了一些值得分享的成绩:
2019 年 8 月 2 日,在吉隆坡举办的《王者荣耀》世界冠军杯(该竞技游戏最高规格赛事)半决赛的特设环节中,腾讯 AI Lab 策略协作型 AI 「绝悟」在与职业选手赛区联队的 5v5 竞技中获胜。这表明绝悟 AI 已经达到了《王者荣耀》电竞职业水平。
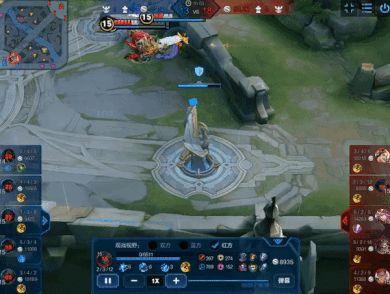
即时策略+团队协作:在赛区联队全队覆灭后, 「绝悟」的兵线尚未到达,下路高地塔还有过半血量,「绝悟」果断选择四人轮流抗塔,无兵线强拆塔。* 注:赛事尾声,赛区联队团灭后,「绝悟」未直接推水晶,而是计算整体收益后,选择先推最后一个高地塔,再推水晶直至胜利。
同一时段,「绝悟」的 1v1 版本「SUPEX 战队」还在国际数码互动娱乐展览会 China Joy 上亮相,在 2100 多场顶级业余玩家体验测试中胜率达到 99.8%。此版本相关的技术论文被顶级学术会议 AAAI 2020 接收。
8 月 25 日,腾讯 AI Lab 开发的、目前担任中国国家围棋队的训练专用围棋 AI 的「绝艺」斩获世界智能围棋公开赛冠军,这是它在问世三年以来,第四次夺得国际赛事冠军。
绝悟和绝艺都用到了一种名为「强化学习」的技术,其思想源自心理学中的行为主义理论,因此这种学习方法与人类学习新知识的方式存在一些共通之处。而游戏作为真实世界的模拟与仿真,一直是检验和提升 AI 能力的试金石,复杂游戏更被业界认为是攻克 AI 终极难题——通用人工智能(AGI)的关键一步。如果在模拟真实世界的虚拟游戏中,AI 学会跟人一样快速分析、决策与行动,就能执行更困难复杂的任务并发挥更大作用。世界顶级科技公司均在推进「AI+游戏」研究,腾讯也一直是此类研究的先行者,希望不断探索找到实现类似人类智能的通用智能的方法。这是一个宏大而又长远的目标,我们将砥砺前行。
我们也在积极建设相关的产学研生态。8 月 18 日,腾讯 AI Lab 与《王者荣耀》开发工作室宣布将共建 AI+游戏开放平台「开悟」。开悟平台将开放《王者荣耀》的游戏数据和游戏核心集群(Game Core),及腾讯 AI Lab 的强化学习和模仿学习能力与计算平台。我们希望能立足这一平台,促进和深化与高校和研究机构的合作,通过产学研结合的方式加速对 AI 的前沿研究探索和技术应用。12 月「开悟」开始在首批 4 所高校内测,开放范围还将在新的一年里进一步扩大。
用数字人探索多模态研究难题
多模态机器学习是一个热门的多学科研究领域,其研究的主题是通过整合和建模多种信息模态(比如语言、声音和视觉信息)来解决某些 AI 任务。腾讯自 2018 年 2 月就开始关注多模态方向的研究,并于 2018 年 11 月宣布探索下一代人机交互方式:多模态智能。
2019 年,我们继续探索如何整合计算机视觉、自然语言处理和理解、语音技术的多模态研究,并在原创研究和实际应用上都取得了进展。在 6 月 20 日 举办的「2019 全球电竞运动领袖峰会暨腾讯电竞年度发布会」上,腾讯 AI Lab 正式发布了首个电竞虚拟人「T.E.G(天鹅静)」。她是腾讯 AI Lab 所研发的数字人中的一员,有自然且感情充沛的声音,并且搭配有生动活力的唇形和表情。
腾讯AI Lab首个电竞虚拟人「T.E.G(天鹅静)」
数字人不仅可以担任游戏解说,而且还能成为虚拟歌手、虚拟主播、虚拟教师、新闻主持和智能助手。我们正以个性化、成长性、互动性为核心探索数字人在更多不同场景中的应用。
腾讯AI Lab神经网络渲染数字人
不同于以前依靠昂贵的电影工业级扫描设备和复杂的后期制作实现的数字人生成,我们开发的数字人诞生于对前沿 AI 技术的整合,包括 3D 人脸和人体重建、文本/语音/口型驱动和神经网络渲染等技术。此类技术虽然在探索期,拟人性和实际效果还不尽如人意,但长期看能降低个性化内容录制和制作的时间、人力和金钱成本。而且基于 AI 的数字人还有望实现与人类的实时动态交互,从而更好地融入人们的日常生活。

数字人的基础能力和相关技术示意图
具体来说,为了生成看起来真实自然的数字人形象,我们使用了基于深度神经网络的 3D 人脸人体重建、文本/语音/口型驱动和神经网络渲染等技术,使所生成的数字人能具备丰富的姿态和表情。这个技术流程分为三个阶段:1)DurIAN 模型生成同步音频和表情口型信息;2)基于此信息由 3D 动画技术生成人脸动画;3)卡通形象交给游戏引擎渲染,真人形象交给神经网络渲染。
数字人声音的 AI 合成及转换则采用了腾讯 AI Lab 今年研发的多模态语音合成算法DurIAN。该算法发布于 2019 年 9 月与顶级刊物 Nature 合办的世界首届「Nature Conference - AI & Robotics」大会。该算法的实现使用了基于神经网络的自回归生成模型,并使用了诸如信号能量归一化、人声增强等信号预处理和后处理的模块处理低质量数据。在模型训练过程中,我们还使用了迁移学习方法,可以在只有少量目标说话人数据的情况下提升语音合成以及歌唱合成的效果。DurIAN 在自然度、鲁棒性、可控性、泛化能力以及实时性都取得了显著进步,能够在保证端到端语音合成模型高自然度的同时又完全杜绝漏字、重复等问题,解决了一直困扰业界的端到端系统的稳定性和可控性问题。
我们研发的数字人还能实现说话转唱歌,所用技术是自创的 DurIAN-4S 的升级算法,可将说话数据和唱歌数据放在一个训练/生成框架下,从样本歌声提取基频和每一帧能量信息,在歌声生成时输入这些信息,可让 AI 自动学会样本歌声的唱歌方式和技巧。最终,我们实现了合成歌声、合成 Rap 和普通话转粤语歌的效果。
数字人的舞蹈动作生成还可以使用我们研发的生成对抗网络(Liquid Warping GAN)[1]来自动生成,并参考了三维人体重建的信息来完成相应舞蹈动作迁移。为保留迁移后的人体相关信息(如衣服纹理和颜色等),AI 会从特征和图像的层面将静态图片里的人体信息不断融合到生成的目标视频中。同时为了进一步保持静态图片里面的人体信息,我们使用了三维人体重建技术来同时建模人体关键点信息和人体身材信息。
综合起来,数字人形象的 AI 生成与实时驱动首先是训练一个动态信息预测器,学习文本/语音到三维特征数据(包括口型、表情、肢体动作)的映射关系,并综合文本、声音、视觉等多模态信息;然后再训练一个神经网络渲染器,学习目标人物的三维特征数据到最终视频画面的映射关系。我们采用了共享隐空间的方式来综合多种不同数据源信息。
二、行业应用,科技向善
行业报告
2019 年,我们发布了两份报告,即《AI与机器人的 42 个大问题》和《智能时代的技术伦理观——重塑数字社会的信任》。
《AI与机器人的 42 个大问题》[1]由腾讯 AI Lab 携手 Nature Research 发布于共同举办的 AI & Robotics 大会。报告汇集了 AI 与机器人领域中 42 个有终极目标意涵的问题,并邀请了 11 位世界知名学者为这些宏大问题给出每个人独特而深刻的理解与答案。此外,本报告还整理了大量来自网络的见解和看法。我们希望这 42 个大问题能激发对人、AI与机器人未来的长远思考与规划。
《智能时代的技术伦理观——重塑数字社会的信任》[2]由腾讯研究院和腾讯 AI Lab 联合发布,是一份旨在推动人工智能伦理道德发展的报告。报告认为在「科技向善」理念之下,需要倡导面向人工智能的新的技术伦理观,包含三个层面:技术信任,人工智能等新技术需要价值引导,做到可用、可靠、可知、可控(「四可」);个体幸福,确保人人都有追求数字福祉、幸福工作的权利,在人机共生的智能社会实现个体更自由、智慧、幸福的发展;社会可持续,践行「科技向善」,发挥好人工智能等新技术的巨大「向善」潜力,善用技术塑造健康包容可持续的智慧社会,持续推动经济发展和社会进步。
这两份报告是腾讯 AI Lab 面向「科技向善」的愿景所做出的贡献,我们希望它们可以帮助促进公众对人工智能技术和应用前景的认知、规范和引导企业与研究机构开发应用向善的科技。
AI+医疗
腾讯 AI Lab 一直以来都在拓展 AI 技术在医疗领域的应用。2019 年,我们在医疗领域取得了一些重要的研究成果:
2019 年 10 月,腾讯 AI Lab 四篇论文入选顶级医学影像会议 MICCAI,涉及病理癌症图像分类、医学影像分割、CT病灶检测等。
在全球医学影像学最顶级的会议 RSNA 上, 腾讯 AI Lab 的「SeuTao」采用多模型、多阶段、多信息融合的方法,通过添加 CT 图像的空间信息,融合医学图像病变的关联性以及有效的数据采样算法,短时间内从超过一百万幅脑部 CT 图像中找到了颅内出血的病变规律,从 1300 多支队伍中脱颖而出,取得了 Stage1 和 Stage2 双榜第一的好成绩。
应用方面,我们为腾讯的国家级影像产品「腾讯觅影」与辅诊导诊产品医疗科普平台「腾讯医典」提供了支持。智能病理显微镜也不断迭代,提升用户体验。
AI+农业
腾讯智慧农业解决方案:iGrow AIoT温室
过去的一年里,我们在农业领域也成果颇丰。通过与国内外的大学与机构合作,我们在农业科技的前沿探索与社区建设方面都做出了重要贡献:
腾讯 AI Lab 与农科院信息所成立联合实验室:借助信息所在农业领域深厚的积累整合腾讯在 AI 等前沿科技的实力,我们成立了智慧农业联合实验室,探索前沿科技和农业的跨领域研究,共同助力产业升级。
与荷兰瓦赫宁根大学联合举办第二届人工智能温室种植大赛:我们和瓦赫宁根大学一起打造自动化温室的算法控制平台,挖掘高效的人工智能种植策略。今年 9 月 12 日预赛结束,从全球来自于 26 个国家的 200 名专家与学生所组成的 21 支队伍中,来自三星电子、中国农科院、先正达(全球第一大农药、第三大种子农化公司)及首尔大学等的 5 支国际队伍脱颖而出,将在下一阶段挑战用 AI 和物联网技术等前沿技术远程控制温室种植番茄。我们将从五个方面:作物品质好、产量高、温室能耗少、操控自动化、技术可迁移,探索未来智慧农业的更大技术可能。
打造中国方案:基于在国际温室种植大赛不断累计的算法与研究基础上,我们搭建了可落地的中国智慧方案——iGrow AIoT 温室,目前已经启动线下试点。
将 AI 应用于农业是腾讯 AI Lab 发起的「AI+FEW」项目的一部分,即将人工智能应用于食物、能源和水资源(FEW),致力于解决人类所面临的重大挑战。
AI+工业
2019 年 8 月在上海举办的「2019 世界人工智能大会」上,腾讯 Robotics X 机器人实验室与腾讯 AI Lab 等多个部门协作研究项目「腾讯工业智能巡检操作机器人」首次展出,这是业界首次探索在常规巡检技术上增加远程实时的灵巧操控技术,可让机器人在石油化工等特种行业的极端环境下发挥更大作用。
在工作流程上,该机器人能利用 AI 视觉技术自主读取多种工业仪表,能辨识各类管道泄漏情况并检测物体姿态,还能实时监测物料摆放位置及监控区域人员违规行为。监测到特殊情况时,机器人会启动响应模式,自动规划路线移到事故区域。工作人员可使用自主或远程的智能遥操作,指挥机械臂对阀门或开关进行灵活抓取与操控。
该方案使用了腾讯云「云智天枢平台」机器人设备管理、云边端连接和调度能力,及面向能源化工行业的智能大数据可视化解决方案。后端处理上方案整合了公司的边缘计算能力,如TencentOS link的边缘视频处理、AI计算和数据上云。搭载5G能力时,该方案还可利用腾讯智能边缘计算网络平台TSEC(Tencent Smart Edge Connector),以更先进的网络服务提供高带宽、低延时的快捷稳定体验。
AI+内容
从个性化内容推荐到内容的自动生成,AI 与数字化内容有着天然的亲和性。依托于其庞大的内容相关业务(比如腾讯看点的整体日活跃用户量达 1.85 亿),腾讯公司一直以来都致力于推进智能技术在搜索和推荐等方面的应用。过去一年中,腾讯 AI Lab 与腾讯多个业务部门共同打造或继续改进基于机器学习的推荐引擎,并将其成功部署到了腾讯看点(看点快报、QQ看点)等重要业务中。相比于传统的基于规则的引擎,机器学习推荐引擎能够基于不同的用户画像(包含年龄、性别、地域等属性与阅读、评论、转发等行为)精准地为不同用户群体提供个性化的推荐服务。
尤其值得一提的是我们在 2019 年实现了视频内容推荐的实际应用部署。我们的方法可以通过分析视频内容和封面图来自动创建视频标签,然后根据用户的个性化模型做出视频推荐。这类技术在火热发展的短视频内容领域具有尤其重要的价值。
在内容搜索方面,我们打造了新一代海量数据搜索引擎 TurboSearch[1] 。其是我们对已有搜索系统的整体重构和优化,是一种大规模、轻量级、松耦合、可裁剪、低运营成本的完整解决方案。该引擎无缝对接了腾讯 AI Lab 的各项 NLP 能力,涵盖 Query 分析及排序等多个领域及丰富的应用场景。我们将逐步开源开放整个引擎,并构建协同开发生态系统。
三、前沿研究进展
腾讯 AI Lab 是国内领先的企业人工智能实验室。2019 年,我们在通用人工智能探索、机器学习研究、计算机视觉和自然语言处理等更细分领域的技术研发方面都做出了业界领先的贡献。通过学术会议和开放平台,我们也一直在积极与 AI 社区分享我们的成果和思考。
2019 年,腾讯 AI Lab 积极参与了人工智能相关领域中所有主流的顶级会议,包括 ACL、CVPR、EMNLP、IJCAI、AAAI、ICML、ICLR 和 NeurIPS,并且在这些会议上发表的论文数量位居国内企业实验室前列。

自 2016 年腾讯 AI Lab 成立以来腾讯在 AI 领域的论文发表情况。可以看出,腾讯在 AI 方面的研究引领国内企业,2018 和 2019 年的论文发表数量增长尤其显著。(截图来自上海交通大学 Acemap:https://www.acemap.info/ranking)
腾讯 AI Lab 不仅积极参与 AI 社区的学术会议,也主动组织了大大小小多个学术分享活动,包括腾讯 AI Lab 与 Nature Research(自然科研)及旗下《自然-机器智能》、《自然-生物医学工程》在深圳联合举办世界首届「Nature Conference - AI 与机器人大会」。
在2019年,腾讯AI Lab总计与多个高校研究机构签署29项合作,其中17项为国际和中国港澳地区著名学者的合作,包括卡内基梅隆大学、加州大学戴维斯分校、伊利诺伊大学香槟分校、悉尼大学等国际顶尖高校,以及香港科技大学、理工大学、中文大学、城市大学等港澳地区一流高校。
下面将分主题概括性地介绍腾讯 AI Lab 在 2019 年所取得的前沿探索成果。
多模态研究
现实世界的问题往往复杂而多变,仅靠单一一类技术有时候无法找到合适的解决方案。这时候,整合不同领域内的技术就显得尤其有价值了。腾讯 AI Lab 一直在积极拓展融合多个方向的技术,并已经与合作团队一起成功开发了多种现实应用。比如结合计算机视觉和自然语言处理,我们研发了使用自注意力和交互注意力模型的视频问答技术[1];我们还提出了多种通过自然语言来描述视觉内容的新方法[2][3]以及一种基于自然语言定位视频中内容的新机制 SCDM[4]。
前文提到的数字人就是一项典型的综合多类信息和技术的多模态研究,涉及计算机视觉、语音技术和自然语言处理等不同领域。
机器学习
机器学习(尤其是深度学习)是催生了近年来人工智能发展热潮的最重要的技术,这类技术最核心的意义是能让机器具备自动发现模式和寻找解决方案的能力。腾讯 AI Lab 在机器学习方面的研究主题包括强化学习、自动机器学习、深度图学习、小样本学习等。
强化学习
强化学习是近年来大放异彩的机器学习技术之一,基于这种技术开发的人工智能模型已经在围棋、扑克、视频游戏和机器人等领域取得了非常多的里程碑式的进步。我们在强化学习方面的研究大都立足于游戏环境,包括围棋以及视频游戏《王者荣耀》和《星际争霸》。
前文已经提到,我们开发的强化学习智能体绝艺和绝悟已经取得很多重大的突破,并且通过与顶级人类玩家比拼的方式取得了多个亮眼的里程碑。2019 年我们在强化学习领域的前沿探索还包括:
为多智能体强化学习环境提出了一种新的元学习方法 LIIR [1],能够通过优化各个智能体的内在奖励值来实现对总体目标的整体优化,这种方法可以激励不同智能体采取多样化的有利于团队的行为。我们用这种方法让《星际争霸 2》智能体学会了更多样化的决策策略。
提出了一种散度增强的策略优化算法 [2],能在重复使用离线数据时实现对策略优化训练的稳定化。这种方法有利于在数据不足的环境中进行学习。
提出了一种针对训练数据选择方法的强化学习框架 [3],可以很好地处理数据的领域迁移任务。
提出了一种基于强化学习的端到端主动目标跟踪方法,通过自定义奖赏函数和环境增强技术在虚拟环境中训练得到鲁棒的主动跟踪器,并在真实场景中对模型的泛化能力进行了进一步的验证。
自动机器学习
如今的机器学习模型有往越来越大、越来越深发展的趋势,也因此通过人工方法来设计模型和配置超参数的思路越来越捉襟见肘。因此,通过自动化的方式来设计/搜索模型架构和超参数的方法正受到越来越多的研究关注和应用。
在架构搜索和优化方面,我们提出了一种神经网络架构变形器 NAT [1],其可以将冗余操作替换为计算效率更高的操作,从而获得精确且紧凑型架构。而在超参数优化方面,我们提出了一种基于分布的贝叶斯优化算法 DistBO [2],它可以迁移历史任务超参数优化的知识,进而对新任务上的超参数优化起到热启动的效果。
我们也研究了通过迁移学习来简化模型的学习过程,比如通过迁移来自真实图像的知识来引导素描图片识别网络的学习过程[3];我们还提出了一种基于渐进式特征对齐的无监督域自适应方法[4],其中包含一种由易到难的迁移策略(EHTS)和一个自适应中心向量对齐步骤(APA),可以迭代并交替地训练域适应网络;另外我们还提出了一种无标签领域自适应算法[5],可用以辅助癌症诊断任务的病理图像分类学习。另外值得一提出的是我们还在一项研究[6]中探索了组合使用迁移学习、多任务学习和半监督学习的方法,并研究了如何通过组合方法来提升医学分类模型的准确率。
另外,为了保证机器学习模型能在现实生活中得到应用,很多时候还需要对模型进行压缩处理,以便在尽可能保证模型优良表现的同时提升模型的执行效率。我们提出了一种名为「协同通道剪枝(Collaborative Channel Pruning )」[7]的模型压缩算法,可以保证在准确度无损的前提下有效降低模型的计算成本,从而可让深度学习模型在移动设备等更多场景中得到应用。我们还提出了一种用于压缩卷积神经网络(CNN)[8]的方法,这种方法基于我们定义的一种可分解卷积滤波器,可以实现非常优良的模型压缩效果。
其他机器学习方法
除此之外,腾讯 AI Lab 也在探索其它形式的机器学习方法,比如结合图学习与深度学习的深度图学习、小样本学习、和多模态学习等方向。
深度图学习是我们的一个非常重要的研究方向,可以帮助我们理解大型信息和知识网络(比如社交网络,这是腾讯的核心业务之一)中的关系信息。在深度图学习方面,我们专注于解决「深度」和「广度」这两个具有深度图学习中具有挑战性的问题。在「深度」方面,我们提出的 DropEdge 方法[1]可让我们更好地学习超深层图神经网络,得到表现显著更佳的结果。在「广度」方面,我们基于自主研发的图采样算法AS-GCN[2],即自适应结构采样图卷积神经网络,开发了可以分布式学习超大规模图数据的图学习系统——在亿级别的超大规模图数据上,我们可以在不到5分钟内完成单次训练迭代。同时,我们也将深度扩图学习算法成功应用到不同领域,如复杂社交网络[3],谣言检测,对抗攻击[4]等。
小样本学习在实际应用中也具有极其重要的价值,毕竟不是每一种应用场景都存在可以轻松收集或标注的数据集。针对这一任务,我们提出了一种基于层次任务结构的元学习算法(HSML)[5],该方法可以迅速找到与新任务最相关的聚类,然后从该聚类的任务中迁移和泛化知识。
腾讯的业务中包含许多需要处理多模态数据的场景,比如通过分析视频内容与用户弹幕来理解用户观看节目时的情绪。针对多模态数据,我们提出了一种高效的特征提取方法[6],该方法可以学习到更有信息量的特征映射,同时优化过程也更为高效。另外我们还提出了一种使用对抗样本的跨模态学习方法(CMLA)[7],该方法创造的对抗样本能快速地骗过一个目标跨模态哈希网络,另一方面也能通过对抗训练提升该目标跨模态哈希网络的鲁棒性。
除此之外,腾讯 AI Lab 在机器学习方面还有一些更多的研究探索,并提出了一些可能具备进一步研究潜力的新方法改进,此处不再一一赘述。
计算机视觉
计算机视觉的重要意义是让机器具备看懂世界的眼睛。腾讯在计算机视觉方面具备业界领先的研发实力,在计算机视觉领域顶级会议 CVPR 2019 上,腾讯共有 58 篇论文入选,其中 33 篇(含 8 篇 Oral 展示论文)来自腾讯 AI Lab。这些研究成果涵盖视频理解、人脸识别、计算机视觉模型对抗攻击、视觉-语言描述等多个重要方向,详情参阅《CVPR 2019 | 腾讯AI Lab解读六大前沿方向及33篇入选论文》。
我们的很多研究工作集中在数字人的多模态课题中。除此之外,我们也持续关注视频理解方向,并在顶级期刊和会议发表论文 14 篇。我们聚焦视频的分类、表示、检索、缩略和生成等技术,相关能力已落地在微信的搜一搜和看一看等功能。我们还提出了无监督跟踪、语句引导的描述生成、基于内容的视频片段检索定位等新的视觉任务,深化此类研究。
语音
语音识别是人工智能领域一个已经得到高度发展的研究方向,现在的基于深度学习的模型已经能够很好地处理多种不同场景中的语音识别任务;但在语音合成方面还有很大的进步空间。2019 年,我们提出了一种全新的端到端合成建模方案 DurIAN [1],其合作结果的质量和自然度能与真人发音相媲美,而且还具备丰富的发音风格与强大的韵律表现力。我们期望这一方案能帮助实现更加自然亲切的人机交互体验。
我们还开展了大量算法研究和改进工作,以提升核心的基础技术的覆盖范围和性能。包括
重新架构了麦克风阵列前处理系统的算法和代码实现,使之变得更通用化和模块化;
改进了传统的 AEC(回声消除)算法,提升双工性能,这项技术在语音交互应用(比如智能音箱)中有重要应用价值;
研发了自定义唤醒词检测系统,实现了从唤醒词文本到唤醒词检测模型的直接映射,达到了和之前固定唤醒词系统相近的唤醒性能。
我们的部分研究成果已经成功整合到了我们的语音解决方案中,同时我们也在拓展更多的落地场景,辅助其它伙伴的业务,目前已全面覆盖了智能电视、车载、智能音箱等产品。

智能语音交互系统工作过程示意图以及使用了该系统的腾讯产品
自然语言处理
自然语言处理(NLP)的终极目的是让机器有能力通过自然语言与人类进行流畅自然地交互。在 2019 年自然语言处理领域顶级会议 ACL 上,腾讯 AI Lab 有 20 篇论文被接收,详见解读文章《ACL 2019 | 腾讯AI Lab解读三大前沿方向及20篇入选论文》。
NLP 领域的任务主要分为两大类:自然语言理解(NLU)和自然语言生成(NLG)。如下图所示,腾讯 AI Lab 的研究方向囊括了从自然语言理解到生成的整个链条。

腾讯 AI Lab 在 NLP 领域的研究方向
在自然语言理解方面,2019 年我们继续发力,在文本表征、实体分析、语义理解和语义关系图学习方面都进行了一些前沿探索。
在人机对话与文本生成方面,我们提出了多种对话生成新框架,包括结合检索和生成技术的骨架生成技术[1];一种可用于提升对话多样性的回复生成模型的离散型变分自编码器(Discrete CVAE)[2];一个大规模预训练语言模型[3],可应用于对话生成来获得更流畅更多样的回复。另外,我们还发布了多个对话数据集:带有对话句子功能标注的单轮对话数据集[4]、用于多轮对话理解的数据集[5]、用于检索加生成技术研究的数据集[6]等。我们也在继续改进我们的开放域对话系统,该系统已经在腾讯云、腾讯叮当平台、腾讯 AI 开放平台等平台,以及企鹅电视盒子、《我的起源》等终端产品中得到了应用。
在机器翻译研究方面,我们继续探索主流翻译模型中的自注意力模型改进[7]和篇章翻译[8]。同时,我们尝试打开神经网络翻译模型的黑盒子,解释其中核心问题的运行机制,比如自注意力模型的词序学习能力[9]和多层翻译模型中的词对齐[10]等。我们也在努力将我们的前沿探索成果应用于实际产品:2019 年我们对 2018 年发布的 AI 辅助翻译产品「腾讯辅助翻译(TranSmart)」进行了进一步的改进和提升。TranSmart 是国内大中型互联网公司的翻译系统中唯一具备人机交互翻译功能的,此外系统的自动翻译(中英和英中)准确度居于国内前列。
四、总结与展望
在过去的一年里,腾讯 AI Lab 通过「AI+游戏」与「数字人」探索了人工智能领域两大重要难题:通用人工智能和多模态研究;并取得了显著的进步。同时,我们在医疗、农业、工业、内容、社交等领域都做出了有价值的应用成果,并为「科技向善」做出了贡献。在前沿研究探索中,我们持续发力,在机器学习、强化学习、自然语言处理、计算机视觉和语音技术等方向继续推进,而且我们也通过 AI 领域的顶级会议与论文开放平台分享了我们的探索成果。
新的一年,我们将再接再厉,在继续探索已有方向的前沿进展的同时,也将扩大对智能机器人、深度学习处理器、互联网与边缘计算等技术方向的专研。我们也将扩大开放力度,与社区共建合作共荣的生态。同时,我们也会继续坚持「科技向善」,为创造一个美好的人类世界贡献自己的力量。
相关链接(含论文地址):
数字人研究
[1] 生成对抗网络(Liquid Warping GAN)
https://arxiv.org/abs/1909.12224
行业报告
[1] 《AI与机器人的 42 个大问题》
https://share.weiyun.com/5IM4LFU
[2] 《智能时代的技术伦理观——重塑数字社会的信任》
http://www.cbdio.com/image/site2/20190729/f42853157e261ea8a87f55.pdfAI+内容
[1] 新一代海量数据搜索引擎 TurboSearch
https://cloud.tencent.com/developer/article/1548031
多模态研究
[1] 使用自注意力和交互注意力模型的视频问答技术
https://www.aaai.org/ojs/index.php/AAAI/article/view/4887
多种通过自然语言来描述视觉内容的新方法:
[2] https://arxiv.org/abs/1805.12589
[3] https://arxiv.org/abs/1811.10787
[4] 一种基于自然语言定位视频中内容的新机制 SCDM
https://papers.nips.cc/paper/8344-semantic-conditioned-dynamic-modulation-for-temporal-sentence-grounding-in-videos
强化学习
[1] 元学习方法 LIIR
https://papers.nips.cc/paper/8691-liir-learning-individual-intrinsic-reward-in-multi-agent-reinforcement-learning
[2] 散度增强的策略优化算法
https://papers.nips.cc/paper/8842-divergence-augmented-policy-optimization
[3] 针对训练数据选择方法的强化学习框架
https://www.aclweb.org/anthology/P19-1189/
自动机器学习
[1]神经网络架构变形器 NAT
https://nips.cc/Conferences/2019/Schedule?showEvent=13305
[2]基于分布的贝叶斯优化算法 DistBO
https://papers.nips.cc/paper/8905-hyperparameter-learning-via-distributional-transfer
[3]通过迁移来自真实图像的知识来引导素描图片识别网络的学习过程
https://www.aaai.org/ojs/index.php/AAAI/article/view/4955
[4]基于渐进式特征对齐的无监督域自适应方法
https://arxiv.org/abs/1811.08585
[5]无标签领域自适应算法
https://link.springer.com/chapter/10.1007/978-3-030-32239-7_40
[6]https://link.springer.com/chapter/10.1007/978-3-030-32254-0_48
[7]协同通道剪枝(Collaborative Channel Pruning )
http://proceedings.mlr.press/v97/peng19c/peng19c.pdf
[8]用于压缩卷积神经网络(CNN)的方法
http://openaccess.thecvf.com/content_CVPR_2019/papers/Li_Compressing_Convolutional_Neural_Networks_via_Factorized_Convolutional_Filters_CVPR_2019_paper.pdf
其他机器学习方法
[1]DropEdge 方法
https://arxiv.org/abs/1907.10903
[2]图采样算法AS-GCN
https://arxiv.org/abs/1904.12659
[3]复杂社交网络
https://arxiv.org/abs/1904.05003
[4]对抗攻击
https://arxiv.org/abs/1908.01297
[5]元学习算法(HSML)
http://proceedings.mlr.press/v97/yao19b/yao19b.pdf
[6]一种高效的特征提取方法
https://arxiv.org/abs/1811.08979
[7]使用对抗样本的跨模态学习方法(CMLA)
https://papers.nips.cc/paper/9262-cross-modal-learning-with-adversarial-samples
语音
[1]端到端合成建模方案 DurIAN
https://arxiv.org/abs/1909.01700
自然语言处理
[1]结合检索和生成技术的骨架生成技术
https://ai.tencent.com/ailab/nlp/dialogue/papers/EMNLP2019_cd.pdf
[2]离散型变分自编码器(Discrete CVAE)
https://ai.tencent.com/ailab/nlp/dialogue/papers/EMNLP2019_jungao.pdf
[3]一个大规模预训练语言模型
http://arxiv.org/abs/1911.11489
[4]单轮对话数据集
https://arxiv.org/abs/1907.10302
[5]用于多轮对话理解的数据集
https://ai.tencent.com/ailab/nlp/dialogue/papers/EMNLP_zhufengpan.pdf
[6]用于检索加生成技术研究的数据集
https://ai.tencent.com/ailab/nlp/dialogue/papers/EMNLP2019_cd.pdf
[7]自注意力模型改进
https://arxiv.org/abs/1909.02222
[8]篇章翻译
https://arxiv.org/abs/1909.00369
[9]自注意力模型的词序学习能力
https://www.aclweb.org/anthology/P19-1354
[10]多层翻译模型中的词对齐
https://www.aclweb.org/anthology/P19-1124
方便交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐阅读:
【ACL 2019】腾讯AI Lab解读三大前沿方向及20篇入选论文
【一分钟论文】IJCAI2019 | Self-attentive Biaffine Dependency Parsing
【一分钟论文】 NAACL2019-使用感知句法词表示的句法增强神经机器翻译
【一分钟论文】Semi-supervised Sequence Learning半监督序列学习
【一分钟论文】Deep Biaffine Attention for Neural Dependency Parsing
详解Transition-based Dependency parser基于转移的依存句法解析器
经验 | 初入NLP领域的一些小建议
学术 | 如何写一篇合格的NLP论文
干货 | 那些高产的学者都是怎样工作的?
一个简单有效的联合模型
近年来NLP在法律领域的相关研究工作

让更多的人知道你“在看”
