目标检测回归损失函数简介:SmoothL1/IoU/GIoU/DIoU/CIoU Loss
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
来源:极市平台
目标检测任务的损失函数由Classificition Loss和Bounding Box Regeression Loss两部分构成。本文介绍目标检测任务中近几年来Bounding Box Regression Loss Function的演进过程,其演进路线是Smooth L1 Loss IoU Loss GIoU Loss DIoU Loss CIoU Loss,本文按照此路线进行讲解。
1. Smooth L1 Loss
本方法由微软rgb大神提出,Fast RCNN论文提出该方法
1.1 假设x为预测框和真实框之间的数值差异,常用的L1和L2 Loss定义为:
1.2 上述的3个损失函数对x的导数分别为:
从损失函数对x的导数可知: 损失函数对x的导数为常数,在训练后期,x很小时,如果learning rate 不变,损失函数会在稳定值附近波动,很难收敛到更高的精度。 损失函数对x的导数在x值很大时,其导数也非常大,在训练初期不稳定。 完美的避开了 和 损失的缺点。
1.3 实际目标检测框回归任务中的损失loss为:
其中 表示GT 的框坐标, 表示预测的框坐标,即分别求4个点的loss,然后相加作为Bounding Box Regression Loss。
<img src="https://pic3.zhimg.com/v2-53ea9d7383ee310a5bb8a0faddbadb4a_b.jpg" data-size="small" data-rawwidth="928" data-rawheight="544" class="origin_image zh-lightbox-thumb" width="928" data-original="https://pic3.zhimg.com/v2-53ea9d7383ee310a5bb8a0faddbadb4a_r.jpg"/>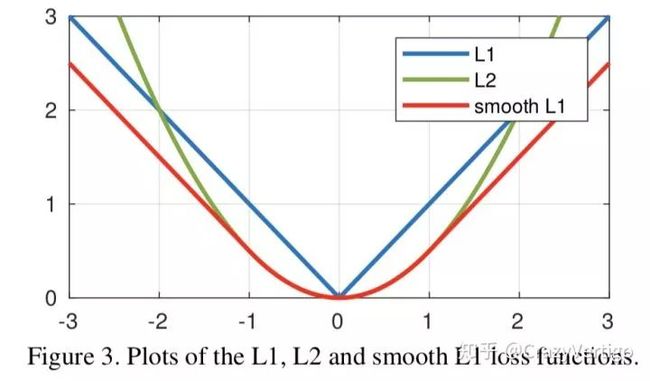 三种loss的曲线图如图所示,可以看到Smooth L1相比L1的曲线更加的Smooth
三种loss的曲线图如图所示,可以看到Smooth L1相比L1的曲线更加的Smooth
缺点:
上面的三种Loss用于计算目标检测的Bounding Box Loss时,独立的求出4个点的Loss,然后进行相加得到最终的Bounding Box Loss,这种做法的假设是4个点是相互独立的,实际是有一定相关性的
实际评价框检测的指标是使用IOU,这两者是不等价的,多个检测框可能有相同大小的 Loss,但IOU可能差异很大,为了解决这个问题就引入了IOU LOSS。
2. IoU Loss
本文由旷视提出,发表于2016 ACM
2.1 通过4个坐标点独立回归Building boxes的缺点:
检测评价的方式是使用IoU,而实际回归坐标框的时候是使用4个坐标点,如下图所示,是不等价的;L1或者L2 Loss相同的框,其IoU 不是唯一的
通过4个点回归坐标框的方式是假设4个坐标点是相互独立的,没有考虑其相关性,实际4个坐标点具有一定的相关性
基于L1和L2的距离的loss对于尺度不具有不变性
 图(a)中的三组框具有相同的L2 Loss,但其IoU差异很大;图(b)中的三组框具有相同的L1 Loss,但IoU 同样差异很大,说明L1,L2这些Loss用于回归任务时,不能等价于最后用于评测检测的IoU.
图(a)中的三组框具有相同的L2 Loss,但其IoU差异很大;图(b)中的三组框具有相同的L1 Loss,但IoU 同样差异很大,说明L1,L2这些Loss用于回归任务时,不能等价于最后用于评测检测的IoU.
2.2 基于此提出IoU Loss,其将4个点构成的box看成一个整体进行回归:
<img src="https://pic2.zhimg.com/v2-090938dacc24098c4e54aa18968f375d_b.jpg" data-size="normal" data-rawwidth="1180" data-rawheight="590" class="origin_image zh-lightbox-thumb" width="1180" data-original="https://pic2.zhimg.com/v2-090938dacc24098c4e54aa18968f375d_r.jpg"/> 上图中的红色点表示目标检测网络结构中Head部分上的点(i,j),绿色的框表示Ground truth框, 蓝色的框表示Prediction的框,IoU loss的定义如上,先求出2个框的IoU,然后再求个-ln(IoU),实际很多是直接定义为IoU Loss = 1-IoU
上图中的红色点表示目标检测网络结构中Head部分上的点(i,j),绿色的框表示Ground truth框, 蓝色的框表示Prediction的框,IoU loss的定义如上,先求出2个框的IoU,然后再求个-ln(IoU),实际很多是直接定义为IoU Loss = 1-IoU
<img src="https://pic3.zhimg.com/v2-98c4ef8ce3a150153be57a454bf2f6ee_b.jpg" data-size="normal" data-rawwidth="548" data-rawheight="468" class="origin_image zh-lightbox-thumb" width="548" data-original="https://pic3.zhimg.com/v2-98c4ef8ce3a150153be57a454bf2f6ee_r.jpg"/>
 IoU Loss 前项推理时的算法实现方式
IoU Loss 前项推理时的算法实现方式
附录:
论文链接:https://arxiv.org/pdf/1608.01471.pdf
3 GIoU Loss
本文由斯坦福学者提出,发表于CVPR2019
3.1 IoU Loss 有2个缺点:
当预测框和目标框不相交时,IoU(A,B)=0时,不能反映A,B距离的远近,此时损失函数不可导,IoU Loss 无法优化两个框不相交的情况。
假设预测框和目标框的大小都确定,只要两个框的相交值是确定的,其IoU值是相同时,IoU值不能反映两个框是如何相交的。
 如上图所示,三种不同相对位置的框拥有相同的IoU=0.33值,但是拥有不同的GIoU=0.33,0.24,-0.1。当框的对齐方向更好一些时GIoU的值会更高一些。 <img src="https://pic4.zhimg.com/v2-1558e62bdf4a379a7cd6904389d9dfa7_b.jpg" data-size="normal" data-rawwidth="850" data-rawheight="391" class="origin_image zh-lightbox-thumb" width="850" data-original="https://pic4.zhimg.com/v2-1558e62bdf4a379a7cd6904389d9dfa7_r.jpg"/>
如上图所示,三种不同相对位置的框拥有相同的IoU=0.33值,但是拥有不同的GIoU=0.33,0.24,-0.1。当框的对齐方向更好一些时GIoU的值会更高一些。 <img src="https://pic4.zhimg.com/v2-1558e62bdf4a379a7cd6904389d9dfa7_b.jpg" data-size="normal" data-rawwidth="850" data-rawheight="391" class="origin_image zh-lightbox-thumb" width="850" data-original="https://pic4.zhimg.com/v2-1558e62bdf4a379a7cd6904389d9dfa7_r.jpg"/>  GIoU的实现方式如上,其中C为A和B的外接矩形。用C减去A和B的并集除以C得到一个数值,然后再用框A和B的IoU减去这个数值即可得到GIoU的值。
GIoU的实现方式如上,其中C为A和B的外接矩形。用C减去A和B的并集除以C得到一个数值,然后再用框A和B的IoU减去这个数值即可得到GIoU的值。
GIoU的性质
GIoU和IoU一样,可以作为一种距离的衡量方式,
GIoU具有尺度不变性
对于 ,有 且 ,因此 当 时,两者相同都等于1,此时 等于1
当 和 不相交时,
附录
论文链接:https://arxiv.org/abs/1902.09630
github链接:https://github.com/generalized-iou/g-darknet
参考链接:目标检测算法之CVPR2019 GIoU Loss(https://mp.weixin.qq.com/s/CNVgrIkv8hVyLRhMuQ40EA)
实现结论和启发:
本文提出了GIoU Loss,最终单阶段检测器YOLO v1涨了2个点,两阶段检测器涨点相对较少(RPN的box比较多,两个框未相交的数量相对较少)
4. DIoU Loss
本文发表在AAAI 2020
GIoU Loss不足
<img src="https://pic2.zhimg.com/v2-d32d8fd6e32ecca603ea9678695b7241_b.jpg" data-size="small" data-rawwidth="715" data-rawheight="386" class="origin_image zh-lightbox-thumb" width="715" data-original="https://pic2.zhimg.com/v2-d32d8fd6e32ecca603ea9678695b7241_r.jpg"/> 当目标框完全包裹预测框的时候,IoU和GIoU的值都一样,此时GIoU退化为IoU, 无法区分其相对位置关系;此时作者提出的DIoU因为加入了中心点归一化距离,所以可以更好地优化此类问题。
当目标框完全包裹预测框的时候,IoU和GIoU的值都一样,此时GIoU退化为IoU, 无法区分其相对位置关系;此时作者提出的DIoU因为加入了中心点归一化距离,所以可以更好地优化此类问题。
启发点:
基于IoU和GIoU存在的问题,作者提出了两个问题:
第一:直接最小化预测框与目标框之间的归一化距离是否可行,以达到更快的收敛速度。
第二:如何使回归在与目标框有重叠甚至包含时更准确、更快。
好的目标框回归损失应该考虑三个重要的几何因素:重叠面积,中心点距离,长宽比。基于问题一,作者提出了DIoU Loss,相对于GIoU Loss收敛速度更快,该Loss考虑了重叠面积和中心点距离,但没有考虑到长宽比;针对问题二,作者提出了CIoU Loss,其收敛的精度更高,以上三个因素都考虑到了。
Distance-IoU Loss
通常基于IoU-based的loss可以定义为 ,其中 定义为预测框 和目标框 的惩罚项。
DIoU中的惩罚项表示为 ,其中 和 分别表示 和 的中心点, 表示欧式距离, 表示 和 的最小外界矩形的对角线距离,如下图所示。可以将DIoU替换IoU用于NMS算法当中,也即论文提出的DIoU-NMS,实验结果表明有一定的提升。
DIoU Loss function定义为:
 上图中绿色框为目标框,黑色框为预测框,灰色框为两者的最小外界矩形框,d表示目标框和真实框的中心点距离,c表示最小外界矩形框的距离。
上图中绿色框为目标框,黑色框为预测框,灰色框为两者的最小外界矩形框,d表示目标框和真实框的中心点距离,c表示最小外界矩形框的距离。
DIoU的性质:
尺度不变性
当两个框完全重合时, ,当2个框不相交时
DIoU Loss可以直接优化2个框直接的距离,比GIoU Loss收敛速度更快
对于目标框包裹预测框的这种情况,DIoU Loss可以收敛的很快,而GIoU Loss此时退化为IoU Loss收敛速度较慢
5. CIoU Loss
Complete-loU Loss
CIoU的惩罚项是在DIoU的惩罚项基础上加了一个影响因子 ,这个因子把预测框长宽比拟合目标框的长宽比考虑进去。 ,其中 是用于做trade-off的参数, , 是用来衡量长宽比一致性的参数,定义为
CIoU Loss function的定义为
DIoU和CIoU的提升效果
<img src="https://pic3.zhimg.com/v2-a12352f61e99815b75eae99881e7634e_b.jpg" data-size="normal" data-rawwidth="941" data-rawheight="493" class="origin_image zh-lightbox-thumb" width="941" data-original="https://pic3.zhimg.com/v2-a12352f61e99815b75eae99881e7634e_r.jpg"/> 上表中左边是用5种不同Boudning Box Regression Loss Function的对比,右边是以IoU和GIoU来计算的2种Evaluation的结果;GIoU相对IoU会有2.49点提升,DIoU相对IoU会有3.29点提升,CIoU会有大概5.67点提升,CIoU结合DIoU-NMS使用效果最好,大概会有5.91点提升。
上表中左边是用5种不同Boudning Box Regression Loss Function的对比,右边是以IoU和GIoU来计算的2种Evaluation的结果;GIoU相对IoU会有2.49点提升,DIoU相对IoU会有3.29点提升,CIoU会有大概5.67点提升,CIoU结合DIoU-NMS使用效果最好,大概会有5.91点提升。
结论:
DIoU Loss和CIoU Loss优化了GIoU Loss的不足,实验证明效果有进一步提升,代码已开源,非常推荐工程上去尝试。
附录:
论文地址:https://arxiv.org/pdf/1911.08287.pdf
github地址:https://github.com/Zzh-tju/DIoU-darknet
6. 后续
本文给大家介绍了目标检测任务中的Bounding Boxes Regression Loss Function的发展演进,后续给大家介绍 Classification Loss 的发展演进,例如Binary Cross Entropy Loss, AUC Loss, focal Loss, GHM Loss, AP Loss等。
参考文献:
[1]FastR-CNN (Smooth L1 Loss; 201509)
[2]UnitBox: An Advanced Object Detection Network (IoU Loss;201608)
[3]Generalized Intersection over Union: A Metric and ALoss for Bounding Box Regression (GIOU Loss;CVPR2019)
[4]Distance-IoU Loss:Faster and Better Learning for Bounding Box Regression(DIOU Loss & CIoU Loss ; CVPR2019)
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

