5折交叉验证_交叉验证:评估模型表现
注明:本文章所有代码均来自scikit-learn官方网站
在实际情况中,如果一个模型要上线,数据分析员需要反复调试模型,以防止模型仅在已知数据集的表现较好,在未知数据集上的表现较差。即要确保模型的泛化能力,它指机器学习对新鲜样本的适应能力。只有保证模型的泛化能力,模型的构建才有意义。因此,交叉验证在整个建模流程中显得尤为重要。
如果不对数据集进行处理,而仅是用含有标签的已知数据训练模型会得到很高分数,但却失效于对未知数据的预测,这种情况称为“过拟合”。过拟合的出现表明模型未学习到数据中的本质规律,造成模型的预测能力较差,因此,如何避免模型的过拟合,是一个值得关注且必须解决的问题。在scikit-learn中,可以使用训练集/测试集拆分和交叉验证的方法避免该种情况的出现,如下图所示,将数据集进行训练集/测试集拆分,在训练集上进行交叉验证后得到最佳模型参数,从而在测试集上得到该模型的评分。
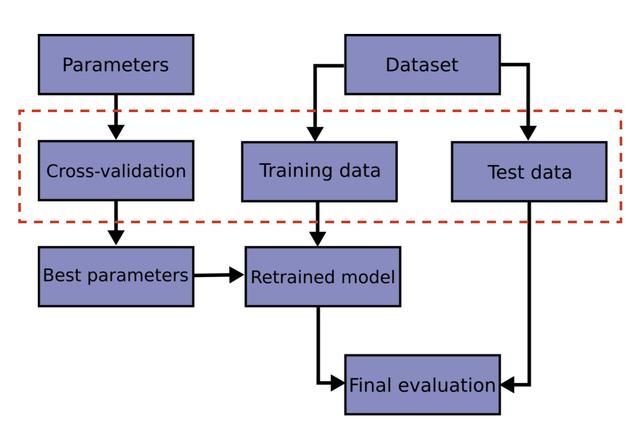
在开始分享之前,要搞清楚两个概念,即过拟合和欠拟合。其中,过拟合为模型在训练集的分数较高,在测试集表现的得分较低。欠拟合是指模型拟合程度不高,数据距离拟合曲线较远,或指模型没有很好地捕捉到数据特征,不能够很好地拟合数据。相对过拟合,欠拟合现象并不经常出现。很容易想到的思路是将模型的拟合能力限制在过拟合和欠拟合之间,就会得到较好的模型预测结果,但训练集/测试集划分和交叉验证只能帮助避免模型的过拟合而不是欠拟合。
以sklearn中自带的莺尾花数据集(iris)为例进行说明:
>>> import numpy as np
>>> from sklearn.model_selection import train_test_split
>>> from sklearn import datasets
>>> from sklearn import svm
>>> X, y = datasets.load_iris(return_X_y=True)
>>> X.shape, y.shape
((150, 4), (150,)) 将数据集拆分为60%训练集,40%测试集,代码如下:
>>> X_train, X_test, y_train, y_test = train_test_split(
... X, y, test_size=0.4, random_state=0)
>>> X_train.shape, y_train.shape
((90, 4), (90,))
>>> X_test.shape, y_test.shape
((60, 4), (60,))
>>> clf = svm.SVC(kernel='linear', C=1).fit(X_train, y_train)
>>> clf.score(X_test, y_test)
0.96... 尽管此时模型在测试集上的得分较高,表现较好,但不能说明找到了最佳的适用模型,譬如支持向量机的超参数C,上例中设置参数C=1,它在训练集上的表现可能很好,但仍不能避免过拟合现象的出现,因为不适宜的超参数设置可能导致模型对数据中主要规律的学习,因此,会在测试集上出现过拟合的现象。为了避免上述情况,scikit-learn提供交叉验证法(cross-validation, CV)。需要注意的是:k值越大,即褶皱越多,从而越能减少由于偏差而导致的误差,但训练集越大,会增加方差从而增加模型的误差。同时,越大的k值会导致时间成本的开销较高。因此,k值的选取很重要,常见取值为k = 10。
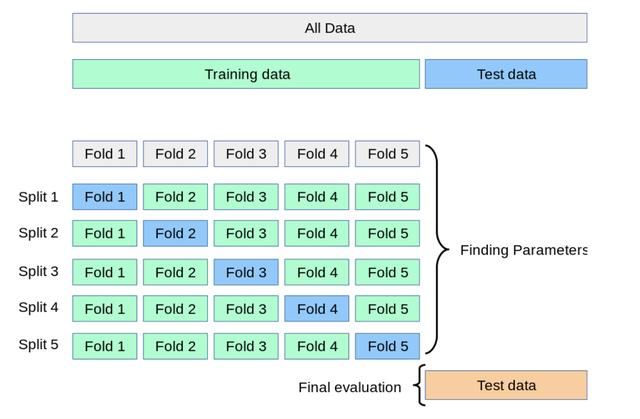
下例中的cv值设置为5,进行5次交叉验证迭代,得出5个模型评分:
>>> from sklearn.model_selection import cross_val_score
>>> clf = svm.SVC(kernel='linear', C=1)
>>> scores = cross_val_score(clf, X, y, cv=5)
>>> scores
array([0.96..., 1. ..., 0.96..., 0.96..., 1. ]) 针对不同模型和实际场景,还可以调整交叉验证的评分策略,需要注意的是:在scikit-learn官方文档中,指明了五种交叉验证方法(五种方法分别为:K-fold, Repeated K-fold, Leave One Out, Leave P Out, Random permutations cross-validation a.k.a. Shuffle & Split)的数据应是服从独立同分布假设的,在此基础上,交叉验证的结果较好,但文档中也说明,独立同分布假设在现实中很难保证,因此,在应用交叉验证方法时,可适当放宽假设条件,但可能会让度一部分结果准确性。
其中,K折交叉验证(K-fold cross-validation)是交叉验证大家族中最简单的数据拆分策略,即将数据集拆分为训练集和测试集,如下图所示,其原理为:先将整个数据集分为k个折叠,用其中k-1个折叠作为训练集训练模型,用剩余的1个折叠作为验证集对模型进行评分,并重复k次上述过程。该种方法的优势在于不需要额外拆分数据,以避免数据的浪费和运算成本的提高;可以促使模型从多方面学习样本,避免模型陷入局部极值。
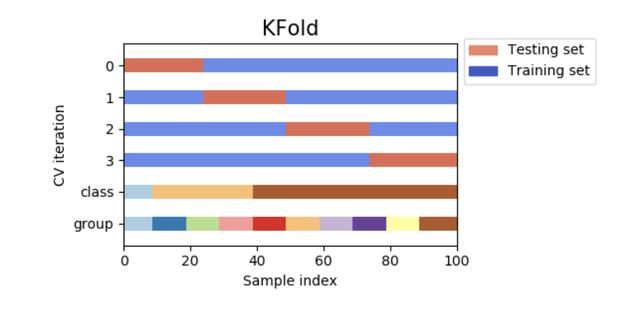
如下是对有4个样本的2-折交叉验证示例,随机将数据分为两个折叠,并且迭代上述步骤两次。其代码如下:
>>> import numpy as np
>>> from sklearn.model_selection import KFold
>>> X = ["a", "b", "c", "d"]
>>> kf = KFold(n_splits=2)
>>> for train, test in kf.split(X):
... print("%s %s" % (train, test))
[2 3] [0 1]
[0 1] [2 3] 在scikit-learn中,还提供基于K折(KFold)法的进一步交叉验证法,为重复的K折(Repeated K-Fold),即将K折重复n次,通过设置n_repeats参数进行传递。其底层原理与KFold相一致,不同点在于重复的K折将K折重复n_repeats次。
选用的数据集与K折示例中的相同,设置n_repeats参数值为2,其代码如下:
>>> import numpy as np
>>> from sklearn.model_selection import RepeatedKFold
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
>>> random_state = 12883823
>>> rkf = RepeatedKFold(n_splits=2, n_repeats=2, random_state=random_state)
>>> for train, test in rkf.split(X):
... print("%s %s" % (train, test))
...
[2 3] [0 1]
[0 1] [2 3]
[0 2] [1 3]
[1 3] [0 2]比较出名的是留一法(Leave One Out),它是一个简单又有趣的交叉验证方法。其原理是出去一个样本外,保留数据集中的所有样本,从而将用于交叉验证的数据集(假设共有n个样本)分为训练集(n-1个样本)和测试集(1个样本)的组合,使得对于一个包含n个样本的数据集而言,可以有n个测试集对模型进行评估。该方法的优势在于最大可能的保证用于模型训练的数据量,仅牺牲一个样本作为测试集,对于大样本而言是可以忽略不计的。
如下的示例中,仍延用上一个例子中的包含四个样本的数据,在每次迭代中,从四个样本中分出一个样本作为测试集。其代码如下:
>>> from sklearn.model_selection import LeaveOneOut
>>> X = [1, 2, 3, 4]
>>> loo = LeaveOneOut()
>>> for train, test in loo.split(X):
... print("%s %s" % (train, test))
[1 2 3] [0]
[0 2 3] [1]
[0 1 3] [2]
[0 1 2] [3] 提到留一法(Leave One Out)就不得不说留P法(Leave P Out),两种方法的底层逻辑相同,只是留P法在留一方的基础上为使用者提供更大的自由空间,使用者可以根据业务场景需要自定义要移除的样本个数,即作为测试集样本的个数。需要注意的是:与留一法和KFold法不同的是,当参数p>1时,测试集可能会重叠。
在如下例子中,仍延用上文中包含四个样本的例子,将参数p设置为2对数据集进行拆分,在四个样本的例子中,可以有6种数据拆分的方法。代码如下:
>>> from sklearn.model_selection import LeavePOut
>>> X = np.ones(4)
>>> lpo = LeavePOut(p=2)
>>> for train, test in lpo.split(X):
... print("%s %s" % (train, test))
[2 3] [0 1]
[1 3] [0 2]
[1 2] [0 3]
[0 3] [1 2]
[0 2] [1 3]
[0 1] [2 3] 最后,想要分享的交叉验证方法是随机排列交叉验证 a.k.a. Shuffle & Split(Random permutations cross-validation a.k.a. Shuffle & Split)。如下图所示,其底层逻辑为:在用户指定数量的基础上,利用ShuffleSplit迭代器生成独立的训练集/测试集划分。其步骤是先打乱样本,再将样本分为不同的训练集和测试集的组合。由于该中方法的随机性较强,因此可以设置随机数种子保证每次数据拆分的结果相同,以得到相同的交叉验证结果,该参数为random_state。
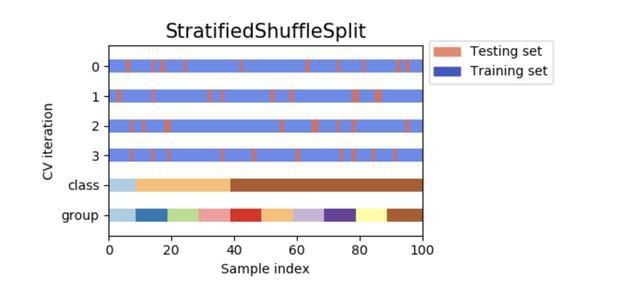
该例子是用np.arange(10)生成从0-9的10个数,n_splits参数限制数据集划分的组数,test_size参数限制用于交叉验证的测试集大小,其代码示例如下:
>>> from sklearn.model_selection import ShuffleSplit
>>> X = np.arange(10)
>>> ss = ShuffleSplit(n_splits=5, test_size=0.25, random_state=0)
>>> for train_index, test_index in ss.split(X):
... print("%s %s" % (train_index, test_index))
[9 1 6 7 3 0 5] [2 8 4]
[2 9 8 0 6 7 4] [3 5 1]
[4 5 1 0 6 9 7] [2 3 8]
[2 7 5 8 0 3 4] [6 1 9]
[4 1 0 6 8 9 3] [5 2 7]本部分新的主要分享了最基本的交叉验证的调用,和五个不同的交叉验证方法,分别为K-折叠(K-Fold),重复的K-折叠(Repeated K-Fold),留一法(Leave One Out),留P法(Leave P Out),随机排列交叉验证a.k.a. Shuffle & Split(Random permutations cross-validation a.k.a. Shuffle & Split),从而,更加细化的了解交叉验证方法。
不同的交叉验证方法针对的场景不同,因次,需要根据不同的实际情况,选择不同的方法对数据进行交叉验证,以提高模型的泛化能力和避免过拟合情况的出现。在后面的内容中,将继续分享交叉验证部分的学习心得。
(1)获取更多优质内容及精彩资讯,可前往:https://www.cda.cn/?seo
(2)了解更多数据领域的优质课程:
https://u.wechat.com/MGNP1Dwa3Z-NVdhFmu-ycmk (二维码自动识别)